
1. Introducción
En este codelab, se aborda el modelo de lenguaje grande (LLM) Gemini, alojado en Vertex AI en Google Cloud. Vertex AI es una plataforma que abarca todos los productos, servicios y modelos de aprendizaje automático en Google Cloud.
Usarás Java para interactuar con la API de Gemini a través del framework de LangChain4j. Verás ejemplos concretos para aprovechar el LLM en la respuesta de preguntas, la generación de ideas, la extracción de entidades y contenido estructurado, la generación mejorada por recuperación y las llamadas a funciones.
¿Qué es la IA generativa?
La IA generativa se refiere al uso de la inteligencia artificial para crear contenido nuevo, como texto, imágenes, música, audio y videos.
La IA generativa usa modelos de lenguaje grandes (LLM) que pueden realizar varias tareas a la vez y de manera predeterminada, como resúmenes, preguntas y respuestas, clasificación y mucho más. Con un entrenamiento mínimo, los modelos de base se pueden adaptar a casos de uso segmentados con muy pocos datos de ejemplo.
¿Cómo funciona la IA generativa?
La IA generativa usa un modelo de aprendizaje automático (AA) para aprender los patrones y las relaciones en un conjunto de datos de contenido creado por humanos. Luego, usa los patrones aprendidos para generar contenido nuevo.
La forma más común de entrenar un modelo de IA generativa es usar el aprendizaje supervisado. El modelo recibe un conjunto de contenido creado por humanos y las etiquetas correspondientes. Luego, aprende a generar contenido similar al creado por humanos.
¿Cuáles son las aplicaciones comunes de la IA generativa?
Estos son algunos usos de la IA generativa:
- Mejorar las interacciones con los clientes a través de experiencias de chat y búsqueda mejoradas
- Explorar grandes cantidades de datos no estructurados a través de interfaces y resúmenes coloquiales
- Ayudar con tareas repetitivas, como responder solicitudes de propuestas, localizar contenido de marketing en diferentes idiomas y verificar los contratos de los clientes para garantizar el cumplimiento, entre otras.
¿Qué ofertas de IA generativa tiene Google Cloud?
Con Vertex AI, puedes interactuar con modelos de base, incorporarlos en tus aplicaciones y personalizarlos sin necesidad de tener experiencia en AA. Puedes acceder a los modelos de base en Model Garden, ajustar los modelos con una IU simple en Vertex AI Studio o usar modelos en un notebook de ciencia de datos.
Vertex AI Search and Conversation ofrece a los desarrolladores la forma más rápida de compilar motores de búsqueda y chatbots con tecnología de IA generativa.
Gemini para Google Cloud, potenciado por Gemini, es un colaborador potenciado por IA disponible en Google Cloud y en los IDE para ayudarte a realizar más tareas con mayor rapidez. Gemini Code Assist proporciona completado de código, generación de código, explicaciones de código y te permite chatear con él para hacer preguntas técnicas.
¿Qué es Gemini?
Gemini es una familia de modelos de IA generativa que desarrolló Google DeepMind y que están diseñados para casos de uso multimodales. Multimodal significa que puede procesar y generar diferentes tipos de contenido, como texto, código, imágenes y audio.

Gemini viene en diferentes variaciones y tamaños:
- Gemini 2.0 Flash: Nuestras funciones de última generación más recientes y capacidades mejoradas.
- Gemini 2.0 Flash-Lite: Es un modelo de Gemini 2.0 Flash optimizado para ser rentable y tener una baja latencia.
- Gemini 2.5 Pro: Nuestro modelo de razonamiento más avanzado hasta la fecha.
- Gemini 2.5 Flash: Es un modelo de razonamiento que ofrece capacidades integrales. Está diseñado para ofrecer un equilibrio entre precio y rendimiento.
Funciones clave:
- Multimodalidad: La capacidad de Gemini para comprender y manejar múltiples formatos de información es un paso significativo más allá de los modelos de lenguaje tradicionales basados solo en texto.
- Rendimiento: Gemini 2.5 Pro supera el estado del arte actual en muchas comparativas y fue el primer modelo en superar a los expertos humanos en la desafiante comparativa MMLU (Massive Multitask Language Understanding).
- Flexibilidad: Los diferentes tamaños de Gemini lo hacen adaptable a varios casos de uso, desde la investigación a gran escala hasta la implementación en dispositivos móviles.
¿Cómo puedes interactuar con Gemini en Vertex AI desde Java?
Tienes estas dos opciones:
- Biblioteca oficial de la API de Vertex AI Java para Gemini
- El framework de LangChain4j
En este codelab, usarás el framework de LangChain4j.
¿Qué es el framework LangChain4j?
El framework LangChain4j es una biblioteca de código abierto para integrar LLM en tus aplicaciones de Java, ya que organiza varios componentes, como el LLM en sí, pero también otras herramientas, como bases de datos vectoriales (para búsquedas semánticas), cargadores y divisores de documentos (para analizar documentos y aprender de ellos), analizadores de resultados y mucho más.
El proyecto se inspiró en el proyecto de Python LangChain, pero con el objetivo de servir a los desarrolladores de Java.

Qué aprenderás
- Cómo configurar un proyecto de Java para usar Gemini y LangChain4j
- Cómo enviar tu primera instrucción a Gemini de forma programática
- Cómo transmitir respuestas de Gemini
- Cómo crear una conversación entre un usuario y Gemini
- Cómo usar Gemini en un contexto multimodal enviando texto e imágenes
- Cómo extraer información estructurada útil del contenido no estructurado
- Cómo manipular plantillas de instrucciones
- Cómo realizar la clasificación de texto, como el análisis de opiniones
- Cómo chatear con tus propios documentos (generación mejorada por recuperación)
- Cómo extender tus chatbots con llamadas a funciones
- Cómo usar Gemma de forma local con Ollama y TestContainers
Requisitos
- Conocimiento del lenguaje de programación Java
- Un proyecto de Google Cloud
- Un navegador, como Chrome o Firefox
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.


- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud se puede operar de manera remota desde tu laptop, en este codelab usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Activar Cloud Shell
- En la consola de Cloud, haz clic en Activar Cloud Shell
 .
.

Si es la primera vez que inicias Cloud Shell, aparecerá una pantalla intermedia en la que se describirá qué es. Si apareció una pantalla intermedia, haz clic en Continuar.

El aprovisionamiento y la conexión a Cloud Shell solo tomará unos minutos.

Esta máquina virtual está cargada con todas las herramientas de desarrollo necesarias. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de tu trabajo en este codelab, si no todo, se puede hacer con un navegador.
Una vez que te conectes a Cloud Shell, deberías ver que te autenticaste y que el proyecto se configuró con tu ID del proyecto.
- En Cloud Shell, ejecuta el siguiente comando para confirmar que tienes la autenticación:
gcloud auth list
Resultado del comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto:
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
3. Cómo preparar tu entorno de desarrollo
En este codelab, usarás la terminal y el editor de Cloud Shell para desarrollar tus programas en Java.
Habilita las APIs de Vertex AI
En la consola de Google Cloud, asegúrate de que el nombre del proyecto se muestre en la parte superior de la consola de Google Cloud. Si no es así, haz clic en Selecciona un proyecto para abrir el Selector de proyectos y selecciona el proyecto que desees.
Puedes habilitar las APIs de Vertex AI desde la sección Vertex AI de la consola de Google Cloud o desde la terminal de Cloud Shell.
Para habilitar la API desde la consola de Google Cloud, primero ve a la sección Vertex AI del menú de la consola de Google Cloud:

Haz clic en Habilitar todas las APIs recomendadas en el panel de Vertex AI.
Esto habilitará varias APIs, pero la más importante para el codelab es la aiplatform.googleapis.com.
Como alternativa, también puedes habilitar esta API desde la terminal de Cloud Shell con el siguiente comando:
gcloud services enable aiplatform.googleapis.com
Clona el repositorio de GitHub
En la terminal de Cloud Shell, clona el repositorio de este codelab:
git clone https://github.com/glaforge/gemini-workshop-for-java-developers.git
Para verificar que el proyecto esté listo para ejecutarse, puedes intentar ejecutar el programa "Hello World".
Asegúrate de estar en la carpeta de nivel superior:
cd gemini-workshop-for-java-developers/
Crea el wrapper de Gradle:
gradle wrapper
Ejecuta con gradlew:
./gradlew run
Deberías ver el siguiente resultado:
.. > Task :app:run Hello World!
Abre y configura Cloud Editor
Abre el código con el editor de Cloud Code desde Cloud Shell:

En el editor de Cloud Code, abre la carpeta de origen del codelab seleccionando File -> Open Folder y apunta a la carpeta de origen del codelab (p. ej., /home/username/gemini-workshop-for-java-developers/).
