
1. Introdução
O que você criará
O Gemini Motion Lab é uma experiência de quiosque ao vivo com tecnologia de IA. Um usuário grava um vídeo curto de dança ou movimento, e o sistema:
- Analisa o movimento usando o Gemini (partes do corpo, fases, tempo, energia)
- Gera uma imagem de avatar estilizada usando o Nano Banana (Gemini Flash Image)
- Cria um vídeo de IA usando o Veo que recria o movimento com o avatar
- Compõe um vídeo lado a lado (original + gerado por IA)
- Compartilha o resultado por um QR code em uma página otimizada para dispositivos móveis
Ao final deste codelab, você terá a demonstração completa implantada no Google Cloud Run e vai entender o pipeline de IA que a alimenta.
Visão geral da arquitetura
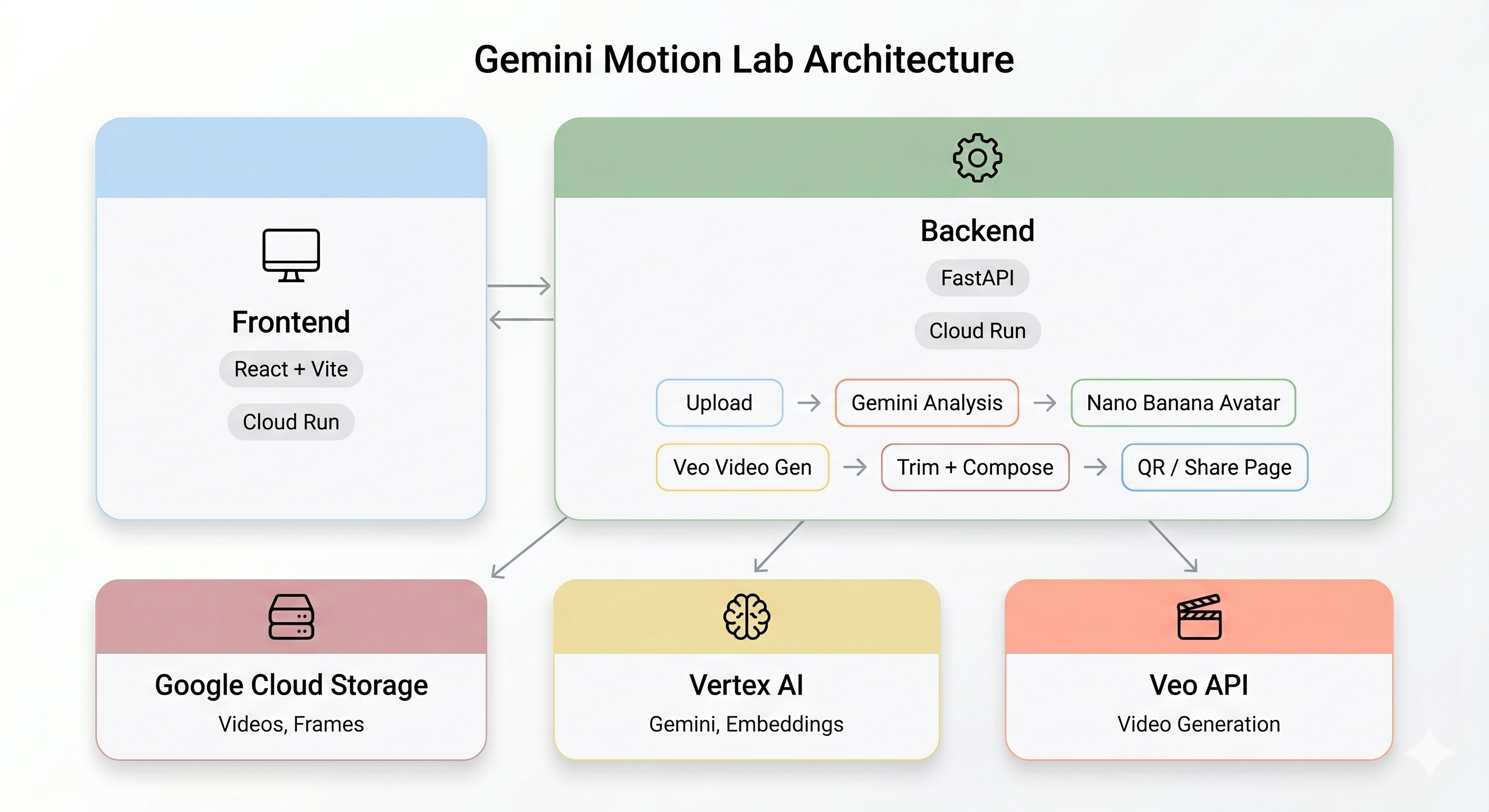
Demonstração final:
Principais tecnologias
Componente | Tecnologia | Finalidade |
Análise de movimento | Gemini Flash | Analisar movimentos, fases e estilo do corpo em vídeos |
Geração de avatar | Gemini Flash Image (Nano Banana) | Gerar um avatar estilizado de 1024×1024 com base em um frame-chave |
Geração de vídeo | Veo 3.1 | Criar um vídeo de IA com base no avatar e no comando de movimento |
Back-end | FastAPI + Python 3.11 | Servidor de API com orquestração de pipeline assíncrona |
Front-end | React + Vite + TypeScript | Interface do quiosque com gravação de câmera e status ao vivo |
Hosting | Cloud Run | Implantação conteinerizada sem servidor |
Armazenamento | Google Cloud Storage | Envios de vídeo, frames, saídas cortadas e compostas |
2. 📦 Clone o repositório
1. Abrir editor do Cloud Shell
👉 Abra o editor do Cloud Shell no navegador.
