
۱. مقدمه
آنچه خواهید ساخت
آزمایشگاه حرکت جمینی (Gemini Motion Lab) یک تجربه کیوسک زنده مبتنی بر هوش مصنوعی است. کاربر یک کلیپ کوتاه رقص یا حرکت ضبط میکند و سیستم:
- تجزیه و تحلیل حرکت با استفاده از Gemini (اعضای بدن، مراحل، سرعت، انرژی)
- با استفاده از Nano Banana (Gemini Flash Image) یک تصویر آواتار با استایل خاص تولید میکند.
- با استفاده از Veo یک ویدیوی هوش مصنوعی ایجاد میکند که حرکت را با آواتار بازسازی میکند.
- یک ویدیوی کنار هم (اصلی + تولید شده توسط هوش مصنوعی) میسازد .
- نتیجه را از طریق یک کد QR در یک صفحه بهینه شده برای موبایل به اشتراک میگذارد
در پایان این آزمایشگاه کد، شما نسخه آزمایشی کامل را در Google Cloud Run مستقر خواهید کرد و با خط لوله هوش مصنوعی که آن را پشتیبانی میکند، آشنا خواهید شد.
نمای کلی معماری
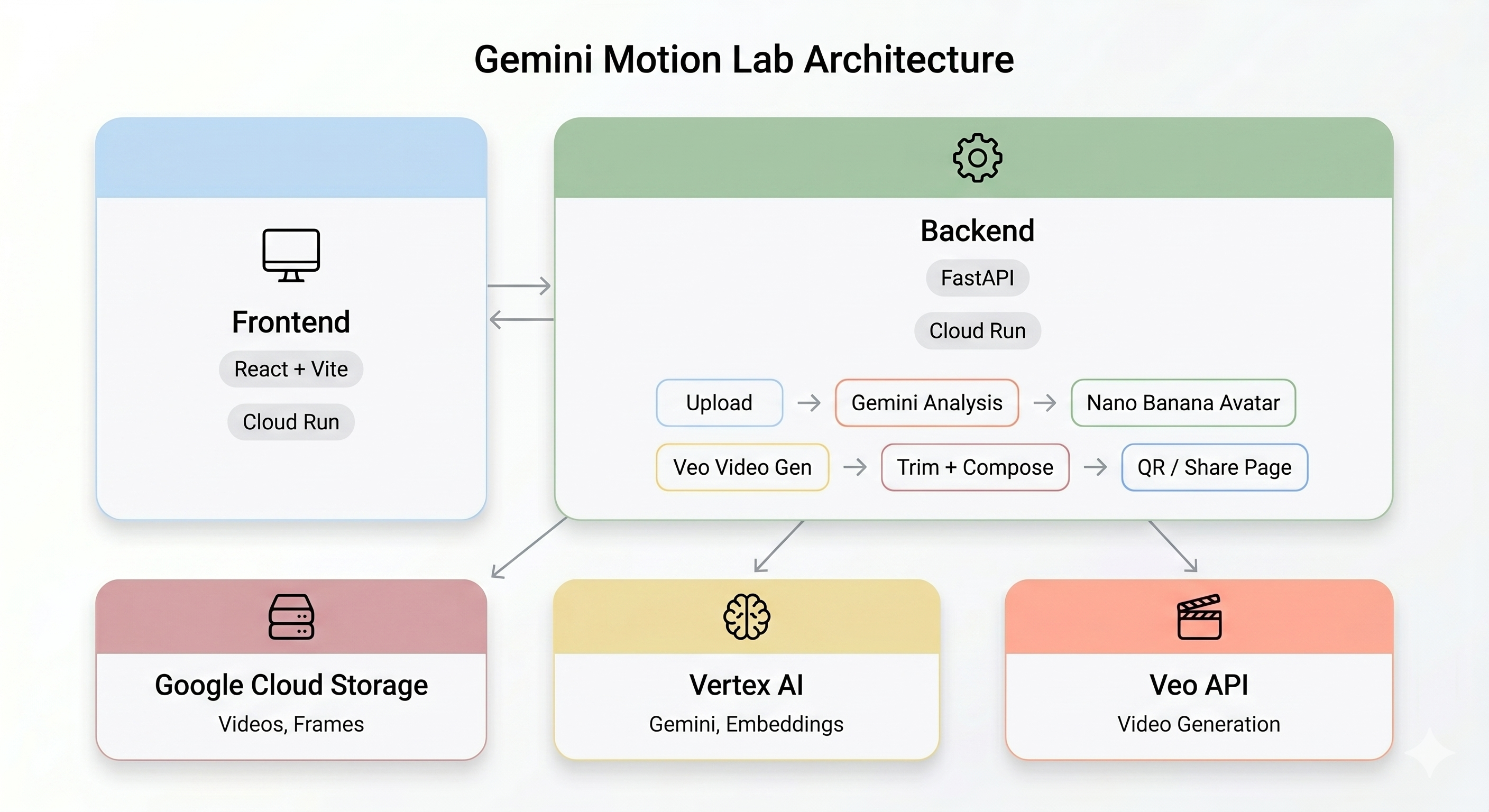
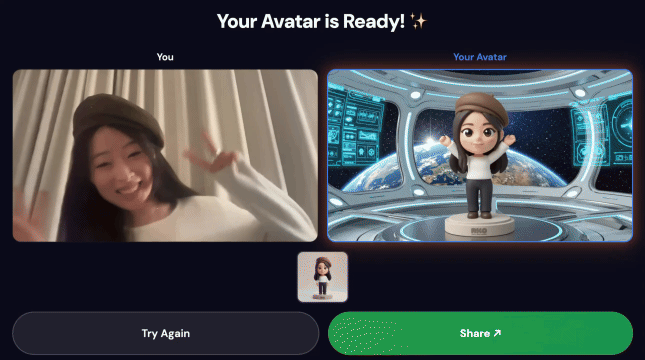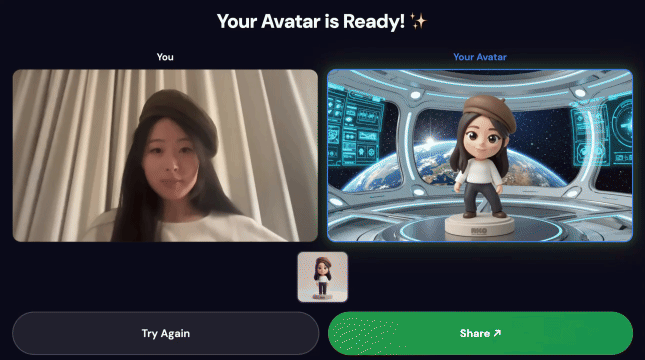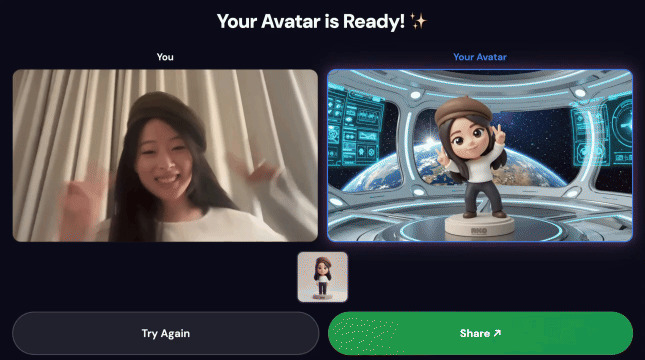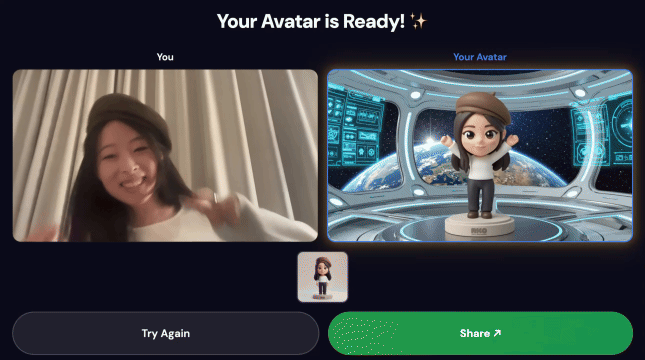
نسخه آزمایشی نهایی:
فناوریهای اصلی
کامپوننت | فناوری | هدف |