Configura variables de entorno
Para abrir una terminal nueva en el editor de Cloud Code, selecciona Terminal -> New Terminal. Configura dos variables de entorno necesarias para ejecutar los ejemplos de código:
- PROJECT_ID: Es el ID de tu proyecto de Google Cloud.
- LOCATION: Es la región en la que se implementa el modelo de Gemini.
Exporta las variables de la siguiente manera:
export PROJECT_ID=$(gcloud config get-value project) export LOCATION=us-central1
4. Primera llamada al modelo de Gemini
Ahora que el proyecto está configurado correctamente, es momento de llamar a la API de Gemini.
Observa QA.java en el directorio app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class QA {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
System.out.println(model.generate("Why is the sky blue?"));
}
}
En este primer ejemplo, debes importar la clase VertexAiGeminiChatModel, que implementa la interfaz ChatModel.
En el método main, configura el modelo de lenguaje de chat con el compilador de VertexAiGeminiChatModel y especifica lo siguiente:
- Proyecto
- Ubicación
- Nombre del modelo (
gemini-2.0-flash).
Ahora que el modelo de lenguaje está listo, puedes llamar al método generate() y pasar tu instrucción, pregunta o instrucciones para enviarlas al LLM. Aquí, haces una pregunta sencilla sobre por qué el cielo es azul.
Puedes cambiar esta instrucción para probar diferentes preguntas o tareas.
Ejecuta la muestra en la carpeta raíz del código fuente:
./gradlew run -q -DjavaMainClass=gemini.workshop.QA
Deberías ver un resultado similar al siguiente:
The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight enters the atmosphere, it is made up of a mixture of different wavelengths of light, each with a different color. The different wavelengths of light interact with the molecules and particles in the atmosphere in different ways. The shorter wavelengths of light, such as those corresponding to blue and violet light, are more likely to be scattered in all directions by these particles than the longer wavelengths of light, such as those corresponding to red and orange light. This is because the shorter wavelengths of light have a smaller wavelength and are able to bend around the particles more easily. As a result of Rayleigh scattering, the blue light from the sun is scattered in all directions, and it is this scattered blue light that we see when we look up at the sky. The blue light from the sun is not actually scattered in a single direction, so the color of the sky can vary depending on the position of the sun in the sky and the amount of dust and water droplets in the atmosphere.
¡Felicitaciones! Acabas de hacer tu primera llamada a Gemini.
Respuesta de transmisión
¿Notaste que la respuesta se dio de una sola vez, después de unos segundos? También es posible obtener la respuesta de forma progresiva gracias a la variante de respuesta de transmisión. Es la respuesta de transmisión. El modelo devuelve la respuesta fragmento por fragmento a medida que está disponible.
En este codelab, nos quedaremos con la respuesta que no es de transmisión, pero veamos la respuesta de transmisión para ver cómo se puede hacer.
En StreamQA.java en el directorio app/src/main/java/gemini/workshop, puedes ver la respuesta de transmisión en acción:
package gemini.workshop;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiStreamingChatModel;
import static dev.langchain4j.model.LambdaStreamingResponseHandler.onNext;
public class StreamQA {
public static void main(String[] args) {
StreamingChatLanguageModel model = VertexAiGeminiStreamingChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(4000)
.build();
model.generate("Why is the sky blue?", onNext(System.out::println));
}
}
Esta vez, importamos las variantes de la clase de transmisión VertexAiGeminiStreamingChatModel, que implementa la interfaz StreamingChatLanguageModel. También deberás importar de forma estática LambdaStreamingResponseHandler.onNext, que es un método conveniente que proporciona StreamingResponseHandlers para crear un controlador de transmisión con expresiones lambda de Java.
Esta vez, la firma del método generate() es un poco diferente. En lugar de devolver una cadena, el tipo de datos que se devuelve es void. Además de la instrucción, debes pasar un controlador de respuestas de transmisión. Aquí, gracias a la importación estática que mencionamos anteriormente, podemos definir una expresión lambda que se pasa al método onNext(). Se llama a la expresión lambda cada vez que hay disponible una nueva parte de la respuesta, mientras que a la segunda solo se la llama si alguna vez ocurre un error.
Ejecución:
./gradlew run -q -DjavaMainClass=gemini.workshop.StreamQA
Obtendrás una respuesta similar a la de la clase anterior, pero, esta vez, notarás que la respuesta aparece progresivamente en tu shell, en lugar de esperar a que se muestre la respuesta completa.
Configuración adicional
Para la configuración, solo definimos el proyecto, la ubicación y el nombre del modelo, pero hay otros parámetros que puedes especificar para el modelo:
temperature(Float temp): Para definir qué tan creativa quieres que sea la respuesta (0 es poco creativa y, a menudo, más fáctica, mientras que 2 es para resultados más creativos)topP(Float topP): Para seleccionar las palabras posibles cuya probabilidad total sume ese número de punto flotante (entre 0 y 1)topK(Integer topK): Para seleccionar aleatoriamente una palabra entre una cantidad máxima de palabras probables para la finalización de texto (de 1 a 40)maxOutputTokens(Integer max): Para especificar la longitud máxima de la respuesta que proporciona el modelo (en general, 4 tokens representan aproximadamente 3 palabras)maxRetries(Integer retries): En caso de que superes la cuota de solicitudes por período o la plataforma tenga algún problema técnico, puedes hacer que el modelo vuelva a intentar la llamada 3 veces.
Hasta ahora, le hiciste una sola pregunta a Gemini, pero también puedes tener una conversación de varios turnos. Eso es lo que explorarás en la siguiente sección.
5. Chatea con Gemini
En el paso anterior, hiciste una sola pregunta. Ahora es el momento de tener una conversación real entre un usuario y el LLM. Cada pregunta y respuesta puede basarse en las anteriores para formar una conversación real.
Consulta Conversation.java en la carpeta app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.service.AiServices;
import java.util.List;
public class Conversation {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
interface ConversationService {
String chat(String message);
}
ConversationService conversation =
AiServices.builder(ConversationService.class)
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
List.of(
"Hello!",
"What is the country where the Eiffel tower is situated?",
"How many inhabitants are there in that country?"
).forEach( message -> {
System.out.println("\nUser: " + message);
System.out.println("Gemini: " + conversation.chat(message));
});
}
}
En esta clase, se incluyen un par de importaciones nuevas interesantes:
MessageWindowChatMemory: Una clase que ayudará a controlar el aspecto de varios turnos de la conversación y a mantener en la memoria local las preguntas y respuestas anterioresAiServices: Es una clase de abstracción de nivel superior que vinculará el modelo de chat y la memoria de chat.
En el método principal, configurarás el modelo, la memoria de chat y el servicio de IA. El modelo se configura como de costumbre con la información del proyecto, la ubicación y el nombre del modelo.
Para la memoria del chat, usamos el compilador de MessageWindowChatMemory para crear una memoria que conserve los últimos 20 mensajes intercambiados. Es una ventana deslizante sobre la conversación cuyo contexto se mantiene de forma local en nuestro cliente de clase Java.
Luego, crea el AI service que vincula el modelo de chat con la memoria de chat.
Observa cómo el servicio de IA usa una interfaz ConversationService personalizada que definimos, que LangChain4j implementa y que toma una consulta String y devuelve una respuesta String.
Ahora es el momento de conversar con Gemini. Primero, se envía un saludo simple y, luego, una primera pregunta sobre la Torre Eiffel para saber en qué país se encuentra. Observa que la última oración se relaciona con la respuesta de la primera pregunta, ya que te preguntas cuántos habitantes hay en el país donde se encuentra la Torre Eiffel, sin mencionar explícitamente el país que se proporcionó en la respuesta anterior. Muestra que las preguntas y respuestas anteriores se envían con cada instrucción.
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.Conversation
Deberías ver tres respuestas similares a estas:
User: Hello! Gemini: Hi there! How can I assist you today? User: What is the country where the Eiffel tower is situated? Gemini: France User: How many inhabitants are there in that country? Gemini: As of 2023, the population of France is estimated to be around 67.8 million.
Puedes hacer preguntas de un solo turno o tener conversaciones de varios turnos con Gemini, pero, hasta ahora, la entrada solo ha sido texto. ¿Qué sucede con las imágenes? Exploremos las imágenes en el siguiente paso.
6. Multimodalidad con Gemini
Gemini es un modelo multimodal. No solo acepta texto como entrada, sino también imágenes o incluso videos. En esta sección, verás un caso de uso para combinar texto e imágenes.
¿Crees que Gemini reconocerá a este gato?

