
1. Wprowadzenie
BigQuery to w pełni zarządzana, ekonomiczna hurtownia danych klasy korporacyjnej, która może obsługiwać petabajty danych i jest przeznaczona do analizy. BigQuery jest usługą bezserwerową. Nie musisz konfigurować klastrów ani nimi zarządzać.
Zbiór danych BigQuery znajduje się w projekcie GCP i zawiera co najmniej jedną tabelę. Możesz wysyłać zapytania SQL dotyczące tych zbiorów danych.
W tym module dowiesz się, jak korzystać z interfejsu internetowego BigQuery w konsoli GCP, aby poznać partycjonowanie i klastrowanie w BigQuery. Partycjonowanie i klastrowanie tabel w BigQuery pomaga w strukturyzacji danych pod kątem typowych wzorców dostępu do danych. Partycjonowanie i klastrowanie to kluczowe elementy, które pozwalają w pełni zmaksymalizować wydajność i zmniejszyć koszty BigQuery podczas wykonywania zapytań w określonym zakresie danych. Dzięki temu każde zapytanie skanuje mniej danych, a przycinanie jest określane przed rozpoczęciem zapytania.
Więcej informacji o BigQuery znajdziesz w dokumentacji BigQuery.
Czego się nauczysz
- Jak tworzyć tabele partycjonowane i klastrowane oraz wykonywać na nich zapytania
- Porównywanie wydajności zapytań w przypadku tabel partycjonowanych i zgrupowanych
Czego potrzebujesz
Do ukończenia modułu potrzebne będą:
- najnowsza wersja Google Chrome;
- Konto rozliczeniowe Google Cloud Platform
2. Przygotowania
Aby korzystać z BigQuery, musisz utworzyć projekt GCP lub wybrać istniejący projekt.
Tworzenie projektu
Aby utworzyć nowy projekt, wykonaj te czynności:
- Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), utwórz je.
- Zaloguj się w konsoli Google Cloud Platform ( console.cloud.google.com) i utwórz nowy projekt.
- Jeśli nie masz żadnych projektów, kliknij przycisk tworzenia projektu:
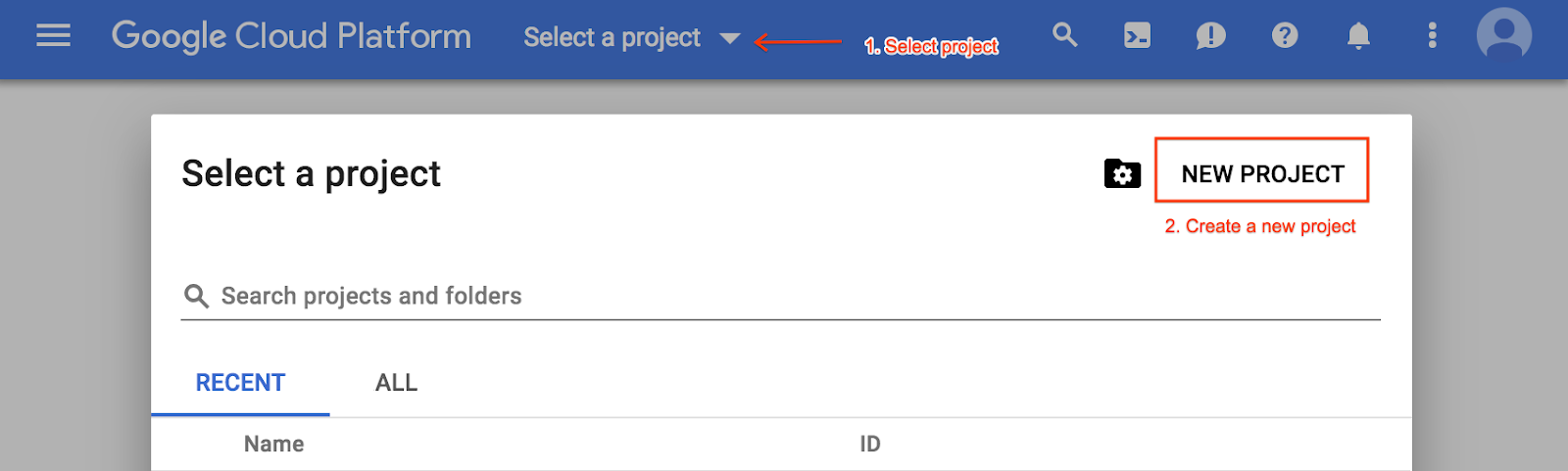
W przeciwnym razie utwórz nowy projekt w menu wyboru projektu:
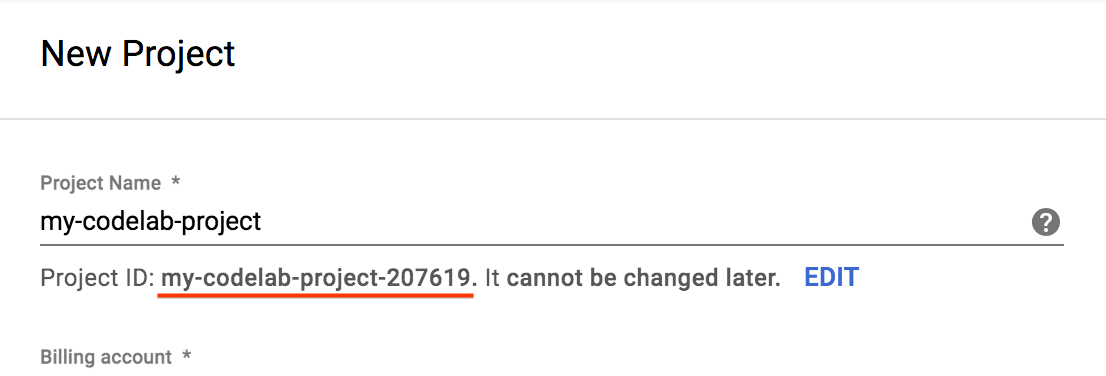
- Wpisz nazwę projektu i kliknij Utwórz. Zwróć uwagę na identyfikator projektu, który jest unikalną nazwą we wszystkich projektach Google Cloud.
3. Praca z publicznymi zbiorami danych
