
1. Introduzione
Cosa creerai
Gemini Motion Lab è un'esperienza di chiosco live basata sull'AI. Un utente registra un breve video di danza o movimento e il sistema:
- Analizza il movimento utilizzando Gemini (parti del corpo, fasi, tempo, energia)
- Genera un'immagine stilizzata dell'avatar utilizzando Nano Banana (Gemini Flash Image)
- Crea un video AI utilizzando Veo che ricrea il movimento con l'avatar
- Compone un video affiancato (originale + generato con l'AI)
- Condivide il risultato tramite un codice QR su una pagina ottimizzata per il mobile
Al termine di questo codelab, avrai eseguito il deployment della demo completa su Google Cloud Run e avrai compreso la pipeline di AI che la alimenta.
Panoramica dell'architettura
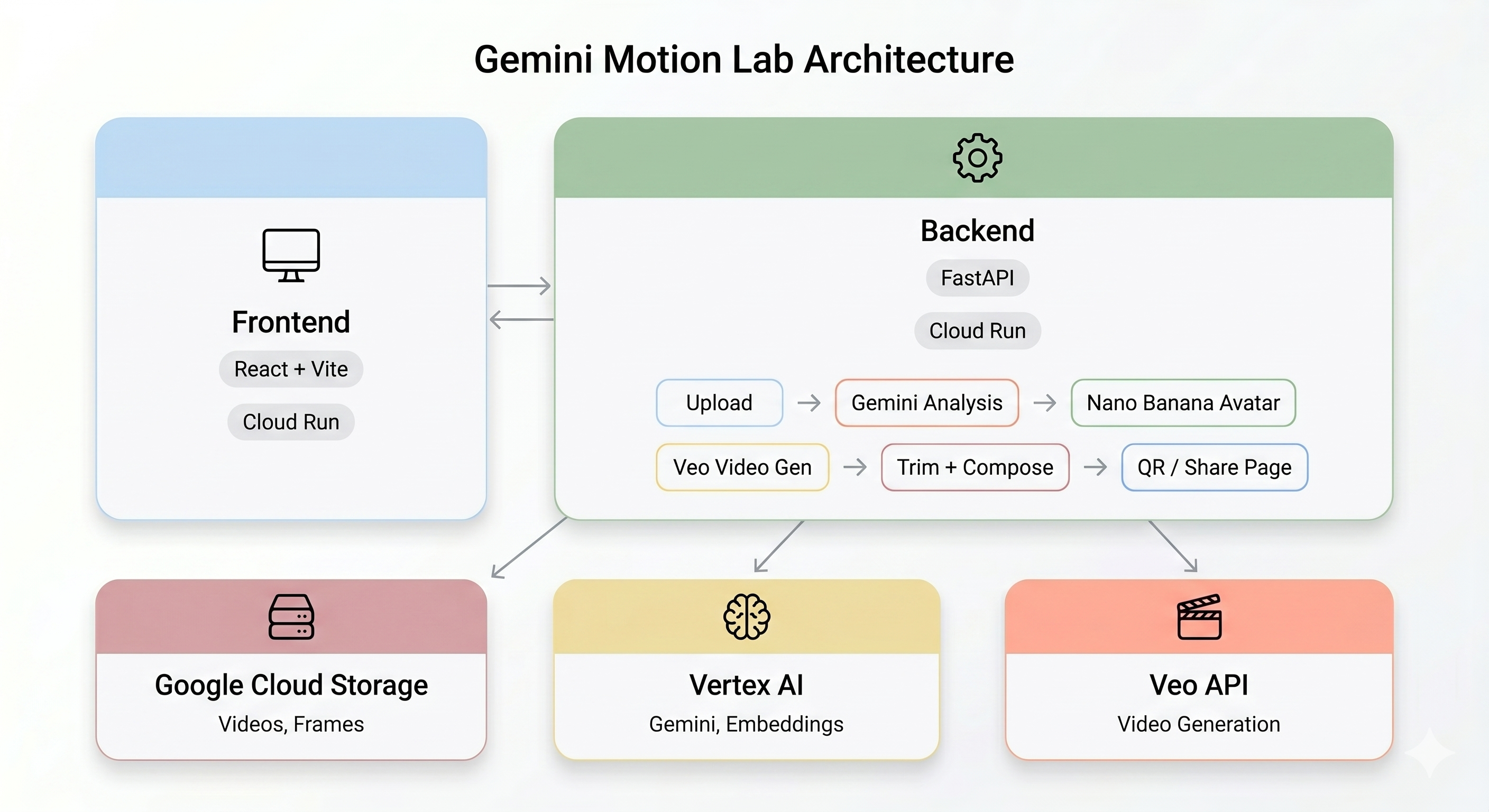
Demo finale:
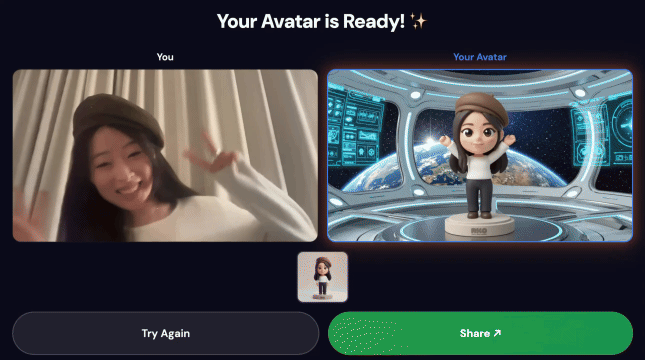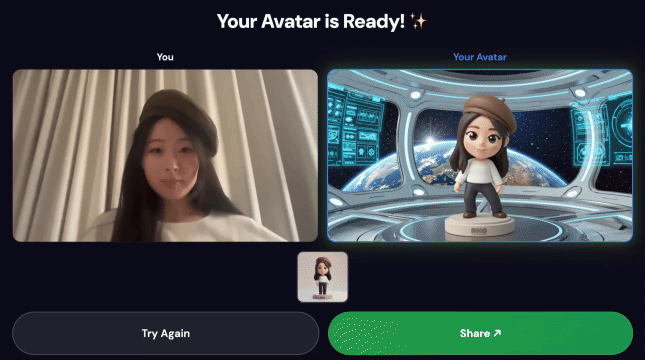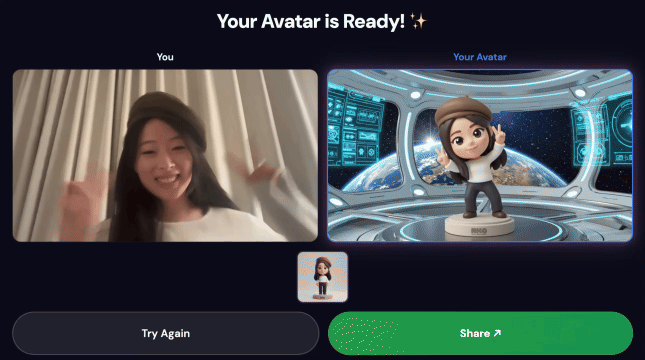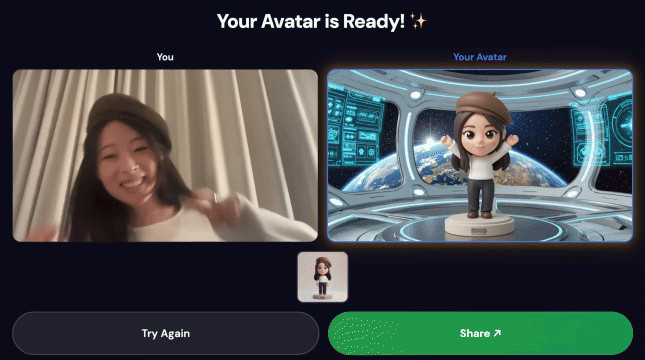
Tecnologie di base
Componente | Tecnologia | Finalità |
Analisi del movimento | Gemini Flash | Analizzare il video per movimento del corpo, fasi e stile |
Generazione di avatar | Gemini Flash Image (Nano Banana) | Genera un avatar stilizzato 1024×1024 da un fotogramma chiave |
Generazione di video | Veo 3.1 | Crea un video AI dal prompt dell'avatar e del movimento |
Backend | FastAPI + Python 3.11 | Server API con orchestrazione della pipeline asincrona |
Frontend | React + Vite + TypeScript | Interfaccia utente del kiosk con registrazione della videocamera e stato live |
Hosting | Cloud Run | Deployment serverless containerizzato |
Spazio di archiviazione | Google Cloud Storage | Caricamenti di video, frame, output tagliati e composti |
2. 📦 Clona il repository
1. Apri editor di Cloud Shell
👉 Apri Cloud Shell Editor nel browser.
Se il terminale non viene visualizzato nella parte inferiore dello schermo:
- Fai clic su Visualizza.
- Fai clic su Terminale.
