
1. บทนำ
ภาพรวม
กรอบการทำงานสำหรับการวิเคราะห์สตรีมมิงมีความสำคัญมากขึ้นเรื่อยๆ ในระบบคลังข้อมูลร่วมสมัย โดยผู้ใช้แบบธุรกิจ ความต้องการการวิเคราะห์แบบเรียลไทม์ยังคงไม่หยุดนิ่ง เราได้สร้างความก้าวหน้าครั้งใหญ่เพื่อปรับปรุงความใหม่ของข้อมูลภายในคลังสินค้าและเพื่อรองรับการวิเคราะห์สตรีมมิงโดยทั่วไป แต่วิศวกรข้อมูลยังต้องเผชิญกับความท้าทายเมื่อนำแหล่งที่มาของสตรีมมิงเหล่านี้มาปรับใช้กับสถาปัตยกรรมคลังข้อมูลของตน
ในบล็อกนี้ เราพูดถึงปัญหาที่พบบ่อยที่สุดบางประการที่วิศวกรข้อมูลต้องเผชิญในการแก้ปัญหากรณีการใช้งานเหล่านี้ เราสรุปแนวคิดในการออกแบบและรูปแบบทางสถาปัตยกรรมบางส่วนเพื่อการรวบรวมข้อมูลสตรีมมิงอย่างมีประสิทธิภาพโดยใช้ BigQuery
ความใหม่และความถูกต้องของข้อมูล
แบบใหม่หมายความว่าเวลาในการตอบสนองของข้อมูลแบบรวมนั้นต่ำกว่าเกณฑ์บางอย่าง เช่น "อัปเดตจนถึงชั่วโมงล่าสุด" ความใหม่จะพิจารณาจากข้อมูลดิบชุดย่อยที่รวมอยู่ในข้อมูลรวม
เมื่อจัดการกับข้อมูลสตรีมมิง เป็นเรื่องปกติที่เหตุการณ์จะมาถึงล่าช้าภายในระบบประมวลผลข้อมูล ซึ่งหมายความว่าเวลาที่ระบบของเราประมวลผลเหตุการณ์จะช้ากว่าเวลาที่เหตุการณ์เกิดขึ้นอย่างมาก
เมื่อเราประมวลผลข้อเท็จจริงที่ส่งมาทีหลัง ค่าสถิติรวมของเราจะเปลี่ยนแปลง ซึ่งหมายความว่าค่าที่นักวิเคราะห์จะเห็นจะเปลี่ยนไปตามในแต่ละวัน[1] ค่าถูกต้องหมายความว่าสถิติรวมใกล้เคียงกับค่าที่ปรับยอดแล้วมากที่สุด
แน่นอนว่ามีมิติที่ 3 ในการเพิ่มประสิทธิภาพ ซึ่งก็คือต้นทุน ในแง่ของเงินและประสิทธิภาพ ตัวอย่างคือเราสามารถใช้มุมมองเชิงตรรกะสำหรับออบเจ็กต์ข้อมูลในการจัดระยะและการรายงานได้ ข้อเสียของการใช้มุมมองเชิงตรรกะคือทุกครั้งที่มีการค้นหาตารางรวม ระบบจะสแกนชุดข้อมูลดิบทั้งหมด ซึ่งจะทำงานช้าและใช้ต้นทุนสูง
คำอธิบายสถานการณ์
มาเตรียมความพร้อมให้กับกรณีการใช้งานนี้กัน เรากำลังจะนำเข้าข้อมูลสตรีมกิจกรรม Wikipedia ที่เผยแพร่โดย Wikimedia เป้าหมายของเราคือการสร้างลีดเดอร์บอร์ดที่จะแสดงให้ผู้เขียนเห็นสิ่งที่มีการเปลี่ยนแปลงมากที่สุด และจะอัปเดตให้เป็นปัจจุบันเมื่อมีการเผยแพร่บทความใหม่ ลีดเดอร์บอร์ดของเราซึ่งจะใช้เป็นแดชบอร์ด BI Engine จะรวบรวมเหตุการณ์ดิบโดยใช้ชื่อผู้ใช้เพื่อคำนวณคะแนน[2]
