
1. מבוא
מה תפַתחו
Gemini Motion Lab הוא חוויה אינטראקטיבית של קיוסק שמבוססת על AI. משתמש מצלם קטע קצר של ריקוד או תנועה, והמערכת:
- מנתח את התנועה באמצעות Gemini (חלקי גוף, שלבים, קצב, אנרגיה)
- יצירת תמונה של דמות מעוצבת באמצעות Nano Banana (תמונה של Gemini Flash)
- יוצר סרטון מ-AI באמצעות Veo שבו התנועה משוחזרת באמצעות הדמות
- יוצר סרטון שבו מוצגים זה לצד זה הסרטון המקורי והסרטון שנוצר על ידי AI
- שיתוף התוצאה באמצעות קוד QR בדף שמיועד לנייד
בסיום שיעור ה-Codelab הזה, ההדגמה המלאה תיפרס ב-Google Cloud Run ותבינו את פייפליין ה-AI שמפעיל אותה.
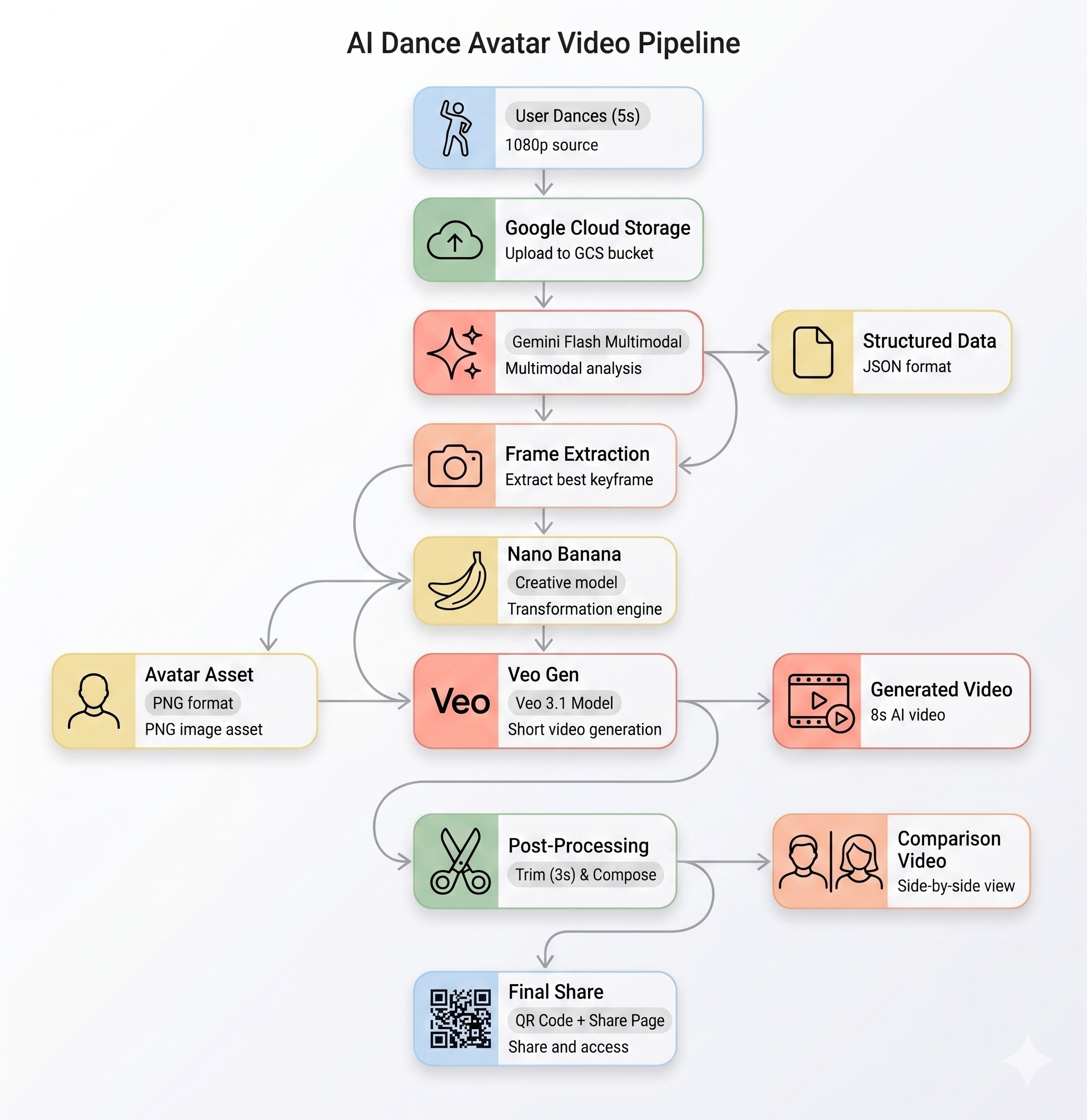
סקירה כללית של הארכיטקטורה
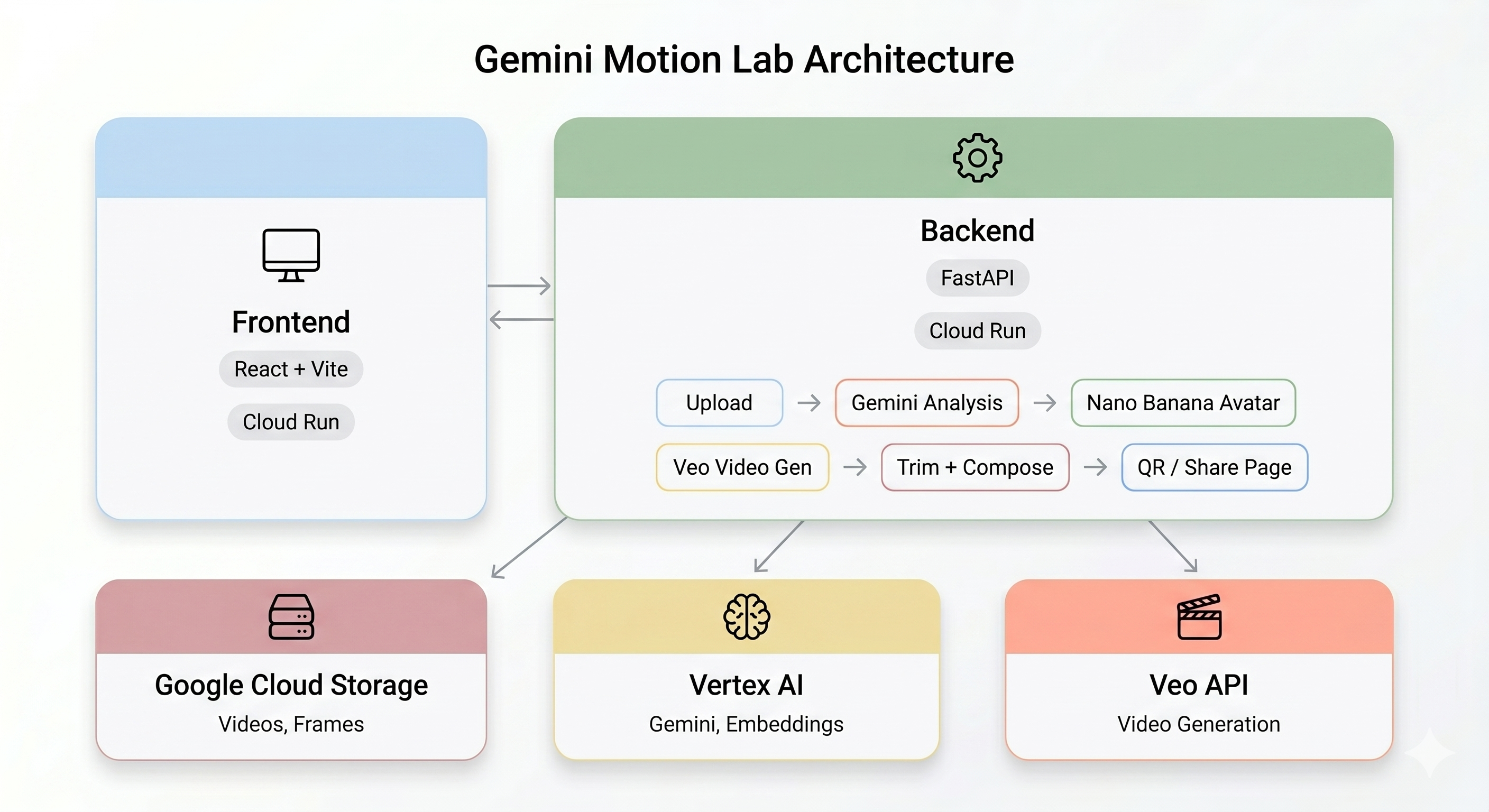
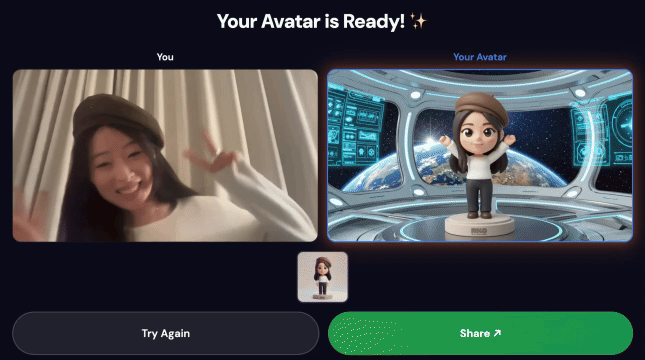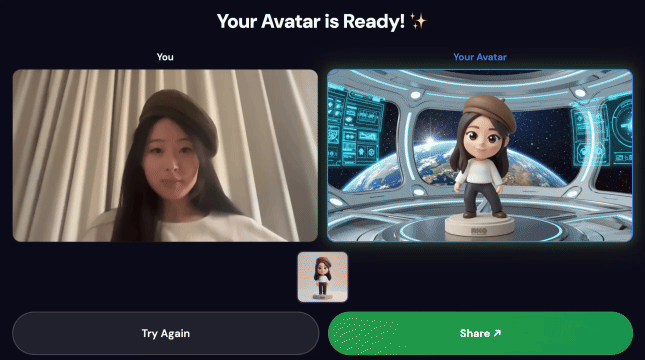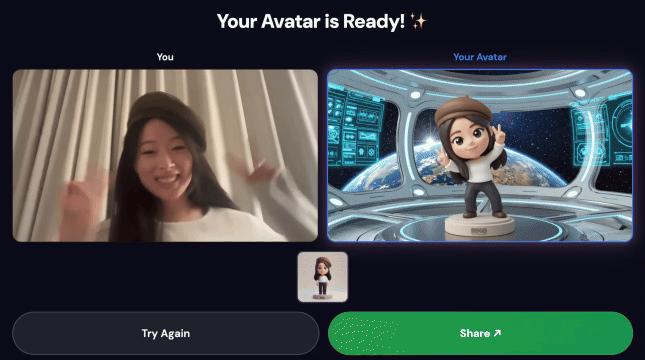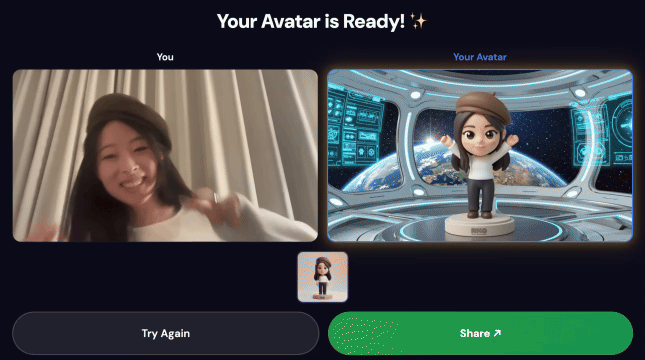
הדגמה סופית:
טכנולוגיות ליבה
רכיב | טכנולוגיה | מטרה |
ניתוח תנועה | Gemini Flash | ניתוח של סרטון כדי לזהות תנועות גוף, שלבים וסגנון |
יצירת דמויות | Gemini Flash Image (Nano Banana) | יצירת דמות מעוצבת בגודל 1024x1024 מפריים מרכזי |
יצירת סרטונים | Veo 3.1 | יצירת סרטון AI מהאווטאר + הנחיה לגבי תנועה |
Backend | FastAPI + Python 3.11 | שרת API עם תזמור אסינכרוני של פייפליינים |
Frontend | React + Vite + TypeScript | ממשק משתמש של קיוסק עם הקלטה מהמצלמה וסטטוס בזמן אמת |
אירוח | Cloud Run | פריסה בקונטיינרים בלי שרת (serverless) |
אחסון | Google Cloud Storage | העלאות של סרטונים, פריים, פלט חתוך ומורכב |
2. 📦 שכפול המאגר
1. פתיחת Cloud Shell Editor
👉 פותחים את Cloud Shell Editor בדפדפן.
