
1. Introducción
Qué compilará
Gemini Motion Lab es una experiencia interactiva potenciada por IA. Un usuario graba un clip corto de baile o movimiento, y el sistema hace lo siguiente:
- Analiza el movimiento con Gemini (partes del cuerpo, fases, ritmo, energía).
- Genera una imagen de avatar estilizada con Nano Banana (Gemini Flash Image)
- Crea un video de IA con Veo que recrea el movimiento con el avatar.
- Compone un video en paralelo (original y generado por IA)
- Comparte el resultado a través de un código QR en una página optimizada para dispositivos móviles.
Al final de este codelab, habrás implementado la demostración completa en Google Cloud Run y comprenderás la canalización de IA que la impulsa.
Descripción general de la arquitectura
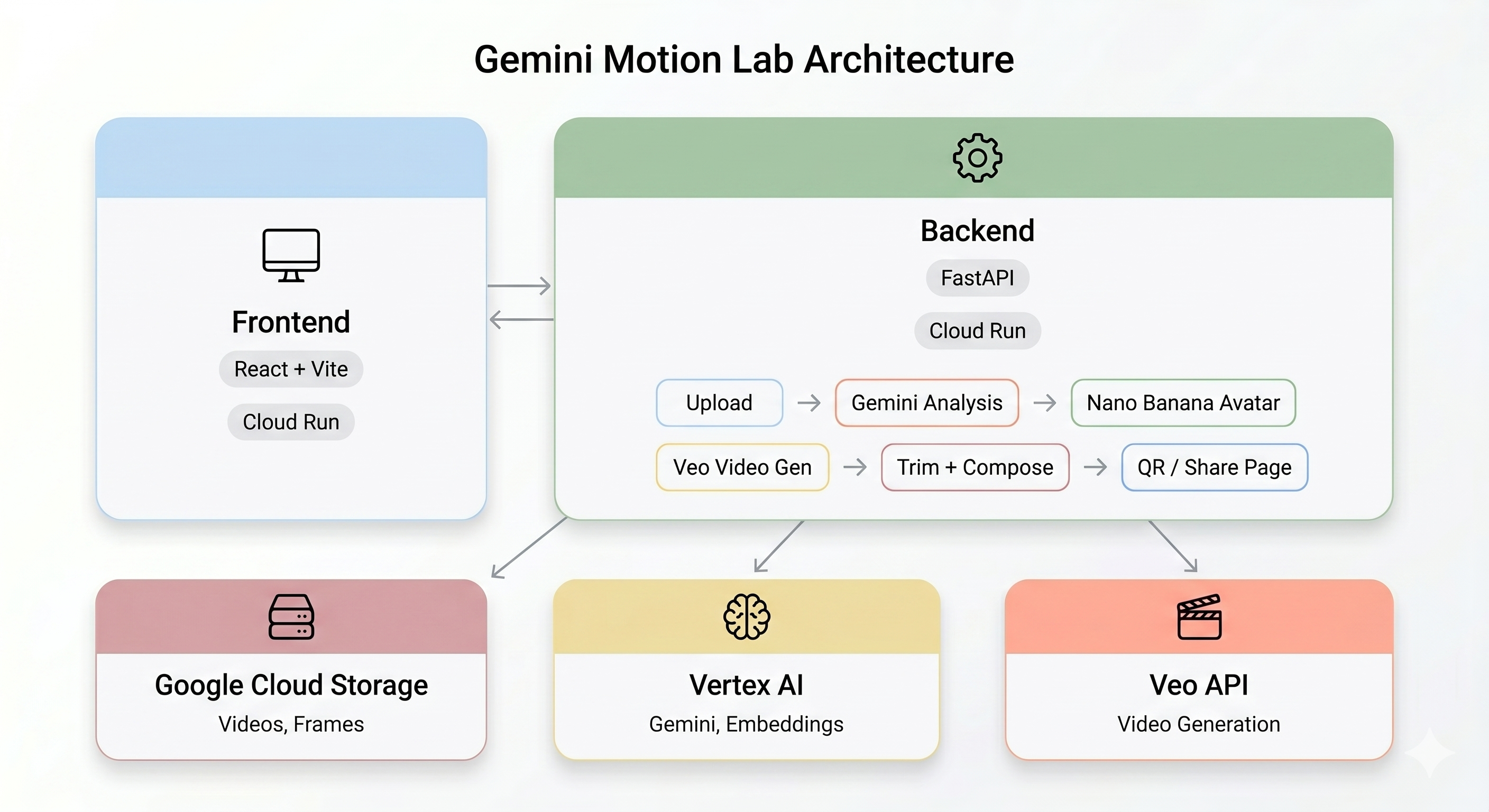
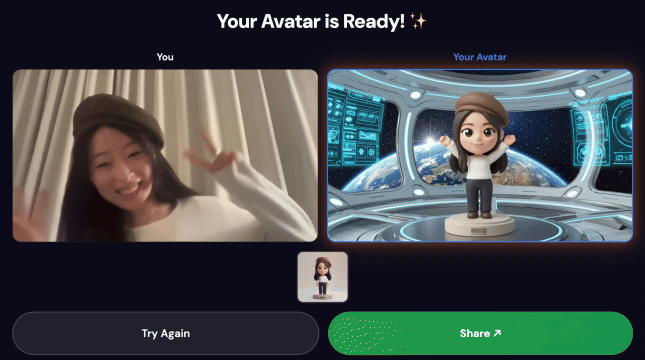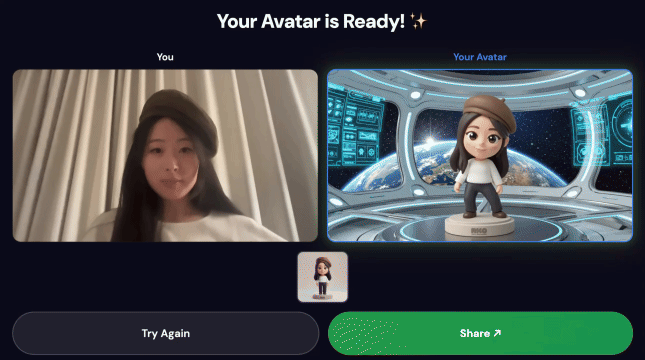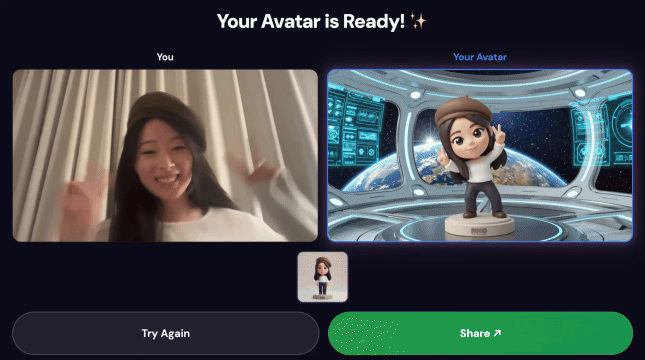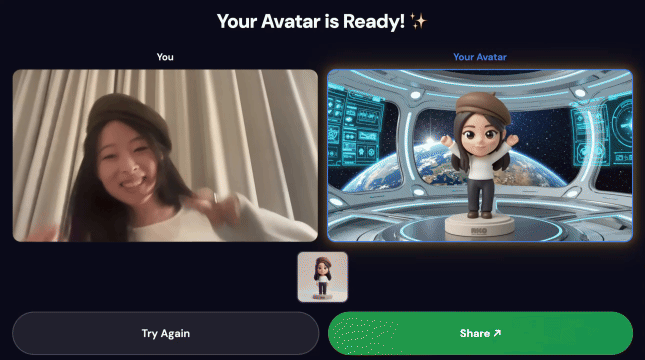
Demostración final:
Tecnologías principales
Componente | Tecnología | Objetivo |
Análisis de movimiento | Gemini Flash | Analiza el video para detectar el movimiento corporal, las fases y el estilo. |