Imagen de un gato en la nieve tomada de Wikipedia
Echa un vistazo a Multimodal.java en el directorio app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.data.message.ImageContent;
import dev.langchain4j.data.message.TextContent;
public class Multimodal {
static final String CAT_IMAGE_URL =
"https://upload.wikimedia.org/wikipedia/" +
"commons/b/b6/Felis_catus-cat_on_snow.jpg";
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
UserMessage userMessage = UserMessage.from(
ImageContent.from(CAT_IMAGE_URL),
TextContent.from("Describe the picture")
);
Response<AiMessage> response = model.generate(userMessage);
System.out.println(response.content().text());
}
}
En las importaciones, observa que distinguimos entre diferentes tipos de mensajes y contenidos. Un UserMessage puede contener un objeto TextContent y un objeto ImageContent. Esto es multimodalidad en acción: combinar texto e imágenes. No solo enviamos una cadena de instrucción simple, sino que enviamos un objeto más estructurado que representa un mensaje del usuario, compuesto por una parte de contenido de imagen y una parte de contenido de texto. El modelo envía un Response que contiene un AiMessage.
Luego, recuperas el AiMessage de la respuesta a través de content() y, luego, el texto del mensaje gracias a text().
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.Multimodal
El nombre de la imagen ciertamente te dio una pista de lo que contenía, pero el resultado de Gemini es similar al siguiente:
A cat with brown fur is walking in the snow. The cat has a white patch of fur on its chest and white paws. The cat is looking at the camera.
La combinación de imágenes y texto en las instrucciones abre casos de uso interesantes. Puedes crear aplicaciones que realicen las siguientes acciones:
- Reconoce texto en imágenes.
- Comprueba si una imagen es segura para mostrar.
- Crear leyendas de imágenes
- Buscar en una base de datos de imágenes con descripciones de texto sin formato
Además de extraer información de imágenes, también puedes extraer información de texto no estructurado. Eso es lo que aprenderás en la siguiente sección.
7. Extrae información estructurada de texto no estructurado
Hay muchas situaciones en las que se proporciona información importante en documentos de informes, correos electrónicos o textos largos de otro tipo de forma no estructurada. Lo ideal sería poder extraer los detalles clave que contiene el texto no estructurado en forma de objetos estructurados. Veamos cómo puedes hacerlo.
Supongamos que deseas extraer el nombre y la edad de una persona a partir de una biografía, un CV o una descripción de esa persona. Puedes indicarle al LLM que extraiga JSON de texto no estructurado con una instrucción ingeniosamente modificada (esto se conoce comúnmente como "ingeniería de instrucciones").
Sin embargo, en el siguiente ejemplo, en lugar de crear una instrucción que describa el resultado JSON, usaremos una potente función de Gemini llamada resultado estructurado, o a veces generación restringida, que obliga al modelo a generar solo contenido JSON válido, siguiendo un esquema JSON especificado.
Echa un vistazo a ExtractData.java en app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import static dev.langchain4j.model.vertexai.SchemaHelper.fromClass;
public class ExtractData {
record Person(String name, int age) { }
interface PersonExtractor {
@SystemMessage("""
Your role is to extract the name and age
of the person described in the biography.
""")
Person extractPerson(String biography);
}
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.responseMimeType("application/json")
.responseSchema(fromClass(Person.class))
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
String bio = """
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
""";
Person person = extractor.extractPerson(bio);
System.out.println(person.name()); // Anna
System.out.println(person.age()); // 23
}
}
Veamos los distintos pasos de este archivo:
- Se define un registro
Personpara representar los detalles que describen a una persona (nombre y edad). - La interfaz
PersonExtractorse define con un método que, dada una cadena de texto no estructurada, devuelve una instancia dePerson. - El
extractPerson()se anota con una anotación@SystemMessageque asocia una instrucción con él. Esa es la instrucción que usará el modelo para guiar su extracción de la información y devolver los detalles en forma de un documento JSON, que se analizará y se deserializará en una instancia dePerson.
Ahora veamos el contenido del método main():
- El modelo de chat se configura y se crea una instancia. Usamos 2 métodos nuevos de la clase del compilador de modelos:
responseMimeType()yresponseSchema(). El primero le indica a Gemini que genere un JSON válido en el resultado. El segundo método define el esquema del objeto JSON que se debe devolver. Además, este último delega en un método de conveniencia que puede convertir una clase o un registro de Java en un esquema JSON adecuado. - Se crea un objeto
PersonExtractorgracias a la claseAiServicesde LangChain4j. - Luego, puedes llamar a
Person person = extractor.extractPerson(...)para extraer los detalles de la persona del texto no estructurado y obtener una instancia dePersoncon el nombre y la edad.
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.ExtractData
Deberías ver el siguiente resultado:
Anna 23
Sí, ella es Anna y tiene 23 años.
Con este enfoque de AiServices, trabajas con objetos con escritura segura. No interactúas directamente con el LLM. En cambio, trabajas con clases concretas, como el registro Person para representar la información personal extraída, y tienes un objeto PersonExtractor con un método extractPerson() que devuelve una instancia Person. La noción de LLM se abstrae y, como desarrollador de Java, solo manipulas clases y objetos normales cuando usas esta interfaz PersonExtractor.
8. Estructura instrucciones con plantillas de instrucciones
Cuando interactúas con un LLM usando un conjunto común de instrucciones o preguntas, hay una parte de esa instrucción que nunca cambia, mientras que otras partes contienen los datos. Por ejemplo, si quieres crear recetas, puedes usar una instrucción como "Eres un chef talentoso. Crea una receta con los siguientes ingredientes:…" y, luego, agregar los ingredientes al final de ese texto. Para eso sirven las plantillas de instrucciones, que son similares a las cadenas interpoladas en los lenguajes de programación. Una plantilla de instrucción contiene marcadores de posición que puedes reemplazar por los datos correctos para una llamada específica al LLM.
De manera más concreta, estudiemos TemplatePrompt.java en el directorio app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.output.Response;
import java.util.HashMap;
import java.util.Map;
public class TemplatePrompt {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(500)
.temperature(1.0f)
.topK(40)
.topP(0.95f)
.maxRetries(3)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
You're a friendly chef with a lot of cooking experience.
Create a recipe for a {{dish}} with the following ingredients: \
{{ingredients}}, and give it a name.
"""
);
Map<String, Object> variables = new HashMap<>();
variables.put("dish", "dessert");
variables.put("ingredients", "strawberries, chocolate, and whipped cream");
Prompt prompt = promptTemplate.apply(variables);
Response<AiMessage> response = model.generate(prompt.toUserMessage());
System.out.println(response.content().text());
}
}
Como de costumbre, configuras el modelo VertexAiGeminiChatModel con un alto nivel de creatividad, una temperatura alta y valores altos de topP y topK. Luego, creas un PromptTemplate con su método estático from(), pasando la cadena de nuestra instrucción, y usas las variables de marcador de posición con doble llave: {{dish}} y {{ingredients}}.
Para crear la instrucción final, llama a apply(), que toma un mapa de pares clave-valor que representan el nombre del marcador de posición y el valor de cadena con el que se reemplazará.
Por último, llamas al método generate() del modelo de Gemini creando un mensaje del usuario a partir de esa instrucción, con la instrucción prompt.toUserMessage().
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.TemplatePrompt
Deberías ver un resultado generado similar a este:
**Strawberry Shortcake** Ingredients: * 1 pint strawberries, hulled and sliced * 1/2 cup sugar * 1/4 cup cornstarch * 1/4 cup water * 1 tablespoon lemon juice * 1/2 cup heavy cream, whipped * 1/4 cup confectioners' sugar * 1/4 teaspoon vanilla extract * 6 graham cracker squares, crushed Instructions: 1. In a medium saucepan, combine the strawberries, sugar, cornstarch, water, and lemon juice. Bring to a boil over medium heat, stirring constantly. Reduce heat and simmer for 5 minutes, or until the sauce has thickened. 2. Remove from heat and let cool slightly. 3. In a large bowl, combine the whipped cream, confectioners' sugar, and vanilla extract. Beat until soft peaks form. 4. To assemble the shortcakes, place a graham cracker square on each of 6 dessert plates. Top with a scoop of whipped cream, then a spoonful of strawberry sauce. Repeat layers, ending with a graham cracker square. 5. Serve immediately. **Tips:** * For a more elegant presentation, you can use fresh strawberries instead of sliced strawberries. * If you don't have time to make your own whipped cream, you can use store-bought whipped cream.
Puedes cambiar los valores de dish y ingredients en el mapa, y ajustar la temperatura, topK y tokP, y volver a ejecutar el código. Esto te permitirá observar el efecto de cambiar estos parámetros en el LLM.
