
1. Введение
Обзор
Платформы для потоковой аналитики становятся все более важными в современных хранилищах данных, поскольку спрос бизнес-пользователей на аналитику в реальном времени не ослабевает. Были достигнуты большие успехи в повышении актуальности данных внутри хранилищ и в поддержке потоковой аналитики в целом, но инженеры данных по-прежнему сталкиваются с проблемами при адаптации этих потоковых источников к своей архитектуре хранилища данных.
В этом блоге мы обсуждаем несколько наиболее распространенных проблем, с которыми сталкиваются инженеры данных при решении этих вариантов использования. Мы изложим некоторые дизайнерские идеи и архитектурные шаблоны для эффективного агрегирования потоковых данных с помощью BigQuery.
Свежесть и точность данных
Под свежестью мы подразумеваем, что задержка данных агрегата меньше некоторого порога, например, «актуально по состоянию на последний час». Свежесть определяется подмножеством необработанных данных, включенных в агрегаты.
При работе с потоковыми данными события очень часто поступают в нашу систему обработки данных с опозданием, а это означает, что время, в которое наша система обрабатывает событие, значительно позже времени, в которое событие происходит.
Когда мы обрабатываем поступившие с опозданием факты, значения нашей агрегированной статистики изменятся, а это означает, что в течение дня значения, которые видят аналитики, изменятся[1]. Под точными мы подразумеваем, что агрегированные статистические данные максимально приближены к окончательным согласованным значениям.
Конечно, есть и третье измерение, которое необходимо оптимизировать: затраты – как в смысле денег, так и в смысле производительности. Для иллюстрации мы могли бы использовать логическое представление объектов данных в Staging and Reporting. Недостаток использования логического представления заключается в том, что каждый раз, когда запрашивается агрегированная таблица, сканируется весь набор необработанных данных, что будет медленным и дорогостоящим процессом.
Описание сценария
Давайте подготовим почву для этого варианта использования. Мы собираемся принимать данные потоков событий Википедии, опубликованные Викимедиа. Наша цель — создать таблицу лидеров, в которой будут показаны авторы, внесшие наибольшее количество изменений, и которая будет обновляться по мере публикации новых статей. Наша таблица лидеров, которая будет реализована в виде информационной панели BI Engine, будет агрегировать необработанные события по имени пользователя для расчета очков[2].
2. Дизайн
Многоуровневое хранение данных
В конвейере данных мы определим несколько уровней данных. Мы будем хранить необработанные данные о событиях и строить конвейер последующих преобразований, обогащения и агрегирования. Мы не подключаем таблицы отчетов напрямую к данным, хранящимся в необработанных таблицах, поскольку мы хотим унифицировать и централизовать преобразования, которые нужны различным командам для промежуточных данных.
Важным принципом этой архитектуры является то, что более высокие уровни — промежуточный уровень и отчетность — могут быть пересчитаны в любое время, используя только необработанные данные.
Разделение
BigQuery поддерживает два стиля секционирования; секционирование целочисленного диапазона и секционирование по дате. В этом посте мы будем рассматривать только секционирование по дате.
Для разделения по дате мы можем выбирать между разделами по времени приема или разделами на основе полей. Секционирование по времени приема помещает данные в раздел в зависимости от того, когда данные были получены. Пользователи также могут выбрать раздел во время загрузки, указав декоратор раздела.
Секционирование полей разделяет данные на основе значения даты или отметки времени в столбце.
Для приема событий мы помещаем данные в таблицу, секционированную по времени приема. Это связано с тем, что время приема важно для обработки или повторной обработки данных, полученных в прошлом. Обратные заполнения исторических данных также могут храниться в разделах времени приема в зависимости от того, когда они должны были поступить.
В этой Codelab мы предполагаем, что не будем получать поздно поступающие факты[3] из потока событий Wikimedia. Это упростит инкрементную загрузку промежуточной таблицы, как описано ниже.
Для промежуточной таблицы мы разделим по времени события. Это связано с тем, что наши аналитики заинтересованы в запросе данных на основе времени события (время публикации статьи в Википедии), а не времени, когда событие было обработано в конвейере.