2. การออกแบบ
การแบ่งระดับข้อมูล
ในไปป์ไลน์ข้อมูล เราจะกำหนดระดับข้อมูลหลายๆ ระดับ เราจะเก็บข้อมูลเหตุการณ์ที่เป็นข้อมูลดิบ และสร้างไปป์ไลน์ของการเปลี่ยนรูปแบบ การสร้างคุณค่า และการรวบรวมในลำดับต่อๆ มา เราไม่เชื่อมโยงตารางการรายงานกับข้อมูลที่อยู่ในตารางข้อมูล RAW โดยตรง เนื่องจากเราต้องการรวมและรวมศูนย์การเปลี่ยนรูปแบบที่ทีมต่างๆ ให้ความสำคัญสำหรับข้อมูลแบบทีละขั้น
หลักการที่สำคัญในสถาปัตยกรรมนี้คือ ระบบสามารถคำนวณระดับที่สูงขึ้น (ขั้นบันไดและการรายงาน) ใหม่ได้ทุกเมื่อโดยใช้ข้อมูลดิบเท่านั้น
การแบ่งพาร์ติชัน
BigQuery รองรับการแบ่งพาร์ติชัน 2 รูปแบบ ได้แก่ การแบ่งพาร์ติชันช่วงจำนวนเต็มและการแบ่งพาร์ติชันวันที่ เราจะพิจารณาการแบ่งพาร์ติชันวันที่ที่อยู่ในขอบเขตของโพสต์นี้เท่านั้น
สำหรับการแบ่งพาร์ติชันวันที่ เราจะเลือกระหว่างพาร์ติชันเวลาการส่งผ่านข้อมูลหรือพาร์ติชันตามช่อง การแบ่งพาร์ติชันเวลาในการนำเข้าจะนำข้อมูลไปไว้ในพาร์ติชันตามเวลาที่ได้ข้อมูลมา นอกจากนี้ ผู้ใช้ยังเลือกพาร์ติชันเมื่อโหลดได้โดยระบุตัวตกแต่งพาร์ติชัน
การแบ่งพาร์ติชันช่องข้อมูลตามค่าวันที่หรือการประทับเวลาในคอลัมน์
สำหรับการส่งผ่านข้อมูลเหตุการณ์ เราจะนำข้อมูลไปไว้ในตารางที่แบ่งพาร์ติชันเวลาการนำเข้า เนื่องจากเวลาการส่งผ่านข้อมูลเกี่ยวข้องกับการประมวลผลหรือประมวลผลข้อมูลที่ได้รับในอดีตอีกครั้ง การทดแทนข้อมูลประวัติจะจัดเก็บไว้ในพาร์ติชันเวลาการนำเข้าได้ด้วย โดยอิงตามเวลาที่ข้อมูลดังกล่าวจะมาถึง
ใน Codelab นี้ เราจะถือว่าเราจะไม่ได้รับข้อเท็จจริงที่ส่งล่าช้า [3] จากสตรีมเหตุการณ์ของ Wikimedia ซึ่งจะลดความซับซ้อนของการโหลดที่เพิ่มขึ้นของตารางชั่วคราวตามที่อธิบายไว้ด้านล่าง
สำหรับตารางชั่วคราว เราจะแบ่งพาร์ติชันตามเวลาของเหตุการณ์ ทั้งนี้เนื่องจากนักวิเคราะห์ของเราสนใจที่จะค้นหาข้อมูลตามเวลาของเหตุการณ์ (เวลาที่บทความได้รับการเผยแพร่บน Wikipedia ไม่ใช่เวลาที่เหตุการณ์ได้รับการประมวลผลภายในไปป์ไลน์
3. สถาปัตยกรรม
สิ่งที่คุณจะสร้าง
