
1. مقدمة
ما ستنشئه
Gemini Motion Lab هي تجربة مباشرة في كشك مستند إلى الذكاء الاصطناعي. يسجّل المستخدم مقطعًا قصيرًا للرقص أو الحركة، ويقوم النظام بما يلي:
- تحليل الحركة باستخدام Gemini (أجزاء الجسم، والمراحل، والإيقاع، والطاقة)
- إنشاء صورة أفاتار منمّقة باستخدام Nano Banana (Gemini Flash Image)
- إنشاء فيديو من إنشاء الذكاء الاصطناعي باستخدام Veo يعيد إنشاء الحركة باستخدام الأفاتار
- إنشاء فيديو جنبًا إلى جنب (الفيديو الأصلي + الفيديو من إنشاء الذكاء الاصطناعي)
- مشاركة النتيجة عبر رمز استجابة سريعة على صفحة محسّنة للأجهزة الجوّالة
في نهاية هذا الدرس التطبيقي حول الترميز، سيتم نشر العرض التوضيحي الكامل على Google Cloud Run وستفهم مسار الذكاء الاصطناعي الذي يتيح تشغيله.
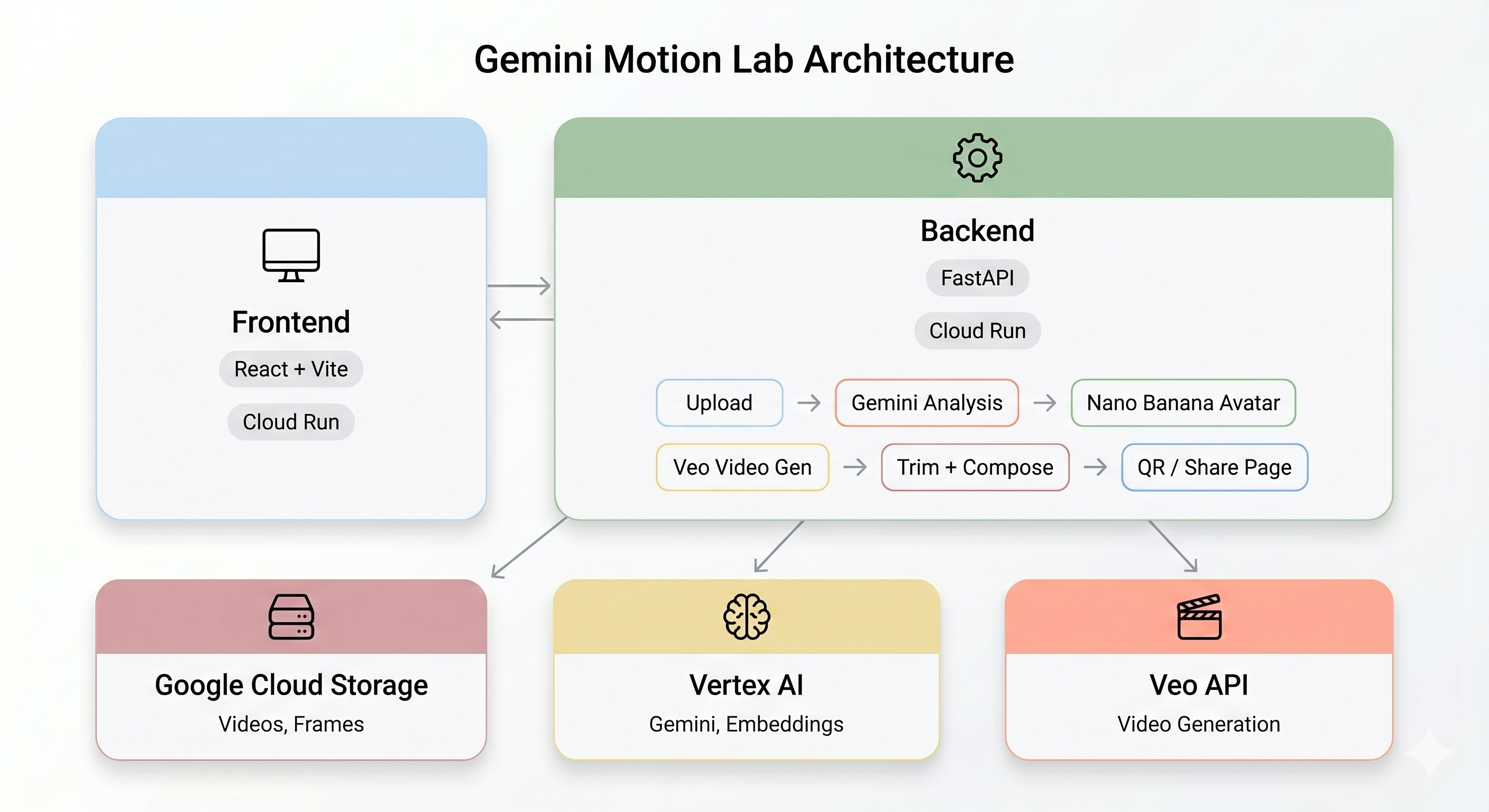
نظرة عامة على البنية
العرض التوضيحي النهائي:
التقنيات الأساسية
المكوّن | تكنولوجيا | الغرض |
تحليل الحركة | Gemini Flash | تحليل الفيديو من حيث حركة الجسم والمراحل والأسلوب |
إنشاء الأفاتار | Gemini Flash Image (Nano Banana) | إنشاء أفاتار مُنمَّط بدقة 1024×1024 من إطار رئيسي |