Generación de avatares | Gemini Flash Image (Nano Banana) | Genera un avatar estilizado de 1,024 × 1,024 a partir de un fotograma clave |
Generación de video | Veo 3.1 | Crea un video con IA a partir del avatar y la instrucción de movimiento |
Backend | FastAPI + Python 3.11 | Servidor de API con organización de canalizaciones asíncronas |
Frontend | React + Vite + TypeScript | IU de kiosko con grabación de cámara y estado en vivo |
Hosting | Cloud Run | Implementación sin servidores alojada en contenedores |
Almacenamiento | Google Cloud Storage | Cargas de videos, fotogramas y salidas recortadas y compuestas |
2. 📦 Clona el repositorio
1. Abre el editor de Cloud Shell
👉 Abre el Editor de Cloud Shell en tu navegador.
Si la terminal no aparece en la parte inferior de la pantalla, haz lo siguiente:
- Haz clic en Ver.
- Haz clic en Terminal.
2. Clona el código
👉💻 En la terminal, clona el repositorio:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Explora la estructura del proyecto
Echa un vistazo rápido al diseño del repositorio:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Reclama créditos y crea un proyecto de GCP
Parte 1: Reclama tus créditos de facturación
👉 Reclama el crédito de tu cuenta de facturación con tu cuenta de Gmail.
