
1. Giới thiệu
Tổng quan
Khung làm việc cho hoạt động phân tích theo luồng ngày càng trở nên quan trọng trong hoạt động lưu trữ dữ liệu hiện đại, khi người dùng doanh nghiệp nhu cầu phân tích theo thời gian thực vẫn chưa giảm. Đã có những bước tiến lớn nhằm cải thiện độ mới của dữ liệu trong nhà kho và hỗ trợ việc phân tích theo luồng nói chung. Tuy nhiên, các kỹ sư dữ liệu vẫn đang đối mặt với nhiều thách thức khi điều chỉnh các nguồn truyền dữ liệu này vào cấu trúc kho dữ liệu của mình.
Trong blog này, chúng tôi trình bày một số thách thức phổ biến nhất mà kỹ sư dữ liệu gặp phải khi giải quyết các trường hợp sử dụng này. Chúng tôi đưa ra một số ý tưởng thiết kế và mẫu cấu trúc để tổng hợp dữ liệu truyền trực tuyến một cách hiệu quả bằng BigQuery.
Độ mới và độ chính xác của dữ liệu
Khi sử dụng mới, chúng tôi muốn nói rằng độ trễ của dữ liệu tổng hợp thấp hơn một ngưỡng nào đó, ví dụ: "đã cập nhật tính đến giờ vừa qua". Độ mới được xác định bởi tập hợp con dữ liệu thô có trong dữ liệu tổng hợp.
Khi xử lý dữ liệu truyền trực tuyến, thông thường các sự kiện sẽ đến trễ trong hệ thống xử lý dữ liệu của chúng tôi, tức là thời gian hệ thống của chúng tôi xử lý sự kiện thường muộn hơn đáng kể so với thời điểm sự kiện đó xảy ra.
Khi chúng tôi xử lý dữ kiện được đưa ra muộn, giá trị của các số liệu thống kê tổng hợp sẽ thay đổi, nghĩa là trong phạm vi ngày, giá trị mà nhà phân tích nhìn thấy sẽ thay đổi[1]. Bằng chính xác, chúng tôi muốn nói rằng số liệu thống kê tổng hợp càng sát với giá trị cuối cùng được điều chỉnh càng tốt.
Tất nhiên, còn có khía cạnh thứ ba để tối ưu hoá: chi phí – cả về tiền và hiệu suất. Để minh hoạ, chúng ta có thể sử dụng chế độ xem logic cho các đối tượng dữ liệu trong tính năng Thử nghiệm và Báo cáo. Nhược điểm của việc sử dụng chế độ xem logic là mỗi lần bảng tổng hợp được truy vấn, toàn bộ tập dữ liệu thô sẽ được quét. Việc này sẽ chậm và tốn kém.
Nội dung mô tả tình huống
Hãy chuẩn bị sẵn sàng cho trường hợp sử dụng này. Chúng tôi sẽ nhập dữ liệu Luồng sự kiện trên Wikipedia do Wikimedia xuất bản. Mục tiêu của chúng tôi là xây dựng một bảng xếp hạng cho thấy những tác giả có nhiều thay đổi nhất và sẽ được cập nhật khi các bài viết mới được xuất bản. Bảng xếp hạng của chúng tôi (được triển khai dưới dạng trang tổng quan của BI Engine) sẽ tổng hợp các sự kiện thô theo tên người dùng để tính toán điểm số[2].
2. Thiết kế
Phân cấp dữ liệu
Trong quy trình dữ liệu, chúng ta sẽ xác định nhiều cấp dữ liệu. Chúng tôi sẽ giữ lại dữ liệu sự kiện thô và xây dựng một quy trình biến đổi, làm giàu và tổng hợp tiếp theo. Chúng tôi không kết nối trực tiếp các bảng Báo cáo với dữ liệu có trong các bảng thô, vì chúng tôi muốn hợp nhất và tập trung các lượt chuyển đổi mà các nhóm khác nhau quan tâm đối với dữ liệu theo giai đoạn.
Một nguyên tắc quan trọng trong cấu trúc này là các cấp cao hơn–Staging and Reporting – có thể được tính toán lại bất kỳ lúc nào chỉ bằng dữ liệu thô.
Phân vùng
BigQuery hỗ trợ hai kiểu phân chia; phân vùng phạm vi số nguyên và phân vùng ngày. Chúng tôi sẽ chỉ xem xét việc phân vùng theo ngày trong phạm vi của bài đăng này.
