
1. Introduction
Objectifs de l'atelier
Gemini Motion Lab est une expérience en direct sur borne interactive basée sur l'IA. Un utilisateur enregistre une courte vidéo de danse ou de mouvement, et le système :
- Analyse le mouvement à l'aide de Gemini (parties du corps, phases, tempo, énergie)
- Génère une image d'avatar stylisée à l'aide de Nano Banana (Gemini Flash Image)
- Crée une vidéo IA à l'aide de Veo qui recrée le mouvement avec l'avatar.
- Compose une vidéo côte à côte (originale et générée par IA)
- Partage le résultat via un code QR sur une page optimisée pour les mobiles
À la fin de cet atelier de programmation, vous aurez déployé la démo complète sur Google Cloud Run et vous comprendrez le pipeline d'IA qui l'alimente.
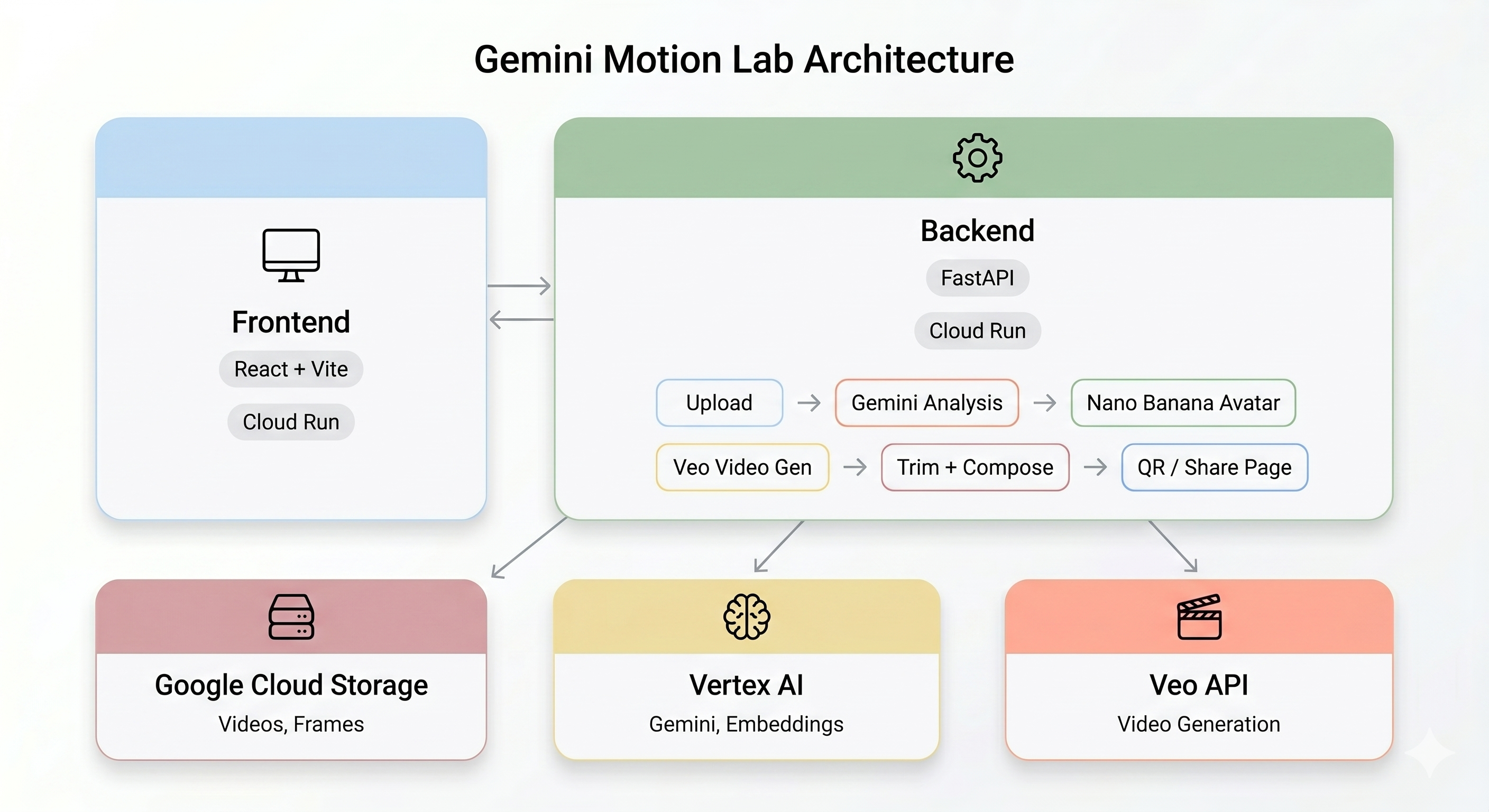
Présentation de l'architecture
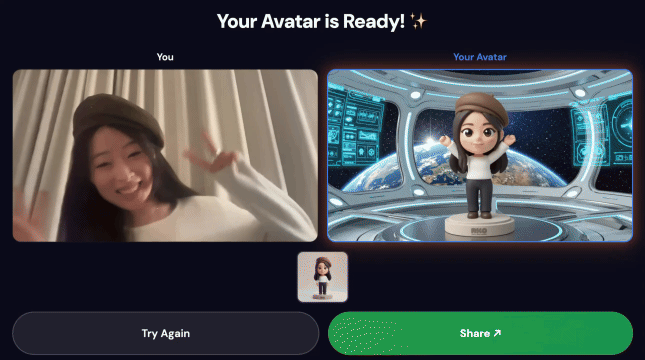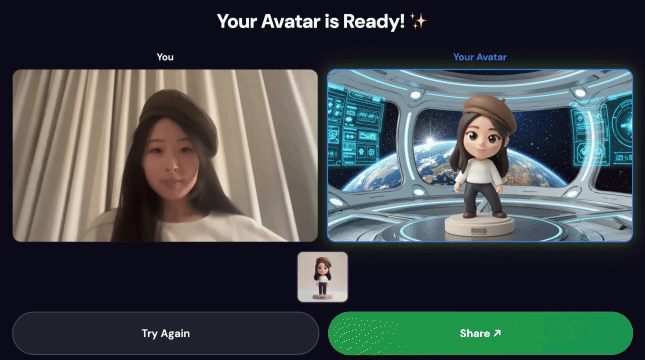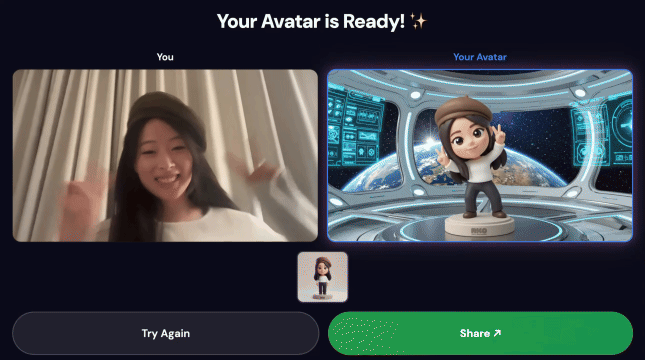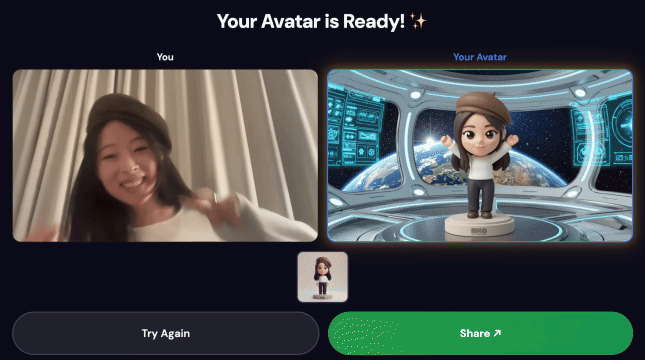
Démonstration finale :
Technologie principale
Composant | Technologie | Objectif |
Analyse des mouvements | Gemini Flash | Analyser les mouvements, les phases et le style du corps dans une vidéo |
Génération d'avatars | Gemini Flash Image (Nano Banana) | Générer un avatar stylisé de 1024 x 1024 à partir d'une image clé |
Génération de vidéos | Veo 3.1 | Créer une vidéo IA à partir du prompt d'avatar et de mouvement |
Backend | FastAPI + Python 3.11 | Serveur d'API avec orchestration de pipeline asynchrone |
Frontend | React + Vite + TypeScript | Interface utilisateur du kiosque avec enregistrement de la caméra et état en direct |
Hébergement | Cloud Run | Déploiement de conteneurs sans serveur |
Stockage | Google Cloud Storage | Mises en ligne de vidéos, images, sorties coupées et composées |
2. 📦 Cloner le dépôt
1. Ouvrir l'éditeur Cloud Shell
👉 Ouvrez l'éditeur Cloud Shell dans votre navigateur.