BigQuery umożliwia pracę z publicznymi zbiorami danych, w tym z danymi BBC News, repozytoriami GitHub, Stack Overflow i zbiorami danych amerykańskiej Narodowej Administracji Oceanicznej i Atmosferycznej (NOAA). Nie musisz wczytywać tych zbiorów danych do BigQuery. Wystarczy otworzyć zbiory danych, aby je przeglądać i wysyłać do nich zapytania w BigQuery. W tym ćwiczeniu będziesz pracować z publicznym zbiorem danych Stack Overflow.
Przeglądanie zbioru danych Stack Overflow
Zbiór danych Stack Overflow zawiera informacje o postach, tagach, odznakach, komentarzach, użytkownikach i innych elementach. Aby przejrzeć zbiór danych Stack Overflow w interfejsie internetowym BigQuery, wykonaj te czynności:
- Otwórz zbiór danych Stack Overflow. W konsoli GCP otworzy się interfejs internetowy BigQuery, w którym będą wyświetlane informacje o zbiorze danych Stackoverflow.
- W panelu użytkownika wybierz bigquery-public-data. Menu rozwinie się i wyświetli listę publicznych zbiorów danych. Każdy zbiór danych zawiera co najmniej jedną tabelę.
- Przewiń w dół i wybierz stackoverflow. Menu rozwinie się i wyświetli listę tabel w zbiorze danych Stack Overflow.
- Kliknij badges, aby wyświetlić schemat tabeli plakietek. Zwróć uwagę na nazwy pól w tabeli.
- Nad nazwami pól kliknij Podgląd, aby wyświetlić przykładowe dane w tabeli odznak.
Więcej informacji o wszystkich publicznych zbiorach danych dostępnych w BigQuery znajdziesz w artykule Publiczne zbiory danych Google BigQuery.
Wykonywanie zapytań dotyczących zbioru danych Stackoverflow
Przeglądanie zbioru danych to dobry sposób na poznanie danych, z którymi pracujesz, ale prawdziwą siłą BigQuery jest wykonywanie zapytań dotyczących zbiorów danych. W tej sekcji dowiesz się, jak uruchamiać zapytania BigQuery. W tej chwili nie musisz znać języka SQL. Zapytania możesz skopiować i wkleić poniżej.
Aby uruchomić zapytanie, wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytora zapytań skopiuj i wklej to zapytanie SQL: BigQuery sprawdza zapytanie, a interfejs internetowy wyświetla pod obszarem tekstowym zielony znacznik wyboru, aby wskazać, że składnia jest prawidłowa.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- Kliknij Uruchom. Zapytanie zwraca liczbę postów lub pytań opublikowanych w Stack Overflow w każdym roku.