تحلیل حرکت | فلش جمینی | تجزیه و تحلیل ویدیو برای حرکات بدن، حالتها و سبک |
نسل آواتار | تصویر فلش جوزا (نانو موز) | ایجاد یک آواتار با ابعاد ۱۰۲۴×۱۰۲۴ از یک فریم کلیدی |
تولید ویدئو | وئو ۳.۱ | یک ویدیوی هوش مصنوعی از آواتار + حرکت سریع ایجاد کنید |
بکاند | FastAPI + پایتون ۳.۱۱ | سرور API با هماهنگی خط لوله ناهمزمان |
ظاهر (فرانتاند) | ریاکت + وایت + تایپاسکریپت | رابط کاربری کیوسک با قابلیت ضبط دوربین و نمایش زنده وضعیت |
میزبانی وب | اجرای ابری | استقرار کانتینری بدون سرور |
ذخیرهسازی | فضای ذخیرهسازی ابری گوگل | آپلود ویدیو، فریم، خروجیهای برش خورده و ترکیب شده |
۲. 📦 کپی کردن مخزن
۱. ویرایشگر Cloud Shell را باز کنید
👉 ویرایشگر Cloud Shell را در مرورگر خود باز کنید.
اگر ترمینال در پایین صفحه نمایش داده نشد:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
۲. کپی کردن کد
👉💻 در ترمینال، مخزن را کلون کنید:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
۳. ساختار پروژه را بررسی کنید
نگاهی سریع به طرح مخزن بیندازید:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