เราจะใช้โปรโตคอล SSE ในการอ่านสตรีมเหตุการณ์จาก Wikimedia เราจะเขียนบริการมิดเดิลแวร์ขนาดเล็กที่จะอ่านจากสตรีมเหตุการณ์เป็นไคลเอ็นต์ SSE และจะเผยแพร่ไปยังหัวข้อ Pub/Sub ภายในสภาพแวดล้อม GCP ของเรา
เมื่อเหตุการณ์พร้อมใช้งานใน Pub/Sub แล้ว เราจะสร้างงาน Cloud Dataflow โดยใช้เทมเพลตที่จะสตรีมระเบียนไปยังระดับข้อมูลดิบของคลังข้อมูล BigQuery ขั้นตอนถัดไปคือการคำนวณสถิติรวมเพื่อสนับสนุนลีดเดอร์บอร์ดสดของเรา
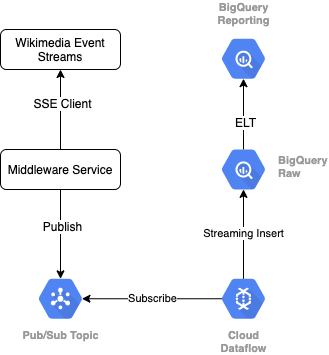
การกำหนดเวลาและการจัดการเป็นกลุ่ม
สำหรับการจัด ELT ที่ป้อนข้อมูลระดับขั้นแสดงและการรายงานของคลังสินค้า เราจะใช้ Dataform Dataform "มอบเครื่องมือ แนวทางปฏิบัติแนะนำ และเวิร์กโฟลว์ที่ได้รับแรงบันดาลใจมาจากวิศวกรรมซอฟต์แวร์" แก่ทีมวิศวกรข้อมูล นอกจากการจัดการเป็นกลุ่มและการกำหนดเวลาแล้ว Dataform ยังมีฟังก์ชันการทำงาน เช่น Assertions และ Tests เพื่อรับรองคุณภาพ การกำหนดการดำเนินการของคลังสินค้าที่กำหนดเองสำหรับการจัดการฐานข้อมูล และฟีเจอร์เอกสารประกอบเพื่อรองรับการค้นพบข้อมูล
ผู้เขียนขอขอบคุณทีม Dataform สำหรับการแสดงความคิดเห็นอันมีค่าในการรีวิวห้องทดลองและบล็อกนี้
ภายใน Dataform ระบบจะประกาศข้อมูลดิบที่สตรีมจาก Dataflow เป็นชุดข้อมูลภายนอก ระบบจะกำหนดตารางการทดลองใช้และการรายงานแบบไดนามิก โดยใช้ไวยากรณ์ SQLX ของ Dataform
เราจะใช้ฟีเจอร์การโหลดที่เพิ่มขึ้นของ Dataform เพื่อป้อนข้อมูลในตารางการทดลองใช้ โดยจะกำหนดเวลาให้โปรเจ็กต์ Dataform ทำงานทุกชั่วโมง ตามข้างต้น เราจะสันนิษฐานว่าเราจะไม่ได้รับข้อเท็จจริงที่มาถึงล่าช้า ดังนั้นตรรกะของเราจะเป็นการนำเข้าบันทึกที่มีเวลาของกิจกรรมซึ่งช้ากว่าเวลาของเหตุการณ์ล่าสุดในบันทึกที่จัดเตรียมไว้ต่างๆ ที่มีอยู่
ในห้องทดลองช่วงท้ายของซีรีส์นี้ เราจะพูดถึงการจัดการข้อเท็จจริงที่มาถึงล่าช้า
เมื่อเราเรียกใช้ทั้งโปรเจ็กต์ ระดับข้อมูลอัปสตรีมจะมีการเพิ่มระเบียนใหม่ทั้งหมด และจะคำนวณการรวมข้อมูลอีกครั้ง โดยเฉพาะอย่างยิ่ง การเรียกใช้แต่ละครั้งจะส่งผลให้ตารางรวมมีการรีเฟรชแบบเต็ม การออกแบบที่จับต้องได้ของเราจะประกอบด้วยการจัดกลุ่มตารางชั่วคราวตามชื่อผู้ใช้ ซึ่งจะช่วยเพิ่มประสิทธิภาพของคำค้นหาแบบรวมที่จะรีเฟรชลีดเดอร์บอร์ดนี้ทั้งหมด