4. Tworzenie nowej tabeli
W poprzedniej sekcji wysłaliśmy zapytanie do publicznych zbiorów danych udostępnianych przez BigQuery. W tej sekcji utworzysz w BigQuery nową tabelę na podstawie istniejącej tabeli. Utworzysz nową tabelę z danymi pobranymi z tabeli posts_questions publicznego zbioru danych Stack Overflow, a następnie wykonasz na niej zapytanie.
Tworzenie nowego zbioru danych
Aby utworzyć dane tabeli i wczytać je do BigQuery, najpierw utwórz zbiór danych BigQuery, w którym będą przechowywane dane. W tym celu wykonaj te czynności:
- W panelu nawigacyjnym konsoli GCP wybierz nazwę projektu utworzonego w ramach konfiguracji.
- Po prawej stronie w panelu szczegółów kliknij Utwórz zbiór danych.
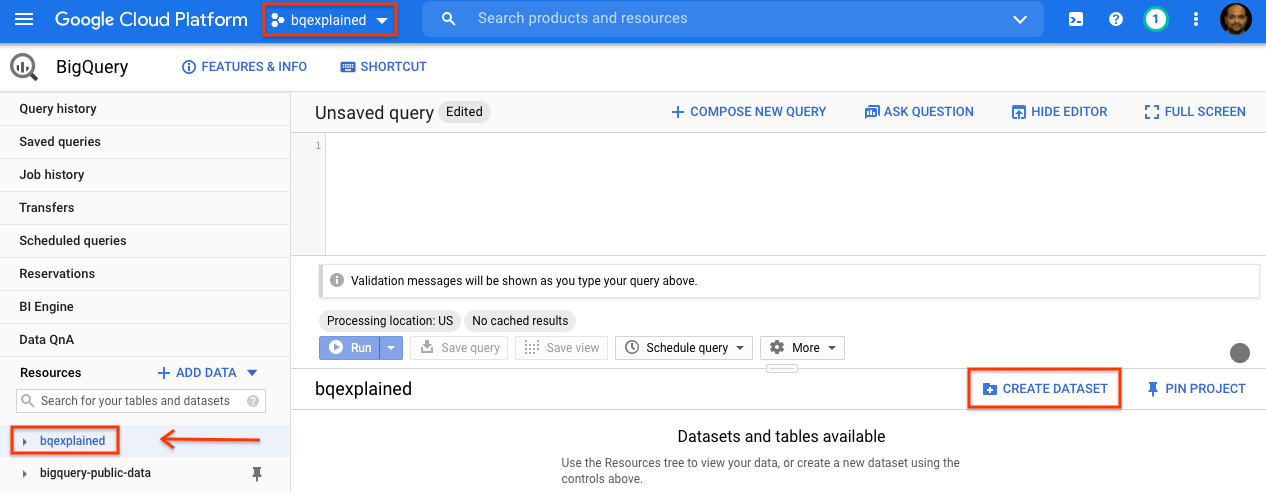
- W oknie Utwórz zbiór danych w polu Identyfikator zbioru danych wpisz
stackoverflow. Pozostaw inne ustawienia domyślne bez zmian i kliknij OK.
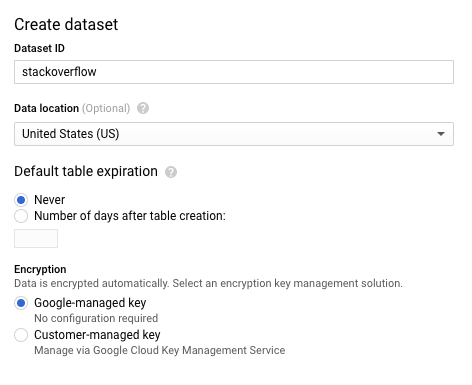
Utwórz nową tabelę z postami z StackOverflow z 2018 roku
Po utworzeniu zbioru danych BigQuery możesz utworzyć w nim nową tabelę. Aby utworzyć tabelę z danymi z istniejącej tabeli, wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.