Las plantillas de instrucciones son una buena forma de tener instrucciones reutilizables y parametrizables para las llamadas a LLM. Puedes pasar datos y personalizar mensajes para diferentes valores que proporcionan tus usuarios.
9. Clasificación de texto con instrucciones con pocos ejemplos
Los LLM son bastante buenos para clasificar texto en diferentes categorías. Puedes ayudar a un LLM en esa tarea proporcionándole algunos ejemplos de textos y sus categorías asociadas. Este enfoque suele denominarse instrucciones con ejemplos limitados.
Abramos TextClassification.java en el directorio app/src/main/java/gemini/workshop para realizar un tipo particular de clasificación de texto: el análisis de opiniones.
package gemini.workshop;
import com.google.cloud.vertexai.api.Schema;
import com.google.cloud.vertexai.api.Type;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import java.util.List;
public class TextClassification {
enum Sentiment { POSITIVE, NEUTRAL, NEGATIVE }
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(10)
.maxRetries(3)
.responseSchema(Schema.newBuilder()
.setType(Type.STRING)
.addAllEnum(List.of("POSITIVE", "NEUTRAL", "NEGATIVE"))
.build())
.build();
interface SentimentAnalysis {
@SystemMessage("""
Analyze the sentiment of the text below.
Respond only with one word to describe the sentiment.
""")
Sentiment analyze(String text);
}
MessageWindowChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);
memory.add(UserMessage.from("This is fantastic news!"));
memory.add(AiMessage.from(Sentiment.POSITIVE.name()));
memory.add(UserMessage.from("Pi is roughly equal to 3.14"));
memory.add(AiMessage.from(Sentiment.NEUTRAL.name()));
memory.add(UserMessage.from("I really disliked the pizza. Who would use pineapples as a pizza topping?"));
memory.add(AiMessage.from(Sentiment.NEGATIVE.name()));
SentimentAnalysis sentimentAnalysis =
AiServices.builder(SentimentAnalysis.class)
.chatLanguageModel(model)
.chatMemory(memory)
.build();
System.out.println(sentimentAnalysis.analyze("I love strawberries!"));
}
}
Un enum Sentiment enumera los diferentes valores de una opinión: negativa, neutral o positiva.
En el método main(), creas el modelo de chat de Gemini como de costumbre, pero con una pequeña cantidad máxima de tokens de salida, ya que solo deseas una respuesta breve: el texto es POSITIVE, NEGATIVE o NEUTRAL. Para restringir el modelo de modo que solo devuelva esos valores, exclusivamente, puedes aprovechar la compatibilidad con el resultado estructurado que descubriste en la sección de extracción de datos. Por eso, se usa el método responseSchema(). Esta vez, no usarás el método conveniente de SchemaHelper para inferir la definición del esquema, sino que usarás el compilador Schema para comprender cómo se ve la definición del esquema.
Una vez que se configura el modelo, creas una interfaz SentimentAnalysis que AiServices de LangChain4j implementará por ti con el LLM. Esta interfaz contiene un método: analyze(). Toma el texto para analizar en la entrada y devuelve un valor de enumeración Sentiment. Por lo tanto, solo manipulas un objeto con escritura segura que representa la clase de opinión reconocida.
Luego, para proporcionar los "ejemplos de pocos disparos" que guíen al modelo para que realice su trabajo de clasificación, creas una memoria de chat para pasar pares de mensajes del usuario y respuestas de IA que representen el texto y el sentimiento asociado a él.
Unamos todo con el método AiServices.builder() pasando nuestra interfaz SentimentAnalysis, el modelo que se usará y la memoria de chat con los ejemplos de pocos disparos. Por último, llama al método analyze() con el texto que se analizará.
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.TextClassification
Deberías ver una sola palabra:
POSITIVE
Parece que amar las fresas es una opinión positiva.
10. Generación mejorada por recuperación
Los LLM se entrenan con una gran cantidad de texto. Sin embargo, su conocimiento solo abarca la información que vio durante su entrenamiento. Si se publica información nueva después de la fecha límite del entrenamiento del modelo, esos detalles no estarán disponibles para el modelo. Por lo tanto, el modelo no podrá responder preguntas sobre información que no haya visto.
Por eso, los enfoques como la generación mejorada por recuperación (RAG), que se abordarán en esta sección, ayudan a proporcionar la información adicional que un LLM puede necesitar para satisfacer las solicitudes de sus usuarios, responder con información que puede ser más actual o sobre información privada a la que no se puede acceder durante el entrenamiento.
Volvamos a las conversaciones. Esta vez, podrás hacer preguntas sobre tus documentos. Crearás un chatbot que pueda recuperar información pertinente de una base de datos que contiene tus documentos divididos en fragmentos más pequeños, y el modelo usará esa información para fundamentar sus respuestas, en lugar de depender únicamente del conocimiento que contiene su entrenamiento.
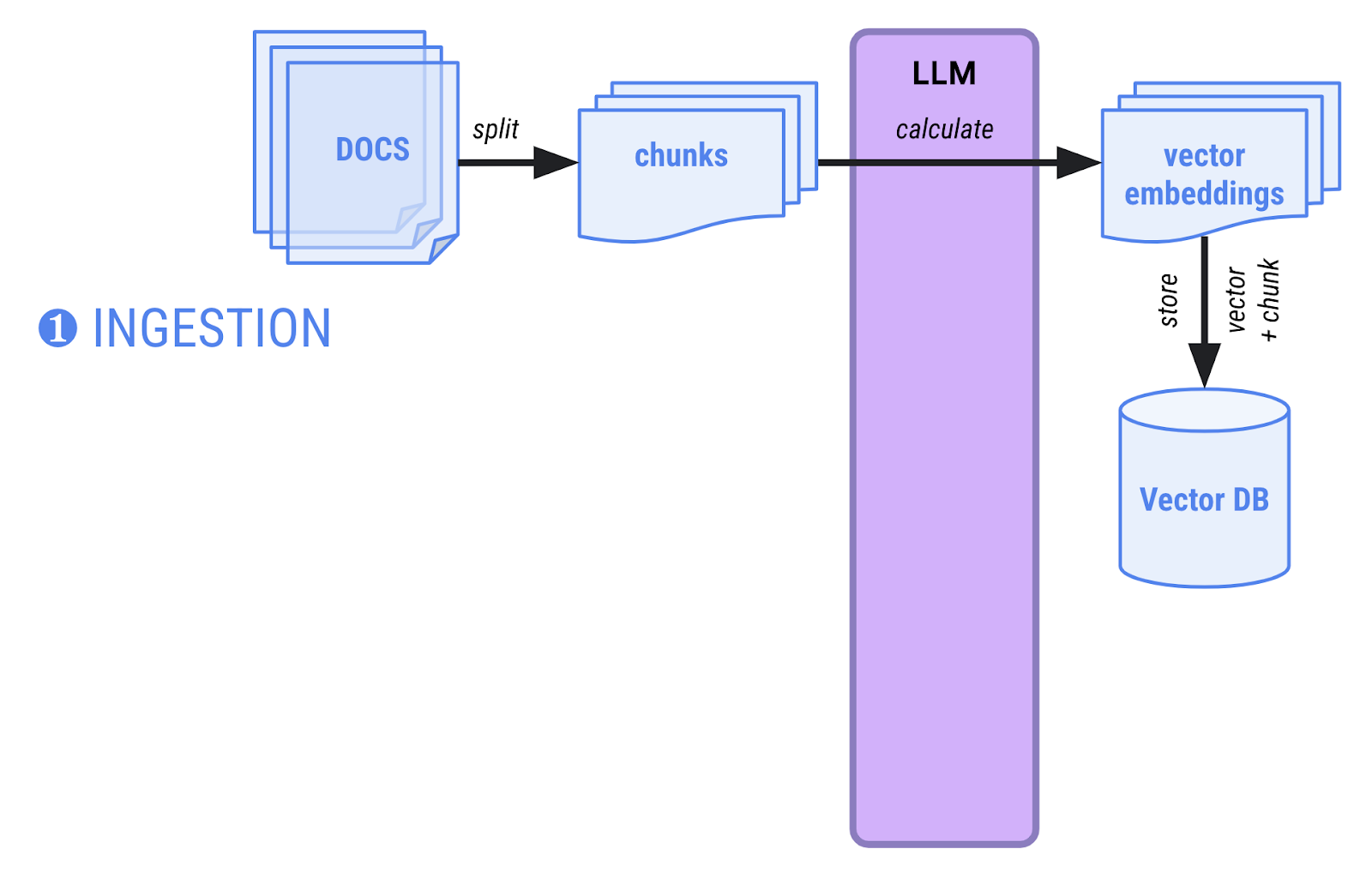
En el RAG, hay dos fases:
- Fase de transferencia: Los documentos se cargan en la memoria, se dividen en fragmentos más pequeños y se calculan los embeddings de vectores (una representación de vectores multidimensionales alta de los fragmentos) y se almacenan en una base de datos de vectores que puede realizar búsquedas semánticas. Por lo general, esta fase de transferencia se realiza una sola vez, cuando se deben agregar documentos nuevos al corpus de documentos.