Để phân vùng theo ngày, chúng ta có thể chọn phân vùng thời gian nhập hoặc phân vùng theo trường. Tính năng phân vùng thời gian truyền dẫn sẽ chuyển dữ liệu vào một phân vùng dựa trên thời điểm thu thập dữ liệu. Người dùng cũng có thể chọn một phân vùng vào thời điểm tải bằng cách chỉ định một công cụ trang trí phân vùng.
Tính năng phân vùng trường dữ liệu phân vùng dựa trên giá trị ngày hoặc dấu thời gian trong một cột.
Để nhập các sự kiện, chúng tôi sẽ chuyển dữ liệu vào một bảng được phân vùng theo thời gian nhập. Lý do là thời gian nhập có liên quan đến việc xử lý hoặc xử lý lại dữ liệu nhận được trước đây. Ngoài ra, việc bổ sung dữ liệu trong quá khứ cũng có thể được lưu trữ trong các phân vùng thời gian nhập, dựa trên thời điểm các dữ liệu đó đến nơi.
Trong lớp học lập trình này, chúng ta sẽ giả định rằng sẽ không nhận được dữ liệu được gửi đến muộn[3] từ luồng sự kiện trên Wikimedia. Thao tác này sẽ đơn giản hoá quá trình tải dần bảng chạy thử nghiệm, như thảo luận dưới đây.
Đối với bảng thử nghiệm, chúng ta sẽ phân vùng theo thời gian sự kiện. Lý do là vì các nhà phân tích của chúng tôi muốn truy vấn dữ liệu dựa trên thời gian xảy ra sự kiện (thời gian bài viết được xuất bản trên Wikipedia) chứ không phải thời gian xử lý sự kiện trong quy trình.
3. Kiến trúc
Sản phẩm bạn sẽ tạo ra
Để đọc luồng sự kiện từ Wikimedia, chúng ta sẽ sử dụng giao thức SSE. Chúng tôi sẽ viết một dịch vụ phần mềm trung gian nhỏ. Dịch vụ này sẽ đọc từ luồng sự kiện dưới dạng một ứng dụng SSE và sẽ xuất bản lên một chủ đề Pub/Sub trong môi trường GCP của chúng tôi.
Sau khi các sự kiện có sẵn trong Pub/Sub, chúng ta sẽ tạo một công việc trên Cloud Dataflow (bằng cách sử dụng một mẫu) để truyền trực tuyến các bản ghi vào Cấp dữ liệu thô trong kho dữ liệu BigQuery của chúng ta. Bước tiếp theo là tính toán số liệu thống kê tổng hợp để hỗ trợ bảng xếp hạng trực tiếp của chúng tôi.
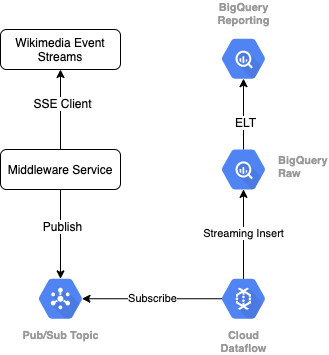
Lên lịch và điều phối
Để điều phối ELT điền sẵn các cấp Sắp xếp và Báo cáo của kho hàng, chúng tôi sẽ sử dụng Biểu mẫu dữ liệu. Biểu mẫu dữ liệu "cung cấp công cụ, các phương pháp hay nhất và quy trình làm việc lấy cảm hứng từ kỹ thuật phần mềm" cho nhóm kỹ thuật dữ liệu. Ngoài việc điều phối và lên lịch, Dataform còn cung cấp những chức năng như Xác nhận và Kiểm thử để đảm bảo chất lượng, xác định Hoạt động kho tuỳ chỉnh để quản lý cơ sở dữ liệu và các tính năng Tài liệu để hỗ trợ khám phá dữ liệu.
Các tác giả cảm ơn nhóm Dataform đã gửi ý kiến phản hồi hữu ích trong quá trình đánh giá phòng thí nghiệm và blog này.
Trong Dataform, Dữ liệu thô truyền vào từ Dataflow sẽ được khai báo là tập dữ liệu bên ngoài. Các bảng Sắp xếp và Báo cáo sẽ được xác định một cách linh động bằng cú pháp SQLX của Dataform.
Chúng ta sẽ sử dụng tính năng tải gia tăng của Dataform để điền sẵn vào bảng chạy thử nghiệm, lên lịch chạy dự án Dataform mỗi giờ. Theo đó, chúng tôi sẽ giả định rằng sẽ không nhận được thông tin thực tế đến trễ. Vì vậy, logic của chúng ta sẽ nhập các bản ghi có thời gian sự kiện muộn hơn thời gian sự kiện gần đây nhất trong số các bản ghi theo giai đoạn hiện có.