- W obszarze tekstowym Edytor zapytań skopiuj i wklej to zapytanie SQL, aby utworzyć nową tabelę, która jest instrukcją DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Kliknij Uruchom. Zapytanie tworzy w zbiorze danych
stackoverfloww Twoim projekcie nową tabelęquestions_2018z danymi uzyskanymi w wyniku uruchomienia zapytania w zbiorze danych BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Wykonywanie zapytań w nowej tabeli z postami z 2018 r. z Stack Overflow
Po utworzeniu tabeli BigQuery uruchom zapytanie, które zwróci posty z Stack Overflow zawierające pytania i tytuły oraz kilka innych statystyk, takich jak liczba odpowiedzi, komentarzy, wyświetleń i ulubionych. Wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytora zapytań skopiuj i wklej to zapytanie SQL:
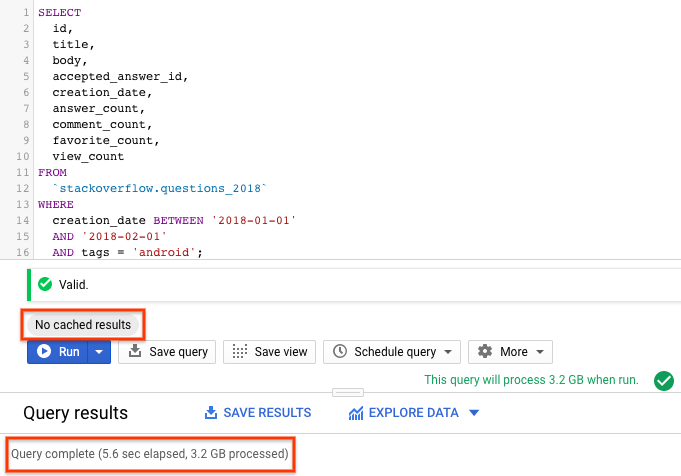
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Kliknij Uruchom. Zapytanie zwraca pytania z Stack Overflow utworzone w styczniu 2018 r., które są oznaczone tagiem
android, wraz z pytaniem i kilkoma innymi statystykami. - Domyślnie BigQuery buforuje wyniki zapytań. Uruchom to samo zapytanie, a zobaczysz, że BigQuery potrzebuje znacznie mniej czasu na zwrócenie wyników, ponieważ pobiera je z pamięci podręcznej.
- Ponownie uruchom to samo zapytanie, ale tym razem z wyłączonym buforowaniem BigQuery. Aby zapewnić uczciwe porównanie wydajności z tabelami podzielonymi na partycje i klastrowanymi, które zostaną uruchomione w następnych sekcjach, wyłączymy pamięć podręczną w pozostałej części laboratorium. W edytorze zapytań kliknij Więcej i wybierz Ustawienia zapytania.
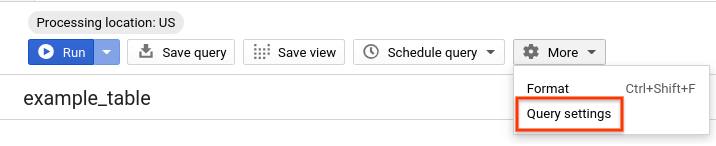
- W sekcji Preferencja pamięci podręcznej odznacz pole Użyj wyników z pamięci podręcznej.
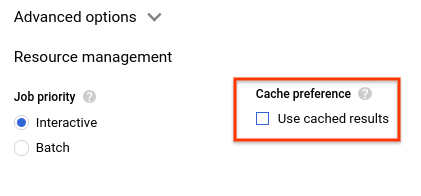
- W wynikach zapytania powinny być widoczne czas wykonania zapytania i ilość danych przetworzonych w celu uzyskania wyników.
5. Tworzenie tabeli partycjonowanej i wysyłanie do niej zapytań
W poprzedniej sekcji utworzyliśmy w BigQuery nową tabelę z danymi z tabeli posts_questions przy użyciu publicznego zbioru danych Stack Overflow. Wykonaliśmy zapytanie do tego zbioru danych z wyłączonym buforowaniem i sprawdziliśmy wydajność zapytania. W tej sekcji utworzysz nową tabelę partycjonowaną z tej samej tabeli posts_questions publicznego zbioru danych Stack Overflow i sprawdzisz wydajność zapytania.
