
1. 简介
概览
流式分析框架在当代数据仓储中变得越来越重要,对实时分析的需求持续增长。在提高仓库内部的数据新鲜度并全面支持流式分析方面已经取得了很大的进步,但是数据工程师在将这些流式源调整到数据仓库架构中时仍面临着挑战。
在此博客中,我们将讨论数据工程师在解决这些用例时面临的一些最常见的挑战。我们将概述使用 BigQuery 高效汇总流式数据的一些设计理念和架构模式。
数据新鲜度和准确性
“全新”是指汇总的数据延迟时间小于某个阈值,例如“截至过去一小时的最新信息”。新鲜度取决于汇总中包含的原始数据子集。
在处理流式数据时,事件在我们的数据处理系统中延迟到达很常见,这意味着,我们的系统处理事件的时间远远晚于事件发生的时间。
在我们处理延迟的事实时,汇总统计信息的值会发生变化,也就是说,分析人员在一天内看到的值会发生变化 [1]。“准确”是指汇总的统计信息尽可能接近最终的对账值。
当然,还有第三个维度需要优化,从费用和效果两方面来看费用。为便于说明,我们可以在“预演”和“报告”界面中使用逻辑视图来查看数据对象。使用逻辑视图的缺点是,每次查询汇总表时,系统都会扫描整个原始数据集,这将速度缓慢且成本高昂。
场景说明
让我们来为此用例做好准备。我们将提取由维基媒体发布的 Wikipedia 事件流数据。我们的目标是构建一个排行榜,其中会显示更改最多的作者,并且随着新文章的发布,排行榜也会随之更新。我们的排行榜将作为 BI Engine 信息中心实现,将按用户名汇总原始事件以计算得分 [2]。
2. 设计
数据分层
在数据流水线中,我们将定义多层数据。我们将保留原始事件数据,并构建用于后续转换、丰富和聚合的流水线。我们不会将报表表格直接关联到保存在原始表中的数据,因为我们希望将不同团队所关注的已暂存数据的转换进行统一和集中处理。
此架构中的一个重要原则是,您可以随时使用原始数据重新计算更高级别(预演和报告)。
分区
BigQuery 支持两种分区样式:整数范围分区和日期分区。在本文中,我们将仅考虑日期分区。
对于日期分区,我们可以选择提取时间分区或基于字段的分区。提取时间分区会根据数据的获取时间将数据归入相应分区。用户还可以通过指定分区修饰器,在加载时选择分区。
字段分区根据列中的日期或时间戳值对数据进行分区。
为了提取事件,我们会将数据放到提取时间分区表中。这是因为提取时间与处理或重新处理过去收到的数据有关。历史数据的回填也可以存储在提取时间分区中,具体取决于这些数据到达的时间。
在此 Codelab 中,我们将假定不会从维基媒体事件流收到延迟的事实信息 [3]。这将简化暂存表的增量加载,如下所述。
对于暂存表,我们将按事件时间分区。这是因为我们的分析师希望根据事件时间(文章在维基百科上发布的时间)查询数据,而不是在流水线中处理事件的时间。
3. 建筑
构建内容
为了从维基媒体读取事件流,我们将使用 SSE 协议。我们将编写一个小型中间件服务,该服务将作为 SSE 客户端从事件流中读取数据,并将结果发布到 GCP 环境中的 Pub/Sub 主题。
事件在 Pub/Sub 中可用后,我们将使用模板创建 Cloud Dataflow 作业,该作业会将记录流式传输到 BigQuery 数据仓库中的原始数据层。下一步是计算汇总统计信息以支持我们的实时排行榜。
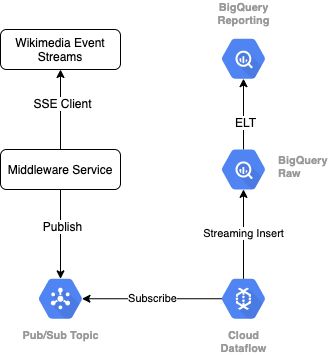
调度和编排