۳. 🛠️ درخواست اعتبار و ایجاد پروژه GCP
بخش ۱: اعتبار صورتحساب خود را مطالبه کنید
👉 با استفاده از حساب جیمیل خود، اعتبار حساب صورتحساب خود را مطالبه کنید.
بخش دوم: ایجاد یک پروژه جدید
👉💻 در ترمینال، اسکریپت init را قابل اجرا کنید و آن را اجرا کنید:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
اسکریپت init.sh موارد زیر را انجام خواهد داد:
- یک پروژه GCP جدید با پیشوند
gemini-motion-labایجاد کنید - شناسه پروژه را در
~/project_id.txtذخیره کنید - وابستگیهای صورتحساب را نصب کنید و حساب صورتحساب خود را به طور خودکار پیوند دهید
بخش ۳: پیکربندی پروژه و فعالسازی APIها
👉💻 شناسه پروژه خود را در ترمینال تنظیم کنید:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 فعال کردن APIهای گوگل کلود مورد نیاز برای این پروژه (این کار حدود ۱ تا ۲ دقیقه طول میکشد):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
۴. 🧠 [فقط بخوانید] درک معماری
این بخش نحوهی عملکرد خط لولهی هوش مصنوعی را از ابتدا تا انتها توضیح میدهد. نیازی به انجام هیچ کاری نیست - فقط قبل از استقرار، برای درک سیستم، آن را مطالعه کنید.