Se o terminal não aparecer na parte de baixo da tela:
- Clique em Visualizar.
- Clique em Terminal.
2. Clonar o código
👉💻 No terminal, clone o repositório:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Conheça a estrutura do projeto
Confira o layout do repositório:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Reivindicar créditos e criar um projeto do GCP
Parte 1: reivindicar seus créditos de faturamento
👉 Reivindique o crédito da conta de faturamento usando sua conta do Gmail.
Parte 2: criar um projeto
👉💻 No terminal, torne o script de inicialização executável e execute-o:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
O script init.sh vai:
- Crie um projeto do GCP com o prefixo
gemini-motion-lab. - Salve o ID do projeto em
~/project_id.txt - Instalar dependências de faturamento e vincular automaticamente sua conta de faturamento
Parte 3: configurar o projeto e ativar as APIs
👉💻 Defina o ID do projeto no terminal:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Ative as APIs do Cloud necessárias para este projeto. Isso leva de 1 a 2 minutos:
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [SOMENTE LEITURA] Noções básicas sobre a arquitetura
Esta seção explica como o pipeline de IA funciona de ponta a ponta. Nenhuma ação necessária: basta ler para entender o sistema antes de implantar.
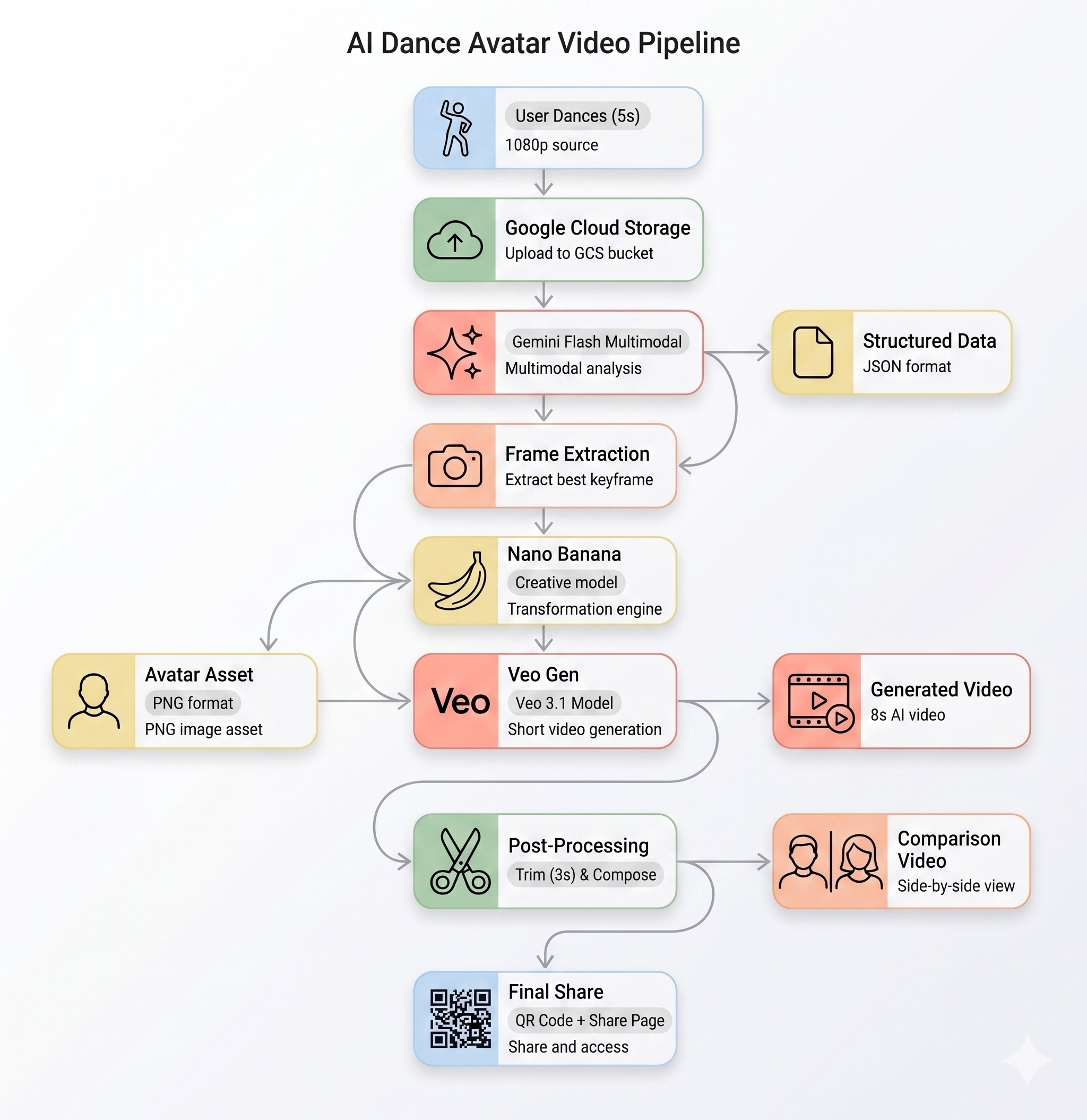
O pipeline de IA
Quando um usuário grava um clipe de movimento no quiosque, cinco etapas são executadas em sequência:

Etapa 1: upload de vídeo
O front-end grava um clipe WebM de 5 segundos da câmera do usuário e faz upload dele para o Google Cloud Storage pelo endpoint /api/upload do back-end.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Etapa 2: análise de movimento do Gemini
O back-end envia o vídeo enviado por upload para o Gemini Flash (gemini-3-flash-preview) para análise estruturada.
Como funciona (backend/app/services/gemini_service.py):
O serviço usa o client.models.generate_content() do SDK da Vertex AI com o vídeo como uma entrada Part.from_uri e um comando estruturado. O response_mime_type="application/json" garante que o Gemini retorne um JSON analisável. O modelo também usa ThinkingConfig(thinking_budget=1024) para melhorar o raciocínio sobre as fases de movimento.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Etapa 3: geração de avatar do Nano Banana