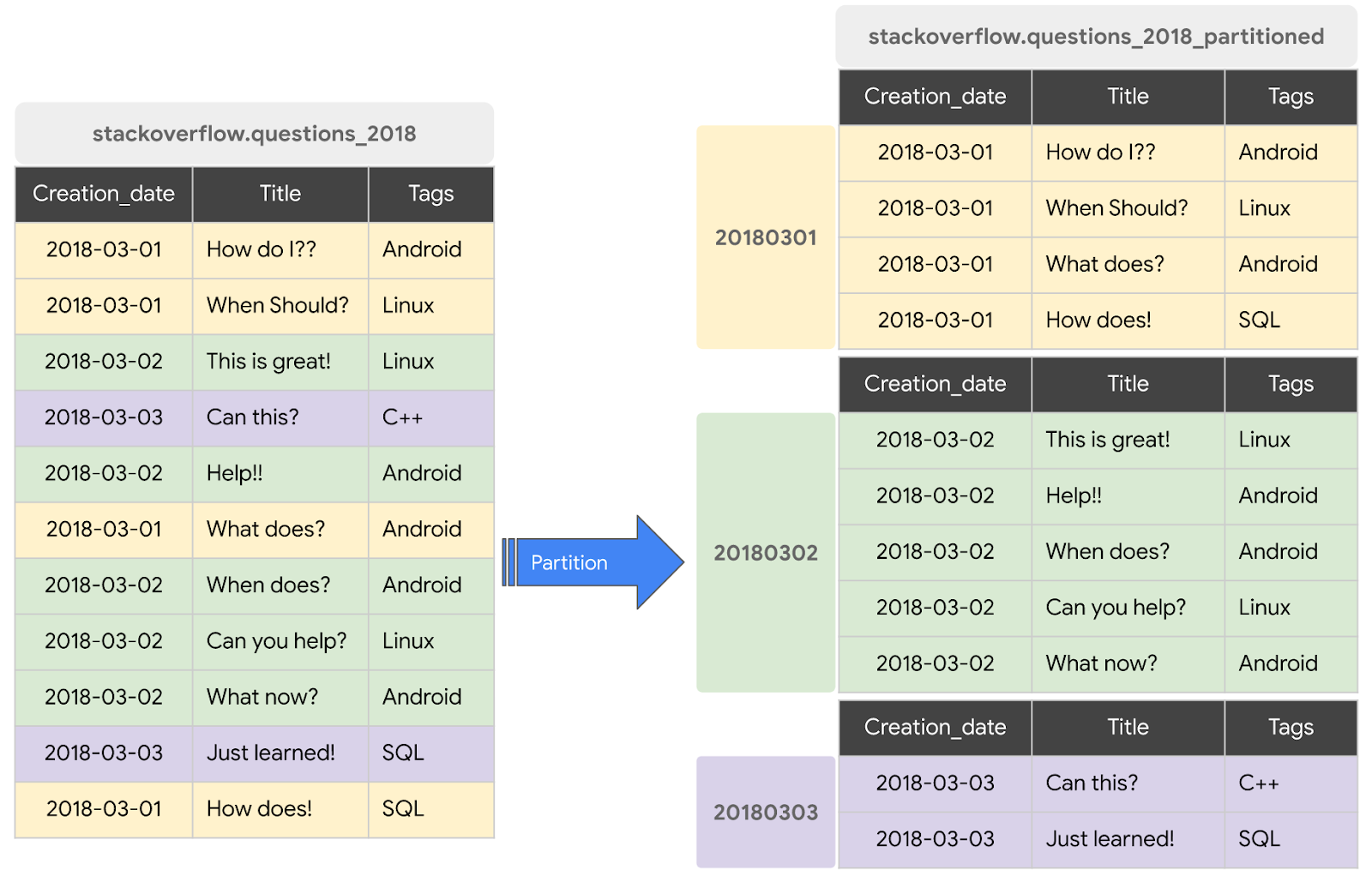
Tabela partycjonowana to specjalna tabela, która jest podzielona na segmenty, czyli partycje, co ułatwia zarządzanie danymi i wykonywanie na nich zapytań. Duże tabele możesz zwykle dzielić na wiele mniejszych partycji, używając czasu pozyskiwania danych, kolumny SYGNATURA CZASOWA/DATA lub kolumny LICZBA CAŁKOWITA. Utworzymy tabelę partycjonowaną według daty.
Więcej informacji o tabelach partycjonowanych znajdziesz tutaj.
