
1. Wprowadzenie
Co utworzysz
Gemini Motion Lab to interaktywny kiosk z technologią AI. Użytkownik nagrywa krótki klip z tańcem lub ruchem, a system:
- Analizuje ruch za pomocą Gemini (części ciała, fazy, tempo, energia).
- Generuje stylizowany obraz awatara za pomocą Nano Banana (Gemini Flash Image).
- Tworzy film AI za pomocą Veo, który odtwarza ruch za pomocą awatara.
- Tworzy film w formacie side-by-side (oryginalny + wygenerowany przez AI).
- Udostępnia wynik za pomocą kodu QR na stronie zoptymalizowanej pod kątem urządzeń mobilnych.
Po ukończeniu tego ćwiczenia będziesz mieć wdrożoną pełną wersję demonstracyjną w usłudze Google Cloud Run i zrozumiesz działanie potoku AI, który ją obsługuje.
Omówienie architektury
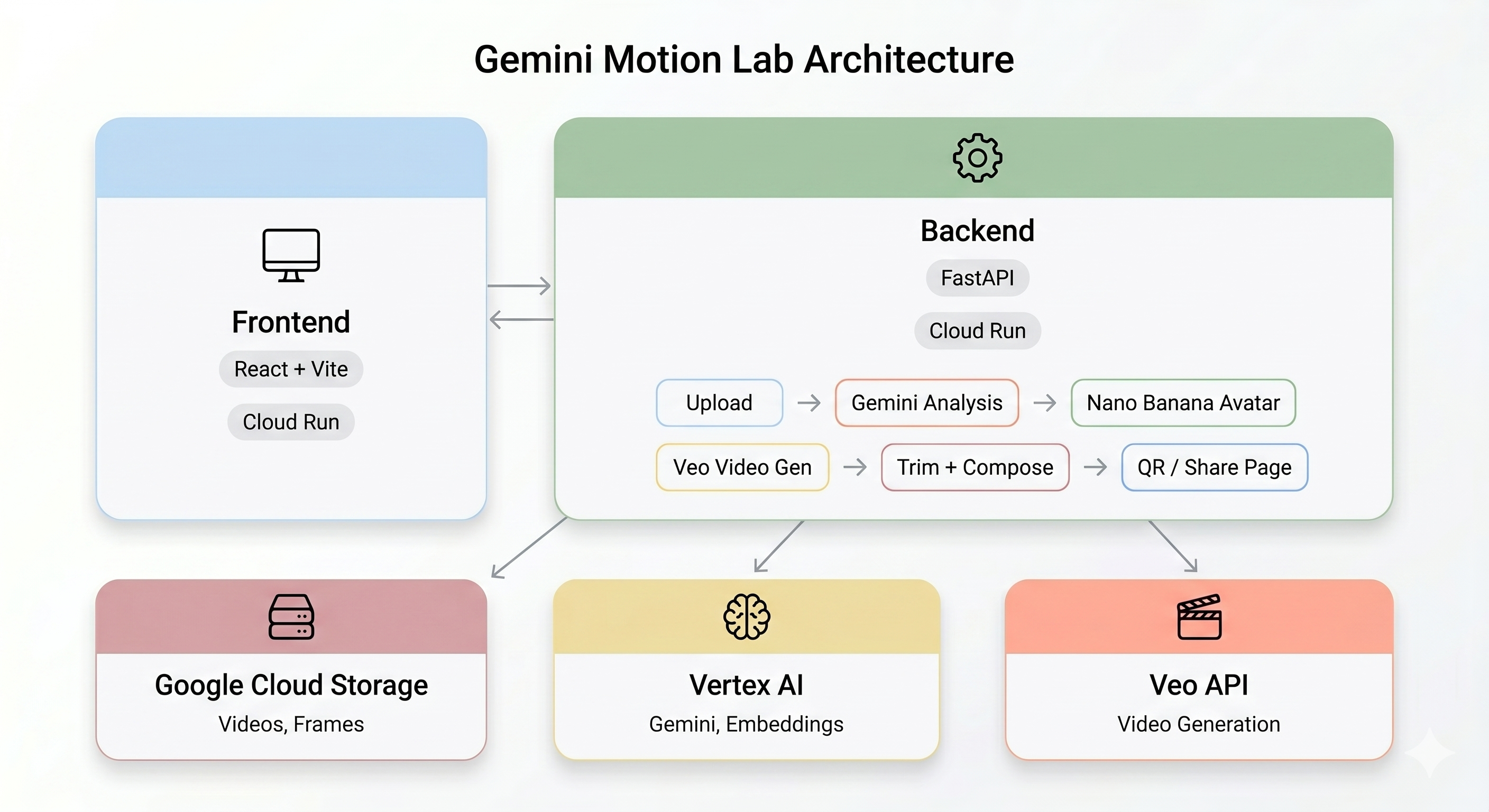
Wersja demonstracyjna:
Technologie podstawowe
Komponent | Technologia | Cel |
Analiza ruchu | Gemini Flash | Analizowanie filmu pod kątem ruchów ciała, faz i stylu |
Generowanie awatarów | Gemini Flash Image (Nano Banana) | Wygeneruj stylizowanego awatara o rozdzielczości 1024 × 1024 z klatki kluczowej |
Generowanie filmów | Veo 3.1 | Tworzenie filmu AI na podstawie awatara i prompta dotyczącego ruchu |
Backend | FastAPI + Python 3.11 | Serwer API z asynchroniczną orkiestracją potoków |
Frontend | React + Vite + TypeScript | Interfejs kiosku z nagrywaniem z kamery i stanem na żywo |
Hosting | Cloud Run | Bezserwerowe wdrożenie skonteneryzowane |
Miejsce na dane | Google Cloud Storage | Przesłane filmy, klatki, przycięte i złożone wyjścia |
2. 📦 Klonowanie repozytorium
1. Otwórz edytor Cloud Shell
👉 Otwórz edytor Cloud Shell w przeglądarce.
Jeśli terminal nie pojawia się u dołu ekranu:
- Kliknij Wyświetl.