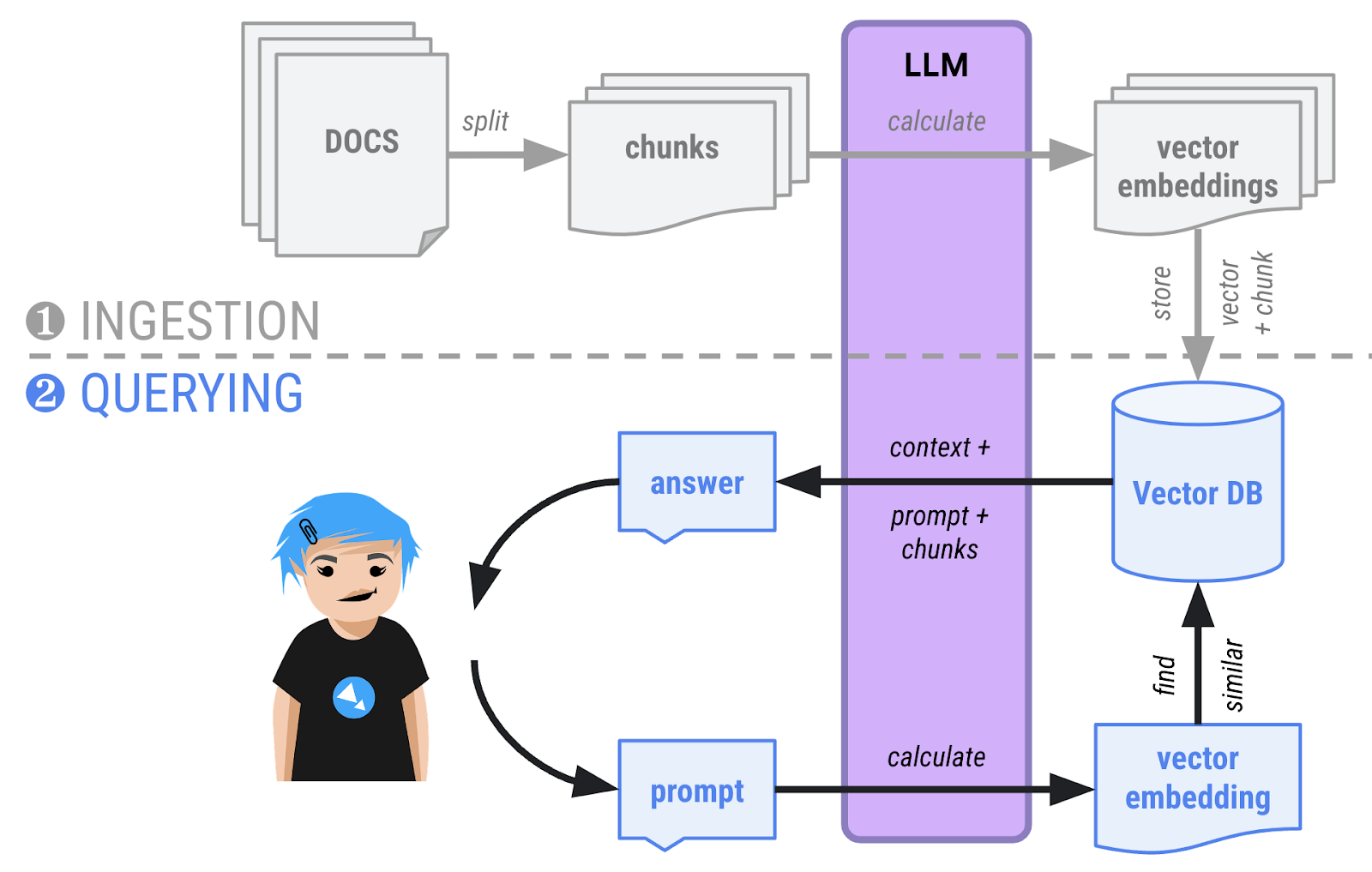
- Fase de preguntas: Ahora los usuarios pueden hacer preguntas sobre los documentos. La pregunta también se transformará en un vector y se comparará con todos los demás vectores de la base de datos. Los vectores más similares suelen estar relacionados semánticamente y los devuelve la base de datos de vectores. Luego, se le proporciona al LLM el contexto de la conversación, los fragmentos de texto que corresponden a los vectores que devolvió la base de datos, y se le pide que fundamente su respuesta consultando esos fragmentos.
Prepara tus documentos
En este nuevo ejemplo, harás preguntas sobre un modelo de automóvil ficticio de un fabricante de automóviles también ficticio: ¡el automóvil Cymbal Starlight! La idea es que un documento sobre un automóvil ficticio no debería formar parte del conocimiento del modelo. Por lo tanto, si Gemini puede responder preguntas correctamente sobre este automóvil, significa que el enfoque de RAG funciona: puede buscar en tu documento.
Implementa el chatbot
Exploremos cómo crear el enfoque de 2 fases: primero, con la incorporación del documento y, luego, con el tiempo de consulta (también llamado "fase de recuperación") cuando los usuarios hacen preguntas sobre el documento.
En este ejemplo, ambas fases se implementan en la misma clase. Normalmente, tendrías una aplicación que se encargaría de la transferencia y otra que ofrecería la interfaz del chatbot a tus usuarios.
Además, en este ejemplo, usaremos una base de datos de vectores en la memoria. En un caso de producción real, las fases de transferencia y de consulta se separarían en dos aplicaciones distintas, y los vectores se conservarían en una base de datos independiente.
Transferencia de documentos
El primer paso de la fase de transferencia del documento es ubicar el archivo PDF sobre nuestro automóvil ficticio y preparar un PdfParser para leerlo:
URL url = new URI("https://raw.githubusercontent.com/meteatamel/genai-beyond-basics/main/samples/grounding/vertexai-search/cymbal-starlight-2024.pdf").toURL();
ApachePdfBoxDocumentParser pdfParser = new ApachePdfBoxDocumentParser();
Document document = pdfParser.parse(url.openStream());
En lugar de crear primero el modelo de lenguaje de chat habitual, creas una instancia de un modelo de embedding. Este es un modelo particular cuya función es crear representaciones vectoriales de fragmentos de texto (palabras, oraciones o incluso párrafos). Devuelve vectores de números de punto flotante, en lugar de respuestas de texto.
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint(System.getenv("LOCATION") + "-aiplatform.googleapis.com:443")
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.publisher("google")
.modelName("text-embedding-005")
.maxRetries(3)
.build();
A continuación, necesitarás algunas clases para colaborar y realizar las siguientes acciones:
- Carga y divide el documento PDF en fragmentos.
- Crea embeddings de vectores para todos estos fragmentos.
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
Se crea una instancia de InMemoryEmbeddingStore, una base de datos de vectores en la memoria, para almacenar los embeddings de vectores.
El documento se divide en fragmentos gracias a la clase DocumentSplitters. Dividirá el texto del archivo PDF en fragmentos de 500 caracteres, con una superposición de 100 caracteres (con el siguiente fragmento, para evitar cortar palabras o frases, en partes).
El procesador de documentos de la tienda vincula el divisor de documentos, el modelo de incorporación para calcular los vectores y la base de datos de vectores en memoria. Luego, el método ingest() se encargará de realizar la transferencia.
Ahora, la primera fase finalizó, el documento se transformó en fragmentos de texto con sus embeddings de vectores asociados y se almacenó en la base de datos de vectores.
Cómo hacer preguntas
Es hora de prepararse para hacer preguntas. Crea un modelo de chat para iniciar la conversación:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(1000)
.build();
También necesitas una clase de recuperación para vincular la base de datos de vectores (en la variable embeddingStore) con el modelo de embedding. Su trabajo es consultar la base de datos de vectores calculando un embedding de vector para la búsqueda del usuario, para encontrar vectores similares en la base de datos:
EmbeddingStoreContentRetriever retriever =
new EmbeddingStoreContentRetriever(embeddingStore, embeddingModel);
Crea una interfaz que represente a un asistente experto en automóviles, es decir, una interfaz que la clase AiServices implementará para que puedas interactuar con el modelo:
interface CarExpert {
Result<String> ask(String question);
}
La interfaz CarExpert devuelve una respuesta de cadena envuelta en la clase Result de LangChain4j. ¿Por qué usar este wrapper? Porque no solo te dará la respuesta, sino que también te permitirá examinar los fragmentos de la base de datos que devolvió el recuperador de contenido. De esta manera, puedes mostrar las fuentes de los documentos que se usan para fundamentar la respuesta final al usuario.