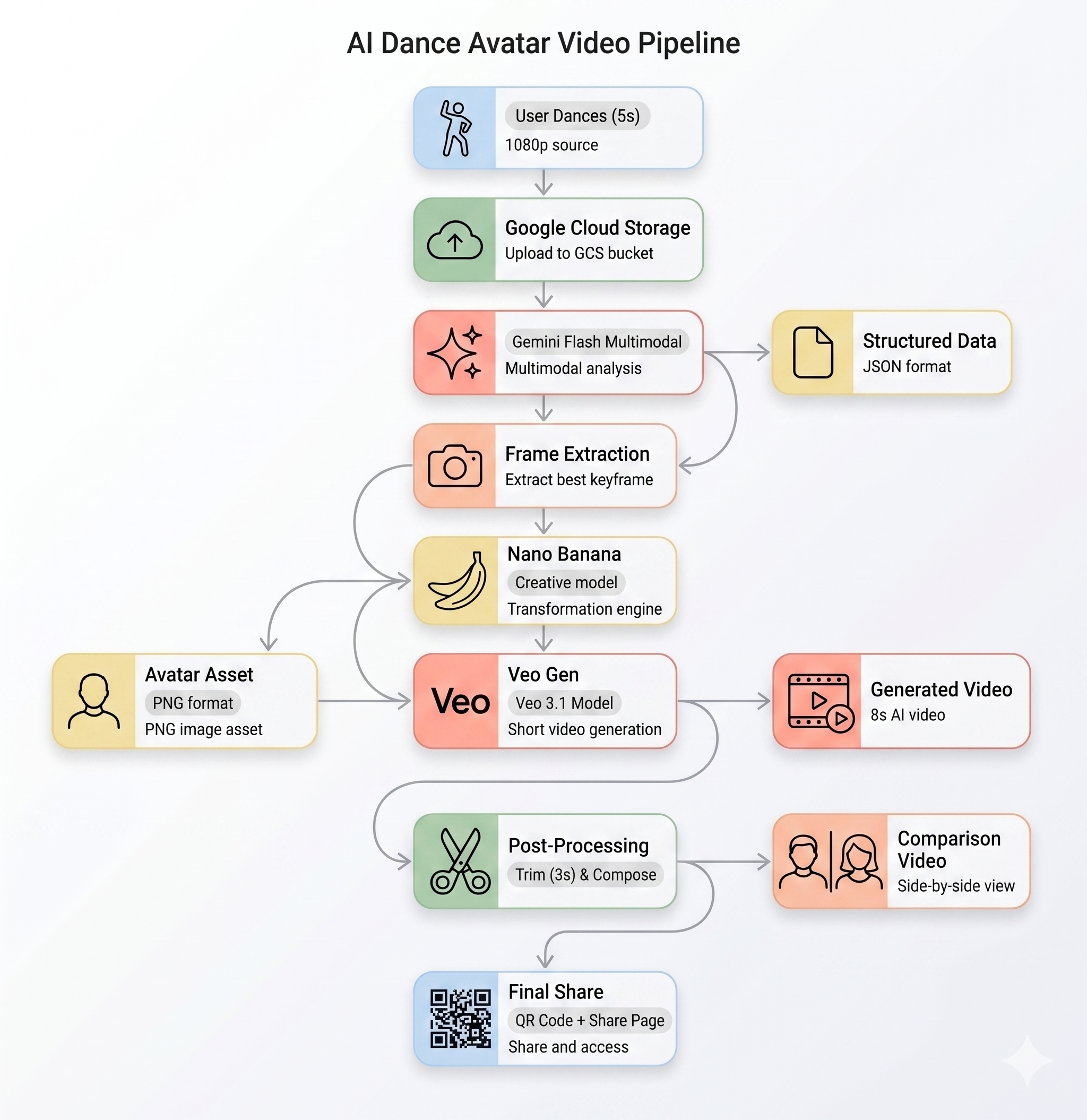
خط لوله هوش مصنوعی
وقتی کاربری در کیوسک یک کلیپ متحرک ضبط میکند، پنج مرحله به ترتیب اجرا میشوند:

مرحله ۱: آپلود ویدیو
بخش فرانتاند یک کلیپ ۵ ثانیهای WebM را از دوربین کاربر ضبط میکند و آن را از طریق نقطه پایانی /api/upload در بخش بکاند، در فضای ذخیرهسازی ابری گوگل آپلود میکند.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
مرحله ۲: تحلیل حرکت جمینی
بخش مدیریت، ویدیوی آپلود شده را برای تجزیه و تحلیل ساختاریافته به Gemini Flash ( gemini-3-flash-preview ) ارسال میکند.