- Kliknij Terminal.
2. Klonowanie kodu
👉💻 W terminalu sklonuj repozytorium:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Poznaj strukturę projektu
Szybki przegląd układu repozytorium:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Odbierz środki i utwórz projekt GCP
Część 1. Odbieranie środków na płatności
👉 Odbierz środki na koncie rozliczeniowym, korzystając z konta Gmail.
Część 2. Tworzenie nowego projektu
👉💻 W terminalu zmień skrypt inicjujący na wykonywalny i uruchom go:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Skrypt init.sh:
- Utwórz nowy projekt GCP z prefiksem
gemini-motion-lab. - Zapisz identyfikator projektu w
~/project_id.txt. - Zainstaluj zależności rozliczeniowe i automatycznie połącz konto rozliczeniowe
Część 3. Konfigurowanie projektu i włączanie interfejsów API
👉💻 Ustaw identyfikator projektu w terminalu:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Włącz interfejsy Google Cloud API potrzebne w tym projekcie (zajmie to około 1–2 minut):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [TYLKO DO ODCZYTU] Omówienie architektury
W tej sekcji opisujemy cały proces działania potoku AI. Nie musisz nic robić – po prostu przeczytaj, aby zrozumieć system przed wdrożeniem.
Potok AI
Gdy użytkownik nagrywa klip z ruchem w kiosku, następuje 5 etapów:

Etap 1. Przesyłanie filmu
Interfejs rejestruje 5-sekundowy klip WebM z kamery użytkownika i przesyła go do Google Cloud Storage za pomocą punktu końcowego /api/upload backendu.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Etap 2. Analiza ruchu w Gemini
Backend wysyła przesłany film do Gemini Flash (gemini-3-flash-preview) w celu przeprowadzenia analizy strukturalnej.