إنشاء الفيديوهات | Veo 3.1 | إنشاء فيديو من أفاتار الذكاء الاصطناعي + طلب الحركة |
الخادم الخلفي | FastAPI + Python 3.11 | خادم API مع تنظيم خط أنابيب غير متزامن |
Frontend | React + Vite + TypeScript | واجهة مستخدم وضع الكشك مع تسجيل الكاميرا والحالة في الوقت الفعلي |
الاستضافة | Cloud Run | نشر الحاويات بدون خادم |
مساحة التخزين | Google Cloud Storage | الفيديوهات المحمَّلة والإطارات والمخرجات التي تمّ قطعها وتجميعها |
2. 📦 إنشاء نسخة طبق الأصل من المستودع
1. فتح "محرّر Cloud Shell"
👉 افتح محرِّر Cloud Shell في المتصفّح.
إذا لم تظهر الوحدة الطرفية في أسفل الشاشة، اتّبِع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal.
2. استنساخ الرمز
👉💻 في الوحدة الطرفية، أنشئ نسخة طبق الأصل من المستودع:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3- استكشاف بنية المشروع
نظرة سريعة على تخطيط المستودع:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3- 🛠️ المطالبة بالاعتمادات وإنشاء مشروع على Google Cloud Platform
الجزء 1: المطالبة برصيد الفوترة
👉 يمكنك المطالبة برصيد حساب الفوترة باستخدام حسابك على Gmail.
