
1. Giriş
Genel Bakış
Akış analizi çerçeveleri, işletme kullanıcılarının buluta geçiş yapmasıyla birlikte modern veri ambarlamada giderek daha önemli hale geliyor. gerçek zamanlı analizlere olan talep artmaya devam ediyor. Depolardaki veri güncelliğini iyileştirmek ve genel olarak akış analizlerini desteklemek için büyük adımlar atıldı. Ancak veri mühendisleri, bu akış kaynaklarını veri ambarı mimarilerine uyarlarken bazı zorluklarla karşılaşıyor.
Bu blogda, veri mühendislerinin bu tür kullanım alanlarını çözerken karşılaştıkları en yaygın zorluklardan birkaçını ele alıyoruz. BigQuery kullanarak akış verilerinin etkili şekilde toplanması için bazı tasarım fikirleri ve mimari kalıplar ana hatlarıyla açıklıyoruz.
Verilerin güncelliği ve doğruluğu
Yeni derken, toplamın veri gecikmesinin belirli bir eşikten az olduğu kastedilmektedir; ör. "son bir saat itibarıyla güncel". Güncellik, toplu işlemlere dahil edilen ham verilerin alt kümesi tarafından belirlenir.
Akış verileri üzerinde çalışırken etkinliklerin veri işleme sistemimize geç ulaşması çok sık karşılaşılan bir durumdur. Diğer bir deyişle, sistemimizin bir etkinliği işlediği zaman, etkinliğin gerçekleştiği zamandan önemli ölçüde daha geçtir.
Bize geç ulaşan bilgileri işlediğimizde, toplu istatistiklerimizin değerleri değişir. Diğer bir deyişle, analistlerin gördüğü değerler gün içinde değişir[1]. Doğru ifadesi, toplu istatistiklerin nihai, mutabık kalınan değerlere olabildiğince yakın olduğu anlamına gelir.
Optimizasyon yapılması gereken üçüncü bir boyut daha vardır: Maliyet ve maliyet. Örnek vermek amacıyla, Hazırlık ve Raporlama'daki veri nesneleri için mantıksal bir görünümden yararlanabiliriz. Mantıksal görünüm kullanmanın dezavantajı, birleştirilmiş tablo her sorgulandığında ham veri kümesinin tamamının taranmasıdır. Bu işlem yavaş ve pahalı olur.
Senaryo Açıklaması
Şimdi bu kullanım alanı için bir zemin oluşturalım. Wikimedia tarafından yayınlanan Wikipedia Etkinlik Akışları verilerini alacağız. Amacımız, en çok değişiklik yapılan yazarları gösteren ve yeni makaleler yayınlandıkça güncel olacak bir skor tablosu oluşturmaktır. BI Engine kontrol paneli olarak uygulanacak olan leaderboard'umuz, puanları hesaplamak için ham etkinlikleri kullanıcı adına göre toplayacaktır[2].
2. Tasarım
Veri Katmanı
Veri ardışık düzeninde birden fazla veri katmanı tanımlayacağız. Ham etkinlik verilerini saklayıp izleyen dönüşüm, zenginleştirme ve toplama işlemlerinden oluşan bir ardışık düzen geliştireceğiz. Aşamalı verilerde farklı ekiplerin önem verdiği dönüşümleri birleştirmek ve merkezileştirmek istediğimiz için Raporlama tablolarını doğrudan ham tablolarda tutulan verilere bağlamayız.
Bu mimarideki önemli bir ilke, daha üst katmanların (Hazırlık ve Raporlama) herhangi bir zamanda yalnızca ham veriler kullanılarak yeniden hesaplanabilmesidir.
Bölümlendirme
BigQuery, iki bölümlendirme stilini destekler: Tam sayı aralığı bölümlendirme ve tarih bölümlendirme. Bu gönderi için yalnızca kapsam dahilinde tarih bölümlendirmeyi dikkate alacağız.
Tarih bölümlendirme için, kullanım süresi bölümleri veya alan tabanlı bölümler arasında seçim yapabiliriz. Besleme süresi, verilerin elde edildiği zamana göre bölümlere ayrılır. Kullanıcılar, yükleme sırasında bölüm süsleyici belirterek de bölüm seçebilir.
Alan bölümlendirme, verileri bir sütundaki tarih veya zaman damgası değerine göre bölümlendirir.
Etkinliklerin kullanımı için veriler, kullanım süresine göre bölümlendirilmiş bir tabloya indirilir. Bunun nedeni, besleme süresinin geçmişte alınan verilerin işlenmesi veya yeniden işlenmesiyle alakalı olmasıdır. Geçmiş verilerin dolguları, ne zaman ulaşacaklarına bağlı olarak kullanım süresi bölümleri içinde de depolanabilir.