Jak to działa (backend/app/services/gemini_service.py):
Usługa korzysta z funkcji client.models.generate_content() pakietu Vertex AI SDK, w której film jest daną wejściową Part.from_uri, a prompt jest strukturalny. Symbol response_mime_type="application/json" sprawia, że Gemini zwraca kod JSON, który można przeanalizować. Model korzysta też z ThinkingConfig(thinking_budget=1024), aby lepiej wnioskować o fazach ruchu.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Etap 3. Generowanie awatara Nano Banana
Na podstawie najlepszej klatki wyodrębnionej z filmu Gemini Flash Image (gemini-3.1-flash-image-preview) generuje stylizowany awatar o rozdzielczości 1024 × 1024 pikseli.
Jak to działa (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
Wygenerowany plik PNG awatara jest przesyłany do GCS i przekazywany do następnego etapu.
Etap 4. Generowanie filmów za pomocą Veo
Obraz awatara jest używany jako zasób referencyjny dla Veo 3.1 (veo-3.1-fast-generate-001) do wygenerowania 8-sekundowego filmu wygenerowanego przez AI.
Jak to działa (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Generowanie Veo jest asynchroniczne – natychmiast zwraca identyfikator operacji. Backend odpytuje operację do momentu jej zakończenia (maksymalnie 10 minut).
Etap 5. Potok przetwarzania końcowego
Po zakończeniu pracy Veo automatycznie uruchamia się proces w tle (backend/app/services/pipeline.py):
- Przytnij 8-sekundowy film wygenerowany przez Veo do 3 sekund.
- Utwórz film obok siebie (oryginalne nagranie po lewej stronie, film wygenerowany przez AI po prawej stronie).
- Prześlij utworzony film do GCS.
- Zwolnij miejsce w kolejce.
Ten potok działa w tle asyncio.Task – interfejs kiosku nie musi czekać.
System kolejkowy
Generowanie filmów w Veo jest zasobochłonne, dlatego system wymusza maksymalnie 3 równoczesne zadania:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Zanim nowy użytkownik rozpocznie sesję, interfejs sprawdza GET /api/queue/status. Gdy potok się zakończy i wywoła funkcję complete(video_id), miejsce zostanie otwarte dla następnego użytkownika.
Cloud Run – kontenery bezserwerowe
Zarówno backend, jak i frontend są wdrażane jako usługi Cloud Run:
Usługa | Cel | Konfiguracja klucza |
Backend | Serwer API FastAPI | 2 GiB pamięci (do przetwarzania wideo za pomocą ffmpeg) |
Frontend | Statyczna aplikacja React obsługiwana przez Nginx | Domyślna pamięć |
5. ⚙️ Uruchom skrypt konfiguracji
1. Uruchom automatyczną konfigurację
Skrypt setup.sh tworzy wymagane zasoby w chmurze i generuje plik .env.
👉💻 Ustaw skrypt jako wykonywalny i uruchom go:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Przyznawanie ról uprawnień
Teraz przyznaj kontu usługi wymagane uprawnienia.
👉💻 Uruchom te polecenia, aby ustawić identyfikator projektu i przyznać wszystkie 3 role:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Weryfikacja pliku .env
👉💻 Sprawdź wygenerowany plik .env:
cat .env
Zobaczysz, że:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Wdróż backend
1. Informacje o pliku Dockerfile backendu
Zanim wdrożysz kontener, zobacz, jak wygląda:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Wdrożenie w Cloud Run
👉💻 Wczytaj zmienne środowiskowe i wdróż:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Zajmie to około 3–5 minut. Cloud Build:
- Prześlij kod źródłowy
- Tworzenie obrazu Dockera
- Przesyłanie go do Artifact Registry
- wdrożyć go w Cloud Run,
3. Zapisz adres URL backendu
👉💻 Po wdrożeniu zapisz adres URL backendu:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Aktualizowanie adresu URL udostępniania backendu
Backend generuje kody QR, aby użytkownicy mogli pobierać filmy. Aby to zrobić, musi znać swój publiczny adres URL.