Si le terminal n'apparaît pas en bas de l'écran :
- Cliquez sur Afficher.
- Cliquez sur Terminal
2. Cloner le code
👉💻 Dans le terminal, clonez le dépôt :
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Explorer la structure du projet
Voici un aperçu de la structure du dépôt :
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Réclamer des crédits et créer un projet GCP
Partie 1 : Demander vos avoirs de facturation
👉 Réclamez le crédit de votre compte de facturation avec votre compte Gmail.
Partie 2 : Créer un projet
👉💻 Dans le terminal, rendez le script d'initialisation exécutable et exécutez-le :
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Le script init.sh :
- Créez un projet GCP avec le préfixe
gemini-motion-lab. - Enregistrez l'ID du projet dans
~/project_id.txt. - Installer les dépendances de facturation et associer automatiquement votre compte de facturation
Partie 3 : Configurer le projet et activer les API
👉💻 Définissez votre ID de projet dans le terminal :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Activez les API Google Cloud nécessaires pour ce projet (cela prend environ une à deux minutes) :
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [LECTURE SEULE] Comprendre l'architecture
Cette section explique le fonctionnement du pipeline d'IA de bout en bout. Aucune action n'est requise : lisez simplement cet article pour comprendre le système avant de le déployer.
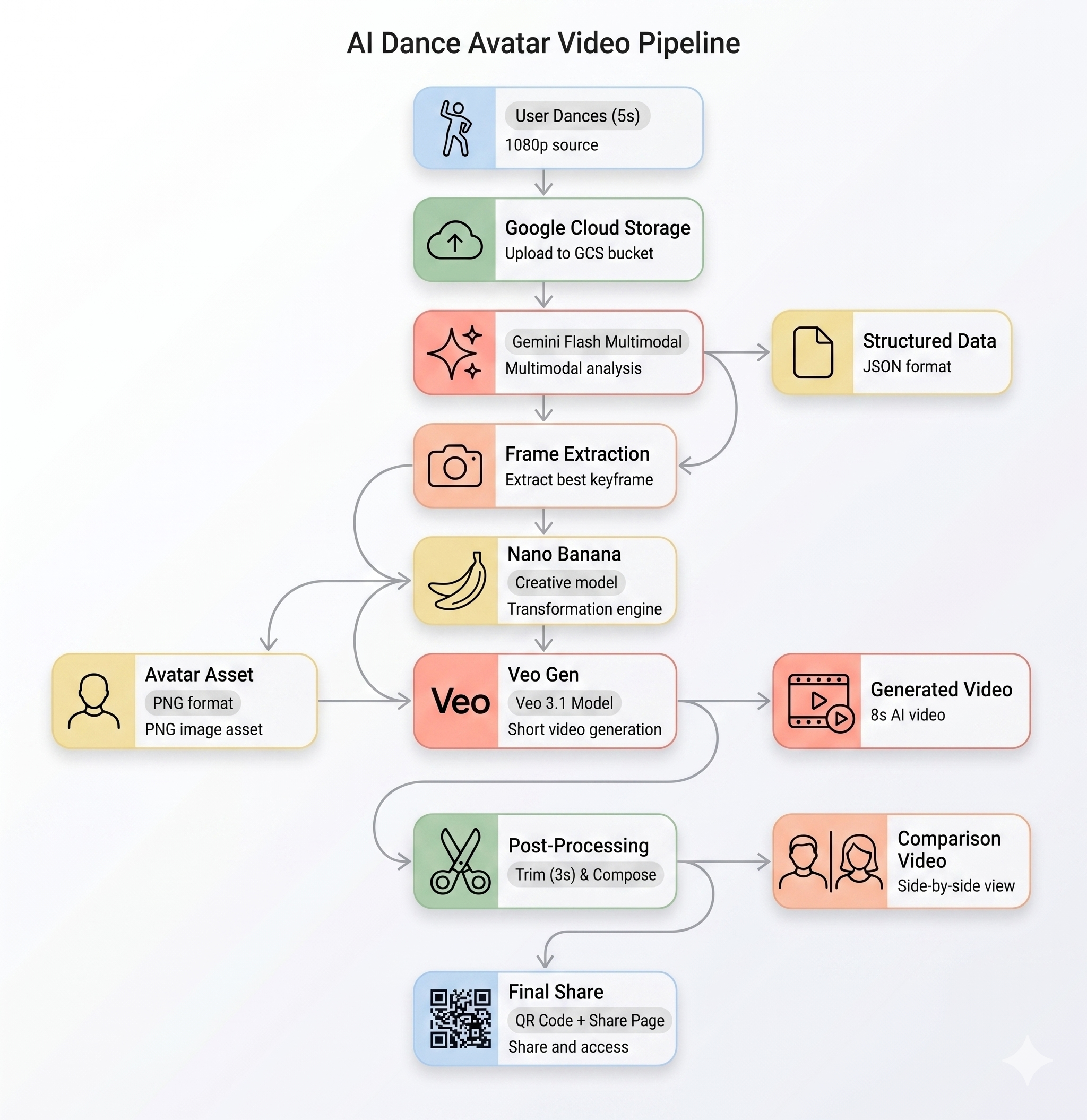
Le pipeline d'IA