Trong các phòng thí nghiệm sau của loạt bài này, chúng ta sẽ thảo luận về cách xử lý các dữ liệu được gửi đến muộn.
Khi chúng ta chạy toàn bộ dự án, tất cả các bản ghi mới sẽ được thêm vào các cấp dữ liệu ở trên và dữ liệu tổng hợp của chúng ta sẽ được tính toán lại. Cụ thể, mỗi lần chạy sẽ dẫn đến việc làm mới hoàn toàn bảng tổng hợp. Thiết kế thực tế của chúng tôi sẽ bao gồm việc nhóm bảng thử nghiệm theo tên người dùng, giúp tăng thêm hiệu suất của truy vấn tổng hợp để làm mới hoàn toàn bảng xếp hạng này.
Bạn cần có
- Phiên bản Chrome mới nhất
- Kiến thức cơ bản về SQL và kiến thức cơ bản về BigQuery
4. Thiết lập
Tạo tập dữ liệu và bảng BigQuery cho cấp thô
Tạo một tập dữ liệu mới để chứa giản đồ kho hàng của chúng ta. Chúng ta cũng sẽ sử dụng các biến này sau, vì vậy, hãy nhớ sử dụng cùng một phiên shell cho các bước sau hoặc đặt các biến nếu cần. Hãy nhớ thay thế <PROJECT_ID> bằng mã dự án của bạn.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Tiếp theo, chúng ta sẽ tạo một bảng để lưu giữ các sự kiện thô bằng Bảng điều khiển GCP. Giản đồ sẽ khớp với các trường mà chúng tôi dự án từ luồng sự kiện của các thay đổi đã xuất bản mà chúng tôi đang sử dụng từ Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Tạo chủ đề và gói đăng ký Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Tạo tài khoản và dự án Dataform
Truy cập vào https://app.dataform.co rồi tạo một tài khoản mới. Sau khi đăng nhập, bạn sẽ tạo một dự án mới.
Trong dự án của mình, bạn cần định cấu hình chế độ tích hợp với BigQuery. Vì Dataform cần kết nối với kho hàng, nên chúng tôi sẽ cần cung cấp thông tin đăng nhập cho tài khoản dịch vụ.
Vui lòng làm theo các bước được liên kết ở trên trong tài liệu về Biểu mẫu dữ liệu. Bạn sẽ thiết lập kết nối với BigQuery trên trang Cơ sở dữ liệu. Hãy nhớ chọn cùng mã projectId mà bạn đã tạo ở trên, sau đó tải thông tin đăng nhập lên và kiểm tra kết nối.
Sau khi định cấu hình chế độ tích hợp BigQuery, bạn sẽ thấy Tập dữ liệu có sẵn trong thẻ Lập mô hình. Cụ thể, bảng Raw mà chúng tôi sử dụng để thu thập các sự kiện từ Dataflow sẽ xuất hiện ở đây. Chúng ta sẽ bàn về vấn đề này ngay sau đây.
5. Triển khai
Tạo Dịch vụ Python để đọc và xuất bản Sự kiện lên Pub/Sub
Vui lòng xem mã Python bên dưới, cũng có sẵn trong nội dung chính này. Chúng tôi đang làm theo tài liệu về API Pub/Sub trong ví dụ này.
Hãy lưu ý về danh sách khoá trong mã. Đây là những trường mà chúng ta sẽ lập dự án từ sự kiện JSON đầy đủ, vẫn tồn tại trong các thông báo đã xuất bản và cuối cùng là trong bảng wiki_changes trong Cấp thô của tập dữ liệu BigQuery.
Các URL này phù hợp với giản đồ bảng wiki_changes mà chúng tôi đã xác định trong tập dữ liệu BigQuery cho wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Triển khai, tiếp tục
Tạo Dataflow Job từ mẫu để đọc từ Pub/Sub và ghi vào BigQuery
Sau khi xuất bản các sự kiện thay đổi gần đây theo chủ đề Pub/Sub, chúng ta có thể sử dụng công việc Cloud Dataflow để đọc và ghi những sự kiện này vào BigQuery.
Nếu chúng tôi có nhu cầu phức tạp khi xử lý luồng – hãy nghĩ đến việc kết hợp các luồng khác nhau, xây dựng các tập hợp cửa sổ, sử dụng các phép tra cứu để làm phong phú dữ liệu – thì chúng tôi có thể triển khai chúng trong mã Apache Beam của mình.