En este punto, puedes configurar un nuevo servicio de IA:
CarExpert expert = AiServices.builder(CarExpert.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(retriever)
.build();
Este servicio vincula lo siguiente:
- El modelo de idioma del chat que configuraste antes.
- Una memoria de chat para hacer un seguimiento de la conversación
- El retriever compara una consulta de embedding de vector con los vectores de la base de datos.
.retrievalAugmentor(DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("""
You are an expert in car automotive, and you answer concisely.
Here is the question: {{userMessage}}
Answer using the following information:
{{contents}}
"""))
.build())
.contentRetriever(retriever)
.build())
Ya puedes hacer tus preguntas.
List.of(
"What is the cargo capacity of Cymbal Starlight?",
"What's the emergency roadside assistance phone number?",
"Are there some special kits available on that car?"
).forEach(query -> {
Result<String> response = expert.ask(query);
System.out.printf("%n=== %s === %n%n %s %n%n", query, response.content());
System.out.println("SOURCE: " + response.sources().getFirst().textSegment().text());
});
El código fuente completo se encuentra en RAG.java en el directorio app/src/main/java/gemini/workshop.
Ejecuta la muestra:
./gradlew -q run -DjavaMainClass=gemini.workshop.RAG
En el resultado, deberías ver respuestas a tus preguntas:
=== What is the cargo capacity of Cymbal Starlight? === The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. SOURCE: Cargo The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of the vehicle. To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell. When loading cargo into the trunk, be sure to distribute the weight evenly. Do not overload the trunk, as this could affect the vehicle's handling and stability. Luggage === What's the emergency roadside assistance phone number? === The emergency roadside assistance phone number is 1-800-555-1212. SOURCE: Chapter 18: Emergencies Roadside Assistance If you experience a roadside emergency, such as a flat tire or a dead battery, you can call roadside assistance for help. Roadside assistance is available 24 hours a day, 7 days a week. To call roadside assistance, dial the following number: 1-800-555-1212 When you call roadside assistance, be prepared to provide the following information: Your name and contact information Your vehicle's make, model, and year Your vehicle's location === Are there some special kits available on that car? === Yes, the Cymbal Starlight comes with a tire repair kit. SOURCE: Lane keeping assist: This feature helps to keep you in your lane by gently steering the vehicle back into the lane if you start to drift. Adaptive cruise control: This feature automatically adjusts your speed to maintain a safe following distance from the vehicle in front of you. Forward collision warning: This feature warns you if you are approaching another vehicle too quickly. Automatic emergency braking: This feature can automatically apply the brakes to avoid a collision.
11. Llamada a función
Hay situaciones en las que te gustaría que un LLM tenga acceso a sistemas externos, como una API web remota que recupera información o tiene una acción, o servicios que realizan algún tipo de cálculo. Por ejemplo:
APIs web remotas:
- Hacer un seguimiento de los pedidos de los clientes y actualizarlos
- Busca o crea un ticket en un sistema de seguimiento de problemas.
- Recupera datos en tiempo real, como cotizaciones de acciones o mediciones de sensores de IoT.
- Enviar un correo electrónico
Herramientas de cálculo:
- Una calculadora para problemas matemáticos más avanzados.
- Interpretación de código para ejecutar código cuando los LLMs necesitan lógica de razonamiento.
- Convierte solicitudes en lenguaje natural en consultas en SQL para que un LLM pueda consultar una base de datos.
Las llamadas a funciones (a veces llamadas herramientas o uso de herramientas) son la capacidad del modelo para solicitar que se realicen una o más llamadas a funciones en su nombre, de modo que pueda responder correctamente el mensaje del usuario con datos más recientes.
Dada una instrucción específica de un usuario y el conocimiento de las funciones existentes que pueden ser relevantes para ese contexto, un LLM puede responder con una solicitud de llamada a función. Luego, la aplicación que integra el LLM puede llamar a la función en su nombre y responderle al LLM con una respuesta, y el LLM interpreta la respuesta con una respuesta textual.
Cuatro pasos de la llamada a función
Veamos un ejemplo de llamada a funciones: obtener información sobre el pronóstico del tiempo.
Si le preguntas a Gemini o a cualquier otro LLM sobre el clima en París, te responderá que no tiene información sobre el pronóstico del clima actual. Si quieres que el LLM tenga acceso en tiempo real a los datos meteorológicos, debes definir algunas funciones que pueda solicitar que se usen.
Observa el siguiente diagrama:

1️⃣ Primero, un usuario pregunta sobre el clima en París. La app de chatbot (con LangChain4j) sabe que tiene a su disposición una o más funciones para ayudar al LLM a satisfacer la búsqueda. El chatbot envía la instrucción inicial y la lista de funciones que se pueden llamar. Aquí, una función llamada getWeather() que toma un parámetro de cadena para la ubicación.

Como el LLM no conoce los pronósticos del clima, en lugar de responder por texto, envía una solicitud de ejecución de función. El chatbot debe llamar a la función getWeather() con "Paris" como parámetro de ubicación.
2️⃣ El chatbot invoca esa función en nombre del LLM y recupera la respuesta de la función. Aquí, suponemos que la respuesta es {"forecast": "sunny"}.
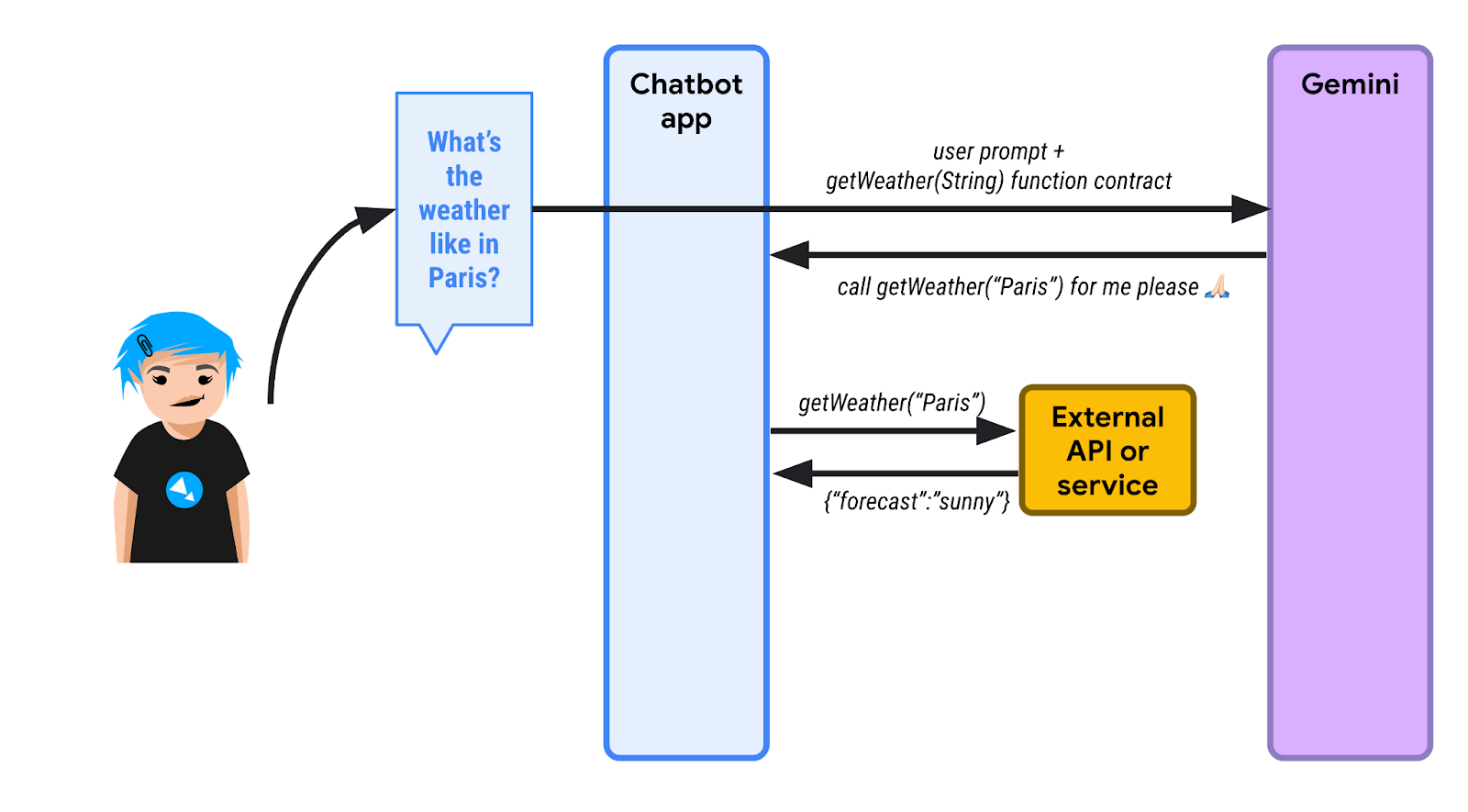
3️⃣ La app de chatbot envía la respuesta JSON al LLM.