Lorsqu'un utilisateur enregistre un clip vidéo sur le kiosque, cinq étapes se déroulent dans l'ordre :

Étape 1 : Mettre en ligne une vidéo
Le frontend enregistre un clip WebM de cinq secondes à partir de la caméra de l'utilisateur et l'importe dans Google Cloud Storage via le point de terminaison /api/upload du backend.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Étape 2 : Analyse du mouvement Gemini
Le backend envoie la vidéo importée à Gemini Flash (gemini-3-flash-preview) pour une analyse structurée.
Fonctionnement (backend/app/services/gemini_service.py) :
Le service utilise client.models.generate_content() du SDK Vertex AI avec la vidéo comme entrée Part.from_uri et une requête structurée. response_mime_type="application/json" permet à Gemini de renvoyer un JSON analysable. Le modèle utilise également ThinkingConfig(thinking_budget=1024) pour mieux raisonner sur les phases de mouvement.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Étape 3 : Génération d'un avatar Nano Banana
À partir de la meilleure image extraite de la vidéo, Gemini Flash Image (gemini-3.1-flash-image-preview) génère un avatar stylisé de 1024 x 1024.
Fonctionnement (backend/app/services/nano_banana_service.py) :
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
Le fichier PNG de l'avatar généré est importé dans GCS et transmis à l'étape suivante.
Étape 4 : Génération de vidéos Veo
L'image de l'avatar est utilisée comme asset de référence pour Veo 3.1 (veo-3.1-fast-generate-001) afin de générer une vidéo de huit secondes par IA.