สิ่งที่คุณต้องมี
- Chrome เวอร์ชันล่าสุด
- ความรู้พื้นฐานเกี่ยวกับ SQL และความคุ้นเคยกับ BigQuery เบื้องต้น
4. การตั้งค่า
สร้างชุดข้อมูลและตาราง BigQuery สำหรับระดับข้อมูลดิบ
สร้างชุดข้อมูลใหม่ที่จะมีสคีมาคลังสินค้า นอกจากนี้เราจะใช้ตัวแปรเหล่านี้ในภายหลัง ดังนั้นโปรดใช้เซสชัน Shell เดียวกันสำหรับขั้นตอนต่อไปนี้ หรือตั้งค่าตัวแปรตามที่จำเป็น อย่าลืมแทนที่ <PROJECT_ID> ด้วยรหัสโปรเจ็กต์
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
ต่อไปเราจะสร้างตารางที่จะเก็บเหตุการณ์ดิบโดยใช้คอนโซล GCP สคีมาจะจับคู่ฟิลด์ที่เราฉายภาพจากสตรีมเหตุการณ์ของการเปลี่ยนแปลงที่เผยแพร่ซึ่งเรากำลังบริโภคจาก Wikimedia
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
สร้างหัวข้อ Pub/Sub และการสมัครใช้บริการ
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
สร้างบัญชีและโปรเจ็กต์ Dataform
ไปที่ https://app.dataform.co แล้วสร้างบัญชีใหม่ เมื่อเข้าสู่ระบบแล้ว คุณจะต้องสร้างโปรเจ็กต์ใหม่
ภายในโปรเจ็กต์ คุณจะต้องกำหนดค่าการผสานรวมกับ BigQuery เนื่องจาก Dataform จะต้องเชื่อมต่อกับคลังสินค้า เราจึงต้องจัดสรรข้อมูลเข้าสู่ระบบบัญชีบริการ
โปรดทำตามขั้นตอนที่ลิงก์ด้านบนภายในเอกสาร Dataform คุณจะต้องกำหนดค่าการเชื่อมต่อกับ BigQuery ในหน้าฐานข้อมูล โปรดเลือกรหัสโปรเจ็กต์เดียวกับที่คุณสร้างไว้ข้างต้น จากนั้นอัปโหลดข้อมูลเข้าสู่ระบบและทดสอบการเชื่อมต่อ
เมื่อกำหนดค่าการผสานรวม BigQuery แล้ว คุณจะเห็นชุดข้อมูลภายในแท็บการประมาณ โดยเฉพาะอย่างยิ่ง ตาราง Raw ที่เราใช้เพื่อบันทึกเหตุการณ์จาก Dataflow จะแสดงที่นี่ เรามากลับมาดูเรื่องนี้กันเร็วๆ นี้
5. การใช้งาน
สร้างบริการ Python สำหรับการอ่านและเผยแพร่เหตุการณ์ไปยัง Pub/Sub
โปรดดูโค้ด Python ด้านล่างที่อยู่ในส่วนนี้ด้วย โปรดดูเอกสาร Pub/Sub API ในตัวอย่างนี้
ลองจดรายการคีย์ในโค้ด ซึ่งเป็นช่องที่เรากำลังจะฉายจากเหตุการณ์ JSON แบบเต็ม ยังคงอยู่ในข้อความที่เผยแพร่ และสุดท้ายอยู่ในตาราง wiki_changes ภายในระดับ Raw ของชุดข้อมูล BigQuery