为了编排填充仓库的 Staging 和 Reporting 层的 ELT,我们将使用 Dataform。Dataform“提供工具、最佳实践和受软件工程启发的工作流”数据工程团队。除了编排和调度之外,Dataform 还提供“断言”和测试“确保质量”等功能,为数据库管理定义自定义仓库操作,以及支持数据发现的文档功能。
作者感谢 Dataform 团队在审核本实验和博客时提供了宝贵的反馈意见。
在 Dataform 中,从 Dataflow 流式传输的原始数据将声明为外部数据集。暂存表和报表表将使用 Dataform 的 SQLX 语法动态定义。
我们将使用 Dataform 的增量加载功能填充暂存表,并安排 Dataform 项目每小时运行一次。根据上述说明,我们假定我们不会收到延迟的事实,因此我们的逻辑是从现有暂存记录中注入事件时间晚于最新事件时间的记录。
在本系列后续实验中,我们将讨论如何处理延迟数据。
当我们运行整个项目时,上游数据层将添加所有新记录,并且将重新计算汇总。具体而言,每次运行都会导致汇总表被完全刷新。我们的物理设计将包括按用户名对暂存表进行聚类,进一步提高完全刷新此排行榜的聚合查询的性能。
所需条件
- 较新版本的 Chrome
- 具备 SQL 基础知识并基本熟悉 BigQuery
4. 准备工作
为原始层级创建 BigQuery 数据集和表
创建一个包含仓库架构的新数据集。我们稍后还会使用这些变量,因此请务必使用相同的 shell 会话来执行以下步骤,或根据需要设置变量。请务必替换 <PROJECT_ID>替换为您的项目 ID。
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
接下来,我们将使用 GCP 控制台创建一个用于存储原始事件的表。架构将与我们从维基媒体中使用的已发布更改的事件流中预测的字段一致。
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
创建 Pub/Sub 主题和订阅
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
创建 Dataform 账号和项目
前往 https://app.dataform.co 并创建一个新账号。登录后,您将创建一个新项目。
在项目中,您需要配置与 BigQuery 的集成。由于 Dataform 需要连接到仓库,因此我们需要预配服务账号凭据。
请按照上方 Dataform 文档中链接的步骤进行操作,您将在“数据库”页面上配置与 BigQuery 的连接。请务必选择您在上面创建的同一 projectId,然后上传凭据并测试连接。
配置 BigQuery 集成后,您会在“建模”标签页中看到可用的数据集。具体而言,我们用于从 Dataflow 捕获事件的原始表将显示在此处。我们稍后回过头来。
5. 实施
创建用于读取事件并将其发布到 Pub/Sub 的 Python 服务
请参阅下面的 Python 代码(也可在此要点中找到)。我们将按照此示例中的 Pub/Sub API 文档进行操作。
请记下代码中的 keys 列表,这些字段是我们将从完整的 JSON 事件中投影的字段,这些字段会保留在已发布的消息中,并最终保留在 BigQuery 数据集“Raw”层级的 wiki_changes 表中。
这些匹配与我们我们在 BigQuery 数据集内为 wiki_changes 定义的 wiki_changes 表架构
