
1. 소개
빌드할 항목
Gemini Motion Lab은 AI 기반의 실시간 키오스크 환경입니다. 사용자가 짧은 댄스 또는 동작 클립을 녹화하면 시스템은 다음 작업을 실행합니다.
- Gemini를 사용하여 움직임을 분석합니다 (신체 부위, 단계, 템포, 에너지).
- Nano Banana (Gemini Flash Image)를 사용하여 스타일이 지정된 아바타 이미지를 생성합니다.
- Veo를 사용하여 아바타로 동작을 재현하는 AI 동영상을 만듭니다.
- 나란히 배치된 동영상 (원본 + AI 생성)을 구성합니다.
- 모바일에 최적화된 페이지의 QR 코드를 통해 결과를 공유합니다.
이 Codelab을 마치면 전체 데모가 Google Cloud Run에 배포되고 이를 지원하는 AI 파이프라인을 이해하게 됩니다.
아키텍처 개요
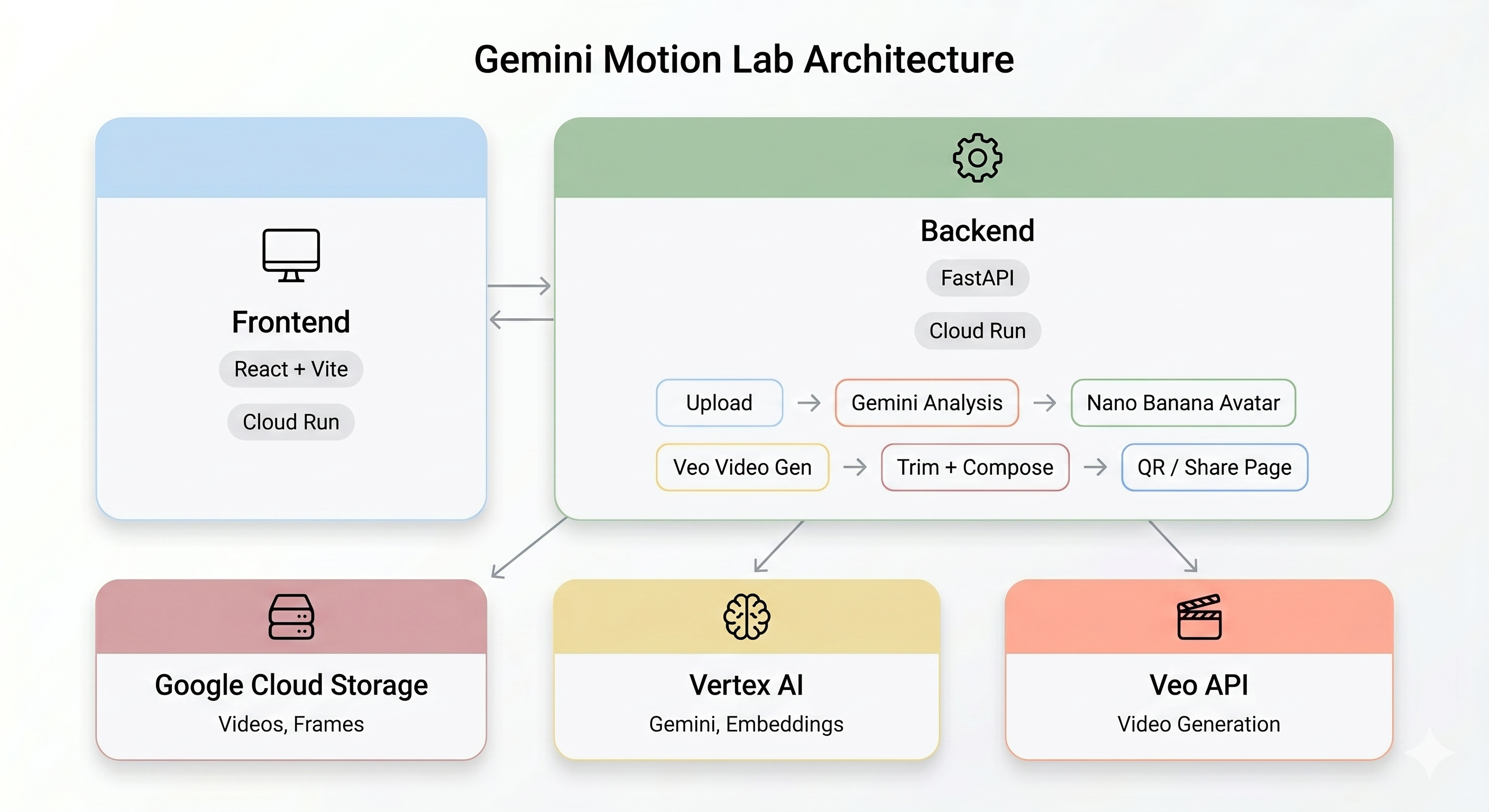
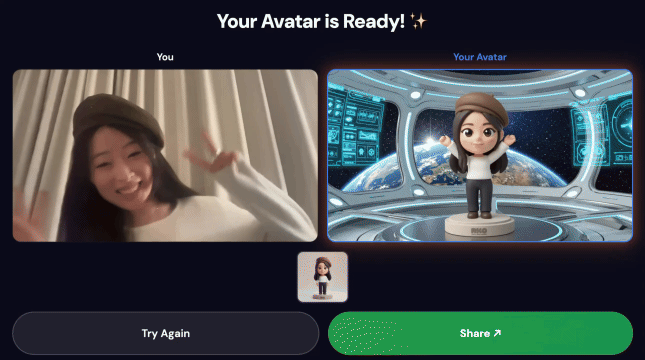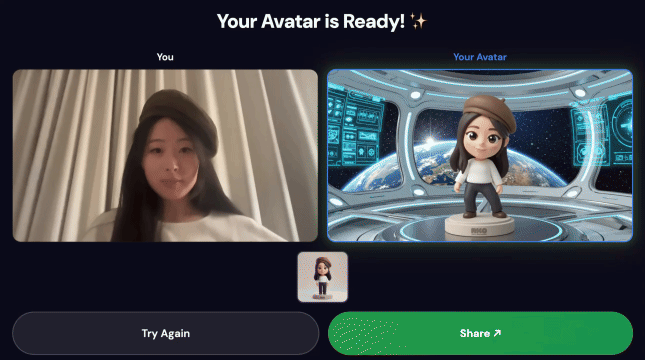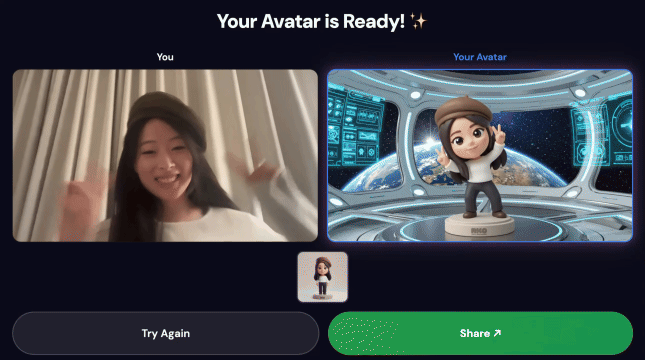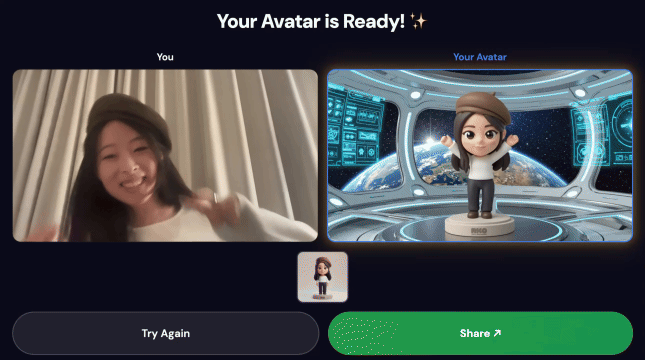
최종 데모:
핵심 기술
구성요소 | 기술 | 목적 |
모션 분석 | Gemini Flash | 동영상의 신체 움직임, 단계, 스타일 분석 |
아바타 생성 | Gemini Flash Image (Nano Banana) | 키 프레임에서 스타일이 지정된 1024×1024 아바타 생성 |
동영상 생성 | Veo 3.1 | 아바타 + 동작 프롬프트로 AI 동영상 만들기 |
백엔드 | FastAPI + Python 3.11 | 비동기 파이프라인 조정이 있는 API 서버 |
프런트엔드 | React + Vite + TypeScript | 카메라 녹화 및 라이브 상태가 표시된 키오스크 UI |
호스팅 | Cloud Run | 서버리스 컨테이너화된 배포 |
스토리지 | Google Cloud Storage | 동영상 업로드, 프레임, 잘라낸 출력 및 구성된 출력 |
2. 📦 저장소 클론
1. Cloud Shell 편집기 열기
👉 브라우저에서 Cloud Shell 편집기를 엽니다.