ข้อมูลเหล่านี้ตรงกับสคีมาตาราง wiki_changes ที่เรากำหนดไว้ในชุดข้อมูล BigQuery สำหรับ wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. การใช้งาน ต่อ
สร้างงาน Dataflow จากเทมเพลตเพื่ออ่านจาก Pub/Sub และเขียนไปยัง BigQuery
เมื่อเผยแพร่เหตุการณ์การเปลี่ยนแปลงล่าสุดไปยังหัวข้อ Pub/Sub แล้ว เราจะใช้ประโยชน์จากงาน Cloud Dataflow เพื่ออ่านและเขียนเหตุการณ์ดังกล่าวลงใน BigQuery ได้
หากเรามีความต้องการที่ซับซ้อนขณะประมวลผลสตรีม ให้ลองคิดเข้าร่วมสตรีมที่แยกกัน สร้างการรวมหน้าต่างโดยใช้การค้นหาเพื่อเพิ่มคุณค่าให้กับข้อมูล เราก็จะใช้สตรีมดังกล่าวในโค้ด Apacheบีมได้
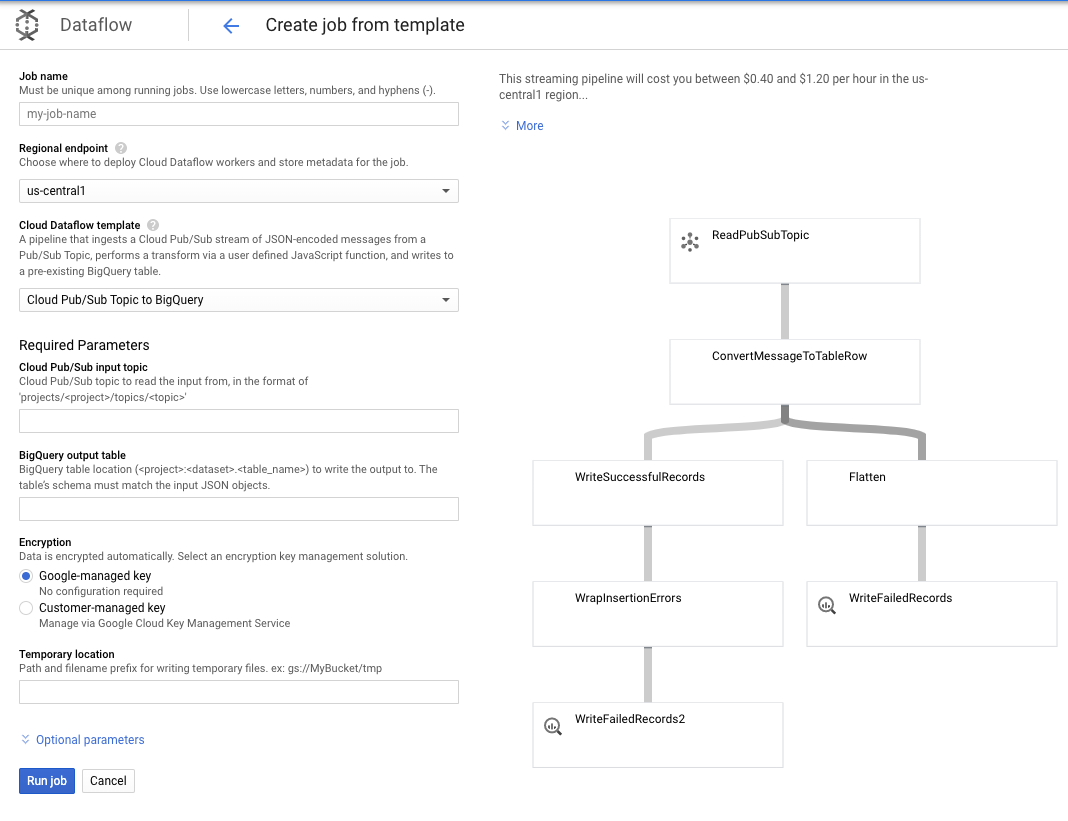
เนื่องจากความต้องการสำหรับกรณีการใช้งานนี้ไม่ซับซ้อน เราจึงใช้เทมเพลต Dataflow แบบพร้อมใช้งานได้ทันทีโดยไม่ต้องปรับแต่งใดๆ เราดำเนินการดังกล่าวได้โดยตรงจากคอนโซล GCP ใน Cloud Dataflow
เราจะใช้หัวข้อ Pub/Sub กับเทมเพลต BigQuery จากนั้นเพียงกำหนดค่าบางอย่างในเทมเพลต Dataflow รวมถึงหัวข้ออินพุต Pub/Sub และตารางเอาต์พุต BigQuery
7. การใช้งาน, ขั้นตอน Dataform
ตารางโมเดลใน Dataform
โมเดล Dataform ของเราเชื่อมโยงกับที่เก็บ GitHub ต่อไปนี้ โดยโฟลเดอร์คำจำกัดความจะมีไฟล์ SQLX ที่กำหนดโมเดลข้อมูล
ตามที่กล่าวไว้ในส่วนการจัดกำหนดการและการจัดการกลุ่ม เราจะกำหนดตารางชั่วคราวใน Dataform ที่รวบรวมระเบียนดิบจาก wiki_changes ลองดู DDL สำหรับตารางการทดลองใช้ (ซึ่งลิงก์อยู่ในที่เก็บ GitHub ที่เชื่อมโยงกับโปรเจ็กต์ Dataform ของเราด้วย)
โปรดทราบคุณลักษณะที่สำคัญบางประการของตารางนี้:
- โดยได้รับการกําหนดค่าเป็นประเภทที่เพิ่มขึ้น ดังนั้นเมื่องาน ELT ที่กำหนดเวลาไว้ทํางานอยู่ ระบบจะเพิ่มเฉพาะระเบียนใหม่เท่านั้น
- ตามที่แสดงโดยโค้ด when() ที่ด้านล่าง ตรรกะสำหรับกรณีนี้จะขึ้นอยู่กับช่องการประทับเวลา ซึ่งแสดงถึงการประทับเวลาในสตรีมเหตุการณ์ กล่าวคือ event_time ของการเปลี่ยนแปลง