Fonctionnement (backend/app/services/veo_service.py) :
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
La génération de VEO est asynchrone : elle renvoie immédiatement un ID d'opération. Le backend interroge l'opération jusqu'à ce qu'elle soit terminée (jusqu'à 10 minutes).
Étape 5 : Pipeline de post-traitement
Une fois Veo terminé, le pipeline en arrière-plan (backend/app/services/pipeline.py) s'exécute automatiquement :
- Coupez la vidéo de 8 secondes générée par Veo pour la ramener à 3 secondes.
- Composer une vidéo côte à côte (enregistrement d'origine à gauche, vidéo IA à droite)
- Importez la vidéo composée dans GCS.
- Libérer l'emplacement dans la file d'attente
Ce pipeline s'exécute en arrière-plan asyncio.Task. L'interface utilisateur du kiosque n'a pas besoin d'attendre.
Le système de file d'attente
La génération de vidéos Veo étant gourmande en ressources, le système applique une limite de trois tâches simultanées :
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Le frontend vérifie GET /api/queue/status avant de laisser un nouvel utilisateur démarrer une session. Lorsqu'un pipeline se termine et appelle complete(video_id), le créneau s'ouvre pour l'utilisateur suivant.
Cloud Run : conteneurs sans serveur
Le backend et l'interface sont déployés en tant que services Cloud Run :
Service | Objectif | Configuration des clés |
Backend | Serveur d'API FastAPI | 2 Gio de mémoire (pour le traitement vidéo via ffmpeg) |
Interface | Application React statique diffusée par Nginx | Mémoire par défaut |
5. ⚙️ Exécuter le script de configuration
1. Exécuter la configuration automatique
Le script setup.sh crée les ressources cloud requises et génère votre fichier .env.
👉💻 Rendez le script exécutable et exécutez-le :
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Accorder des rôles IAM
Accordez ensuite les autorisations requises au compte de service.
👉💻 Exécutez les commandes suivantes pour définir l'ID de votre projet et attribuer les trois rôles :
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Valider votre fichier .env
👉💻 Vérifiez le fichier .env généré :
cat .env
Vous devriez obtenir le résultat suivant :
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Déployer le backend
1. Comprendre le Dockerfile du backend
Avant de déployer, comprenons à quoi ressemble le conteneur :
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Déployer dans Cloud Run
👉💻 Chargez vos variables d'environnement et déployez :
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Cela prend environ trois à cinq minutes. Cloud Build :
- Importer votre code source
- Compiler l'image Docker
- Transférer vers Artifact Registry
- Déployer l'application sur Cloud Run
3. Enregistrer l'URL du backend
👉 💻 Une fois déployée, enregistrez l'URL du backend :
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Mettre à jour l'URL de partage du backend
Le backend génère des codes QR pour que les utilisateurs puissent télécharger leurs vidéos. Pour ce faire, il doit connaître sa propre URL publique.
👉💻 Mettez à jour la configuration du backend avec sa propre URL :
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Vérifier le backend
👉💻 Testez le point de terminaison d'état :
curl $BACKEND_URL/api/health
Résultat attendu :
{"status":"ok"}
👉💻 Vérifiez l'état de la file d'attente :
curl $BACKEND_URL/api/queue/status
Résultat attendu :
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Déployer l'interface
1. Comprendre le fichier Dockerfile de l'interface
L'interface utilise une compilation en plusieurs étapes : elle compile d'abord l'application React, puis la diffuse avec Nginx :
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Déployer dans Cloud Run
👉💻 Commencez par écrire l'URL du backend dans un fichier .env afin que Vite puisse l'intégrer au moment de la compilation :
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Déployez maintenant le frontend :
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Cela prend environ deux à trois minutes.
3. Obtenir l'URL de l'interface
👉💻 Récupérez et ouvrez l'URL de l'interface :
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Ouvrez l'URL dans votre navigateur. L'interface du kiosque Gemini Motion Lab devrait s'afficher.