Tworzenie nowej tabeli partycjonowanej z postami z StackOverflow z 2018 roku
Aby utworzyć tabelę partycjonowaną z danymi z istniejącej tabeli lub zapytania, wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytor zapytań skopiuj i wklej to zapytanie SQL, aby utworzyć nową tabelę, która jest instrukcją DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Kliknij Uruchom. Zapytanie tworzy nową tabelę
questions_2018_partitionedw zbiorze danychstackoverfloww Twoim projekcie z danymi uzyskanymi w wyniku uruchomienia zapytania w zbiorze danych BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Wysyłanie zapytań do tabeli podzielonej na partycje z postami z 2018 r. z Stack Overflow
Po utworzeniu partycjonowanej tabeli BigQuery uruchommy to samo zapytanie, tym razem w partycjonowanej tabeli, aby zwrócić posty z Stack Overflow zawierające pytania i tytuły oraz kilka innych statystyk, takich jak liczba odpowiedzi, komentarzy, wyświetleń i ulubionych. Wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytora zapytań skopiuj i wklej to zapytanie SQL:
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Wybierz Uruchom z wyłączonym buforowaniem BigQuery (informacje o wyłączaniu pamięci podręcznej BigQuery znajdziesz w poprzedniej sekcji). Zapytanie zwraca pytania z Stack Overflow utworzone w styczniu 2018 r., które są oznaczone tagiem
android, wraz z pytaniem i kilkoma innymi statystykami. - W wynikach zapytania powinny być widoczne czas wykonania zapytania i ilość danych przetworzonych w celu uzyskania wyników.
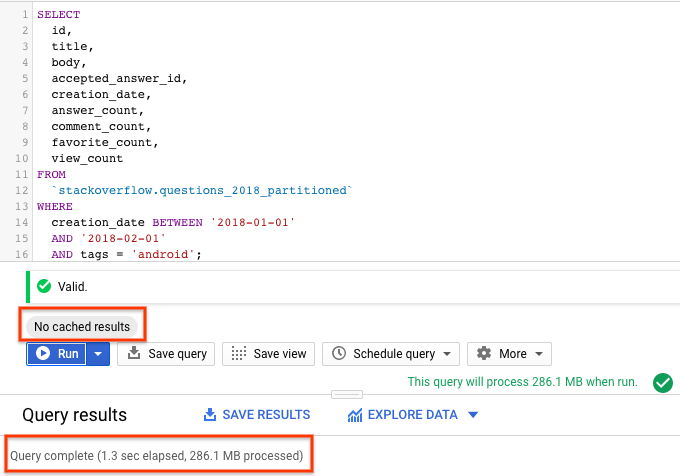
Powinna być widoczna lepsza wydajność zapytania z tabelą partycjonowaną niż z tabelą niepodzieloną na partycje, ponieważ BigQuery przycina partycje, czyli skanuje tylko wymagane partycje, przetwarzając mniej danych i działając szybciej. Pozwala to zoptymalizować koszty i wydajność zapytań.
6. Tworzenie tabeli klastrowej i wykonywanie na niej zapytań
W poprzedniej sekcji utworzyliśmy w BigQuery tabelę partycjonowaną z danymi z tabeli posts_questions w publicznym zbiorze danych Stack Overflow. Wyszukaliśmy dane w tej tabeli z wyłączonym buforowaniem i sprawdziliśmy wydajność zapytań w przypadku tabel niepartycjonowanych i partycjonowanych. W tej sekcji utworzysz nową tabelę pogrupowaną z tej samej tabeli posts_questions publicznego zbioru danych Stack Overflow i sprawdzisz skuteczność zapytania.