- โดยจะมีการคลัสเตอร์โดยใช้ช่อง user ซึ่งหมายความว่าผู้ใช้จะเรียงลำดับระเบียนภายในแต่ละพาร์ติชัน ซึ่งช่วยลดการสับเปลี่ยนที่จำเป็นในการค้นหาที่สร้างลีดเดอร์บอร์ด
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
ตารางอีกตารางที่เราต้องกำหนดในโปรเจ็กต์คือตารางระดับการรายงาน ซึ่งจะรองรับคำค้นหาลีดเดอร์บอร์ด ตารางในระดับการรายงานจะรวบรวมไว้ เนื่องจากผู้ใช้ของเรากังวลเกี่ยวกับจำนวนการเปลี่ยนแปลง Wikipedia ที่เผยแพร่ใหม่และถูกต้อง
คำจำกัดความของตารางไม่ซับซ้อน และใช้ประโยชน์จากการอ้างอิงของ Dataform ข้อดีหลักๆ ของฟีเจอร์อ้างอิงเหล่านี้คือช่วยให้การอ้างอิงที่ชัดเจนว่าทรัพยากร Dependency ระหว่างออบเจ็กต์อย่างชัดเจน ซึ่งช่วยสนับสนุนความถูกต้องของไปป์ไลน์ โดยดูแลให้ทรัพยากร Dependency ดำเนินการก่อนการค้นหาที่อ้างอิงเสมอ
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
ตั้งเวลาโปรเจ็กต์ Dataform
ขั้นตอนสุดท้ายคือการสร้างกำหนดการที่จะดำเนินการทุกชั่วโมง เมื่อมีการเรียกใช้โปรเจ็กต์ Dataform จะดำเนินการตามคำสั่ง SQL ที่จำเป็นเพื่อรีเฟรชตารางชั่วคราวที่เพิ่มขึ้นและโหลดตารางรวมอีกครั้ง
กำหนดการนี้สามารถเรียกใช้ได้ทุกชั่วโมงหรือบ่อยกว่านั้นคือทุก 5-10 นาทีโดยประมาณเพื่อให้ลีดเดอร์บอร์ดอัปเดตตามเหตุการณ์ล่าสุดที่สตรีมเข้ามาในระบบอยู่เสมอ
8. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างสถาปัตยกรรมข้อมูลแบบเป็นขั้นให้กับข้อมูลที่สตรีมสำเร็จแล้ว
เราเริ่มต้นจากสตรีมเหตุการณ์ Wikimedia และได้เปลี่ยนข้อมูลนี้เป็นตารางการรายงานใน BigQuery ที่เป็นปัจจุบันอยู่เสมอ
สิ่งที่ต้องทำต่อไป
อ่านเพิ่มเติม
- ขอแนะนำ Dataform
- วิศวกรรมข้อมูลการทำงาน — กระบวนทัศน์สมัยใหม่สำหรับการประมวลผลข้อมูลแบบกลุ่ม
- วิธีรวมข้อมูลสำหรับ BigQuery โดยใช้ Apache Airflow
[1] เป็นเรื่องปกติที่วิศวกรข้อมูลจะทําการเปลี่ยนรูปแบบเป็นกลุ่มแบบรายวันเพื่อเขียนทับข้อมูลรวมระหว่างวัน (เช่น รายชั่วโมง) หรือที่เรียกว่าการปรับยอด
[2] สำหรับรายละเอียดการใช้งาน โปรดดูที่ส่วนสถาปัตยกรรม
[3] ข้อเท็จจริงที่มาถึงล่าช้าคือเหตุการณ์ที่มี event_time ซึ่งช้ากว่าบันทึกที่ประมวลผลแล้วโดยระบบภายในสตรีมเหตุการณ์เดียวกันนี้