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. 实施(续)
基于模板创建 Dataflow 作业,以从 Pub/Sub 读取数据并将数据写入 BigQuery
将最近的更改事件发布到 Pub/Sub 主题后,我们可以利用 Cloud Dataflow 作业读取这些事件并将其写入 BigQuery。
如果在处理数据流时有复杂的需求(考虑联接不同的数据流、构建窗口化的聚合、使用查询来丰富数据),我们可以在 Apache Beam 代码中实现这些需求。
对于此用例,我们的需求更加简单明了,因此我们可以使用开箱即用的 Dataflow 模板,无需对其进行任何自定义。我们可以直接从 Cloud Dataflow 中的 GCP Console 执行此操作。
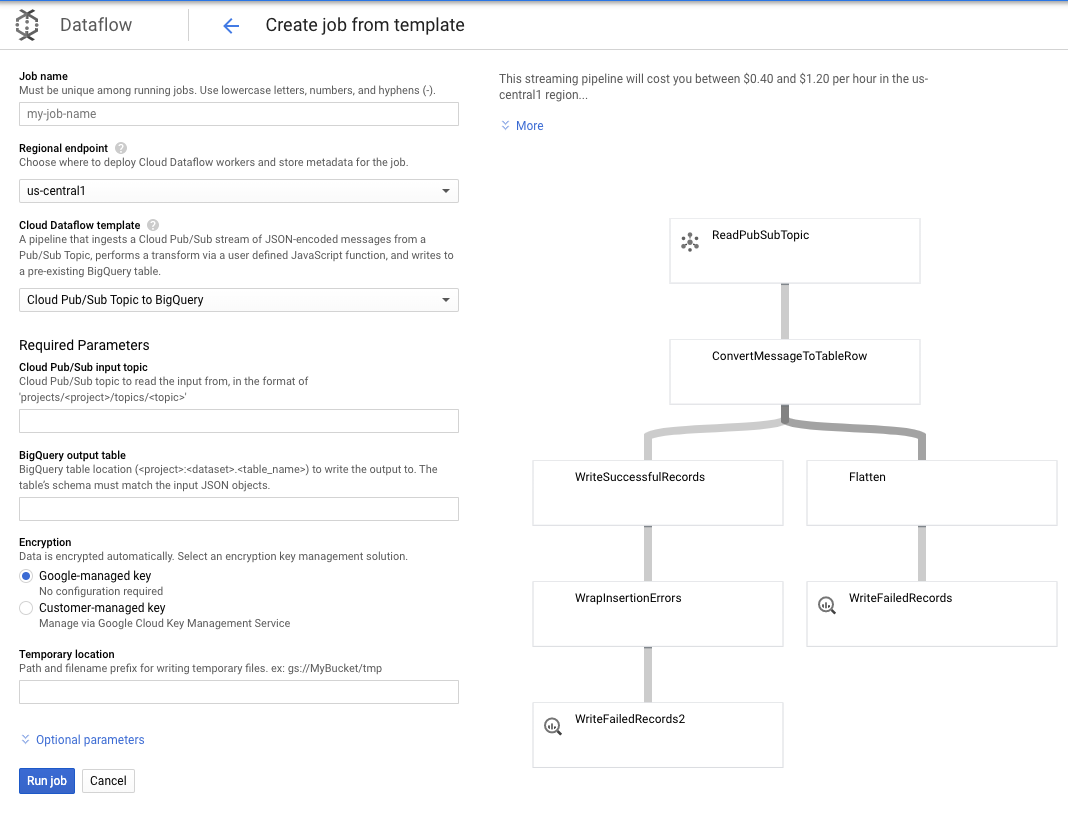
我们将使用 Pub/Sub Topic to BigQuery 模板,然后只需在 Dataflow 模板中配置一些内容,包括 Pub/Sub 输入主题和 BigQuery 输出表。
7. 实现、Dataform 步骤
Dataform 中的模型表
我们的 Dataform 模型与以下 GitHub 代码库相关联 - 定义文件夹包含定义数据模型的 SQLX 文件。
如“调度和编排”部分所述,我们将在 Dataform 中定义一个暂存表,用于汇总来自 wiki_changes 的原始记录。我们来看看暂存表的 DDL(也在与 Dataform 项目关联的 GitHub 代码库中提供了链接)。
请注意此表格的几个重要功能:
- 它配置为增量类型,因此当我们安排的 ELT 作业运行时,系统只会添加新记录
- 如底部的 when() 代码所示,其逻辑基于时间戳字段,该字段反映了事件流中的时间戳,即更改的 event_time
- 它使用 user 字段进行聚类,这意味着每个分区中的记录将按 user 排序,从而减少构建排行榜的查询所需的重排次数。
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
我们需要在项目中定义的另一个表是“报告层级”表,该表支持排行榜查询。报告层中的表是经过汇总的,因为我们的用户关心的是最新、准确的 Wikipedia 更改计数。
表定义简单明了,使用了 Dataform 引用。这些模式的一大优势在于,它们可以明确对象之间的依赖关系,通过确保始终在依赖查询之前执行依赖项来支持流水线的正确性。
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
安排 Dataform 项目
最后一步是创建一个每小时执行的时间表。调用我们的项目时,Dataform 将执行所需的 SQL 语句,以刷新增量暂存表并重新加载汇总表。
系统可每小时(甚至更频繁,最多为每 5-10 分钟)调用此时间表,以根据最近流式传输到系统的事件更新排行榜。
8. 恭喜
恭喜,您已成功为流式传输的数据构建了分层数据架构!
我们从维基媒体事件流开始,并将其转换为始终处于最新状态的 BigQuery 中的报表。
后续操作
深入阅读
[1] 数据工程师通常每天运行一次批量转换,以覆盖当日(例如每小时)的汇总数据(即“对账”)。
[2] 有关实现详情,请参阅“架构”部分。
[3] 迟到事实是指 event_time 晚于系统已经在同一事件流中处理的记录的事件