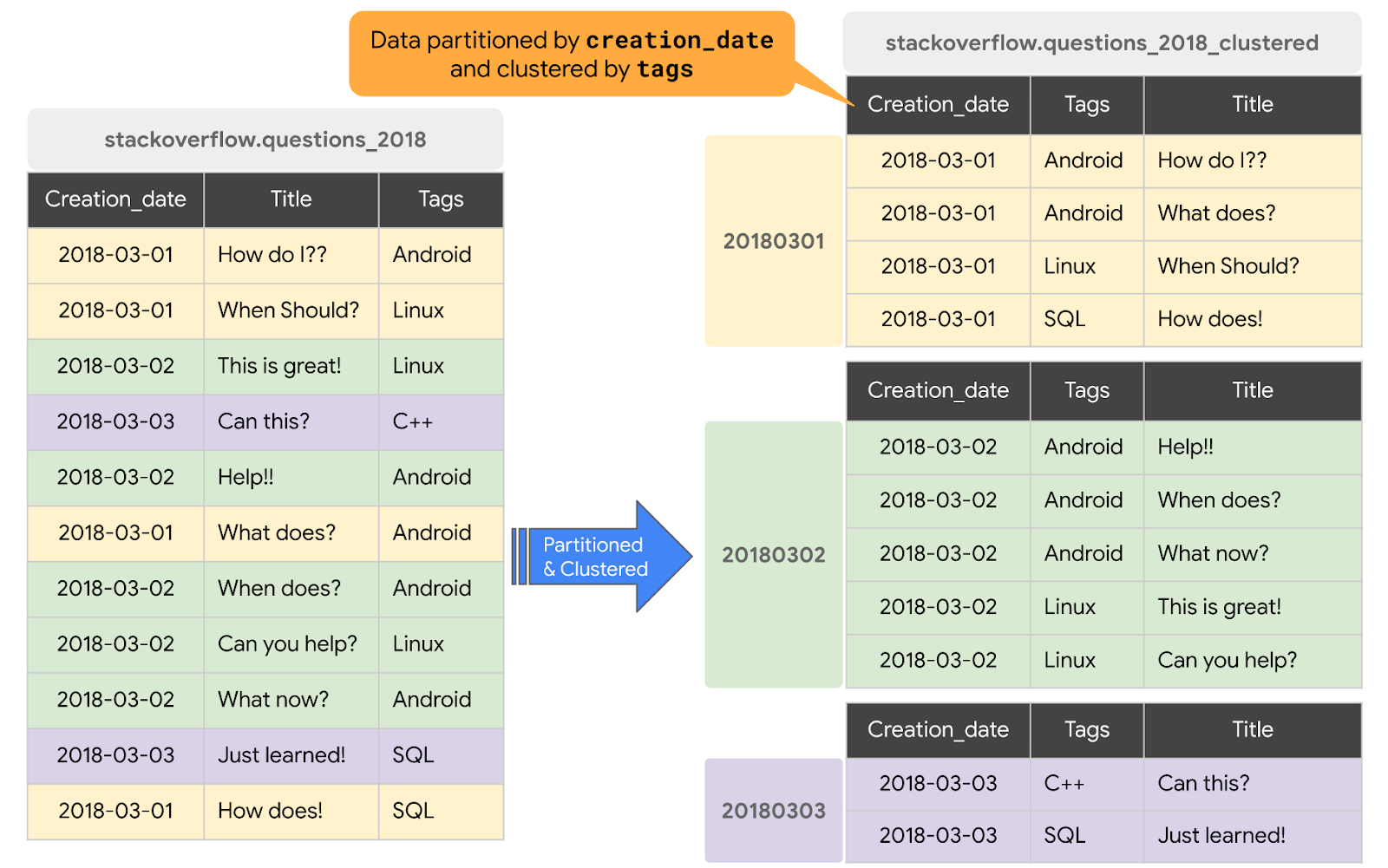
Gdy tabela jest klastrowana w BigQuery, dane tabeli są automatycznie porządkowane na podstawie zawartości co najmniej 1 kolumny w schemacie tabeli. Określone przez Ciebie kolumny służą do kolokacji powiązanych danych. Gdy dane są zapisywane w tabeli pogrupowanej, BigQuery sortuje je według wartości w kolumnach klastrowania. Te wartości służą do porządkowania danych w wielu blokach w pamięci BigQuery. Kolejność kolumn klastrowych określa kolejność sortowania danych. Gdy do tabeli lub konkretnej partycji zostaną dodane nowe dane, BigQuery automatycznie przeprowadzi w tle ponowne klastrowanie, aby przywrócić właściwość sortowania tabeli lub partycji.
Więcej informacji o pracy z tabelami pogrupowanymi znajdziesz tutaj.
Tworzenie nowej tabeli klastrowej z postami z 2018 roku z Stack Overflow
W tej sekcji utworzysz nową tabelę partycjonowaną według kolumny creation_date i klastrowaną według kolumny tags na podstawie wzorca dostępu do zapytań. Aby utworzyć tabelę pogrupowaną z danymi z istniejącej tabeli lub zapytania, wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytor zapytań skopiuj i wklej to zapytanie SQL, aby utworzyć nową tabelę, która jest instrukcją DDL.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Wybierz Uruchom. Zapytanie tworzy nową tabelę
questions_2018_clusteredw zbiorze danychstackoverfloww projekcie z danymi uzyskanymi w wyniku uruchomienia zapytania w tabeli BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions. Nowa tabela jest partycjonowana według kolumny creation_date i klastrowana według kolumny tags.
