
1. Einführung
Umfang
Gemini Motion Lab ist ein interaktiver Kiosk mit KI-Funktionen. Ein Nutzer nimmt einen kurzen Tanz- oder Bewegungsclip auf und das System:
- Analysiert die Bewegung mit Gemini (Körperteile, Phasen, Tempo, Energie)
- Erstellt ein stilisiertes Avatarbild mit Nano Banana (Gemini Flash Image)
- Erstellt mit Veo ein KI-Video, in dem die Bewegung mit dem Avatar nachgebildet wird.
- Erstellt ein nebeneinander angeordnetes Video (Original + KI‑generiert)
- Teilt das Ergebnis über einen QR‑Code auf einer für Mobilgeräte optimierten Seite
Am Ende dieses Codelabs haben Sie die vollständige Demo in Google Cloud Run bereitgestellt und die KI-Pipeline, die sie unterstützt, verstanden.
Überblick über die Architektur
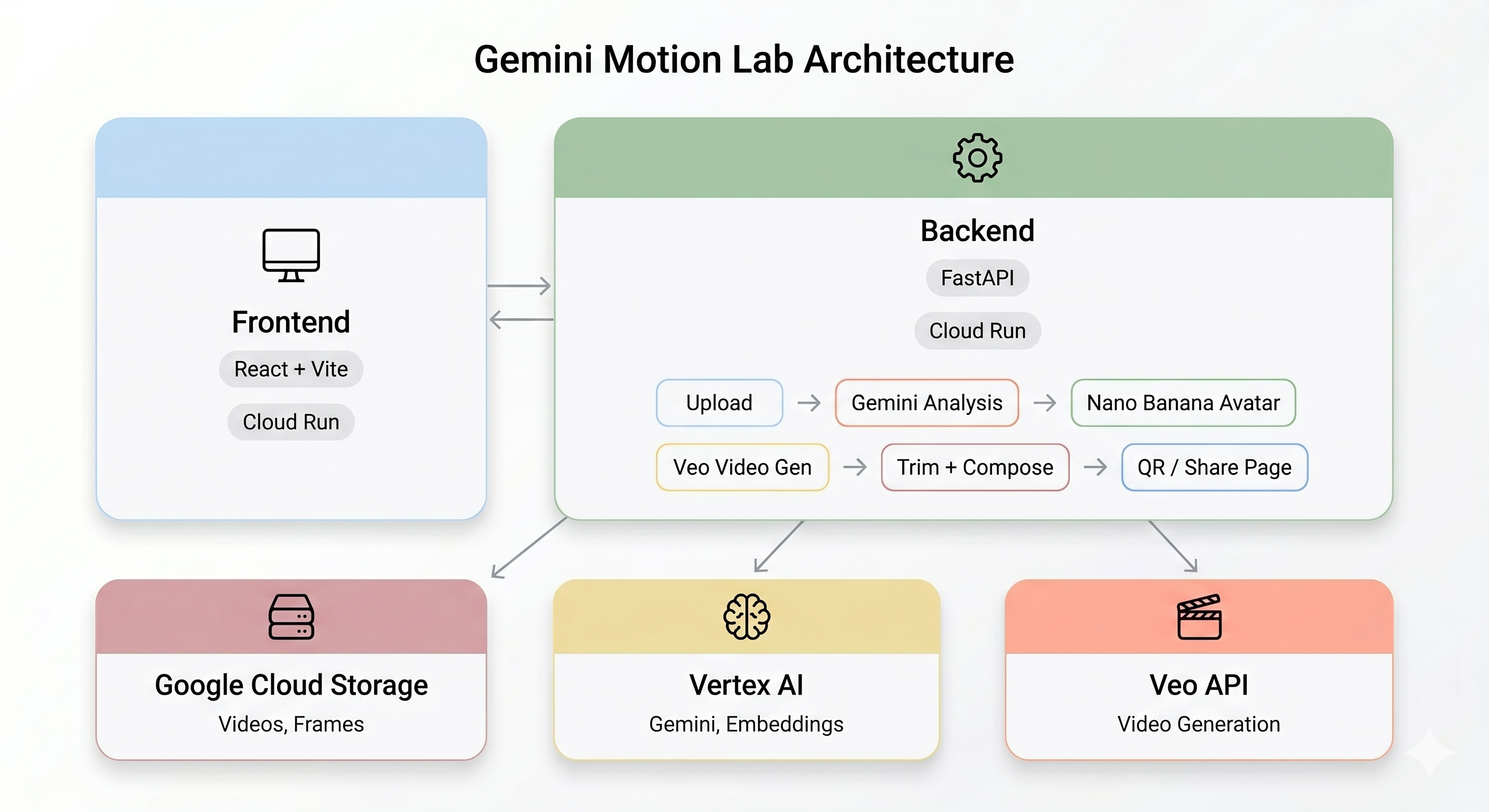
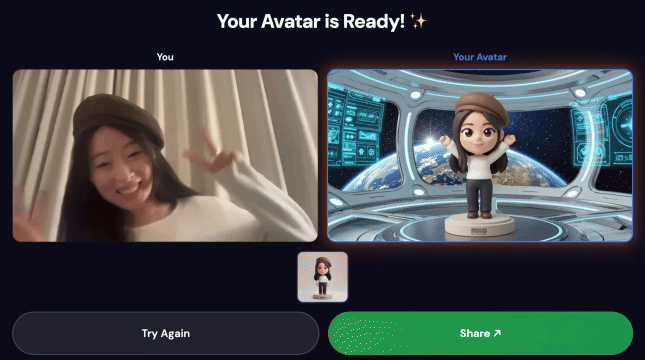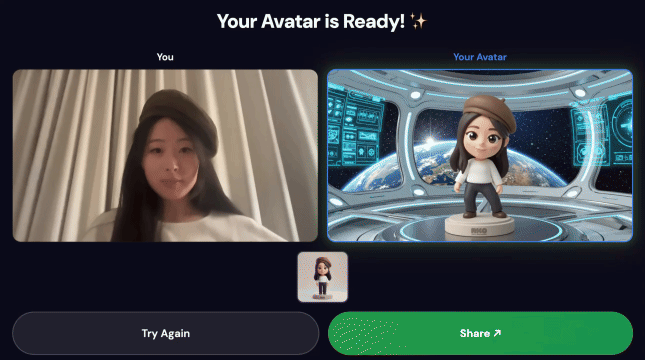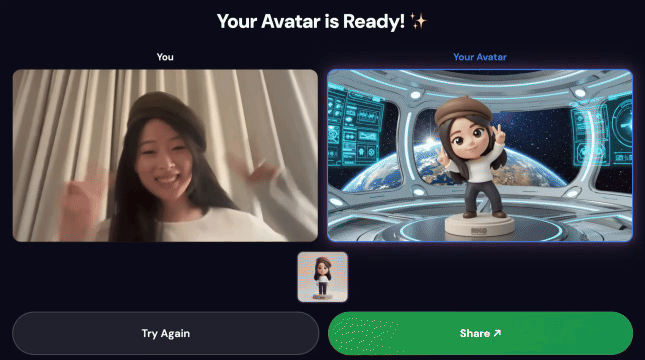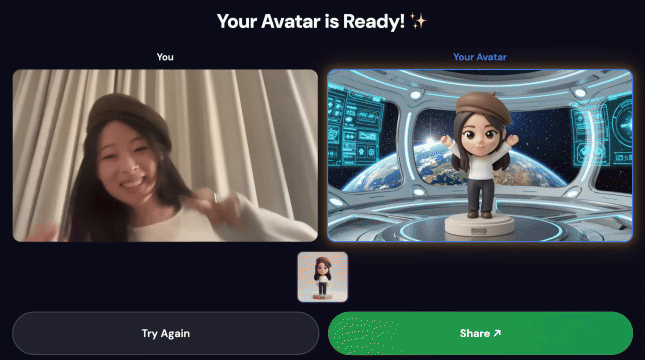
Abschließende Demo:
Kerntechnologien
Komponente | Technologie | Zweck |
Bewegungsanalyse | Gemini Flash | Video auf Körperbewegungen, Phasen und Stil analysieren |
Avatar-Erstellung | Gemini Flash Image (Nano Banana) | Stilisierten Avatar mit einer Auflösung von 1.024 × 1.024 aus einem Keyframe generieren |
Videogenerierung | Veo 3.1 | KI-Video aus dem Avatar- und Bewegungs-Prompt erstellen |
Backend | FastAPI + Python 3.11 | API-Server mit asynchroner Pipeline-Orchestrierung |
Frontend | React + Vite + TypeScript | Kiosk-Benutzeroberfläche mit Kameraaufzeichnung und Livestatus |
Hosting | Cloud Run | Serverlose containerisierte Bereitstellung |
Speicher | Google Cloud Storage | Videouploads, Frames, geschnittene und zusammengesetzte Ausgaben |
2. 📦 Repository klonen
1. Cloud Shell-Editor öffnen
👉 Öffnen Sie den Cloud Shell-Editor in Ihrem Browser.
Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal.
2. Code klonen
👉💻 Klonen Sie das Repository im Terminal:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Projektstruktur ansehen
So sieht das Repository-Layout aus:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Gutschriften einlösen und GCP-Projekt erstellen
Teil 1: Abrechnungsguthaben sichern
👉 Fordern Sie Ihr Guthaben für das Abrechnungskonto mit Ihrem Gmail-Konto an.
Teil 2: Neues Projekt erstellen
👉💻 Machen Sie das Initialisierungsskript im Terminal ausführbar und führen Sie es aus:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Das Skript init.sh tut Folgendes:
- Erstellen Sie ein neues GCP-Projekt mit dem Präfix
gemini-motion-lab. - Speichern Sie die Projekt-ID in
~/project_id.txt. - Abrechnungsabhängigkeiten installieren und Rechnungskonto automatisch verknüpfen
Teil 3: Projekt konfigurieren und APIs aktivieren
👉💻 Legen Sie Ihre Projekt-ID im Terminal fest:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Aktivieren Sie die für dieses Projekt erforderlichen Google Cloud APIs (dies dauert etwa 1–2 Minuten):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [NUR LESEN] Informationen zur Architektur
In diesem Abschnitt wird die Funktionsweise der KI-Pipeline von Anfang bis Ende erläutert. Keine Aktion erforderlich: Lesen Sie sich die Informationen durch, um das System vor der Bereitstellung zu verstehen.
Die KI-Pipeline
Wenn ein Nutzer am Kiosk einen Bewegungsclip aufnimmt, werden fünf Phasen nacheinander durchlaufen:

Phase 1: Video hochladen
Das Frontend zeichnet einen 5-Sekunden-WebM-Clip von der Kamera des Nutzers auf und lädt ihn über den /api/upload-Endpunkt des Backends in Google Cloud Storage hoch.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Phase 2: Gemini Motion Analysis
Das Backend sendet das hochgeladene Video zur strukturierten Analyse an Gemini Flash (gemini-3-flash-preview).
Funktionsweise (backend/app/services/gemini_service.py):
Der Dienst verwendet das client.models.generate_content() des Vertex AI SDK mit dem Video als Part.from_uri-Eingabe und einem strukturierten Prompt. Mit response_mime_type="application/json" wird sichergestellt, dass Gemini analysierbares JSON zurückgibt. Das Modell verwendet auch ThinkingConfig(thinking_budget=1024), um Bewegungsphasen besser nachvollziehen zu können.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Phase 3: Nano Banana-Avatargenerierung
Gemini Flash Image (gemini-3.1-flash-image-preview) verwendet den besten Frame aus dem Video, um einen stilisierten Avatar mit einer Auflösung von 1024 × 1024 Pixeln zu generieren.
Funktionsweise (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
Die generierte Avatar-PNG-Datei wird in GCS hochgeladen und an die nächste Phase übergeben.
Phase 4: Videogenerierung mit Veo
Das Avatarbild wird als Referenz-Asset für Veo 3.1 (veo-3.1-fast-generate-001) verwendet, um ein 8‑sekündiges KI-Video zu generieren.
Funktionsweise (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Die Veo-Generierung ist asynchron – es wird sofort eine Vorgangs-ID zurückgegeben. Das Backend fragt den Vorgang ab, bis er abgeschlossen ist (bis zu 10 Minuten).