نحوه کار ( backend/app/services/gemini_service.py ):
این سرویس از client.models.generate_content() مربوط به Vertex AI SDK به همراه ویدیو به عنوان ورودی Part.from_uri و یک اعلان ساختاریافته استفاده میکند. response_mime_type="application/json" تضمین میکند که Gemini JSON قابل تجزیه را برمیگرداند. این مدل همچنین از ThinkingConfig(thinking_budget=1024) برای استدلال بهتر در مورد مراحل حرکت استفاده میکند.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
مرحله ۳: تولید آواتار نانو موز
با استفاده از بهترین فریم استخراج شده از ویدیو، ابزار Gemini Flash Image ( gemini-3.1-flash-image-preview ) یک آواتار با ابعاد 1024×1024 پیکسل تولید میکند.
نحوهی کار ( backend/app/services/nano_banana_service.py ):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
تصویر PNG آواتار تولید شده در GCS آپلود شده و به مرحله بعدی منتقل میشود.
مرحله ۴: تولید ویدیوی Veo
تصویر آواتار به عنوان یک منبع مرجع برای Veo 3.1 ( veo-3.1-fast-generate-001 ) برای تولید یک ویدیوی هوش مصنوعی ۸ ثانیهای استفاده میشود.
نحوه کار ( backend/app/services/veo_service.py ):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
تولید Veo ناهمزمان است - بلافاصله یک شناسه عملیات را برمیگرداند. بکاند عملیات را تا زمان تکمیل (تا 10 دقیقه) بررسی میکند.
مرحله ۵: خط لوله پس از پردازش
پس از اتمام Veo، خط لوله پسزمینه ( backend/app/services/pipeline.py ) به طور خودکار اجرا میشود:
- خروجی ۸ ثانیهای Veo را به ۳ ثانیه کاهش دهید
- یک ویدیوی کنار هم بسازید (ضبط اصلی در سمت چپ، ویدیوی هوش مصنوعی در سمت راست)
- ویدیوی ساخته شده را در GCS آپلود کنید
- جایگاه صف را آزاد کنید
این خط لوله به عنوان یک asyncio.Task پسزمینه اجرا میشود - نیازی نیست که رابط کاربری کیوسک منتظر بماند.
سیستم صف
از آنجایی که تولید Veo منابع زیادی مصرف میکند، سیستم حداکثر ۳ کار همزمان را اجرا میکند:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
قبل از اینکه به کاربر جدید اجازه شروع جلسه داده شود، frontend دستور GET /api/queue/status بررسی میکند. وقتی یک pipeline تکمیل میشود و complete(video_id) فراخوانی میشود، اسلات برای کاربر بعدی باز میشود.
اجرای ابری - کانتینرهای بدون سرور
هر دو بخش بکاند و فرانتاند به عنوان سرویسهای Cloud Run مستقر شدهاند:
خدمات | هدف | پیکربندی کلید |
بکاند | سرور API فستاِیاِی | ۲ گیگابایت حافظه (برای پردازش ویدیو از طریق ffmpeg) |
ظاهر (فرانتاند) | برنامه استاتیک React که توسط Nginx ارائه میشود | حافظه پیشفرض |
۵. ⚙️ اجرای اسکریپت راهاندازی
۱. راهاندازی خودکار را اجرا کنید
اسکریپت setup.sh منابع ابری مورد نیاز را ایجاد کرده و فایل .env شما را تولید میکند.