Parte 2: Crea un proyecto nuevo
👉💻 En la terminal, haz que la secuencia de comandos de inicialización sea ejecutable y ejecútala:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
La secuencia de comandos init.sh hará lo siguiente:
- Crea un proyecto de GCP nuevo con el prefijo
gemini-motion-lab. - Guarda el ID del proyecto en
~/project_id.txt. - Instala dependencias de facturación y vincula automáticamente tu cuenta de facturación
Parte 3: Configura el proyecto y habilita las APIs
👉💻 Establece tu ID del proyecto en la terminal:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Habilita las APIs de Google Cloud necesarias para este proyecto (esto tarda entre 1 y 2 minutos):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [SOLO LECTURA] Información sobre la arquitectura
En esta sección, se explica cómo funciona la canalización de IA de extremo a extremo. No se requiere ninguna acción: Solo lee para comprender el sistema antes de la implementación.
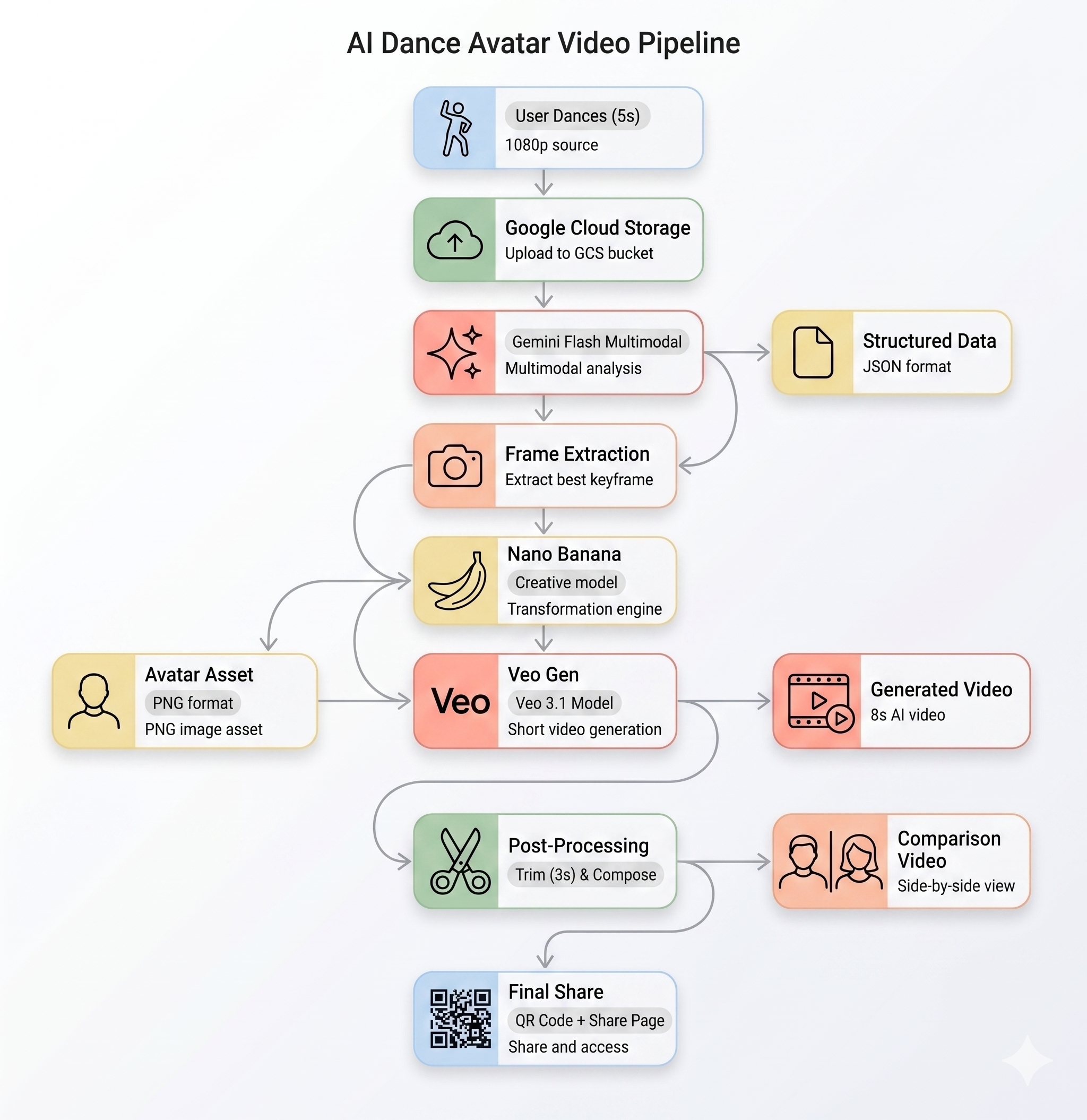
La canalización de IA
Cuando un usuario graba un clip de movimiento en la estación, se ejecutan cinco etapas en secuencia:

Etapa 1: Carga de videos
El frontend graba un clip de WebM de 5 segundos desde la cámara del usuario y lo sube a Google Cloud Storage a través del extremo /api/upload del backend.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Etapa 2: Análisis de movimiento con Gemini
El backend envía el video subido a Gemini Flash (gemini-3-flash-preview) para su análisis estructurado.