Usando o melhor frame extraído do vídeo, o Gemini Flash Image (gemini-3.1-flash-image-preview) gera um avatar estilizado de 1024×1024.
Como funciona (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
O PNG do avatar gerado é enviado para o GCS e transmitido para a próxima etapa.
Etapa 4: geração de vídeos com o Veo
A imagem do avatar é usada como um recurso de referência para o Veo 3.1 (veo-3.1-fast-generate-001) gerar um vídeo de IA de 8 segundos.
Como funciona (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
A geração do Veo é assíncrona: ela retorna um ID de operação imediatamente. O back-end pesquisa a operação até a conclusão (até 10 minutos).
Etapa 5: pipeline de pós-processamento
Quando o Veo termina, o pipeline em segundo plano (backend/app/services/pipeline.py) é executado automaticamente:
- Corte a saída de 8 segundos do Veo para 3 segundos
- Componha um vídeo lado a lado (gravação original à esquerda, vídeo de IA à direita)
- Faça upload do vídeo composto para o GCS
- Libere o espaço na fila
Esse pipeline é executado como um asyncio.Task em segundo plano. O front-end do quiosque não precisa esperar.
O sistema de filas
Como a geração do Veo consome muitos recursos, o sistema impõe um máximo de três jobs simultâneos:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
O front-end verifica GET /api/queue/status antes de permitir que um novo usuário inicie uma sessão. Quando um pipeline é concluído e chama complete(video_id), o slot é aberto para o próximo usuário.
Cloud Run: contêineres sem servidor
O back-end e o front-end são implantados como serviços do Cloud Run:
Serviço | Finalidade | Configuração da chave |
Back-end | Servidor de API FastAPI | 2 GiB de memória (para processamento de vídeo via ffmpeg) |
Front-end | App React estático veiculado pelo Nginx | Memória padrão |
5. ⚙️ Executar script de configuração
1. Executar a configuração automática
O script setup.sh cria os recursos de nuvem necessários e gera o arquivo .env.