터미널이 화면 하단에 표시되지 않는 경우 다음 단계를 따르세요.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
2. 코드 클론
👉💻 터미널에서 저장소를 클론합니다.
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. 프로젝트 구조 살펴보기
저장소 레이아웃을 간단히 살펴보세요.
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ 크레딧 신청 및 GCP 프로젝트 만들기
1부: 결제 크레딧 신청
👉 Gmail 계정을 사용하여 결제 계정 크레딧을 청구하세요.
2부: 새 프로젝트 만들기
👉💻 터미널에서 init 스크립트를 실행 가능하게 만들고 실행합니다.
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
init.sh 스크립트는 다음을 수행합니다.
gemini-motion-lab접두사로 새 GCP 프로젝트를 만듭니다.- 프로젝트 ID를
~/project_id.txt에 저장합니다. - 결제 종속 항목 설치 및 결제 계정 자동 연결
3부: 프로젝트 구성 및 API 사용 설정
👉💻 터미널에서 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 이 프로젝트에 필요한 Google Cloud API를 사용 설정합니다 (1~2분 소요).
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [읽기 전용] 아키텍처 이해
이 섹션에서는 AI 파이프라인이 엔드 투 엔드로 작동하는 방식을 설명합니다. 조치 필요 없음 - 배포하기 전에 시스템을 이해하기 위해 읽어보세요.
AI 파이프라인
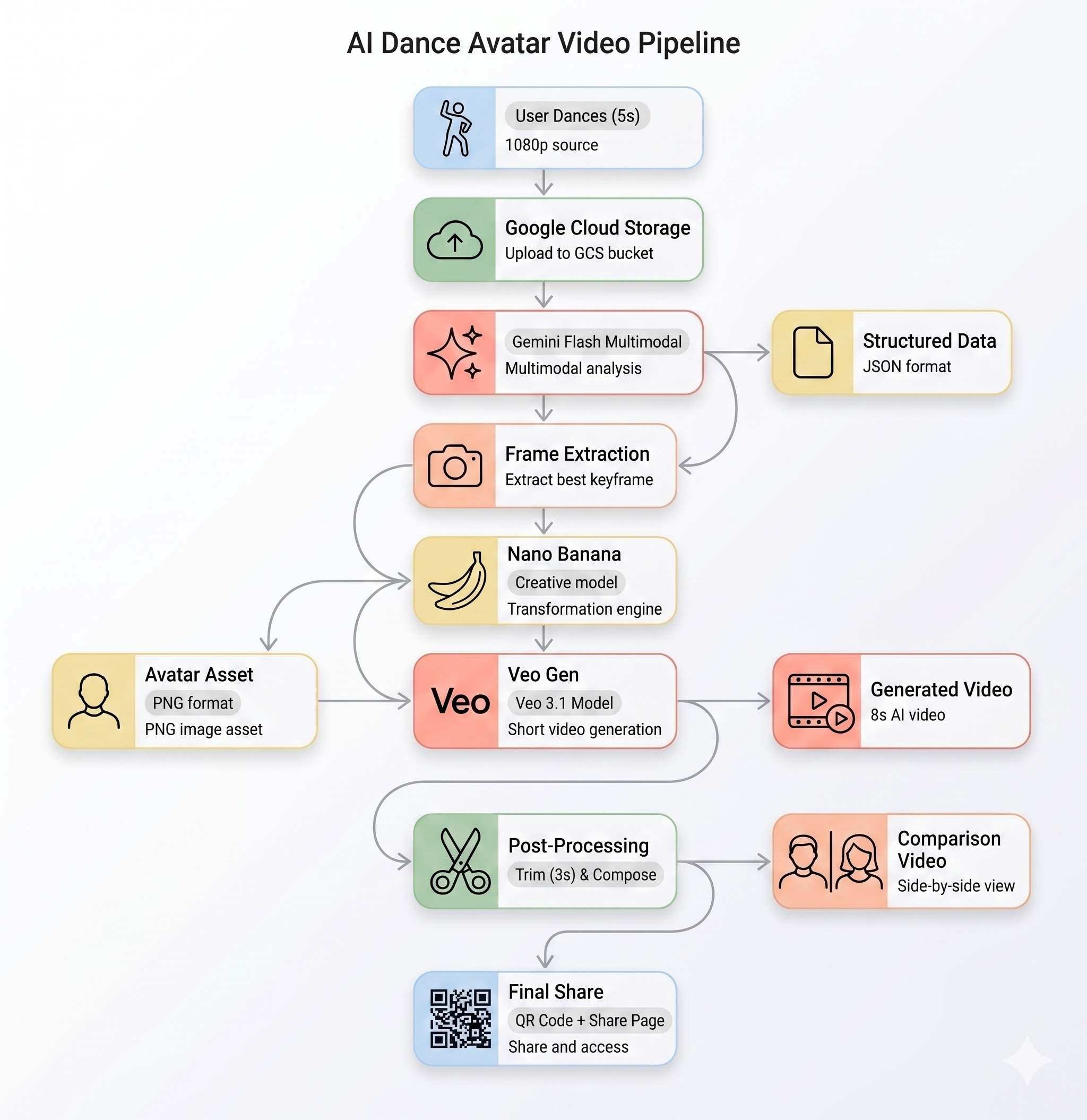
사용자가 키오스크에서 동작 클립을 녹화하면 다음 5단계가 순서대로 실행됩니다.