👉💻 اسکریپت را قابل اجرا کنید و آن را اجرا کنید:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
۲. اعطای نقش به IAM
اکنون مجوزهای لازم را به حساب سرویس اعطا کنید.
👉💻 دستورات زیر را برای تنظیم شناسه پروژه و اعطای هر سه نقش اجرا کنید:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
۳. فایل .env خود را تأیید کنید
👉💻 فایل .env تولید شده را بررسی کنید:
cat .env
شما باید ببینید:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
۶. 🚀 استقرار بکاند
۱. درک داکرفایل بکاند
قبل از استقرار، بیایید بفهمیم کانتینر چه شکلی است:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
۲. استقرار در Cloud Run
👉💻 متغیرهای محیطی خود را بارگذاری و مستقر کنید:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
این کار حدود ۳ تا ۵ دقیقه طول میکشد. ساخت ابری:
- کد منبع خود را آپلود کنید
- ساخت ایمیج داکر
- آن را به رجیستری مصنوعات فشار دهید
- آن را در Cloud Run مستقر کنید
۳. آدرس اینترنتی بکاند را ذخیره کنید
👉💻 پس از استقرار، آدرس اینترنتی (URL) بکاند را ذخیره کنید:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
۴. آدرس اشتراکگذاری بکاند را بهروزرسانی کنید
بخش پشتیبانی، کدهای QR تولید میکند تا کاربران بتوانند ویدیوهای خود را دانلود کنند. برای انجام این کار، باید URL عمومی خود را بداند.
👉💻 پیکربندی backend را با URL مخصوص خودش بهروزرسانی کنید:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
۵. بکاند را تأیید کنید
👉💻 نقطه پایانی سلامت را آزمایش کنید:
curl $BACKEND_URL/api/health
خروجی مورد انتظار:
{"status":"ok"}
👉💻 وضعیت صف را بررسی کنید:
curl $BACKEND_URL/api/queue/status
خروجی مورد انتظار:
{"active_jobs":0,"max_jobs":3,"available":true}
۷. 🎨 استقرار فرانتاند
۱. داکرفایل فرانتاند را درک کنید
رابط کاربری از یک ساخت چند مرحلهای استفاده میکند - ابتدا برنامه React را میسازد، سپس آن را با Nginx ارائه میدهد:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
۲. استقرار در Cloud Run
👉💻 ابتدا، آدرس URL مربوط به بکاند را در یک فایل .env بنویسید تا Vite بتواند آن را در زمان ساخت اضافه کند:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 اکنون رابط کاربری (frontend) را مستقر کنید:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
این کار حدود ۲-۳ دقیقه طول میکشد.
۳. آدرس اینترنتی فرانتاند را دریافت کنید
👉💻 آدرس اینترنتی (URL) بخش کاربری را بازیابی و باز کنید:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 آدرس اینترنتی (URL) را در مرورگر خود باز کنید - باید رابط کاربری کیوسک Gemini Motion Lab را ببینید!
۸. 🎮 [اختیاری] با نسخه آزمایشی بازی کنید
۱. ضبط یک حرکت
- URL مربوط به رابط کاربری را در مرورگر خود باز کنید (ترجیحاً کروم برای پشتیبانی بهتر از دوربین)
- برای شروع ضبط، روی شروع کلیک کنید
- حدود ۵ ثانیه برقصید یا حرکت کنید - حرکات بزرگ بازو و حالتهای پویا بهترین نتیجه را میدهند.