Vì nhu cầu của chúng tôi đơn giản hơn đối với trường hợp sử dụng này, nên chúng tôi có thể sử dụng mẫu Dataflow có sẵn và chúng tôi sẽ không phải tuỳ chỉnh mẫu này. Chúng ta có thể thực hiện việc này ngay trên Bảng điều khiển GCP trong Cloud Dataflow.
Chúng ta sẽ sử dụng mẫu Pub/Sub Topic cho BigQuery. Sau đó, chúng ta chỉ cần định cấu hình một vài mục trong mẫu Dataflow, bao gồm cả chủ đề đầu vào Pub/Sub và bảng dữ liệu đầu ra của BigQuery.

7. Triển khai, các bước trong biểu mẫu dữ liệu
Bảng mô hình trong biểu mẫu dữ liệu
Mô hình Dataform của chúng tôi được liên kết với kho lưu trữ GitHub sau đây – thư mục định nghĩa chứa các tệp SQLX xác định mô hình dữ liệu.
Như đã thảo luận trong phần Lập lịch biểu và điều phối, chúng ta sẽ xác định một bảng thử nghiệm trong Biểu mẫu dữ liệu để tổng hợp các bản ghi thô từ wiki_changes. Hãy xem DDL cho bảng chạy thử (cũng được liên kết trong kho lưu trữ GitHub được liên kết với dự án Dataform của chúng tôi).
Hãy lưu ý một vài tính năng quan trọng của bảng này:
- Thuộc tính này được định cấu hình theo kiểu gia tăng, vì vậy, khi chạy các công việc ELT đã lên lịch, chỉ có các bản ghi mới được thêm vào
- Như được biểu thị bằng mã when() ở dưới cùng, logic cho việc này dựa trên trường dấu thời gian, phản ánh dấu thời gian trong luồng sự kiện, tức là event_time của thay đổi
- Bảng này được nhóm bằng trường người dùng, tức là các bản ghi trong mỗi phân vùng sẽ được sắp xếp theo người dùng, giúp giảm sự xáo trộn mà truy vấn tạo bảng xếp hạng yêu cầu
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
Một bảng khác mà chúng ta cần xác định trong dự án là bảng Cấp báo cáo. Bảng này sẽ hỗ trợ các truy vấn bảng xếp hạng. Các bảng trong cấp Báo cáo được tổng hợp vì người dùng của chúng tôi lo ngại về số lượng mới và chính xác các thay đổi đã xuất bản trên Wikipedia.
Định nghĩa bảng rất đơn giản và sử dụng tệp tham chiếu của Biểu mẫu dữ liệu. Ưu điểm lớn của các tệp tham chiếu này là chúng làm rõ các phần phụ thuộc giữa các đối tượng, hỗ trợ tính chính xác của quy trình bằng cách đảm bảo rằng các phần phụ thuộc luôn được thực thi trước các truy vấn phụ thuộc.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Lên lịch cho dự án Dataform
Bước cuối cùng chỉ đơn giản là tạo lịch biểu sẽ thực thi theo giờ. Khi dự án của chúng ta được gọi, Dataform sẽ thực thi các câu lệnh SQL bắt buộc để làm mới bảng thử nghiệm gia tăng và tải lại bảng tổng hợp.
Lịch biểu này có thể được gọi mỗi giờ – hoặc thậm chí thường xuyên hơn, tối đa là khoảng 5 – 10 phút một lần – để bảng xếp hạng luôn được cập nhật những sự kiện gần đây đã được truyền trực tuyến vào hệ thống.
8. Xin chúc mừng
Xin chúc mừng! Bạn đã xây dựng thành công cấu trúc dữ liệu theo cấp độ cho dữ liệu được truyền trực tuyến!
Chúng tôi bắt đầu bằng một luồng sự kiện trên Wikimedia và đã chuyển đổi luồng này thành bảng Báo cáo trong BigQuery và được cập nhật liên tục.
Tiếp theo là gì?
Tài liệu đọc thêm
- Giới thiệu về Dataform
- Kỹ thuật dữ liệu chức năng – một mô hình hiện đại cho hoạt động xử lý dữ liệu hàng loạt
- Cách tổng hợp dữ liệu cho BigQuery bằng Apache Airflow
[1] Thông thường, các kỹ sư dữ liệu sẽ chạy quy trình biến đổi hàng loạt hằng ngày để ghi đè dữ liệu tổng hợp trong ngày (ví dụ: hằng giờ) – đây được gọi là quy trình điều chỉnh.
[2] Để biết thông tin chi tiết về cách triển khai, vui lòng tham khảo phần Kiến trúc.
[3] Dữ liệu đến trễ là một sự kiện có event_time trễ hơn các bản ghi đã được hệ thống xử lý trong cùng một luồng sự kiện này