Phase 5: Nachbearbeitungspipeline
Sobald Veo abgeschlossen ist, wird automatisch die Hintergrundpipeline (backend/app/services/pipeline.py) ausgeführt:
- Kürze die 8 Sekunden lange Veo-Ausgabe auf 3 Sekunden.
- Nebeneinander stellen: Originalaufnahme links, KI-Video rechts
- Das zusammengesetzte Video in GCS hochladen
- Warteschlangenplatz freigeben
Diese Pipeline wird als Hintergrundprozess asyncio.Task ausgeführt. Das Kiosk-Frontend muss nicht warten.
Das Warteschlangensystem
Da die Veo-Generierung ressourcenintensiv ist, gilt für das System ein Maximum von 3 gleichzeitigen Jobs:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Das Frontend prüft GET /api/queue/status, bevor ein neuer Nutzer eine Sitzung starten kann. Wenn eine Pipeline abgeschlossen ist und complete(video_id) aufgerufen wird, wird der Slot für den nächsten Nutzer geöffnet.
Cloud Run – Serverlose Container
Sowohl das Backend als auch das Frontend werden als Cloud Run-Dienste bereitgestellt:
Dienst | Zweck | Schlüsselkonfiguration |
Backend | FastAPI-API-Server | 2 GiB Arbeitsspeicher (für die Videoverarbeitung über ffmpeg) |
Frontend | Statische React-App, die von Nginx bereitgestellt wird | Standardarbeitsspeicher |
5. ⚙️ Setup-Skript ausführen
1. Automatisierte Einrichtung ausführen
Das Skript setup.sh erstellt die erforderlichen Cloud-Ressourcen und generiert die Datei .env.
👉💻 Machen Sie das Skript ausführbar und führen Sie es aus:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. IAM-Rollen zuweisen
Gewähren Sie dem Dienstkonto nun die erforderlichen Berechtigungen.
👉💻 Führen Sie die folgenden Befehle aus, um Ihre Projekt-ID festzulegen und alle drei Rollen zuzuweisen:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. .env-Datei bestätigen
👉💻 Generierte .env-Datei prüfen:
cat .env
Hier sollten Sie dies sehen:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Backend bereitstellen
1. Dockerfile für das Back-End
Sehen wir uns an, wie der Container aussieht, bevor wir ihn bereitstellen:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. In Cloud Run bereitstellen
👉💻 Umgebungsvariablen laden und bereitstellen:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Das dauert etwa 3–5 Minuten. Cloud Build führt folgende Aktionen aus:
- Quellcode hochladen
- Docker-Image erstellen
- Per Push in Artifact Registry übertragen
- In Cloud Run bereitstellen
3. Backend-URL speichern
👉💻 Speichern Sie nach der Bereitstellung die Back-End-URL:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Backend-Freigabe-URL aktualisieren
Im Backend werden QR‑Codes generiert, damit Nutzer ihre Videos herunterladen können. Dazu muss die öffentliche URL des Geräts bekannt sein.
👉💻 Aktualisieren Sie die Backend-Konfiguration mit der zugehörigen URL:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Backend prüfen
👉💻 Endpunkt für die Systemdiagnose testen:
curl $BACKEND_URL/api/health
Erwartete Ausgabe:
{"status":"ok"}
👉💻 Warteschlangenstatus prüfen:
curl $BACKEND_URL/api/queue/status
Erwartete Ausgabe:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Frontend bereitstellen
1. Frontend-Dockerfile verstehen
Das Frontend verwendet einen mehrstufigen Build. Zuerst wird die React-App erstellt und dann mit Nginx bereitgestellt:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. In Cloud Run bereitstellen
👉💻 Schreiben Sie zuerst die Backend-URL in eine .env-Datei, damit Vite sie zur Build-Zeit einfügen kann:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Stellen Sie jetzt das Frontend bereit:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Das dauert etwa 2–3 Minuten.
3. Frontend-URL abrufen
👉💻 Frontend-URL abrufen und öffnen:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Öffnen Sie die URL in Ihrem Browser. Sie sollten die Kiosk-Oberfläche von Gemini Motion Lab sehen.