2. Clona il codice
👉💻 Nel terminale, clona il repository:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Esplora la struttura del progetto
Dai un'occhiata rapida al layout del repository:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Richiedi crediti e crea un progetto Google Cloud
Parte 1: richiedi i tuoi crediti di fatturazione
👉 Richiedi il credito del tuo account di fatturazione utilizzando il tuo account Gmail.
Parte 2: crea un nuovo progetto
👉💻 Nel terminale, rendi eseguibile lo script init ed eseguilo:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Lo script init.sh:
- Crea un nuovo progetto Google Cloud con il prefisso
gemini-motion-lab - Salva l'ID progetto in
~/project_id.txt - Installa le dipendenze di fatturazione e collega automaticamente il tuo account di fatturazione
Parte 3: configura il progetto e abilita le API
👉💻 Imposta l'ID progetto nel terminale:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Abilita le API Cloud di Google necessarie per questo progetto (questa operazione richiede circa 1-2 minuti):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [SOLO LETTURA] Informazioni sull'architettura
Questa sezione spiega come funziona la pipeline AI end-to-end. Nessuna azione necessaria: leggi per comprendere il sistema prima dell'implementazione.
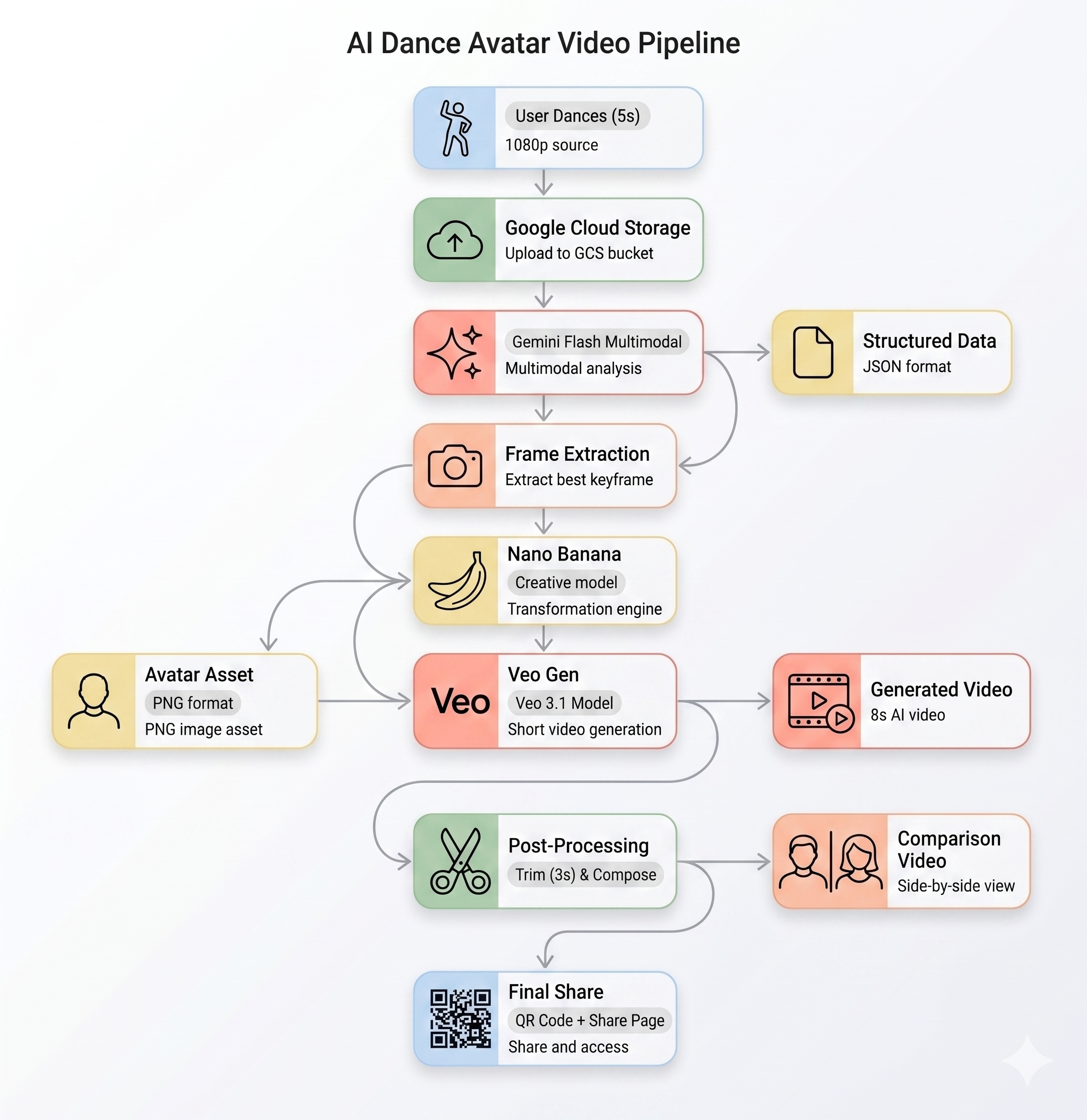
La pipeline AI
Quando un utente registra un clip di movimento al chiosco, vengono eseguite cinque fasi in sequenza:

Fase 1: caricamento del video
Il frontend registra un clip WebM di 5 secondi dalla videocamera dell'utente e lo carica su Google Cloud Storage tramite l'endpoint /api/upload del backend.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Fase 2: analisi del movimento di Gemini
Il backend invia il video caricato a Gemini Flash (gemini-3-flash-preview) per l'analisi strutturata.