👉💻 Torne o script executável e execute-o:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Conceder papéis do IAM
Agora conceda as permissões necessárias à conta de serviço.
👉💻 Execute os comandos a seguir para definir o ID do projeto e conceder todas as três funções:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Verificar seu arquivo .env
👉💻 Confira o arquivo .env gerado:
cat .env
Você verá:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Implantar o back-end
1. Entender o Dockerfile do back-end
Antes de fazer a implantação, vamos entender como o contêiner se parece:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Implantar no Cloud Run
👉💻 Carregue as variáveis de ambiente e implante:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Isso leva cerca de 3 a 5 minutos. O Cloud Build vai:
- Fazer upload do código-fonte
- Compilar a imagem Docker
- Envie para o Artifact Registry
- Implante no Cloud Run
3. Salvar o URL de back-end
👉💻 Depois da implantação, salve o URL do back-end:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Atualizar o URL de compartilhamento de back-end
O back-end gera QR codes para que os usuários possam baixar os vídeos. Para isso, ele precisa saber o próprio URL público.
👉💻 Atualize a configuração de back-end com o próprio URL:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Verificar o back-end
👉💻 Teste o endpoint de integridade:
curl $BACKEND_URL/api/health
Resposta esperada:
{"status":"ok"}
👉💻 Verifique o status da fila:
curl $BACKEND_URL/api/queue/status
Resposta esperada:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Implante o front-end
1. Entender o Dockerfile do front-end
O front-end usa um build de várias etapas. Primeiro, ele cria o app React e, em seguida, o disponibiliza com o Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Implantar no Cloud Run
👉💻 Primeiro, escreva o URL do back-end em um arquivo .env para que o Vite possa incorporá-lo no tempo de build:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Agora implante o front-end:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Isso leva cerca de 2 a 3 minutos.
3. Acessar o URL do front-end
👉💻 Recupere e abra o URL do front-end:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Abra o URL no navegador. A interface do quiosque do Gemini Motion Lab vai aparecer.
8. 🎮 [OPCIONAL] Teste a demonstração
1. Gravar um movimento
- Abra o URL do front-end no navegador (de preferência o Chrome para melhor suporte à câmera).
- Clique em Iniciar para começar a gravar.
- Dance ou se movimente por cerca de 5 segundos. Movimentos amplos dos braços e poses dinâmicas funcionam melhor.
- A gravação será interrompida e enviada automaticamente
2. Acompanhar o pipeline de IA
Depois do upload, você vai ver a execução do pipeline em tempo real:
Fase | O que está acontecendo | Duração |
Analisando... | O Gemini Flash analisa seu vídeo em busca de padrões de movimento | Cerca de 5 a 10 segundos |