Cómo funciona (backend/app/services/gemini_service.py):
El servicio usa client.models.generate_content() del SDK de Vertex AI con el video como entrada Part.from_uri y una instrucción estructurada. El parámetro response_mime_type="application/json" garantiza que Gemini devuelva un JSON analizable. El modelo también usa ThinkingConfig(thinking_budget=1024) para razonar mejor sobre las fases de movimiento.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Etapa 3: Generación de avatares con Nano Banana
Con el mejor fotograma extraído del video, Gemini Flash Image (gemini-3.1-flash-image-preview) genera un avatar estilizado de 1,024 × 1,024.
Cómo funciona (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
El PNG del avatar generado se sube a GCS y se pasa a la siguiente etapa.
Etapa 4: Generación de video con Veo
La imagen del avatar se usa como un recurso de referencia para Veo 3.1 (veo-3.1-fast-generate-001) y generar un video de IA de 8 segundos.
Cómo funciona (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
La generación de Veo es asíncrona, ya que muestra un ID de operación de inmediato. El backend sondea la operación hasta que se completa (hasta 10 minutos).
Etapa 5: Canalización de posprocesamiento
Una vez que Veo completa la tarea, se ejecuta automáticamente la canalización en segundo plano (backend/app/services/pipeline.py):
- Corta el video de 8 s generado por Veo a 3 segundos.
- Compón un video en paralelo (grabación original a la izquierda y video de IA a la derecha).
- Sube el video compuesto a GCS.
- Libera el espacio de la fila.
Esta canalización se ejecuta como un asyncio.Task en segundo plano, por lo que el frontend del kiosco no necesita esperar.
El sistema de filas
Dado que la generación de Veo requiere muchos recursos, el sistema aplica un máximo de 3 trabajos simultáneos:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
El frontend realiza una verificación de GET /api/queue/status antes de permitir que un usuario nuevo inicie una sesión. Cuando se completa una canalización y se llama a complete(video_id), la ranura se abre para el siguiente usuario.
Cloud Run: Contenedores sin servidores
Tanto el backend como el frontend se implementan como servicios de Cloud Run:
Servicio | Objetivo | Configuración de la llave |
Backend | Servidor de la API de FastAPI | 2 GiB de memoria (para el procesamiento de video a través de ffmpeg) |
Frontend | App de React estática publicada por Nginx | Memoria predeterminada |
5. ⚙️ Ejecutar secuencia de comandos de configuración
1. Ejecuta la configuración automática
La secuencia de comandos setup.sh crea los recursos de Cloud necesarios y genera tu archivo .env.
👉💻 Haz que la secuencia de comandos sea ejecutable y ejecútala:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Otorga roles de IAM
Ahora otorga los permisos necesarios a la cuenta de servicio.
👉💻 Ejecuta los siguientes comandos para establecer el ID del proyecto y otorgar los tres roles:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Verifica tu archivo de .env
👉💻 Comprueba el archivo .env generado:
cat .env
Deberías ver lo siguiente:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Implementa el backend
1. Información sobre el Dockerfile de backend
Antes de la implementación, veamos cómo se ve el contenedor:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Implementa en Cloud Run
👉💻 Carga tus variables de entorno y realiza la implementación:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Este proceso tarda entre 3 y 5 minutos. Cloud Build hará lo siguiente:
- Sube tu código fuente
- Compila la imagen de Docker
- Envía el contenedor a Artifact Registry
- Implementa en Cloud Run
3. Cómo guardar la URL del backend
👉💻 Una vez que se implemente, guarda la URL del backend:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Actualiza la URL de uso compartido del backend
El backend genera códigos QR para que los usuarios puedan descargar sus videos. Para ello, debe conocer su propia URL pública.