👉💻 Zaktualizuj konfigurację backendu za pomocą własnego adresu URL:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Weryfikacja backendu
👉💻 Przetestuj punkt końcowy stanu:
curl $BACKEND_URL/api/health
Oczekiwane dane wyjściowe:
{"status":"ok"}
👉💻 Sprawdź stan kolejki:
curl $BACKEND_URL/api/queue/status
Oczekiwane dane wyjściowe:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Wdrażanie frontendu
1. Informacje o pliku Dockerfile frontendu
Interfejs korzysta z wielostopniowego procesu kompilacji – najpierw kompiluje aplikację React, a następnie udostępnia ją za pomocą Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Wdrożenie w Cloud Run
👉💻 Najpierw wpisz adres URL backendu do pliku .env, aby Vite mógł go uwzględnić podczas kompilacji:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Teraz wdróż frontend:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Zajmie to około 2–3 minut.
3. Pobieranie adresu URL interfejsu
👉💻 Pobierz i otwórz adres URL frontendu:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Otwórz adres URL w przeglądarce – powinna się wyświetlić interaktywna aplikacja Gemini Motion Lab.
8. 🎮 [OPCJONALNIE] Wypróbuj wersję demonstracyjną
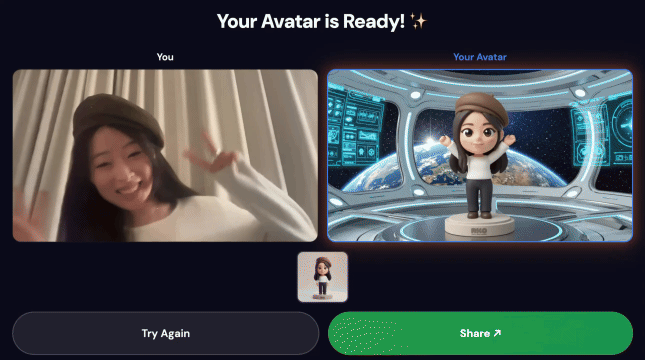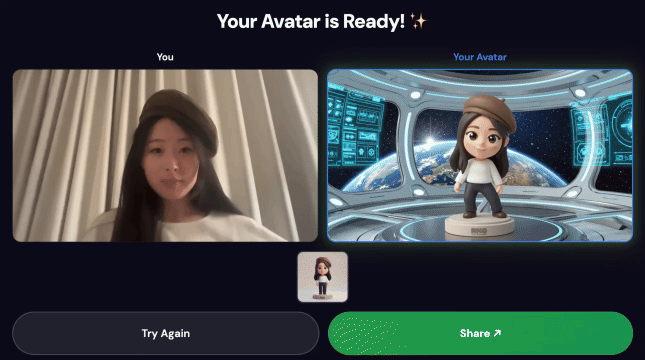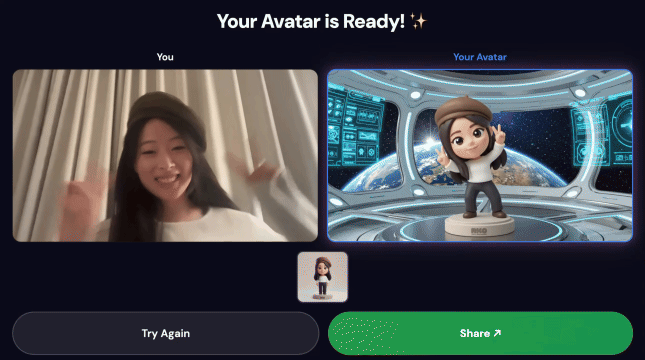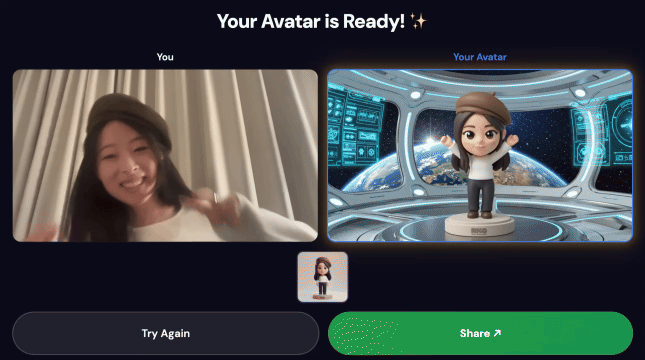
1. Nagrywanie ruchu
- Otwórz adres URL interfejsu w przeglądarce (najlepiej w Chrome, aby uzyskać najlepszą obsługę kamery).