Bu Codelab'de, Wikimedia etkinlik akışından geç gelen gerçekleri[3] almayacağımızı varsayacağız. Bu, aşağıda açıklandığı gibi hazırlık tablosunun artımlı yüklemesini basitleştirecektir.
Hazırlık tablosu için etkinlik zamanına göre bölümlendirme yaparız. Bunun nedeni, analistlerimizin olayın ardışık düzende işlendiği zamana değil, olayın tarihine (makalenin Wikipedia'da yayınlandığı zamana) dayalı olarak verileri sorgulamayla ilgilenmesidir.
3. Mimari
Oluşturacaklarınız
Wikimedia'dan etkinlik akışını okumak için SSE protokolünü kullanırız. Etkinlik akışından SSE istemcisi olarak okuyacak ve GCP ortamımızdaki bir Pub/Sub konusuna yayınlayacak küçük bir ara katman yazılımı hizmeti yazacağız.
Etkinlikler Pub/Sub'da kullanılabilir hale geldiğinde, bir şablon kullanarak kayıtları BigQuery veri ambarımızdaki Ham veri katmanımıza aktaracak bir Cloud Dataflow işi oluşturacağız. Bir sonraki adım, canlı skor tablosumuzu desteklemek için toplu istatistikleri hesaplamaktır.
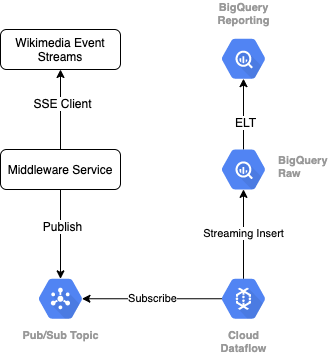
Planlama ve Düzenleme
Deponun Hazırlık ve Raporlama katmanlarını dolduran ELT'yi düzenlemek için Dataform'dan yararlanacağız. Dataform "araçlar, en iyi uygulamalar ve yazılım mühendisliğinden esinlenen iş akışları sunar" veri mühendisliği ekiplerine gönderiyor. Dataform, düzenleme ve planlamanın yanı sıra kalitenin sağlanmasına yönelik Onaylar ve Testler, veritabanı yönetimi için özel depo operasyonları ve veri keşfini destekleyen Belgeleme özellikleri gibi işlevler de sunar.
Yazarlar, bu laboratuvarı ve blogu inceleme sırasında paylaştıkları değerli geri bildirimler için Dataform ekibine teşekkür eder.
Dataform'da, Dataflow'dan aktarılan ham veriler harici veri kümesi olarak tanımlanır. Hazırlık ve Raporlama tabloları Dataform'un SQLX söz dizimi kullanılarak dinamik olarak tanımlanır.
Hazırlık tablosunu doldurmak için Dataform'un artımlı yükleme özelliğinden yararlanacağız ve Dataform projesini saatte bir çalışacak şekilde planlayacağız. Yukarıdakilere göre, geç gelen bilgileri almayacağımızı varsayacağız. Bu nedenle mantığımız, mevcut aşamalı kayıtlar arasındaki en son etkinlik zamanından daha geç bir etkinlik zamanına sahip kayıtları almak olacaktır.
Bu serinin sonraki laboratuvarlarında, geç teslim edilen olguların ele alınmasını ele alacağız.
Projenin tamamını çalıştırdığımızda tüm yeni kayıtlar yukarı akış veri katmanlarına eklenir ve toplamalarımız yeniden hesaplanır. Özellikle her çalıştırma, birleştirilmiş tablonun tamamen yenilenmesini sağlar. Fiziksel tasarımımız, hazırlık tablosunun username olarak kümelenmesini içerir. Böylece, bu skor tablosunu tamamen yenileyecek toplama sorgusunun performansı daha da artırılır.
Gerekenler
- Chrome'un son sürümü
- Temel SQL bilgisi ve BigQuery hakkında temel düzeyde bilgi
4. Kurulum
Ham Katman için BigQuery Veri Kümesi ve Tablosu Oluşturma
Depo şemamızı içerecek yeni bir veri kümesi oluşturun. Bu değişkenleri daha sonra da kullanacağız. Bu nedenle, aşağıdaki adımlar için aynı kabuk oturumunu kullandığınızdan emin olun veya değişkenleri gerektiği şekilde ayarlayın. <PROJECT_ID> değerini değiştirdiğinizden emin olun girin.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Şimdi, GCP Console'u kullanarak ham etkinlikleri tutacak bir tablo oluşturacağız. Şema, Wikimedia'dan kullandığımız yayınlanmış değişikliklerin etkinlik akışından yansıttığımız alanlarla eşleşecek.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Pub/Sub konusu ve aboneliği oluşturma
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Dataform Hesabı ve Projesi Oluşturma
https://app.dataform.co adresine gidin ve yeni bir hesap oluşturun. Giriş yaptığınızda yeni bir proje oluşturacaksınız.