👉💻 Actualiza la configuración del backend con su propia URL:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Verifica el backend
👉💻 Prueba el extremo de estado:
curl $BACKEND_URL/api/health
Resultado esperado:
{"status":"ok"}
👉💻 Verifica el estado de la fila:
curl $BACKEND_URL/api/queue/status
Resultado esperado:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Implementa el frontend
1. Información sobre el Dockerfile del frontend
El frontend usa una compilación de varias etapas: primero compila la app de React y, luego, la entrega con Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Implementa en Cloud Run
👉💻 Primero, escribe la URL de backend en un archivo .env para que Vite pueda incorporarla en el tiempo de compilación:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Ahora implementa el frontend:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Este proceso tarda entre 2 y 3 minutos.
3. Obtén la URL de frontend
👉💻 Recupera y abre la URL del frontend:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Abre la URL en tu navegador. Deberías ver la interfaz de la estación de Gemini Motion Lab.
8. 🎮 [OPCIONAL] Juega con la demostración
1. Cómo grabar un movimiento
- Abre la URL de frontend en tu navegador (preferentemente Chrome para obtener la mejor compatibilidad con la cámara).
- Haz clic en Iniciar para comenzar a grabar.
- Baila o muévete durante unos 5 segundos. Los movimientos grandes de los brazos y las poses dinámicas funcionan mejor.
- La grabación se detendrá y subirá automáticamente.
2. Observa la canalización de IA
Después de la carga, verás la ejecución de la canalización en tiempo real:
Fase | Qué sucede | Duración |
Analizando… | Gemini Flash analiza tu video en busca de patrones de movimiento | Entre 5 y 10 s |
Generando avatar… | Nano Banana crea un avatar estilizado a partir de tu mejor fotograma | Aprox. 8 a 12 s |
Creando video… | Veo 3.1 genera un video de IA a partir del avatar y la instrucción de movimiento. | Entre 60 y 120 s |
Redactando… | ffmpeg recorta y crea una comparación en paralelo | Entre 5 y 10 s |
3. Comparte tu creación
Una vez que se complete la canalización, haz lo siguiente:
- Aparecerá un código QR en la pantalla de la estación de carga.
- Escanea el código QR con tu teléfono.
- Verás una página para compartir optimizada para dispositivos móviles con el video que creaste.
4. Verifica los registros de backend
👉💻 Mira lo que sucedió tras bambalinas:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Verás líneas de registro que rastrean la canalización:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Supervisa la fila
👉💻 Comprueba cuántos trabajos se están ejecutando:
curl $BACKEND_URL/api/queue/status
Si hay 3 sesiones activas de forma simultánea, la respuesta mostrará lo siguiente:
{"active_jobs":3,"max_jobs":3,"available":false}
A los usuarios nuevos se les pedirá que esperen hasta que se abra un espacio.
9. 🎉 Conclusión
Qué compilaste
✅ Análisis de movimiento con IA: Gemini Flash analiza el movimiento, el ritmo y el estilo de los videos.
✅ Generación de avatares: Nano Banana crea avatares estilizados a partir de fotogramas de video.
✅ Generación de video con IA: Veo 3.1 genera videos nuevos que coinciden con el movimiento del usuario.
✅ Async Pipeline: Procesamiento en segundo plano con administración de filas (máx. 3 procesos simultáneos)
✅ Composición en paralelo: Composición de video con tecnología de ffmpeg
✅ Implementación de Cloud Run: Sin servidores, con ajuste de escala automático y sin administración de servidores
Conceptos clave que aprendiste
- Gemini Multimodal: Envía videos como entrada y recibe análisis estructurados en formato JSON
- Nano Banana (generación de imágenes con Gemini): Uso de imágenes de referencia y mensajes de estilo para generar avatares
- Veo 3.1: Generación asíncrona de videos con recursos de referencia y mensajes de texto
- Cloud Run: Implementación de contenedores con variables de entorno y escalamiento automático
- Patrón de canalización asíncrona: Tareas en segundo plano de activación y recuperación con
asyncio.Taskpara operaciones de IA de larga duración - Administración de filas: Limita la frecuencia de los trabajos simultáneos de IA para controlar los costos y las cuotas de la API
Recap de arquitectura
¿Qué sigue?
- Agregar más estilos de avatar: Edita
backend/app/prompts/avatar_generation.py. - Personaliza la instrucción de Veo: Edita
backend/app/prompts/video_generation.py - Ejecuta de forma local en modo de simulación: Establece
MOCK_AI=trueen.envpara el desarrollo sin llamadas a la API - Escala para eventos: Aumenta
--max-instancesyMAX_CONCURRENT_JOBS