- Aby rozpocząć nagrywanie, kliknij Start.
- Zatańcz lub poruszaj się przez około 5 sekund – najlepiej sprawdzą się duże ruchy ramion i dynamiczne pozy.
- Nagrywanie zostanie automatycznie zatrzymane i przesłane.
2. Obejrzyj potok AI
Po przesłaniu zobaczysz działanie potoku w czasie rzeczywistym:
Faza | Co się dzieje | Czas trwania |
Analizuję… | Gemini Flash analizuje film pod kątem wzorców ruchu. | ~5–10 s |
Generowanie awatara... | Nano Banana tworzy stylizowany awatar na podstawie najlepszej klatki | ~8–12 s |
Tworzenie filmu… | Veo 3.1 generuje film AI na podstawie awatara i prompta dotyczącego ruchu. | ~60–120 s |
Tworzenie… | ffmpeg przycina pliki i tworzy porównanie obok siebie. | ~5–10 s |
3. Udostępnianie utworzonego filmu
Po zakończeniu potoku:
- Na ekranie kiosku pojawi się kod QR.
- Zeskanuj kod QR telefonem.
- Pojawi się strona udostępniania zoptymalizowana pod kątem urządzeń mobilnych, na której będzie Twój film.
4. Sprawdzanie dzienników backendu
👉💻 Zobacz, co się wydarzyło za kulisami:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Zobaczysz wiersze logów śledzące potok:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Monitorowanie kolejki
👉💻 Sprawdź, ile zadań jest uruchomionych:
curl $BACKEND_URL/api/queue/status
Jeśli jednocześnie aktywne są 3 sesje, odpowiedź będzie wyglądać tak:
{"active_jobs":3,"max_jobs":3,"available":false}
Nowi użytkownicy będą musieli poczekać, aż zwolni się miejsce.
9. 🎉 Podsumowanie
Co utworzysz
✅ Analiza ruchu AI – Gemini Flash analizuje wideo pod kątem ruchu, tempa i stylu.
✅ Generowanie awatarów – Nano Banana tworzy stylizowane awatary z klatek wideo.
✅ Tworzenie filmów AI – Veo 3.1 generuje nowe filmy pasujące do ruchu użytkownika.
✅ Potok asynchroniczny – przetwarzanie w tle z zarządzaniem kolejką (maks. 3 jednocześnie)
✅ Kompozycja obok siebie – kompozycja wideo oparta na ffmpeg
✅ Wdrożenie Cloud Run – bezserwerowe, autoskalowanie, bez zarządzania serwerami
Kluczowe pojęcia, które zostały omówione
- Gemini Multimodal – wysyłanie filmu jako danych wejściowych i otrzymywanie uporządkowanej analizy w formacie JSON
- Nano Banana (generowanie obrazów w Gemini) – generowanie awatarów na podstawie obrazów referencyjnych i promptów dotyczących stylu
- Veo 3.1 – asynchroniczne generowanie filmów z użyciem komponentów referencyjnych i promptów tekstowych.
- Cloud Run – wdrażanie kontenerów ze zmiennymi środowiskowymi i autoskalowaniem
- Wzorzec potoku asynchronicznego – zadania w tle typu „wyślij i zapomnij” z
asyncio.Taskdo długotrwałych operacji AI. - Zarządzanie kolejką – ograniczanie liczby równoczesnych zadań AI w celu kontrolowania kosztów i limitów interfejsu API.