Projeniz içinde BigQuery ile entegrasyonu yapılandırmanız gerekir. Dataform'un depoya bağlanması gerektiğinden hizmet hesabı kimlik bilgilerinin sağlanması gerekecektir.
Lütfen yukarıdaki Dataform belgelerinde bağlantısı verilen adımları uygulayın. BigQuery bağlantısını Veritabanı sayfasında yapılandıracaksınız. Yukarıda oluşturduğunuz proje kimliğini seçtiğinizden emin olun, ardından kimlik bilgilerini yükleyin ve bağlantıyı test edin.
BigQuery entegrasyonunu yapılandırdıktan sonra Modelleme sekmesinde Veri Kümeleri'ni görürsünüz. Özellikle, Dataflow'dan etkinlikleri yakalamak için kullandığımız Ham tablo burada olacaktır. Bu konuya birazdan geri dönelim.
5. Uygulama
Etkinlikleri okumak ve Pub/Sub'da yayınlamak için Python Hizmeti oluşturma
Lütfen bu özet içinde de bulunan aşağıdaki Python kodunu inceleyin. Bu örnekte Pub/Sub API dokümanlarını izleriz.
Koddaki anahtarlar listesini not edelim. Bunlar, tam JSON etkinliğinden yansıtacağımız, yayınlanan mesajlarda ve son olarak BigQuery veri kümemizin Ham katmanındaki wiki_changes tablosunda yer alacak alanlardır.
Bunlar, wiki_changes için BigQuery veri kümemizde tanımladığımız wiki_changes tablo şemasıyla eşleşir
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Uygulama, devam
Pub/Sub'dan okumak ve BigQuery'ye yazmak için şablondan Dataflow işi oluşturma
Son değişiklik etkinlikleri Pub/Sub konusuna yayınlandıktan sonra bu etkinlikleri okumak ve BigQuery'ye yazmak için bir Cloud Dataflow işini kullanabiliriz.
Akışı işlerken farklı ihtiyaçlarımız varsa (farklı akışları birleştirme, aralıklı toplama oluşturma, verileri zenginleştirmek için aramalar kullanma gibi) varsa bunları Apache Beam kodumuzda uygulayabiliriz.
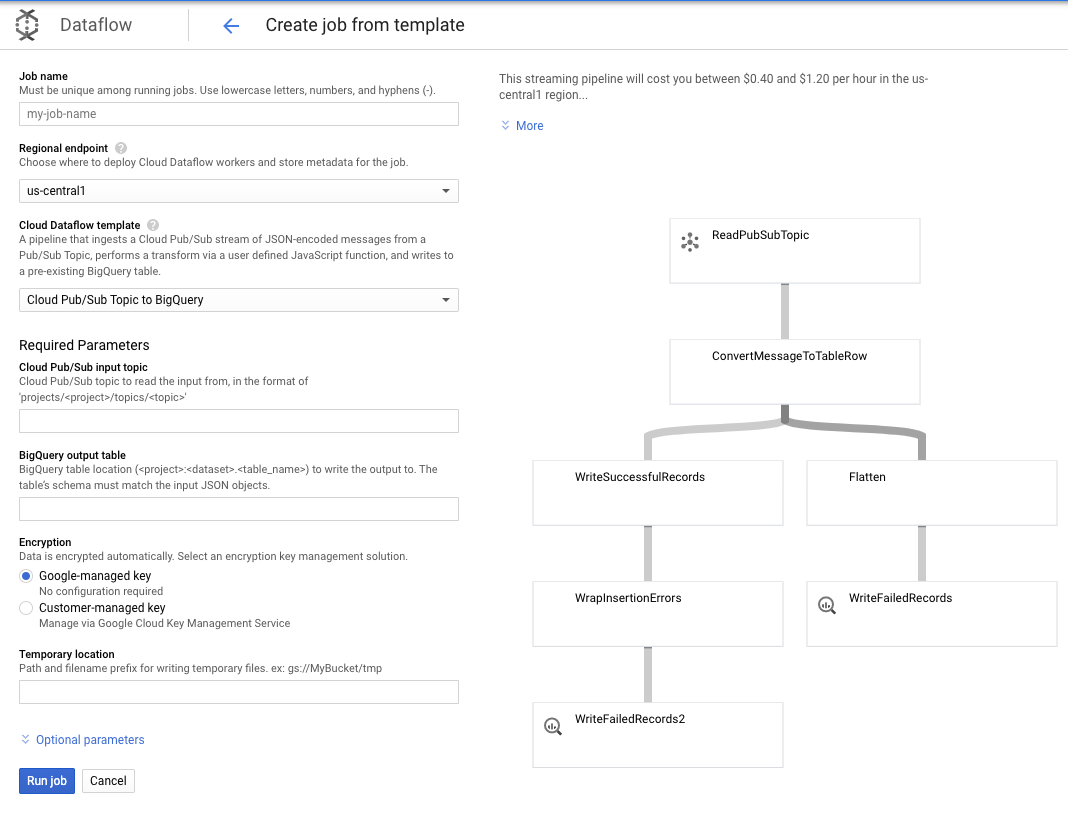
Bu kullanım alanı için ihtiyaçlarımız daha basit olduğundan, kullanıma hazır Dataflow şablonunu kullanabiliriz ve bu şablonda herhangi bir özelleştirme yapmak zorunda kalmayız. Bu işlemi doğrudan Cloud Dataflow'daki GCP Console'dan yapabiliriz.