8. 🎮 [OPTIONAL] Demo spielen
1. Bewegungsmodus aufzeichnen
- Öffnen Sie die Frontend-URL in Ihrem Browser (vorzugsweise Chrome, um die beste Kameraunterstützung zu erhalten).
- Klicken Sie auf Starten, um die Aufnahme zu starten.
- Tanze oder bewege dich etwa 5 Sekunden lang. Große Armbewegungen und dynamische Posen eignen sich am besten.
- Die Aufnahme wird automatisch beendet und hochgeladen
2. AI Pipeline ansehen
Nach dem Hochladen sehen Sie die Pipeline in Echtzeit:
Phase | Darum geht es | Dauer |
Wird analysiert… | Gemini Flash analysiert Ihr Video auf Bewegungsmuster. | ca. 5–10 Sekunden |
Avatar wird erstellt… | Nano Banana erstellt einen stilisierten Avatar aus Ihrem besten Frame | ~8–12 s |
Video wird erstellt… | Veo 3.1 generiert ein KI-Video aus dem Avatar und dem Bewegungs-Prompt. | ~60–120 Sekunden |
Wird erstellt… | ffmpeg schneidet das Video und erstellt einen Direktvergleich | ca. 5–10 Sekunden |
3. Werk teilen
Nach Abschluss der Pipeline:
- Auf dem Kioskbildschirm wird ein QR‑Code angezeigt.
- Scanne den QR‑Code mit deinem Smartphone.
- Es wird eine für Mobilgeräte optimierte Seite mit dem von dir erstellten Video angezeigt.
4. Back-End-Logs prüfen
👉💻 Hinter die Kulissen blicken:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Es werden Logzeilen angezeigt, die die Pipeline nachvollziehen:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Warteschlange beobachten
👉💻 Prüfen Sie, wie viele Jobs ausgeführt werden:
curl $BACKEND_URL/api/queue/status
Wenn drei Sitzungen gleichzeitig aktiv sind, wird in der Antwort Folgendes angezeigt:
{"active_jobs":3,"max_jobs":3,"available":false}
Neue Nutzer werden gebeten, zu warten, bis ein Platz frei wird.
9. 🎉 Fazit
Was Sie erstellt haben
✅ KI-Bewegungsanalyse: Gemini Flash analysiert Videos hinsichtlich Bewegung, Tempo und Stil.
✅ Avatargenerierung: Mit Nano Banana können stilisierte Avatare aus Videoframes erstellt werden.
✅ Videoerstellung mit KI: Veo 3.1 generiert neue Videos, die zur Bewegung des Nutzers passen.
✅ Asynchrone Pipeline: Hintergrundverarbeitung mit Warteschlangenverwaltung (max. 3 gleichzeitig)
✅ Nebeneinander-Komposition – auf ffmpeg basierende Videokomposition
✅ Cloud Run-Bereitstellung: Serverlos, automatische Skalierung, keine Serververwaltung
Wichtige Konzepte, die Sie gelernt haben
- Gemini Multimodal: Video als Eingabe senden und strukturierte JSON-Analyse erhalten
- Nano Banana (Gemini Image Generation): Avatare mit Referenzbildern und Stil-Prompts erstellen
- Veo 3.1: Asynchrone Videogenerierung mit Referenz-Assets und Text-Prompts
- Cloud Run – Container mit Umgebungsvariablen und Autoscaling bereitstellen
- Asynchrones Pipeline-Muster: Fire-and-Forget-Hintergrundaufgaben mit
asyncio.Taskfür KI-Vorgänge mit langer Ausführungszeit - Warteschlangenverwaltung: Gleichzeitige KI-Jobs werden ratenbegrenzt, um Kosten und API-Kontingente zu kontrollieren.