1단계: 동영상 업로드
프런트엔드는 사용자의 카메라에서 5초 WebM 클립을 녹화하고 백엔드의 /api/upload 엔드포인트를 통해 Google Cloud Storage에 업로드합니다.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
2단계: Gemini 동작 분석
백엔드에서 업로드된 동영상을 Gemini Flash (gemini-3-flash-preview)로 전송하여 구조화된 분석을 실행합니다.
작동 방식 (backend/app/services/gemini_service.py):
이 서비스는 Vertex AI SDK의 client.models.generate_content()를 동영상을 Part.from_uri 입력으로 사용하고 구조화된 프롬프트와 함께 사용합니다. response_mime_type="application/json"를 사용하면 Gemini가 파싱 가능한 JSON을 반환합니다. 또한 이 모델은 동작 단계에 대한 추론을 개선하기 위해 ThinkingConfig(thinking_budget=1024)를 사용합니다.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
3단계: Nano Banana 아바타 생성
동영상에서 추출한 최고의 프레임을 사용하여 Gemini Flash Image (gemini-3.1-flash-image-preview)가 1024×1024 스타일 아바타를 생성합니다.
작동 방식 (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
생성된 아바타 PNG가 GCS에 업로드되고 다음 단계로 전달됩니다.
4단계: Veo 동영상 생성
아바타 이미지는 Veo 3.1 (veo-3.1-fast-generate-001)이 8초 길이의 AI 동영상을 생성하는 데 사용되는 참조 애셋입니다.