الجزء 2: إنشاء مشروع جديد
👉💻 في الوحدة الطرفية، اجعل النص البرمجي init قابلاً للتنفيذ وشغِّله:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
سيؤدي النص البرمجي init.sh ما يلي:
- أنشئ مشروعًا جديدًا على Google Cloud Platform بالبادئة
gemini-motion-lab - احفظ رقم تعريف المشروع في
~/project_id.txt - تثبيت التبعيات المتعلقة بالفوترة وربط حساب الفوترة تلقائيًا
الجزء 3: ضبط المشروع وتفعيل واجهات برمجة التطبيقات
👉💻 اضبط رقم تعريف مشروعك في نافذة الأوامر:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 فعِّل واجهات Google Cloud API اللازمة لهذا المشروع (يستغرق ذلك من دقيقة إلى دقيقتَين تقريبًا):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [للقراءة فقط] فهم البنية
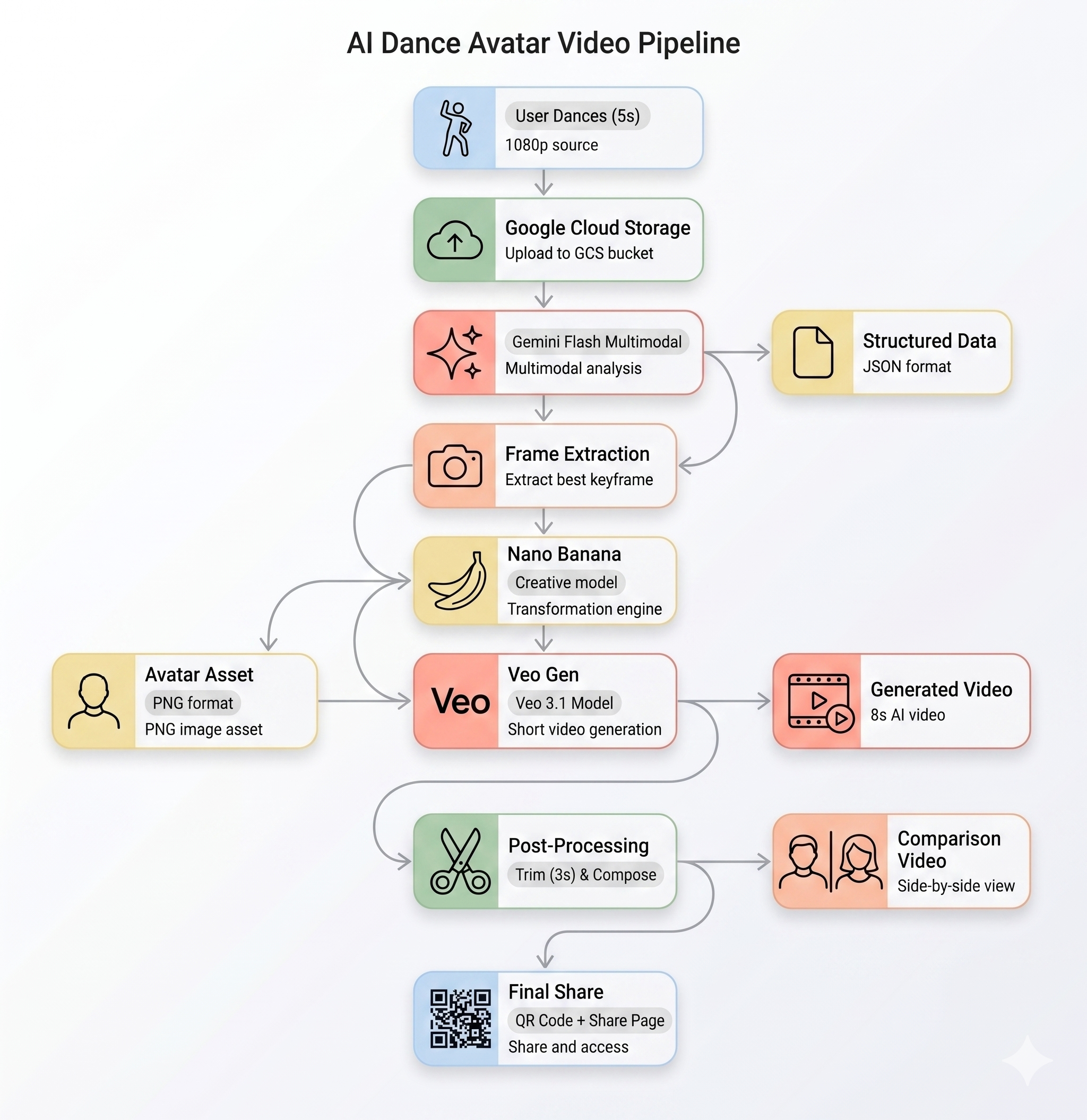
يوضّح هذا القسم طريقة عمل مسار الذكاء الاصطناعي من البداية إلى النهاية. ليس عليك اتّخاذ أي إجراء، ما عليك سوى القراءة لفهم النظام قبل نشره.