Come funziona (backend/app/services/gemini_service.py):
Il servizio utilizza client.models.generate_content() dell'SDK Vertex AI con il video come input Part.from_uri e un prompt strutturato. response_mime_type="application/json" garantisce che Gemini restituisca un JSON analizzabile. Il modello utilizza anche ThinkingConfig(thinking_budget=1024) per un migliore ragionamento sulle fasi del movimento.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Fase 3: generazione dell'avatar Nano Banana
Utilizzando il fotogramma migliore estratto dal video, Gemini Flash Image (gemini-3.1-flash-image-preview) genera un avatar stilizzato 1024×1024.
Come funziona (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
Il PNG dell'avatar generato viene caricato in GCS e passato alla fase successiva.
Fase 4: generazione di video con Veo
L'immagine dell'avatar viene utilizzata come asset di riferimento per Veo 3.1 (veo-3.1-fast-generate-001) per generare un video AI di 8 secondi.
Come funziona (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
La generazione di Veo è asincrona: restituisce immediatamente un ID operazione. Il backend esegue il polling dell'operazione fino al completamento (fino a 10 minuti).
Fase 5: pipeline di post-elaborazione
Una volta completata l'operazione, Veo esegue automaticamente la pipeline in background (backend/app/services/pipeline.py):
- Taglia l'output di Veo di 8 secondi a 3 secondi
- Componi un video affiancato (registrazione originale a sinistra, video AI a destra)
- Carica il video composto su GCS.
- Rilascia lo slot della coda
Questa pipeline viene eseguita in background asyncio.Task, quindi il frontend del chiosco non deve attendere.
Il sistema di coda
Poiché la generazione di Veo richiede molte risorse, il sistema impone un massimo di 3 job simultanei:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Il frontend controlla GET /api/queue/status prima di consentire a un nuovo utente di avviare una sessione. Quando una pipeline viene completata e chiama complete(video_id), lo slot si apre per l'utente successivo.
Cloud Run - Container serverless
Sia il backend che il frontend vengono implementati come servizi Cloud Run:
Servizio | Finalità | Configurazione della chiave |
Backend | Server API FastAPI | 2 GiB di memoria (per l'elaborazione video tramite ffmpeg) |
Frontend | App React statica gestita da Nginx | Memoria predefinita |
5. ⚙️ Esegui lo script di configurazione
1. Esegui la configurazione automatica
Lo script setup.sh crea le risorse cloud richieste e genera il file .env.
👉💻 Rendi eseguibile lo script ed eseguilo:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Concedi ruoli IAM
Ora concedi le autorizzazioni necessarie al service account.
👉💻 Esegui questi comandi per impostare l'ID progetto e concedere tutti e tre i ruoli:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Verifica del file .env
👉💻 Controlla il file .env generato:
cat .env
Dovresti vedere:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Esegui il deployment del backend
1. Informazioni sul Dockerfile di backend
Prima del deployment, vediamo com'è fatto il container:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Esegui il deployment in Cloud Run
👉💻 Carica le variabili di ambiente ed esegui il deployment:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
L'operazione richiede circa 3-5 minuti. Cloud Build:
- Caricare il codice sorgente
- Crea l'immagine Docker
- Esegui il push in Artifact Registry
- Esegui il deployment in Cloud Run
3. Salva l'URL di backend
👉💻 Una volta eseguito il deployment, salva l'URL di backend:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Aggiorna l'URL di condivisione del backend
Il backend genera codici QR in modo che gli utenti possano scaricare i propri video. Per farlo, deve conoscere il proprio URL pubblico.