Podsumowanie architektury
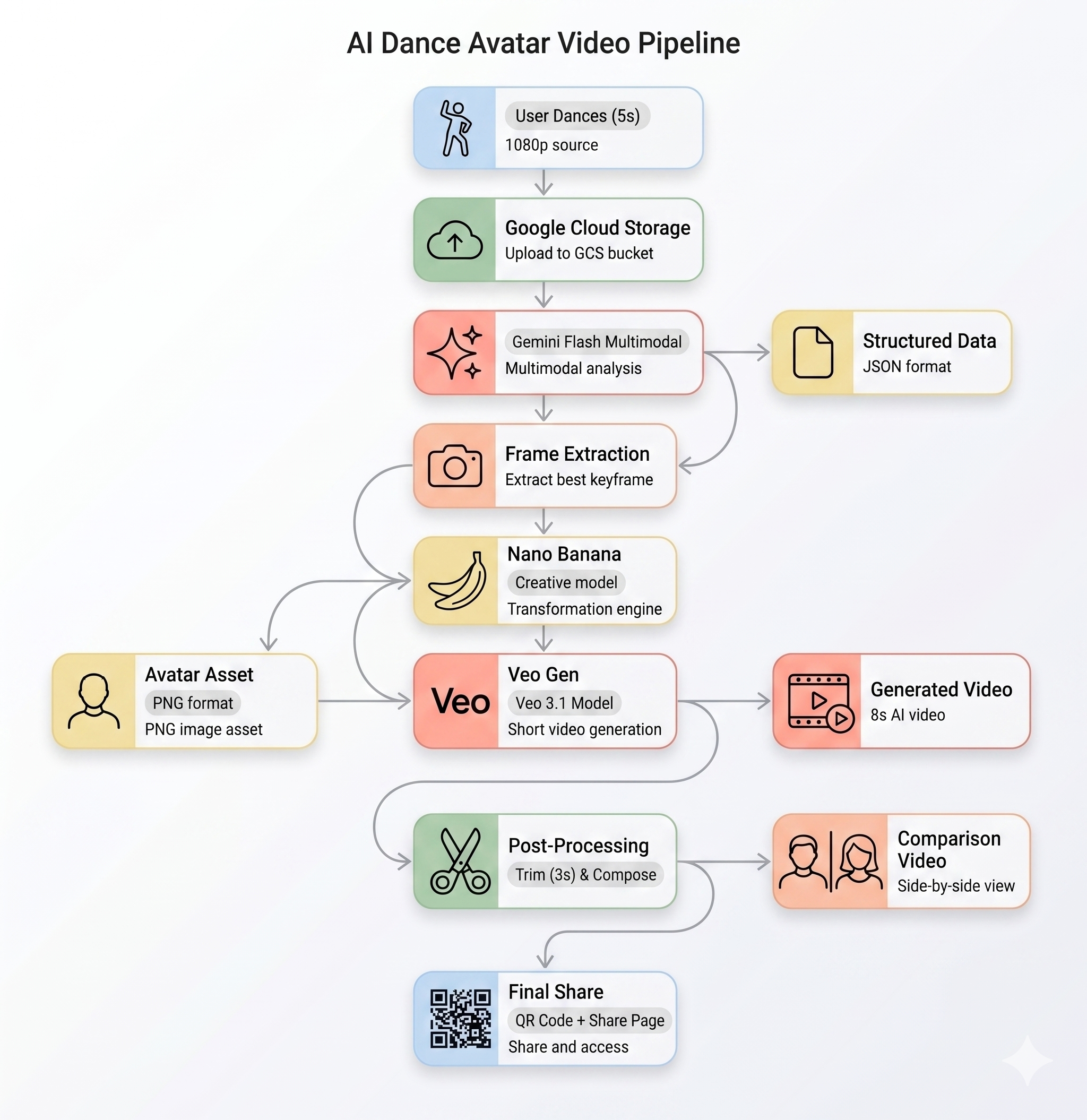
Co dalej?
- Dodaj więcej stylów awatara – Edytuj
backend/app/prompts/avatar_generation.py - Dostosowywanie prompta Veo – kliknij Edytuj
backend/app/prompts/video_generation.py. - Uruchamianie lokalne w trybie symulacji – ustaw
MOCK_AI=truew.envna potrzeby programowania bez wywołań interfejsu API. - Skalowanie pod kątem zdarzeń – zwiększanie wartości
--max-instancesiMAX_CONCURRENT_JOBS