مسار الذكاء الاصطناعي
عندما يسجّل المستخدم مقطع فيديو للحركة في جهاز Kiosk، يتم تنفيذ خمس مراحل بالتسلسل:

المرحلة 1: تحميل الفيديو
يسجّل الواجهة الأمامية مقطع WebM مدته 5 ثوانٍ من كاميرا المستخدم ويحمّله إلى Google Cloud Storage من خلال نقطة النهاية /api/upload في الواجهة الخلفية.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
المرحلة 2: تحليل الحركة في Gemini
يرسل الخلفية الفيديو الذي تم تحميله إلى Gemini Flash (gemini-3-flash-preview) لإجراء تحليل منظَّم.
طريقة العمل (backend/app/services/gemini_service.py):
تستخدم الخدمة client.models.generate_content() في حزمة تطوير البرامج (SDK) الخاصة بـ Vertex AI مع الفيديو كإدخال Part.from_uri وطلب منظَّم. يضمن الرمز response_mime_type="application/json" أن يعرض Gemini ملف JSON قابلاً للتحليل. يستخدم النموذج أيضًا ThinkingConfig(thinking_budget=1024) لتحسين الاستدلال بشأن مراحل الحركة.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
المرحلة 3: إنشاء أفاتار باستخدام Nano Banana
باستخدام أفضل لقطة مستخرَجة من الفيديو، ينشئ Gemini Flash Image (gemini-3.1-flash-image-preview) صورة رمزية منمّقة بحجم 1024×1024.
طريقة العمل (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
يتم تحميل صورة PNG للأفاتار الذي تم إنشاؤه إلى GCS ونقلها إلى المرحلة التالية.
المرحلة 4: إنشاء الفيديوهات باستخدام Veo
يتم استخدام صورة الأفاتار كأصل مرجعي لنموذج Veo 3.1 (veo-3.1-fast-generate-001) من أجل إنشاء فيديو مدته 8 ثوانٍ باستخدام الذكاء الاصطناعي.
طريقة العمل (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
تتم عملية إنشاء الفيديو في Veo بشكل غير متزامن، إذ يتم عرض رقم تعريف العملية على الفور. يطلب النظام الخلفي العملية بشكل متكرّر إلى أن تكتمل (لمدة تصل إلى 10 دقائق).
المرحلة 5: مسار المعالجة اللاحقة
بعد اكتمال عملية Veo، يتم تشغيل مسار الخلفية (backend/app/services/pipeline.py) تلقائيًا:
- تقصير فيديو Veo الذي تبلغ مدته 8 ثوانٍ إلى 3 ثوانٍ
- إنشاء فيديو جنبًا إلى جنب (التسجيل الأصلي على اليمين والفيديو من إنشاء الذكاء الاصطناعي على اليسار)
- تحميل الفيديو الذي تم إنشاؤه إلى GCS
- إلغاء حجز خانة في قائمة الانتظار
يتم تشغيل مسار المعالجة هذا في الخلفية asyncio.Task، ولا يحتاج الواجهة الأمامية لجهاز Kiosk إلى الانتظار.
نظام الصفّ
بما أنّ عملية إنشاء الفيديوهات باستخدام Veo تتطلّب الكثير من الموارد، يفرض النظام حدًا أقصى يبلغ 3 مهام متزامنة:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
يتحقّق الواجهة الأمامية من GET /api/queue/status قبل السماح لمستخدم جديد ببدء جلسة. عندما تكتمل عملية تنفيذ سلسلة التعليمات ويتم استدعاء complete(video_id)، يتم فتح الخانة للمستخدم التالي.