작동 방식 (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Veo 생성은 비동기적이며 작업 ID를 즉시 반환합니다. 백엔드는 완료될 때까지 작업을 폴링합니다 (최대 10분).
5단계: 후처리 파이프라인
Veo가 완료되면 백그라운드 파이프라인 (backend/app/services/pipeline.py)이 자동으로 실행됩니다.
- 8초 Veo 출력을 3초로 자르기
- 나란히 배치된 동영상 (왼쪽에는 원본 녹화, 오른쪽에는 AI 동영상)을 작성합니다.
- 구성된 동영상을 GCS에 업로드합니다.
- 대기열 슬롯 해제
이 파이프라인은 백그라운드 asyncio.Task로 실행되므로 키오스크 프런트엔드가 기다릴 필요가 없습니다.
큐 시스템
Veo 생성은 리소스 집약적이므로 시스템에서 동시 작업 최대 3개를 적용합니다.
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
프런트엔드는 신규 사용자가 세션을 시작하기 전에 GET /api/queue/status를 확인합니다. 파이프라인이 완료되고 complete(video_id)을 호출하면 다음 사용자를 위해 슬롯이 열립니다.
Cloud Run - 서버리스 컨테이너
백엔드와 프런트엔드는 모두 Cloud Run 서비스로 배포됩니다.
서비스 | 목적 | 키 구성 |
백엔드 | FastAPI API 서버 | 2GiB 메모리 (ffmpeg를 통한 동영상 처리용) |
프런트엔드 | Nginx에서 제공하는 정적 React 앱 | 기본 메모리 |
5. ⚙️ 설정 스크립트 실행
1. 자동 설정 실행
setup.sh 스크립트는 필요한 클라우드 리소스를 만들고 .env 파일을 생성합니다.
👉💻 스크립트를 실행 가능하게 만들고 실행합니다.
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. IAM 역할 부여
이제 서비스 계정에 필요한 권한을 부여합니다.
👉💻 다음 명령어를 실행하여 프로젝트 ID를 설정하고 세 가지 역할을 모두 부여합니다.
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. .env 파일 확인
👉💻 생성된 .env 파일을 확인합니다.
cat .env
다음과 같이 표시됩니다.
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 백엔드 배포
1. 백엔드 Dockerfile 이해
배포하기 전에 컨테이너가 어떤 모습인지 알아보겠습니다.
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Cloud Run에 배포
👉💻 환경 변수를 로드하고 배포합니다.
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
3~5분 정도 걸립니다. Cloud Build는 다음을 수행합니다.
- 소스 코드 업로드
- Docker 이미지 빌드
- Artifact Registry로 푸시
- Cloud Run에 배포
3. 백엔드 URL 저장
👉💻 배포가 완료되면 백엔드 URL을 저장합니다.
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. 백엔드 공유 URL 업데이트
백엔드에서 사용자가 동영상을 다운로드할 수 있도록 QR 코드를 생성합니다. 이를 위해서는 자체 공개 URL을 알아야 합니다.
👉💻 자체 URL로 백엔드 구성을 업데이트합니다.
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. 백엔드 확인
👉💻 상태 엔드포인트를 테스트합니다.
curl $BACKEND_URL/api/health
예상 출력:
{"status":"ok"}
👉💻 대기열 상태를 확인합니다.
curl $BACKEND_URL/api/queue/status
예상 출력:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 프런트엔드 배포
1. 프런트엔드 Dockerfile 이해
프런트엔드는 다단계 빌드를 사용합니다. 먼저 React 앱을 빌드한 다음 Nginx로 제공합니다.
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Cloud Run에 배포
👉💻 먼저 Vite가 빌드 시에 이를 포함할 수 있도록 백엔드 URL을 .env 파일에 작성합니다.
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 이제 프런트엔드를 배포합니다.
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
2~3분 정도 걸립니다.
3. 프런트엔드 URL 가져오기
👉💻 프런트엔드 URL을 가져와 엽니다.
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 브라우저에서 URL을 엽니다. Gemini Motion Lab 키오스크 인터페이스가 표시됩니다.