3. Архитектура
Что ты построишь
Чтобы прочитать поток событий из Викимедиа, мы будем использовать протокол SSE . Мы напишем небольшую службу промежуточного программного обеспечения, которая будет считывать поток событий в качестве клиента SSE и публиковать ее в теме Pub/Sub в нашей среде GCP.
Как только события станут доступны в Pub/Sub, мы создадим задание Cloud Dataflow, используя шаблон, который будет передавать записи на наш уровень необработанных данных в нашем хранилище данных BigQuery. Следующим шагом будет вычисление агрегированной статистики для поддержки нашей активной таблицы лидеров.
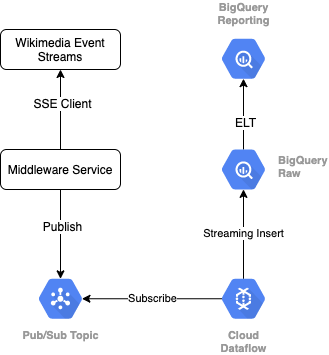
Планирование и оркестровка
Для организации ELT, который заполняет уровни промежуточного хранения и отчетности хранилища, мы будем использовать Dataform . Dataform «приносит инструменты, лучшие практики и рабочие процессы, основанные на разработке программного обеспечения», командам по разработке данных. Помимо оркестрации и планирования, Dataform предоставляет такие функции, как утверждения и тесты для обеспечения качества, определение пользовательских операций хранилища для управления базами данных, а также функции документирования для поддержки обнаружения данных.
Авторы благодарят команду Dataform за ценные отзывы при обзоре этой лаборатории и блога.
В Dataform необработанные данные, поступающие из Dataflow, будут объявлены как внешний набор данных. Таблицы промежуточного хранения и отчетности будут определяться динамически с использованием синтаксиса SQLX Dataform.
Мы будем использовать функцию инкрементной загрузки Dataform для заполнения промежуточной таблицы, планируя запуск проекта Dataform каждый час. В соответствии с вышеизложенным мы предполагаем, что мы не будем получать поздно поступившие факты, поэтому наша логика будет заключаться в приеме записей, время события которых позже, чем время самого последнего события среди существующих промежуточных записей.
В последующих лабораторных работах этой серии мы обсудим обработку поздно поступивших фактов.
Когда мы запустим весь проект, на вышестоящие уровни данных будут добавлены все новые записи, и наши агрегаты будут пересчитаны. В частности, каждый запуск приведет к полному обновлению агрегированной таблицы. Наш физический дизайн будет включать кластеризацию промежуточной таблицы по имени пользователя , что еще больше повысит производительность агрегирующего запроса, который полностью обновит эту таблицу лидеров.
Что вам понадобится
- Последняя версия Chrome
- Базовые знания SQL и базовое знание BigQuery.
4. Приступаем к настройке
Создайте набор данных и таблицу BigQuery для необработанного уровня
Создайте новый набор данных, содержащий нашу схему хранилища. Мы также будем использовать эти переменные позже, поэтому обязательно используйте тот же сеанс оболочки для следующих шагов или установите переменные по мере необходимости. Обязательно замените <PROJECT_ID> идентификатором вашего проекта.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Далее мы создадим таблицу, которая будет хранить необработанные события, используя консоль GCP. Схема будет соответствовать полям, которые мы проецируем из потока событий опубликованных изменений, которые мы получаем из Викимедиа.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Создать тему Pub/Sub и подписку
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Создать учетную запись и проект в форме данных
Перейдите на https://app.dataform.co и создайте новую учетную запись. После входа в систему вы создадите новый проект.
В рамках вашего проекта вам необходимо настроить интеграцию с BigQuery . Поскольку Dataform потребуется подключиться к хранилищу, нам потребуется предоставить учетные данные сервисной учетной записи .
Следуйте инструкциям, указанным выше в документации Dataform, и вы настроите подключение к BigQuery на странице базы данных. Обязательно выберите тот же идентификатор проекта, который вы создали выше, затем загрузите учетные данные и проверьте соединение.