👉💻 Aggiorna la configurazione del backend con il relativo URL:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Verifica il backend
👉💻 Testa l'endpoint di integrità:
curl $BACKEND_URL/api/health
Output previsto:
{"status":"ok"}
👉💻 Controlla lo stato della coda:
curl $BACKEND_URL/api/queue/status
Output previsto:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Esegui il deployment del frontend
1. Comprendere il Dockerfile del frontend
Il frontend utilizza una compilazione in più fasi: prima compila l'app React, poi la pubblica con Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Esegui il deployment in Cloud Run
👉💻 Innanzitutto, scrivi l'URL di backend in un file .env in modo che Vite possa incorporarlo al tempo di compilazione:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Ora esegui il deployment del frontend:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
L'operazione richiede circa 2-3 minuti.
3. Recuperare l'URL frontend
👉💻 Recupera e apri l'URL del frontend:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Apri l'URL nel browser: dovresti visualizzare l'interfaccia del chiosco Gemini Motion Lab.
8. 🎮 [FACOLTATIVO] Gioca con la demo
1. Registrare un movimento
- Apri l'URL frontend nel browser (preferibilmente Chrome per il miglior supporto della videocamera).
- Fai clic su Avvia per iniziare la registrazione.
- Balla o muoviti per circa 5 secondi. I movimenti ampi delle braccia e le pose dinamiche sono le più efficaci.
- La registrazione verrà interrotta e caricata automaticamente
2. Guarda la pipeline di AI
Dopo il caricamento, vedrai l'esecuzione della pipeline in tempo reale:
Fase | Che cosa sta succedendo | Durata |
Analisi in corso… | Gemini Flash analizza il tuo video alla ricerca di schemi di movimento | ~5-10s |
Generazione dell'avatar in corso… | Nano Banana crea un avatar stilizzato a partire dal tuo fotogramma migliore | ~8-12s |
Creazione del video in corso… | Veo 3.1 genera un video AI a partire dal prompt dell'avatar e del movimento | ~60-120 sec |
Composizione… | ffmpeg taglia e crea un confronto fianco a fianco | ~5-10s |
3. Condividere la tua creazione
Al termine della pipeline:
- Sullo schermo del chiosco appare un codice QR.
- Scansiona il codice QR con lo smartphone
- Visualizzerai una pagina di condivisione ottimizzata per il mobile con il video composto.
4. Controllare i log di backend
👉💻 Scopri cosa è successo dietro le quinte:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Vedrai le righe di log che tracciano la pipeline:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Monitorare la coda
👉💻 Controlla quanti job sono in esecuzione:
curl $BACKEND_URL/api/queue/status
Se 3 sessioni sono attive contemporaneamente, la risposta mostrerà:
{"active_jobs":3,"max_jobs":3,"available":false}
Ai nuovi utenti verrà chiesto di attendere l'apertura di un posto.
9. 🎉 Conclusione
Cosa hai creato
✅ Analisi del movimento AI: Gemini Flash analizza il video per movimento, tempo e stile
✅ Generazione di avatar: Nano Banana crea avatar stilizzati a partire dai fotogrammi dei video
✅ Creazione di video AI: Veo 3.1 genera nuovi video che corrispondono al movimento dell'utente
✅ Pipeline asincrona: elaborazione in background con gestione delle code (max 3 simultanee)
✅ Composizione affiancata: composizione video basata su ffmpeg
✅ Deployment di Cloud Run: serverless, scalabilità automatica, nessuna gestione dei server
Concetti chiave che hai imparato
- Gemini Multimodal: invio di video come input e ricezione di analisi JSON strutturate
- Nano Banana (generazione di immagini di Gemini): utilizzo di immagini di riferimento e prompt di stile per generare avatar
- Veo 3.1: generazione di video asincrona con asset di riferimento e prompt di testo
- Cloud Run: deployment di container con variabili di ambiente e scalabilità automatica
- Pattern pipeline asincrona: attività in background fire-and-forget con
asyncio.Taskper operazioni di AI a lunga esecuzione - Gestione delle code: limitazione della frequenza dei job di AI simultanei per controllare i costi e le quote API
Riepilogo dell'architettura
Passaggi successivi
- Aggiungere altri stili di avatar: modifica
backend/app/prompts/avatar_generation.py - Personalizzare il prompt di Veo: modifica
backend/app/prompts/video_generation.py - Esegui localmente in modalità simulazione: imposta
MOCK_AI=truein.envper lo sviluppo senza chiamate API - Scalabilità per gli eventi: aumenta
--max-instanceseMAX_CONCURRENT_JOBS