אם הטרמינל לא מופיע בתחתית המסך:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף).
2. שיבוט הקוד
👈💻 בטרמינל, משכפלים את המאגר:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. עיון במבנה הפרויקט
סקירה מהירה של פריסת המאגר:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ מימוש קרדיטים ויצירת פרויקט GCP
חלק 1: מימוש שוברי הפרסום
👉 אפשר לממש את הקרדיט בחשבון לחיוב באמצעות חשבון Gmail.
חלק 2: יצירת פרויקט חדש
👈💻 בטרמינל, הופכים את סקריפט ההפעלה לקובץ הפעלה ומריצים אותו:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
הסקריפט init.sh:
- יצירת פרויקט חדש ב-GCP עם הקידומת
gemini-motion-lab - שומרים את מזהה הפרויקט ב-
~/project_id.txt - התקנת תלות בחיוב וקישור אוטומטי של החשבון לחיוב
חלק 3: הגדרת הפרויקט והפעלת ממשקי API
👈💻 מגדירים את מזהה הפרויקט במסוף:
gcloud config set project $(cat ~/project_id.txt) --quiet
👈💻 מפעילים את Cloud APIs של Google שנדרשים לפרויקט הזה (הפעולה הזו אורכת כדקה עד שתי דקות):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [לקריאה בלבד] הסבר על הארכיטקטורה
בסעיף הזה מוסבר איך צינור ה-AI פועל מקצה לקצה. לא נדרשת פעולה – פשוט קוראים כדי להבין את המערכת לפני הפריסה.
צינור ה-AI
כשמשתמש מצלם קליפ תנועה בקיוסק, חמישה שלבים מופעלים ברצף:

שלב 1: העלאת סרטון
ממשק הקצה מתעד סרטון WebM באורך 5 שניות מהמצלמה של המשתמש ומעלה אותו אל Google Cloud Storage דרך נקודת הקצה /api/upload של ה-Backend.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
שלב 2: ניתוח תנועה באמצעות Gemini
הקצה העורפי שולח את הסרטון שהועלה אל Gemini Flash (gemini-3-flash-preview) לניתוח מובנה.
איך זה עובד (backend/app/services/gemini_service.py):
השירות משתמש ב-client.models.generate_content() של Vertex AI SDK עם הסרטון כקלט Part.from_uri והנחיה מובנית. התו response_mime_type="application/json" מבטיח ש-Gemini יחזיר קובץ JSON שאפשר לנתח. בנוסף, המודל משתמש ב-ThinkingConfig(thinking_budget=1024) כדי להסיק מסקנות טובות יותר לגבי שלבי התנועה.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
שלב 3: יצירת אווטאר באמצעות Nano Banana
באמצעות הפריים הכי טוב שחולץ מהסרטון, Gemini Flash Image (gemini-3.1-flash-image-preview) יוצר אווטאר מסוגנן בגודל 1024×1024.
איך זה עובד (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
קובץ ה-PNG של האווטאר שנוצר מועלה ל-GCS ועובר לשלב הבא.
שלב 4: יצירת סרטונים באמצעות Veo
תמונת האווטאר משמשת כנכס הפניה ל-Veo 3.1 (veo-3.1-fast-generate-001) כדי ליצור סרטון AI באורך 8 שניות.
איך זה עובד (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
היצירה ב-Veo היא אסינכרונית – היא מחזירה מזהה פעולה באופן מיידי. הקצה העורפי מבצע בדיקה חוזרת של הפעולה עד שהיא מסתיימת (עד 10 דקות).
שלב 5: צינור עיבוד נתונים לאחר העיבוד
אחרי ש-Veo מסיים, צינור עיבוד הנתונים ברקע (backend/app/services/pipeline.py) פועל באופן אוטומטי:
- חיתוך של הפלט של Veo באורך 8 שניות ל-3 שניות
- הרכבת סרטון זה לצד זה (ההקלטה המקורית מימין, סרטון ה-AI משמאל)
- מעלים את הסרטון המורכב אל GCS
- פרסום המשבצת בתור
הפייפליין הזה פועל ברקע asyncio.Task – אין צורך להמתין לקצה הקדמי של הקיוסק.