Wysyłanie zapytań do tabeli klastrowanej z postami z Stack Overflow z 2018 roku
Po utworzeniu tabeli pogrupowanej BigQuery ponownie uruchomimy to samo zapytanie, tym razem w tabeli podzielonej na partycje i pogrupowanej, aby zwrócić posty z Stack Overflow zawierające pytania i tytuły wraz z kilkoma innymi statystykami, takimi jak liczba odpowiedzi, komentarzy, wyświetleń i ulubionych. Wykonaj te czynności:
- W prawym górnym rogu konsoli GCP kliknij Utwórz nowe zapytanie.
- W obszarze tekstowym Edytora zapytań skopiuj i wklej to zapytanie SQL:
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Wybierz Uruchom z wyłączonym buforowaniem BigQuery (informacje o wyłączaniu pamięci podręcznej BigQuery znajdziesz w poprzedniej sekcji). Zapytanie zwraca pytania z Stack Overflow utworzone w styczniu 2018 r., które są oznaczone tagiem
android, wraz z pytaniem i kilkoma innymi statystykami. - W wynikach zapytania powinny być widoczne czas wykonania zapytania i ilość danych przetworzonych w celu uzyskania wyników.
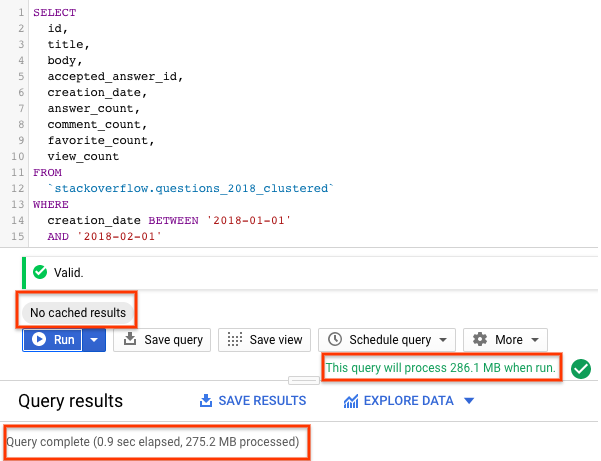
W przypadku tabeli partycjonowanej i pogrupowanej zapytanie skanowało mniej danych niż w przypadku tabeli partycjonowanej lub niepartycjonowanej. Sposób organizacji danych przez partycjonowanie i grupowanie minimalizuje ilość danych skanowanych przez instancje robocze, co zwiększa wydajność zapytań i optymalizuje koszty.
7. Czyszczę dane
Jeśli nie planujesz dalszej pracy ze zbiorem danych stackoverflow, usuń go i usuń projekt utworzony na potrzeby tego laboratorium.
Usuwanie zbioru danych BigQuery
Aby usunąć zbiór danych BigQuery, wykonaj te czynności:
- W panelu użytkownika po lewej stronie w BigQuery wybierz zbiór danych stackoverflow .
- W panelu szczegółów kliknij Usuń zbiór danych.
- W oknie Usuń zbiór danych wpisz stackoverflow i kliknij Usuń, aby potwierdzić, że chcesz usunąć zbiór danych.
Usuwanie projektu
Aby usunąć projekt GCP utworzony na potrzeby tego laboratorium, wykonaj te czynności:
- W menu nawigacyjnym GCP wybierz Uprawnienia i administracja.
- W panelu użytkownika kliknij Ustawienia.
- W panelu szczegółów sprawdź, czy bieżący projekt to projekt utworzony na potrzeby tego laboratorium, i kliknij Wyłącz.
- W oknie Wyłącz projekt wpisz identyfikator projektu (nie nazwę projektu) i kliknij Wyłącz, aby potwierdzić.
Gratulacje! Wiesz już,
- Jak utworzyć nową tabelę na podstawie istniejących tabel za pomocą interfejsu internetowego BigQuery
- Jak tworzyć tabele partycjonowane i klastrowane oraz wykonywać na nich zapytania
- Jak partycjonowanie i grupowanie optymalizuje wydajność zapytań i koszty
Pamiętaj, że aby pracować ze zbiorami danych, nie musisz konfigurować klastrów ani nimi zarządzać.