4️⃣ El LLM analiza la respuesta en formato JSON, interpreta esa información y, finalmente, responde con el texto que indica que el clima es soleado en París.

Cada paso como código
Primero, configurarás el modelo de Gemini como de costumbre:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
Defines una especificación de la herramienta que describe la función que se puede llamar:
ToolSpecification weatherToolSpec = ToolSpecification.builder()
.name("getWeather")
.description("Get the weather forecast for a given location or city")
.parameters(JsonObjectSchema.builder()
.addStringProperty(
"location",
"the location or city to get the weather forecast for")
.build())
.build();
Se definen el nombre de la función, así como el nombre y el tipo del parámetro, pero observa que tanto la función como los parámetros tienen descripciones. Las descripciones son muy importantes y ayudan al LLM a comprender realmente lo que puede hacer una función y, por lo tanto, a juzgar si es necesario llamar a esta función en el contexto de la conversación.
Comencemos con el paso 1 y enviemos la pregunta inicial sobre el clima en París:
List<ChatMessage> allMessages = new ArrayList<>();
// 1) Ask the question about the weather
UserMessage weatherQuestion = UserMessage.from("What is the weather in Paris?");
allMessages.add(weatherQuestion);
En el paso 2, pasamos la herramienta que queremos que use el modelo, y este responde con una solicitud de ejecución de la herramienta:
// 2) The model replies with a function call request
Response<AiMessage> messageResponse = model.generate(allMessages, weatherToolSpec);
ToolExecutionRequest toolExecutionRequest = messageResponse.content().toolExecutionRequests().getFirst();
System.out.println("Tool execution request: " + toolExecutionRequest);
allMessages.add(messageResponse.content());
Paso 3: En este punto, sabemos qué función quiere que llamemos el LLM. En el código, no hacemos una llamada real a una API externa, solo devolvemos un pronóstico del tiempo hipotético directamente:
// 3) We send back the result of the function call
ToolExecutionResultMessage toolExecResMsg = ToolExecutionResultMessage.from(toolExecutionRequest,
"{\"location\":\"Paris\",\"forecast\":\"sunny\", \"temperature\": 20}");
allMessages.add(toolExecResMsg);
En el paso 4, el LLM aprende sobre el resultado de la ejecución de la función y, luego, puede sintetizar una respuesta textual:
// 4) The model answers with a sentence describing the weather
Response<AiMessage> weatherResponse = model.generate(allMessages);
System.out.println("Answer: " + weatherResponse.content().text());
El código fuente completo se encuentra en FunctionCalling.java en el directorio app/src/main/java/gemini/workshop.
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCalling
Deberías ver un resultado similar al siguiente:
Tool execution request: ToolExecutionRequest { id = null, name = "getWeatherForecast", arguments = "{"location":"Paris"}" }
Answer: The weather in Paris is sunny with a temperature of 20 degrees Celsius.
En el resultado anterior, puedes ver la solicitud de ejecución de la herramienta, así como la respuesta.
12. LangChain4j controla las llamadas a funciones
En el paso anterior, viste cómo se intercalan las interacciones normales de preguntas y respuestas de texto y las solicitudes y respuestas de funciones. Entre ellas, proporcionaste la respuesta de función solicitada directamente, sin llamar a una función real.
Sin embargo, LangChain4j también ofrece una abstracción de nivel superior que puede controlar las llamadas a funciones de forma transparente por ti, mientras maneja la conversación como de costumbre.
Llamada a una sola función
Analicemos FunctionCallingAssistant.java parte por parte.
Primero, crea un registro que representará la estructura de datos de la respuesta de la función:
record WeatherForecast(String location, String forecast, int temperature) {}
La respuesta contiene información sobre la ubicación, el pronóstico y la temperatura.
Luego, crea una clase que contenga la función real que deseas que esté disponible para el modelo:
static class WeatherForecastService {
@Tool("Get the weather forecast for a location")
WeatherForecast getForecast(@P("Location to get the forecast for") String location) {
if (location.equals("Paris")) {
return new WeatherForecast("Paris", "Sunny", 20);
} else if (location.equals("London")) {
return new WeatherForecast("London", "Rainy", 15);
} else {
return new WeatherForecast("Unknown", "Unknown", 0);
}
}
}
Ten en cuenta que esta clase contiene una sola función, pero está anotada con la anotación @Tool, que corresponde a la descripción de la función que el modelo puede solicitar que se llame.
Los parámetros de la función (solo uno en este caso) también se anotan, pero con esta anotación @P corta, que también proporciona una descripción del parámetro. Podrías agregar tantas funciones como quisieras para que estén disponibles para el modelo en situaciones más complejas.
En esta clase, devuelves algunas respuestas predefinidas, pero, si quisieras llamar a un servicio externo real de previsión meteorológica, en el cuerpo de ese método harías la llamada a ese servicio.
Como vimos cuando creaste un ToolSpecification en el enfoque anterior, es importante documentar lo que hace una función y describir a qué corresponden los parámetros. Esto ayuda al modelo a comprender cómo y cuándo se puede usar esta función.
A continuación, LangChain4j te permite proporcionar una interfaz que corresponde al contrato que deseas usar para interactuar con el modelo. Aquí, es una interfaz simple que toma una cadena que representa el mensaje del usuario y devuelve una cadena correspondiente a la respuesta del modelo:
interface WeatherAssistant {
String chat(String userMessage);
}
También es posible usar firmas más complejas que involucren UserMessage (para un mensaje del usuario) o AiMessage (para una respuesta del modelo) de LangChain4j, o incluso un TokenStream, si deseas controlar situaciones más avanzadas, ya que esos objetos más complicados también contienen información adicional, como la cantidad de tokens consumidos, etcétera. Sin embargo, para simplificar, solo tomaremos cadenas como entrada y salida.
Terminemos con el método main() que une todas las piezas:
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
WeatherForecastService weatherForecastService = new WeatherForecastService();
WeatherAssistant assistant = AiServices.builder(WeatherAssistant.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.tools(weatherForecastService)
.build();
System.out.println(assistant.chat("What is the weather in Paris?"));
System.out.println(assistant.chat("Is it warmer in London or in Paris?"));
}
Como de costumbre, configura el modelo de chat de Gemini. Luego, crearás una instancia de tu servicio de previsión meteorológica que contiene la "función" que el modelo nos pedirá que llamemos.
Ahora, vuelves a usar la clase AiServices para vincular el modelo de chat, la memoria de chat y la herramienta (es decir, el servicio de previsión meteorológica con su función). AiServices devuelve un objeto que implementa la interfaz WeatherAssistant que definiste. Lo único que queda es llamar al método chat() de ese asistente. Cuando la invoques, solo verás las respuestas de texto, pero las solicitudes y las respuestas de llamadas a funciones no serán visibles para el desarrollador, y esas solicitudes se manejarán de forma automática y transparente. Si Gemini cree que se debe llamar a una función, responderá con la solicitud de llamada a la función, y LangChain4j se encargará de llamar a la función local en tu nombre.
Ejecuta la muestra:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCallingAssistant
Deberías ver un resultado similar al siguiente:
OK. The weather in Paris is sunny with a temperature of 20 degrees.
It is warmer in Paris (20 degrees) than in London (15 degrees).
Este fue un ejemplo de una sola función.
Varias llamadas a funciones
También puedes tener varias funciones y dejar que LangChain4j controle varias llamadas a funciones en tu nombre. Consulta MultiFunctionCallingAssistant.java para ver un ejemplo de varias funciones.