מערכת התורים
יצירת סרטונים ב-Veo היא פעולה שדורשת הרבה משאבים, ולכן המערכת מגבילה את מספר המשימות שניתן להריץ בו-זמנית ל-3 לכל היותר:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
הקצה הקדמי בודק את GET /api/queue/status לפני שמשתמש חדש מתחיל סשן. כשפייפליין מסתיים ומפעיל את complete(video_id), המשבצת נפתחת למשתמש הבא.
Cloud Run – קונטיינרים ללא שרת
הקצה העורפי והקצה הקדמי נפרסים כשירותי Cloud Run:
שירות | מטרה | הגדרת מפתח |
בק-אנד | שרת FastAPI API | זיכרון בנפח 2GiB (לעיבוד וידאו באמצעות ffmpeg) |
קצה קדמי | אפליקציית React סטטית שמוצגת על ידי Nginx | זיכרון ברירת המחדל |
5. ⚙️ הרצת סקריפט ההגדרה
1. הפעלת תהליך ההגדרה האוטומטי
הסקריפט setup.sh יוצר את משאבי הענן הנדרשים ומפיק את קובץ .env.
👈💻 הופכים את הסקריפט לניתן להרצה ומפעילים פתרונות חכמים:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. הקצאת תפקידי IAM
עכשיו מעניקים לחשבון השירות את ההרשאות הנדרשות.
👈💻 מריצים את הפקודות הבאות כדי להגדיר את מזהה הפרויקט ולהעניק את שלושת התפקידים:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. אימות קובץ .env
👉💻 בודקים את קובץ ה-.env שנוצר:
cat .env
הפרטים שמוצגים הם:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 פריסת הקצה העורפי
1. הסבר על קובץ ה-Dockerfile של ה-Backend
לפני הפריסה, כדאי להבין איך נראה ה-container:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. פריסה ב-Cloud Run
👈💻 טוענים את משתני הסביבה ומבצעים פריסה:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
התהליך נמשך כ-3 עד 5 דקות. Cloud Build יבצע את הפעולות הבאות:
- העלאת קוד המקור
- יצירת קובץ האימג' של Docker
- העלאה ל-Artifact Registry
- פריסה ב-Cloud Run
3. שמירת כתובת ה-URL של ה-Backend
👈💻 אחרי הפריסה, שומרים את כתובת ה-URL של ה-Backend:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. עדכון כתובת ה-URL לשיתוף של ה-Backend
הקצה העורפי יוצר קודי QR כדי שהמשתמשים יוכלו להוריד את הסרטונים שלהם. כדי לעשות את זה, הוא צריך לדעת את כתובת ה-URL הציבורית שלו.
👈💻 מעדכנים את הגדרות ה-Backend עם כתובת ה-URL שלו:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. אימות ה-Backend
👈💻 בדיקת נקודת הקצה של הבריאות:
curl $BACKEND_URL/api/health
הפלט הצפוי:
{"status":"ok"}
👉💻 בדיקת סטטוס התור:
curl $BACKEND_URL/api/queue/status
הפלט הצפוי:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 פריסת הקצה הקדמי
1. הסבר על קובץ ה-Dockerfile של הקצה הקדמי
החלק הקדמי של האתר משתמש בmulti-stage build – קודם הוא בונה את אפליקציית React, ואז מציג אותה באמצעות Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. פריסה ב-Cloud Run
👈💻 קודם כותבים את כתובת ה-URL של ה-Backend בקובץ .env כדי ש-Vite יוכל להוסיף אותה בזמן ה-Build:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👈💻 עכשיו פורסים את הקצה הקדמי:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
התהליך נמשך כ-2-3 דקות.
3. איך מוצאים את כתובת ה-URL של ממשק הקצה
👉💻 מאחזרים ופותחים את כתובת ה-URL של חזית האתר:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👈 פותחים את כתובת ה-URL בדפדפן – אמור להופיע הממשק של עמדת המידע של Gemini Motion Lab.