8. 🎮 [FACULTATIF] Jouer avec la démo
1. Enregistrer un mouvement
- Ouvrez l'URL du frontend dans votre navigateur (de préférence Chrome pour une compatibilité optimale avec les caméras).
- Cliquez sur Démarrer pour commencer l'enregistrement.
- Dansez ou bougez pendant environ cinq secondes. Les grands mouvements de bras et les poses dynamiques sont les plus efficaces.
- L'enregistrement s'arrête et est importé automatiquement.
2. Regarder le pipeline d'IA
Une fois l'importation effectuée, vous verrez le pipeline s'exécuter en temps réel :
Phase | Les nouveautés | Durée |
Analyse en cours… | Gemini Flash analyse votre vidéo pour identifier les schémas de mouvement. | ~5 à 10 s |
Génération de l'avatar... | Nano Banana crée un avatar stylisé à partir de votre meilleure image | ~8 à 12 s |
Création de la vidéo… | Veo 3.1 génère une vidéo IA à partir de l'avatar et du prompt de mouvement. | ~60 à 120 s |
Rédaction… | ffmpeg coupe la vidéo et crée une comparaison côte à côte | ~5 à 10 s |
3. Partager votre création
Une fois le pipeline terminé :
- Un code QR s'affiche sur l'écran de la borne.
- Scannez le code QR avec votre téléphone.
- Une page de partage optimisée pour les mobiles s'affiche avec la vidéo que vous avez créée.
4. Vérifier les journaux du backend
👉💻 Découvrez ce qui s'est passé en coulisses :
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Des lignes de journalisation retraçant le pipeline s'affichent :
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Surveiller la file d'attente
👉💻 Vérifiez le nombre de jobs en cours d'exécution :
curl $BACKEND_URL/api/queue/status
Si trois sessions sont actives simultanément, la réponse affichera :
{"active_jobs":3,"max_jobs":3,"available":false}
Les nouveaux utilisateurs seront invités à attendre qu'un créneau se libère.
9. 🎉 Conclusion
Ce que vous avez créé
✅ Analyse du mouvement par l'IA : Gemini Flash analyse les vidéos pour détecter les mouvements, le tempo et le style.
✅ Génération d'avatars : Nano Banana crée des avatars stylisés à partir d'images vidéo.
✅ Création de vidéos par IA : Veo 3.1 génère de nouvelles vidéos correspondant aux mouvements de l'utilisateur.
✅ Pipeline asynchrone : traitement en arrière-plan avec gestion des files d'attente (max. 3 simultanément)
✅ Composition côte à côte : composition vidéo optimisée par ffmpeg
✅ Déploiement Cloud Run : sans serveur, autoscaling, sans gestion de serveur
Concepts clés que vous avez appris
- Gemini Multimodal : envoyer une vidéo en entrée et recevoir une analyse JSON structurée
- Nano Banana (génération d'images Gemini) : utiliser des images de référence et des prompts de style pour générer des avatars
- Veo 3.1 : génération asynchrone de vidéos avec des assets de référence et des requêtes textuelles
- Cloud Run : déployer des conteneurs avec des variables d'environnement et l'autoscaling
- Modèle de pipeline asynchrone : tâches d'arrière-plan "fire and forget" avec
asyncio.Taskpour les opérations d'IA de longue durée - Gestion des files d'attente : limitation du débit des tâches d'IA simultanées pour contrôler les coûts et les quotas d'API
Récapitulatif de l'architecture
Et maintenant ?
- Ajouter d'autres styles d'avatar : modifier
backend/app/prompts/avatar_generation.py - Personnaliser la requête Veo : modifier
backend/app/prompts/video_generation.py - Exécuter en local en mode simulation : définissez
MOCK_AI=truesur.envpour le développement sans appels d'API. - Échelle pour les événements : augmentez
--max-instancesetMAX_CONCURRENT_JOBS