8. 🎮 [선택사항] 데모 플레이
1. 모션 녹화
- 브라우저 (카메라 지원이 가장 우수한 Chrome 권장)에서 프런트엔드 URL을 엽니다.
- 시작을 클릭하여 녹화를 시작합니다.
- 약 5초 동안 춤을 추거나 움직입니다. 팔을 크게 움직이고 역동적인 포즈를 취하는 것이 좋습니다.
- 녹화가 자동으로 중지되고 업로드됩니다.
2. AI 파이프라인 보기
업로드 후 파이프라인이 실시간으로 실행되는 것을 확인할 수 있습니다.
단계 | 상황 설명 | 기간 |
분석 중... | Gemini Flash가 동영상의 움직임 패턴을 분석합니다. | 약 5~10초 |
아바타 생성 중... | Nano Banana가 가장 적합한 프레임으로 스타일이 지정된 아바타를 만듭니다. | 약 8~12초 |
동영상 만드는 중... | Veo 3.1은 아바타와 동작 프롬프트로 AI 동영상을 생성합니다. | 약 60~120초 |
작성 중... | ffmpeg가 자르고 나란히 비교를 만듭니다. | 약 5~10초 |
3. 작품 공유하기
파이프라인이 완료되면 다음 단계를 따르세요.
- 키오스크 화면에 QR 코드가 표시됩니다.
- 휴대전화로 QR 코드를 스캔합니다.
- 작성한 동영상이 포함된 모바일 최적화 공유 페이지가 표시됩니다.
4. 백엔드 로그 확인
👉💻 비하인드 스토리 보기:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
파이프라인을 추적하는 로그 줄이 표시됩니다.
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. 대기열 모니터링
👉💻 실행 중인 작업 수를 확인합니다.
curl $BACKEND_URL/api/queue/status
세션 3개가 동시에 활성 상태인 경우 응답에 다음이 표시됩니다.
{"active_jobs":3,"max_jobs":3,"available":false}
신규 사용자는 자리가 열릴 때까지 기다리라는 메시지가 표시됩니다.
9. 🎉 결론
빌드한 항목
✅ AI 동작 분석: Gemini Flash가 동영상을 분석하여 움직임, 템포, 스타일을 파악합니다.
✅ 아바타 생성: Nano Banana가 동영상 프레임에서 스타일이 지정된 아바타를 생성합니다.
✅ AI 생성 동영상 제작: Veo 3.1이 사용자의 움직임에 맞는 새 동영상을 생성합니다.
✅ 비동기 파이프라인 - 대기열 관리를 사용한 백그라운드 처리 (최대 동시 실행 수 3개)
✅ 나란히 보기 구성 - ffmpeg 기반 동영상 합성
✅ Cloud Run 배포 - 서버리스, 자동 확장, 서버 관리 없음
학습한 주요 개념
- Gemini 멀티모달 - 동영상을 입력으로 전송하고 구조화된 JSON 분석을 수신
- Nano Banana (Gemini 이미지 생성): 참조 이미지와 스타일 프롬프트를 사용하여 아바타 생성
- Veo 3.1: 참조 애셋 및 텍스트 프롬프트를 사용한 비동기 동영상 생성
- Cloud Run - 환경 변수 및 자동 확장을 사용하여 컨테이너 배포
- 비동기 파이프라인 패턴 - 장기 실행 AI 작업을 위해
asyncio.Task를 사용하여 백그라운드 작업을 파이어 앤 포겟 - 대기열 관리: 비용과 API 할당량을 관리하기 위해 동시 AI 작업의 비율 제한
아키텍처 요약
다음 단계
- 아바타 스타일 추가 -
backend/app/prompts/avatar_generation.py수정 - Veo 프롬프트 맞춤설정하기 - 수정
backend/app/prompts/video_generation.py - 모의 모드로 로컬에서 실행 - API 호출 없이 개발할 수 있도록
.env에서MOCK_AI=true설정 - 이벤트에 맞게 확장 -
--max-instances및MAX_CONCURRENT_JOBS증가