8. 🎮 [אופציונלי] משחק עם ההדגמה
1. הקלטת תנועה
- פותחים את כתובת ה-URL של חזית האתר בדפדפן (מומלץ להשתמש ב-Chrome כדי לקבל את התמיכה הטובה ביותר במצלמה)
- לוחצים על התחלה כדי להתחיל להקליט.
- רוקדים או זזים במשך כ-5 שניות – תנועות גדולות של הידיים ותנוחות דינמיות מניבות את התוצאות הטובות ביותר
- ההקלטה תיפסק ותועלה אוטומטית
2. צפייה בצינור עיבוד הנתונים של ה-AI
אחרי ההעלאה, תוכלו לראות את הפעלת צינור הנתונים בזמן אמת:
שלב | מה קורה | משך |
בתהליך ניתוח… | Gemini Flash מנתח את הסרטון כדי לזהות דפוסי תנועה | ~5-10 שניות |
יצירת דמות… | Nano Banana יוצר אווטאר מסוגנן מהפריים הכי טוב שלכם | ~8-12 שנ' |
יצירת סרטון... | Veo 3.1 יוצר סרטון AI מהדמות + הנחיית התנועה | ~60-120 שניות |
בתהליך כתיבה... | ffmpeg חותך את הסרטון ויוצר השוואה זה לצד זה | ~5-10 שניות |
3. שיתוף היצירה
אחרי שהצינור יסיים את הפעולה:
- קוד QR מופיע במסך הקיוסק
- סורקים את קוד ה-QR באמצעות הטלפון.
- יוצג דף שיתוף שעבר אופטימיזציה לניידים עם הסרטון שיצרתם
4. בדיקת יומני הרישום של ה-Backend
👉💻 צפייה במה שקרה מאחורי הקלעים:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
יוצגו שורות ביומן שמתעדות את הפייפליין:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. מעקב אחרי התור
👈💻 בדיקה של מספר המשימות שפועלות:
curl $BACKEND_URL/api/queue/status
אם 3 סשנים פעילים בו-זמנית, התגובה תהיה:
{"active_jobs":3,"max_jobs":3,"available":false}
משתמשים חדשים יתבקשו להמתין עד שיתפנה מקום.
9. 🎉 סיכום
מה יצרתם
✅ AI Motion Analysis – Gemini Flash מנתח סרטונים כדי לזהות תנועה, קצב וסגנון
✅ יצירת דמויות – Nano Banana יוצר דמויות מסוגננות מפריים של סרטונים
✅ AI Video Creation — Veo 3.1 generates new videos matching the user's motion
✅ Async Pipeline – עיבוד ברקע עם ניהול תורים (עד 3 תורים בו-זמנית)
✅ Side-by-Side Composition – קומפוזיציה של סרטונים זה לצד זה שמבוססת על ffmpeg
✅ Cloud Run Deployment – פריסה ללא שרתים (serverless), התאמה אוטומטית לעומס (auto-scaling), ללא ניהול שרתים
מושגים מרכזיים שלמדתם
- Gemini Multimodal – שליחת וידאו כקלט וקבלת ניתוח מובנה ב-JSON
- Nano Banana (יצירת תמונות ב-Gemini) – יצירת אווטרים באמצעות תמונות להשוואה + הנחיות סגנון
- Veo 3.1 – יצירת סרטונים אסינכרונית עם נכסי הפניה והנחיות טקסט
- Cloud Run – פריסת קונטיינרים עם משתני סביבה והתאמה אוטומטית לעומס
- תבנית פייפליין אסינכרוני – משימות ברקע מסוג 'הפעלה ושכחה' עם
asyncio.Taskלפעולות AI ארוכות - ניהול תורים – הגבלת קצב של משימות AI מקבילות כדי לשלוט בעלויות ובמכסות של ממשקי API
סיכום הארכיטקטורה
מה השלב הבא?
- הוספת סגנונות נוספים של דמויות – עריכה
backend/app/prompts/avatar_generation.py - התאמה אישית של ההנחיה ב-Veo – עריכה
backend/app/prompts/video_generation.py - הרצה מקומית במצב מדומה – מגדירים את
MOCK_AI=trueב-.envלפיתוח בלי קריאות ל-API - התאמה של אירועים להיקף – הגדלת
--max-instancesו-MAX_CONCURRENT_JOBS