Cloud Run — حاويات بدون خادم
يتم نشر كلّ من الخلفية والواجهة الأمامية كخدمات على Cloud Run:
الخدمة | الغرض | إعدادات المفتاح |
الخلفية | خادم واجهة برمجة تطبيقات FastAPI | ذاكرة بسعة 2 غيغابايت (لمعالجة الفيديو من خلال ffmpeg) |
الواجهة الأمامية | تطبيق React ثابت يعرضه Nginx | الذاكرة التلقائية |
5- ⚙️ تشغيل نص الإعداد البرمجي
1. تشغيل عملية الإعداد الآلي
ينشئ النص البرمجي setup.sh موارد السحابة الإلكترونية المطلوبة وينتج ملف .env.
👉💻 اجعل النص البرمجي قابلاً للتنفيذ وشغِّله:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. منح أدوار "إدارة الهوية وإمكانية الوصول"
الآن، امنح حساب الخدمة الأذونات المطلوبة.
👉💻 نفِّذ الأوامر التالية لضبط رقم تعريف مشروعك ومنح الأدوار الثلاثة كلها:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3- تأكيد ملف .env
👉💻 تحقَّق من ملف .env الذي تم إنشاؤه:
cat .env
سيظهر لك ما يلي:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 نشر الخلفية
1. التعرّف على ملف Backend Dockerfile
قبل النشر، دعنا نتعرّف على شكل الحاوية:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. النشر على Cloud Run
👉💻 حمِّلوا متغيرات البيئة ونفِّذوا ما يلي:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
يستغرق ذلك حوالي 3 إلى 5 دقائق. ستعمل خدمة Cloud Build على ما يلي:
- تحميل رمز المصدر
- إنشاء صورة Docker
- إرسالها إلى Artifact Registry
- نشره على Cloud Run
3- حفظ عنوان URL للخادم الخلفي
👉💻 بعد النشر، احفظ عنوان URL للخادم الخلفي:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. تعديل عنوان URL للمشاركة في الخلفية
ينشئ الخلفية رموز استجابة سريعة ليتمكّن المستخدمون من تنزيل فيديوهاتهم. ولإجراء ذلك، يجب أن يعرف عنوان URL المتاح للجميع الخاص به.
👉💻 عدِّل إعدادات الخلفية باستخدام عنوان URL الخاص بها:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5- التحقّق من الخلفية
👉💻 اختبِر نقطة نهاية الصحة:
curl $BACKEND_URL/api/health
الناتج المتوقّع:
{"status":"ok"}
👉💻 الاطّلاع على حالة قائمة الانتظار:
curl $BACKEND_URL/api/queue/status
الناتج المتوقّع:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 نشر الواجهة الأمامية
1. التعرّف على ملف Frontend Dockerfile
تستخدم الواجهة الأمامية عملية إنشاء متعددة المراحل، حيث يتم أولاً إنشاء تطبيق React، ثم عرضه باستخدام Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. النشر على Cloud Run
👉💻 أولاً، اكتب عنوان URL للخادم الخلفي في ملف .env حتى يتمكّن Vite من تضمينه في مدّة التصميم:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 الآن، يمكنك نشر الواجهة الأمامية:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
يستغرق ذلك حوالي دقيقتَين أو ثلاث دقائق.
3- الحصول على عنوان URL للواجهة الأمامية
👉💻 استرداد عنوان URL للواجهة الأمامية وفتحه:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 افتح عنوان URL في متصفّحك، من المفترض أن تظهر لك واجهة كشك Gemini Motion Lab.
8. 🎮 [اختياري] تجربة العرض التوضيحي
1. تسجيل حركة
- افتح عنوان URL للواجهة الأمامية في متصفّحك (يُفضّل استخدام Chrome للحصول على أفضل دعم للكاميرا).