Настроив интеграцию с BigQuery, вы увидите наборы данных, доступные на вкладке «Моделирование». В частности, здесь будет присутствовать таблица Raw, которую мы используем для захвата событий из Dataflow. Давайте вернемся к этому в ближайшее время.
5. Реализация
Создайте службу Python для чтения и публикации событий в Pub/Sub.
См. приведенный ниже код Python, который также доступен в этом списке . В этом примере мы следуем документации API Pub/Sub .
Давайте обратим внимание на список ключей в коде. Это поля, которые мы собираемся проецировать из полного события JSON, сохранять в опубликованных сообщениях и, в конечном итоге, в таблице wiki_changes на уровне Raw нашего набора данных BigQuery.
Они соответствуют схеме таблицы wiki_changes , которую мы определили в нашем наборе данных BigQuery для wiki_changes.
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Реализация, продолжение
Создайте задание потока данных из шаблона для чтения из Pub/Sub и записи в BigQuery.
Как только последние события изменения будут опубликованы в теме Pub/Sub, мы сможем использовать задание Cloud Dataflow, чтобы прочитать эти события и записать их в BigQuery.
Если бы у нас были сложные потребности при обработке потока — например, объединение разрозненных потоков, построение оконных агрегатов, использование поисков для обогащения данных — тогда мы могли бы реализовать их в нашем коде Apache Beam.
Поскольку в этом случае наши потребности более просты, мы можем использовать готовый шаблон Dataflow, и нам не придется вносить в него какие-либо настройки. Мы можем сделать это непосредственно из консоли GCP в Cloud Dataflow.
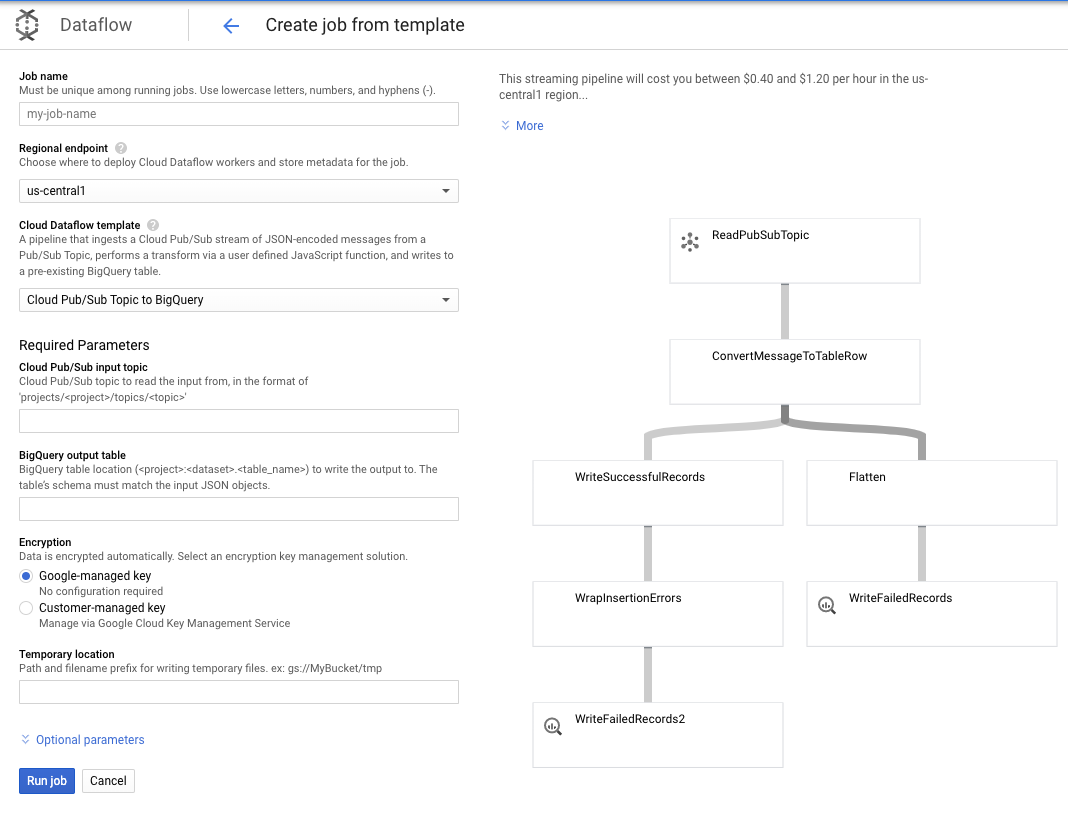
Мы будем использовать шаблон Pub/Sub Topic to BigQuery, а затем нам просто нужно настроить несколько вещей в шаблоне Dataflow, включая входную тему Pub/Sub и выходную таблицу BigQuery.