- ضبط به طور خودکار متوقف و آپلود خواهد شد
۲. به روند هوش مصنوعی توجه کنید
پس از آپلود، اجرای خط لوله را به صورت بلادرنگ مشاهده خواهید کرد:
فاز | چه اتفاقی دارد میافتد؟ | مدت زمان |
در حال تحلیل... | Gemini Flash ویدیوی شما را برای الگوهای حرکتی تجزیه و تحلیل میکند | ۵-۱۰ ثانیه |
تولید آواتار... | نانو موز از بهترین قاب شما یک آواتار با استایل خاص میسازد | ۸-۱۲ ثانیه |
در حال ساخت ویدیو... | Veo 3.1 یک ویدیوی هوش مصنوعی از آواتار + اعلان حرکت تولید میکند | ~۶۰-۱۲۰ ثانیه |
آهنگسازی... | ffmpeg برش میدهد و یک مقایسه پهلو به پهلو ایجاد میکند. | ۵-۱۰ ثانیه |
۳. اثر خود را به اشتراک بگذارید
پس از اتمام خط لوله:
- یک کد QR روی صفحه کیوسک ظاهر میشود
- کد QR را با گوشی خود اسکن کنید
- یک صفحه اشتراکگذاری بهینهشده برای موبایل را همراه با ویدیوی ساختهشده خود مشاهده خواهید کرد.
۴. لاگهای بکاند را بررسی کنید
👉💻 ببینید پشت صحنه چه اتفاقی افتاده است:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
خطوط لاگ را مشاهده خواهید کرد که خط لوله را ردیابی میکنند:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
۵. صف را زیر نظر داشته باشید
👉💻 بررسی کنید که چند شغل در حال اجرا است:
curl $BACKEND_URL/api/queue/status
اگر ۳ جلسه به طور همزمان فعال باشند، پاسخ نشان داده خواهد شد:
{"active_jobs":3,"max_jobs":3,"available":false}
از کاربران جدید خواسته میشود تا زمان باز شدن یک اسلات منتظر بمانند.
۹. 🎉 نتیجهگیری
آنچه ساختهاید
✅ تحلیل حرکت با هوش مصنوعی - Gemini Flash ویدیو را از نظر حرکت، سرعت و سبک تجزیه و تحلیل میکند
✅ تولید آواتار — نانو موز آواتارهای استایلدار را از فریمهای ویدیویی ایجاد میکند
✅ ساخت ویدیو با هوش مصنوعی — Veo 3.1 ویدیوهای جدیدی متناسب با حرکت کاربر تولید میکند.
✅ خط لوله ناهمگام - پردازش پسزمینه با مدیریت صف (حداکثر ۳ پردازش همزمان)
✅ ترکیببندی پهلو به پهلو — ترکیببندی ویدئو با استفاده از ffmpeg
✅ استقرار ابری — بدون سرور، مقیاسپذیری خودکار، بدون مدیریت سرور
مفاهیم کلیدی که یاد گرفتید
- Gemini Multimodal - ارسال ویدیو به عنوان ورودی و دریافت تحلیل ساختاریافته JSON
- نانو موز (تولید تصویر جمینی) — استفاده از تصاویر مرجع + استایلهای پیشنهادی برای تولید آواتارها
- Veo 3.1 - تولید ویدئوی غیرهمزمان با منابع مرجع و پیامهای متنی
- Cloud Run - استقرار کانتینرها با متغیرهای محیطی و مقیاسبندی خودکار
- الگوی خط لوله ناهمگام - وظایف پسزمینهایِ اجرا-و-فراموششده با
asyncio.Taskبرای عملیات هوش مصنوعیِ طولانیمدت - مدیریت صف - محدود کردن نرخ وظایف همزمان هوش مصنوعی برای کنترل هزینهها و سهمیههای API
خلاصه معماری
قدم بعدی چیست؟
- افزودن سبکهای بیشتر برای آواتار —
backend/app/prompts/avatar_generation.pyرا ویرایش کنید - سفارشیسازی اعلان Veo — ویرایش
backend/app/prompts/video_generation.py - اجرا به صورت محلی در حالت شبیهسازی شده — برای توسعه بدون فراخوانی API،
MOCK_AI=trueرا در.envتنظیم کنید. - مقیاسبندی رویدادها — افزایش
--max-instancesوMAX_CONCURRENT_JOBS