- انقر على بدء لبدء التسجيل
- الرقص أو الحركة لمدة 5 ثوانٍ تقريبًا، مع الحرص على تحريك الذراعين بشكل كبير واتخاذ وضعيات ديناميكية
- سيتوقّف التسجيل تلقائيًا وسيتم تحميله
2. مشاهدة مسار الذكاء الاصطناعي
بعد التحميل، سترى عملية تنفيذ خط الأنابيب في الوقت الفعلي:
المرحلة | What's Happening | المدة |
جارٍ التحليل... | يحلّل Gemini Flash الفيديو بحثًا عن أنماط الحركة | ~5-10 ثوانٍ |
جارٍ إنشاء الأفاتار... | Nano Banana ينشئ صورة رمزية منمقة من أفضل لقطة لك | ~8-12 ثانية |
جارٍ إنشاء الفيديو... | ينشئ Veo 3.1 فيديو باستخدام الذكاء الاصطناعي من الأفاتار + طلب الحركة | ~60-120 ثانية |
جارٍ إنشاء الرسالة... | يقتطع ffmpeg الفيديو وينشئ مقارنة جنبًا إلى جنب | ~5-10 ثوانٍ |
3- مشاركة المحتوى الذي أنشأته
بعد اكتمال مسار التعلّم:
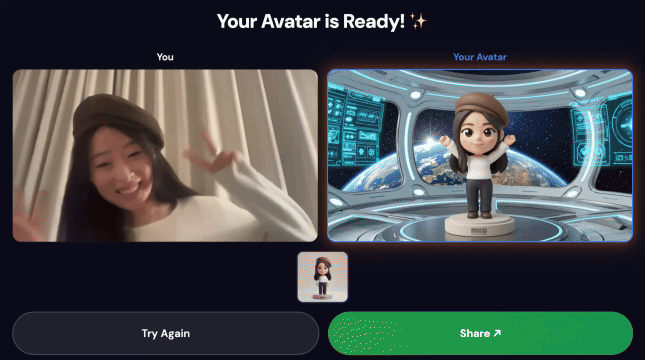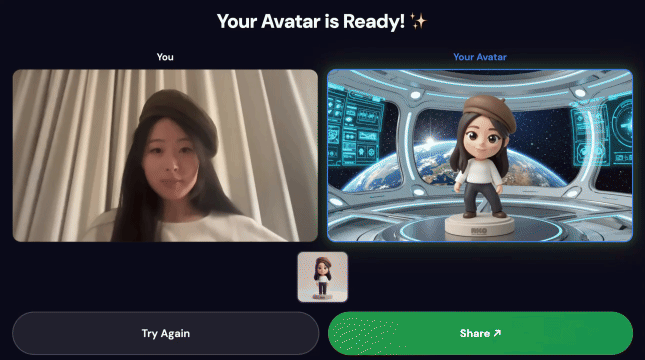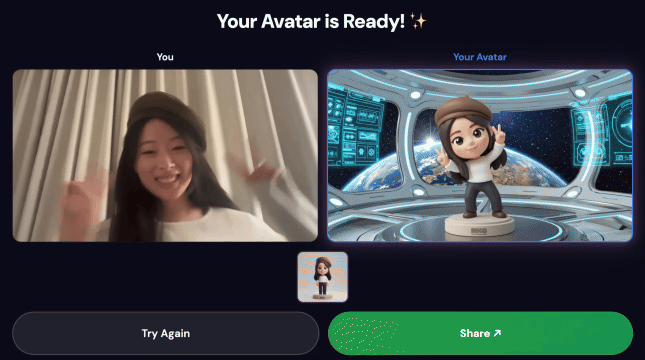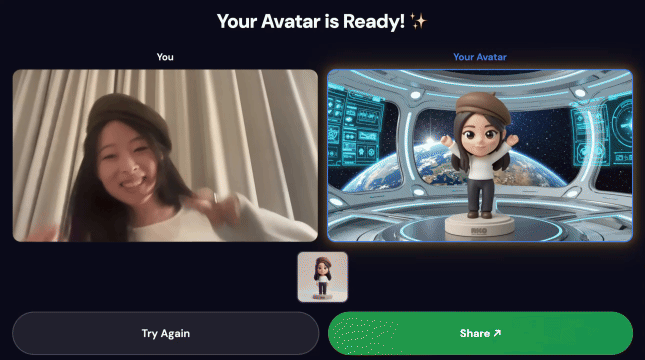
- يظهر رمز استجابة سريعة على شاشة الكشك
- امسح رمز الاستجابة السريعة ضوئيًا باستخدام هاتفك
- ستظهر صفحة مشاركة محسّنة للأجهزة الجوّالة تتضمّن الفيديو الذي أنشأته
4. التحقّق من سجلّات الخلفية
👉💻 الاطّلاع على ما حدث وراء الكواليس:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
ستظهر لك أسطر السجلّ التي تتتبّع مسار خط الأنابيب:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5- مراقبة قائمة الانتظار
👉💻 التحقّق من عدد المهام التي يتم تنفيذها:
curl $BACKEND_URL/api/queue/status
إذا كانت 3 جلسات نشطة في الوقت نفسه، سيظهر الردّ التالي:
{"active_jobs":3,"max_jobs":3,"available":false}