Tiene una función para convertir monedas:
@Tool("Convert amounts between two currencies")
double convertCurrency(
@P("Currency to convert from") String fromCurrency,
@P("Currency to convert to") String toCurrency,
@P("Amount to convert") double amount) {
double result = amount;
if (fromCurrency.equals("USD") && toCurrency.equals("EUR")) {
result = amount * 0.93;
} else if (fromCurrency.equals("USD") && toCurrency.equals("GBP")) {
result = amount * 0.79;
}
System.out.println(
"convertCurrency(fromCurrency = " + fromCurrency +
", toCurrency = " + toCurrency +
", amount = " + amount + ") == " + result);
return result;
}
Otra función para obtener el valor de una acción:
@Tool("Get the current value of a stock in US dollars")
double getStockPrice(@P("Stock symbol") String symbol) {
double result = 170.0 + 10 * new Random().nextDouble();
System.out.println("getStockPrice(symbol = " + symbol + ") == " + result);
return result;
}
Otra función para aplicar un porcentaje a un importe determinado:
@Tool("Apply a percentage to a given amount")
double applyPercentage(@P("Initial amount") double amount, @P("Percentage between 0-100 to apply") double percentage) {
double result = amount * (percentage / 100);
System.out.println("applyPercentage(amount = " + amount + ", percentage = " + percentage + ") == " + result);
return result;
}
Luego, puedes combinar todas estas funciones y una clase MultiTools, y hacer preguntas como "¿Cuál es el 10% del precio de las acciones de AAPL convertido de USD a EUR?".
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
MultiTools multiTools = new MultiTools();
MultiToolsAssistant assistant = AiServices.builder(MultiToolsAssistant.class)
.chatLanguageModel(model)
.chatMemory(withMaxMessages(10))
.tools(multiTools)
.build();
System.out.println(assistant.chat(
"What is 10% of the AAPL stock price converted from USD to EUR?"));
}
Ejecútalo de la siguiente manera:
./gradlew run -q -DjavaMainClass=gemini.workshop.MultiFunctionCallingAssistant
Deberías ver las múltiples funciones llamadas:
getStockPrice(symbol = AAPL) == 172.8022224055534 convertCurrency(fromCurrency = USD, toCurrency = EUR, amount = 172.8022224055534) == 160.70606683716468 applyPercentage(amount = 160.70606683716468, percentage = 10.0) == 16.07060668371647 10% of the AAPL stock price converted from USD to EUR is 16.07060668371647 EUR.
Hacia los agentes
Las llamadas a funciones son un excelente mecanismo de extensión para los modelos de lenguaje grandes, como Gemini. Nos permite crear sistemas más complejos que a menudo se denominan "agentes" o "asistentes de IA". Estos agentes pueden interactuar con el mundo exterior a través de APIs externas y con servicios que pueden tener efectos secundarios en el entorno externo (como enviar correos electrónicos, crear tickets, etcétera).
Cuando crees agentes tan potentes, debes hacerlo de forma responsable. Debes considerar la intervención humana antes de realizar acciones automáticas. Es importante tener en cuenta la seguridad cuando se diseñan agentes potenciados por LLMs que interactúan con el mundo externo.
13. Ejecuta Gemma con Ollama y TestContainers
Hasta ahora, usamos Gemini, pero también existe Gemma, su modelo hermano más pequeño.
Gemma es una familia de modelos abiertos, livianos y de última generación creados a partir de la misma investigación y tecnología que se utilizaron para crear los modelos de Gemini. El modelo de Gemma más reciente es Gemma3, que está disponible en cuatro tamaños: 1B (solo texto), 4B, 12B y 27B. Sus pesos están disponibles de forma gratuita y sus tamaños pequeños significan que puedes ejecutarlo por tu cuenta, incluso en tu laptop o en Cloud Shell.
¿Cómo ejecutas Gemma?
Hay muchas formas de ejecutar Gemma: en la nube, a través de Vertex AI con un solo clic o en GKE con algunas GPUs, pero también puedes ejecutarlo de forma local.
Una buena opción para ejecutar Gemma de forma local es Ollama, una herramienta que te permite ejecutar modelos pequeños, como Llama, Mistral y muchos otros en tu máquina local. Es similar a Docker, pero para LLMs.
Instala Ollama siguiendo las instrucciones para tu sistema operativo.
Si usas un entorno de Linux, primero deberás habilitar Ollama después de instalarlo.
ollama serve > /dev/null 2>&1 &
Una vez que se instale de forma local, podrás ejecutar comandos para extraer un modelo:
ollama pull gemma3:1b
Espera a que se extraiga el modelo. Este proceso puede demorar unos minutos.
Ejecuta el modelo:
ollama run gemma3:1b
Ahora puedes interactuar con el modelo:
>>> Hello! Hello! It's nice to hear from you. What can I do for you today?
Para salir del mensaje, presiona Ctrl + D.
Ejecuta Gemma en Ollama en TestContainers
En lugar de tener que instalar y ejecutar Ollama de forma local, puedes usar Ollama dentro de un contenedor, controlado por TestContainers.
TestContainers no solo es útil para las pruebas, sino que también puedes usarlo para ejecutar contenedores. Incluso puedes aprovechar un OllamaContainer específico.
Aquí tienes el panorama completo:

Implementación
Analicemos GemmaWithOllamaContainer.java parte por parte.
Primero, debes crear un contenedor de Ollama derivado que extraiga el modelo de Gemma. Esta imagen ya existe de una ejecución anterior o se creará. Si la imagen ya existe, solo le dirás a TestContainers que quieres sustituir la imagen predeterminada de Ollama por tu variante potenciada por Gemma:
private static final String TC_OLLAMA_GEMMA3 = "tc-ollama-gemma3-1b";
public static final String GEMMA_3 = "gemma3:1b";
// Creating an Ollama container with Gemma 3 if it doesn't exist.
private static OllamaContainer createGemmaOllamaContainer() throws IOException, InterruptedException {
// Check if the custom Gemma Ollama image exists already
List<Image> listImagesCmd = DockerClientFactory.lazyClient()
.listImagesCmd()
.withImageNameFilter(TC_OLLAMA_GEMMA3)
.exec();
if (listImagesCmd.isEmpty()) {
System.out.println("Creating a new Ollama container with Gemma 3 image...");
OllamaContainer ollama = new OllamaContainer("ollama/ollama:0.7.1");
System.out.println("Starting Ollama...");
ollama.start();
System.out.println("Pulling model...");
ollama.execInContainer("ollama", "pull", GEMMA_3);
System.out.println("Committing to image...");
ollama.commitToImage(TC_OLLAMA_GEMMA3);
return ollama;
}
System.out.println("Ollama image substitution...");
// Substitute the default Ollama image with our Gemma variant
return new OllamaContainer(
DockerImageName.parse(TC_OLLAMA_GEMMA3)
.asCompatibleSubstituteFor("ollama/ollama"));
}
A continuación, crearás e iniciarás un contenedor de prueba de Ollama y, luego, crearás un modelo de chat de Ollama apuntando a la dirección y el puerto del contenedor con el modelo que deseas usar. Por último, invoca model.generate(yourPrompt) como de costumbre:
public static void main(String[] args) throws IOException, InterruptedException {
OllamaContainer ollama = createGemmaOllamaContainer();
ollama.start();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(String.format("http://%s:%d", ollama.getHost(), ollama.getFirstMappedPort()))
.modelName(GEMMA_3)
.build();
String response = model.generate("Why is the sky blue?");
System.out.println(response);
}
Ejecútalo de la siguiente manera:
./gradlew run -q -DjavaMainClass=gemini.workshop.GemmaWithOllamaContainer
La primera ejecución tardará un tiempo en crear y ejecutar el contenedor, pero, una vez que finalice, deberías ver que Gemma responde:
INFO: Container ollama/ollama:0.7.1 started in PT7.228339916S
The sky appears blue due to Rayleigh scattering. Rayleigh scattering is a phenomenon that occurs when sunlight interacts with molecules in the Earth's atmosphere.
* **Scattering particles:** The main scattering particles in the atmosphere are molecules of nitrogen (N2) and oxygen (O2).
* **Wavelength of light:** Blue light has a shorter wavelength than other colors of light, such as red and yellow.
* **Scattering process:** When blue light interacts with these molecules, it is scattered in all directions.
* **Human eyes:** Our eyes are more sensitive to blue light than other colors, so we perceive the sky as blue.
This scattering process results in a blue appearance for the sky, even though the sun is actually emitting light of all colors.
In addition to Rayleigh scattering, other atmospheric factors can also influence the color of the sky, such as dust particles, aerosols, and clouds.
¡Ya tienes Gemma ejecutándose en Cloud Shell!
14. Felicitaciones
¡Felicitaciones! Compilaste con éxito tu primera aplicación de chat de IA generativa en Java con LangChain4j y la API de Gemini. En el camino, descubriste que los modelos de lenguaje grandes multimodales son bastante potentes y capaces de manejar varias tareas, como preguntas y respuestas, incluso en tu propia documentación, extracción de datos, interacción con APIs externas y mucho más.
¿Qué sigue?
Es tu turno de mejorar tus aplicaciones con potentes integraciones de LLM.
Lecturas adicionales
- Casos de uso comunes de la IA generativa
- Recursos de capacitación sobre IA generativa
- Interactúa con Gemini a través de Generative AI Studio
- IA responsable