7. Реализация, этапы формирования данных
Таблицы моделей в форме данных
Наша модель Dataform привязана к следующему репозиторию GitHub: папка определений содержит файлы SQLX, которые определяют модель данных.
Как обсуждалось в разделе «Планирование и оркестрация», мы определим промежуточную таблицу в Dataform, которая агрегирует необработанные записи из wiki_changes . Давайте посмотрим на DDL для промежуточной таблицы (ссылка на которую также имеется в репозитории GitHub, связанном с нашим проектом Dataform).
Отметим несколько важных особенностей этой таблицы:
- Он настроен как инкрементный тип, поэтому при запуске запланированных заданий ELT будут добавляться только новые записи.
- Как показано в коде When() внизу, логика этого основана на поле временной метки, которое отражает временную метку в потоке событий, т. е. event_time изменения.
- Он кластеризуется с использованием пользовательского поля, что означает, что записи в каждом разделе будут упорядочены по пользователю , что уменьшает перетасовку, необходимую для запроса, который создает таблицу лидеров.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
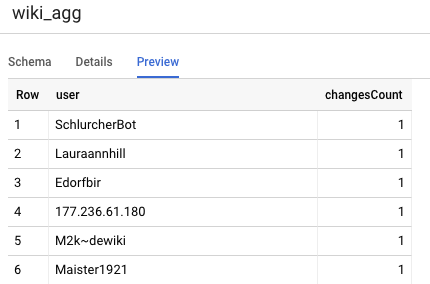
Другая таблица, которую нам нужно определить в нашем проекте, — это таблица уровня отчетности, которая будет поддерживать запросы таблицы лидеров. Таблицы на уровне отчетности агрегируются, поскольку наши пользователи заинтересованы в свежем и точном количестве опубликованных изменений в Википедии.
Определение таблицы является простым и использует ссылки на формы данных. Большим преимуществом этих ссылок является то, что они явно определяют зависимости между объектами, поддерживая корректность конвейера, гарантируя, что зависимости всегда выполняются перед зависимыми запросами.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Расписание проекта формы данных
Последний шаг — просто создать расписание, которое будет выполняться почасово. Когда наш проект вызывается, Dataform выполнит необходимые инструкции SQL, чтобы обновить инкрементную промежуточную таблицу и перезагрузить агрегированную таблицу.
Это расписание можно вызывать каждый час или даже чаще, примерно каждые 5–10 минут, чтобы обновлять таблицу лидеров последними событиями, которые поступают в систему.
8. Поздравления
Поздравляем, вы успешно создали многоуровневую архитектуру для своих потоковых данных!
Мы начали с потока событий Wikimedia и преобразовали его в таблицу отчетов в BigQuery, которая постоянно обновляется.
Что дальше?
Дальнейшее чтение
- Представляем форму данных
- Functional Data Engineering — современная парадигма пакетной обработки данных.
- Как агрегировать данные для BigQuery с помощью Apache Airflow
[1] Инженеры по обработке данных обычно выполняют ежедневное пакетное преобразование для перезаписи внутридневных (скажем, почасовых) агрегатов — это называется сверкой.
[2] Подробности реализации см. в разделе «Архитектура».
[3] Факт с опозданием — это событие, значение event_time которого позднее, чем записи, уже обработанные системой в этом же потоке событий.