سيُطلب من المستخدمين الجدد الانتظار إلى حين توفّر مكان.
9- 🎉 الخاتمة
المشاريع التي أنشأتها
✅ تحليل الحركة بالذكاء الاصطناعي: يحلّل Gemini Flash الفيديو بحثًا عن الحركة والإيقاع والأسلوب
✅ إنشاء الأفاتارات: تنشئ Nano Banana أفاتارات منمّقة من إطارات الفيديو
✅ إنشاء فيديوهات باستخدام الذكاء الاصطناعي: ينشئ Veo 3.1 فيديوهات جديدة تتطابق مع حركة المستخدم
✅ Async Pipeline: المعالجة في الخلفية مع إدارة قائمة الانتظار (3 عمليات متزامنة كحد أقصى)
✅ تركيب الصور جنبًا إلى جنب: تركيب الصور والفيديوهات باستخدام ffmpeg
✅ النشر على Cloud Run: حوسبة بدون خادم، وتدرّج تلقائي، وبدون إدارة الخادم
المفاهيم الرئيسية التي تعلّمتها
- Gemini Multimodal: إرسال فيديو كمدخل وتلقّي تحليل JSON منظَّم
- Nano Banana (أداة Gemini لإنشاء الصور): استخدام صور مرجعية + طلبات أنماط لإنشاء صور رمزية
- Veo 3.1: إنشاء فيديوهات غير متزامنة باستخدام مواد عرض مرجعية وطلبات نصية
- Cloud Run: نشر الحاويات باستخدام متغيرات البيئة والتوسّع التلقائي
- نمط المسار غير المتزامن: مهام الخلفية التي يتم تنفيذها بدون انتظار الرد باستخدام
asyncio.Taskلعمليات الذكاء الاصطناعي الطويلة الأمد - إدارة قائمة الانتظار: تحديد معدل مهام الذكاء الاصطناعي المتزامنة للتحكّم في التكاليف وحصص واجهة برمجة التطبيقات
ملخّص حول الهندسة المعمارية
الخطوات التالية:
- إضافة المزيد من أنماط الأفاتار — تعديل
backend/app/prompts/avatar_generation.py - تخصيص طلب Veo — تعديل
backend/app/prompts/video_generation.py - التشغيل محليًا في وضع المحاكاة: اضبط
MOCK_AI=trueفي.envللتطوير بدون طلبات بيانات من واجهة برمجة التطبيقات - التوسّع في الأحداث: زيادة
--max-instancesوMAX_CONCURRENT_JOBS