Architektur-Recap
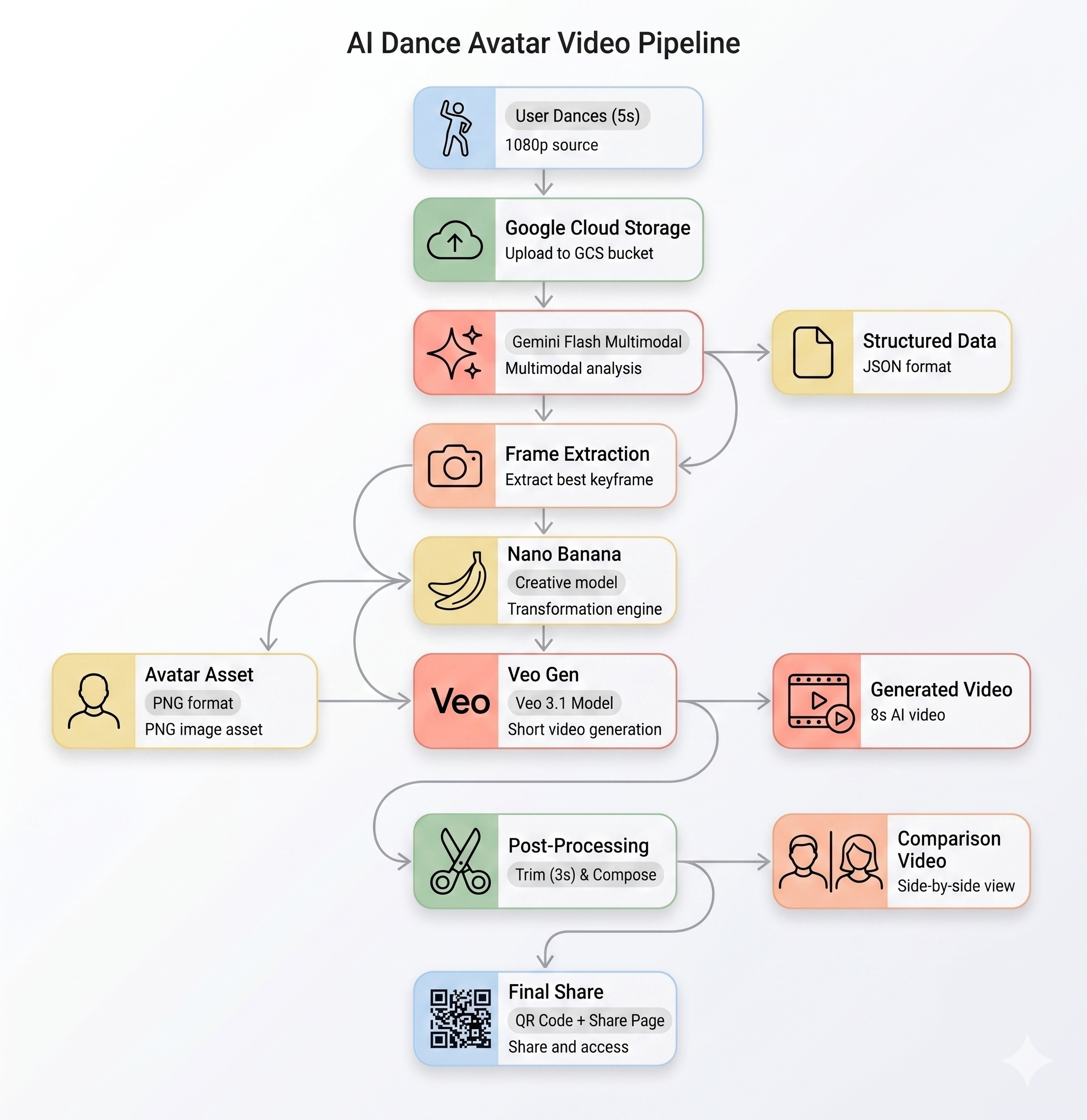
Wie geht es weiter?
- Weitere Avatarstile hinzufügen –
backend/app/prompts/avatar_generation.pybearbeiten - Veo-Prompt anpassen –
backend/app/prompts/video_generation.pybearbeiten - Lokal im Mock-Modus ausführen: Legen Sie
MOCK_AI=truein.envfür die Entwicklung ohne API-Aufrufe fest. - Reichweite für Ereignisse erhöhen –
--max-instancesundMAX_CONCURRENT_JOBSsteigern