Önce Pub/Sub Topic to BigQuery şablonunu kullanacağız ve ardından Dataflow şablonunda Pub/Sub giriş konusu ve BigQuery çıkış tablosu gibi birkaç şeyi yapılandırmamız gerekecek.
7. Uygulama, Veri Formu Adımları
Dataform'daki Model Tabloları
Dataform modelimiz, aşağıdaki GitHub deposına bağlıdır. Tanımlar klasörü, veri modelini tanımlayan SQLX dosyalarını içerir.
Planlama ve Düzenleme bölümünde açıklandığı gibi, Veri Formu'nda wiki_changes sayfasındaki ham kayıtları toplayan bir hazırlık tablosu tanımlayacağız. Şimdi, hazırlık tablosu için DDL'ye bakalım (Dataform projemize bağlı GitHub deposunda da bağlantılıdır).
Bu tablonun bazı önemli özelliklerine dikkat edelim:
- Artımlı tür olarak yapılandırılır. Böylece planlanmış ELT işlerimiz çalıştırıldığında yalnızca yeni kayıtlar eklenir
- En alttaki zaman() koduyla da ifade edildiği gibi, bunun mantığı etkinlik akışındaki zaman damgasını (ör.değişikliğin event_time) yansıtan zaman damgası alanına dayanır.
- user alanı kullanılarak kümelenir. Bu, her bir bölümdeki kayıtlar user alanına göre sıralanacağı anlamına gelir. Böylece, skor tablosunu oluşturan sorgunun gerektirdiği karıştırma azaltılır.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
Projemizde tanımlamamız gereken diğer tablo, skor tablosu sorgularını destekleyecek olan Raporlama katmanı tablosudur. Kullanıcılarımız yayınlanan Wikipedia değişikliklerinin yeni ve doğru sayılarına önem verdiğinden Raporlama katmanındaki tablolar toplanır.
Tablo tanımı basittir ve Dataform referanslarından faydalanır. Bu referansların en önemli avantajlarından biri, nesneler arasındaki bağımlılıkları açık bir şekilde belirtmeleridir. Bağımlılıkların her zaman bağımlı sorgulardan önce yürütülmesini sağlayarak ardışık düzen doğruluğunu desteklerler.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Dataform Projesini Planlama
Son adım sadece saatlik olarak yürütülecek bir zaman çizelgesi oluşturmaktır. Projemiz çağrıldığında Dataform, artımlı hazırlık tablosunu yenilemek ve birleştirilmiş tabloyu yeniden yüklemek için gerekli SQL ifadelerini yürütür.
Bu program, skor tablosunun sisteme aktarılan son etkinliklerle güncel kalmasını sağlamak için saatte bir veya daha sık, en fazla 5-10 dakikada bir çağrılabilir.
8. Tebrikler
Tebrikler, akışlı verileriniz için başarıyla katmanlı veri mimarisi oluşturdunuz.
Bir Wikimedia etkinlik akışı ile başladık ve bunu BigQuery'de sürekli güncel olan bir raporlama tablosuna dönüştürdük.
Sırada ne var?
Daha fazla bilgi
- Dataform ile tanışın
- İşlevsel Veri Mühendisliği: Toplu veri işleme için modern bir paradigma
- Apache Airflow kullanarak BigQuery için verileri birleştirme
[1] Veri mühendislerinin gün içi (örneğin, saatlik) toplamaların üzerine yazmak için günlük, toplu bir dönüştürme yapması yaygın bir uygulamadır. Buna mutabakat denir.
[2] Uygulama ayrıntıları için lütfen Mimari bölümüne bakın.
[3] Geç gelen bilgi, event_time etkinliği, sistem tarafından aynı etkinlik akışında işlenen kayıtlardan daha geç olan bir etkinliktir