Gerando avatar… | O Nano Banana cria um avatar estilizado com base no seu melhor frame | Cerca de 8 a 12 segundos |
Criando vídeo… | O Veo 3.1 gera um vídeo de IA com base no avatar e no comando de movimento | ~60 a 120 s |
Criando… | O ffmpeg corta e cria uma comparação lado a lado | Cerca de 5 a 10 segundos |
3. Compartilhe sua criação
Quando o pipeline for concluído:
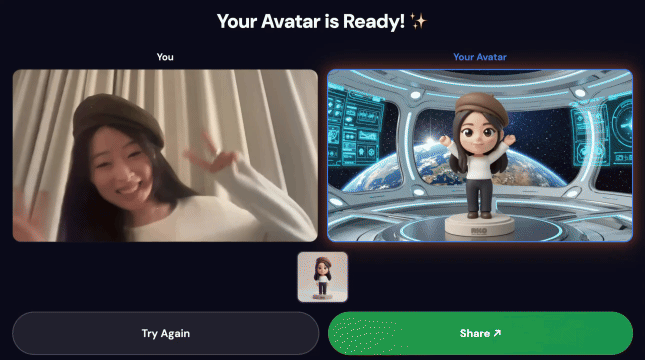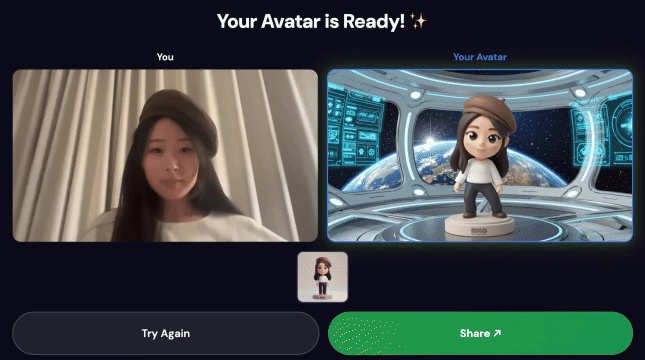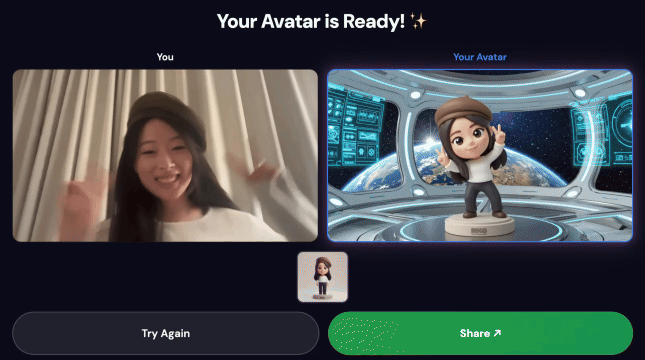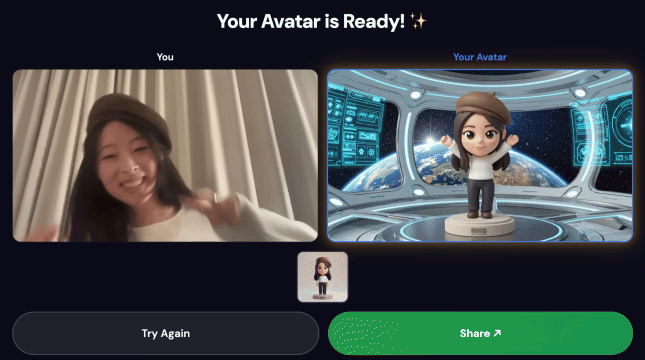
- Um QR code vai aparecer na tela do quiosque.
- Leia o QR code com seu smartphone.
- Uma página de compartilhamento otimizada para dispositivos móveis vai aparecer com o vídeo criado.
4. Verificar os registros do back-end
👉💻 Veja o que aconteceu nos bastidores:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Você vai ver linhas de registro rastreando o pipeline:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Monitorar a fila
👉💻 Verifique quantos jobs estão em execução:
curl $BACKEND_URL/api/queue/status
Se três sessões estiverem ativas simultaneamente, a resposta vai mostrar:
{"active_jobs":3,"max_jobs":3,"available":false}
Os novos usuários vão precisar esperar até que uma vaga seja aberta.
9. 🎉 Conclusão
O que você criou
✅ Análise de movimento com IA: o Gemini Flash analisa o movimento, o ritmo e o estilo do vídeo.
✅ Geração de avatar: o Nano Banana cria avatares estilizados com base em frames de vídeo.
✅ Ferramenta de criação de vídeo com IA: o Veo 3.1 gera novos vídeos que correspondem ao movimento do usuário.
✅ Pipeline assíncrono: processamento em segundo plano com gerenciamento de filas (máximo de três simultâneos)
✅ Composição lado a lado: composição de vídeo com tecnologia ffmpeg.
✅ Implantação do Cloud Run: sem servidor, com escalonamento automático e sem gerenciamento de servidores
Principais conceitos aprendidos
- Gemini Multimodal: envie um vídeo como entrada e receba uma análise estruturada em JSON.
- Nano Banana (geração de imagens do Gemini): use imagens de referência e comandos de estilo para gerar avatares
- Veo 3.1: geração de vídeo assíncrona com recursos de referência e comandos de texto
- Cloud Run: implantação de contêineres com variáveis de ambiente e escalonamento automático
- Padrão de pipeline assíncrono: tarefas em segundo plano de disparo e esquecimento com
asyncio.Taskpara operações de IA de longa duração - Gerenciamento de filas: limitação de taxa de jobs simultâneos de IA para controlar custos e cotas de API
Recapitulação da arquitetura
A seguir
- Adicionar mais estilos de avatar: edite
backend/app/prompts/avatar_generation.py - Personalizar o comando do Veo: clique em Editar
backend/app/prompts/video_generation.py. - Executar localmente no modo de simulação: defina
MOCK_AI=trueem.envpara desenvolvimento sem chamadas de API. - Escalonar para eventos: aumente
--max-instanceseMAX_CONCURRENT_JOBS