
1. Введение
Что вы построите
Gemini Motion Lab — это интерактивный киоск с поддержкой искусственного интеллекта. Пользователь записывает короткий танцевальный или другой видеоролик, и система:
- Анализирует движения, используя черты Близнецов (части тела, фазы, темп, энергия).
- Создает стилизованное изображение аватара с помощью Nano Banana (Gemini Flash Image).
- Создает видео с использованием ИИ и Veo , которое воспроизводит движение с помощью аватара.
- Создает видеоролик, состоящий из двух частей (оригинальный + сгенерированный ИИ).
- Результат отображается через QR-код на странице, оптимизированной для мобильных устройств.
К концу этого практического занятия вы развернете полную демонстрационную версию в Google Cloud Run и поймете, как работает конвейер обработки данных на основе искусственного интеллекта.
Обзор архитектуры
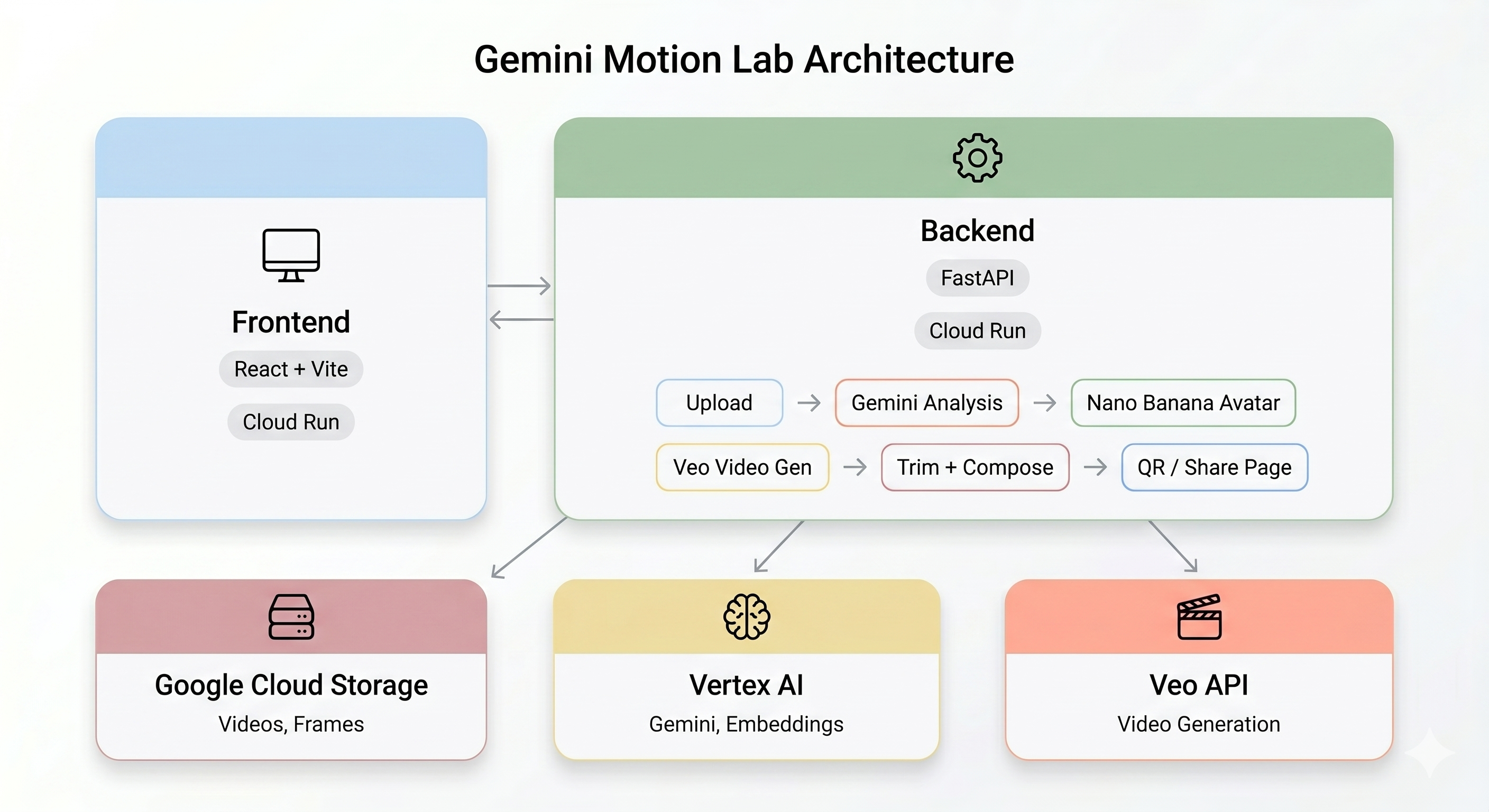
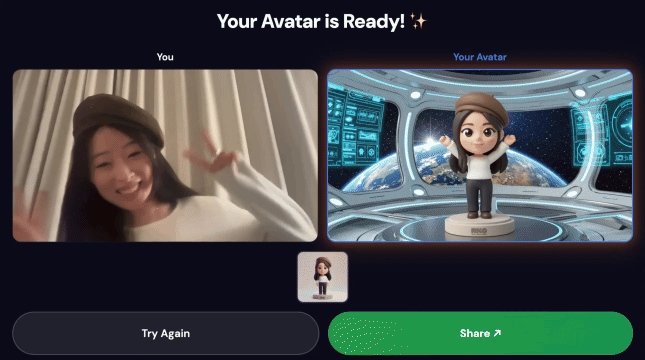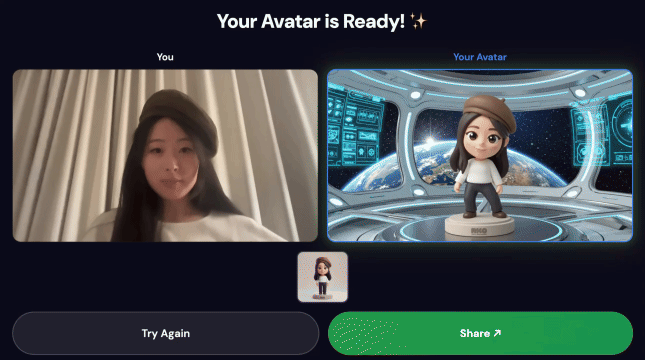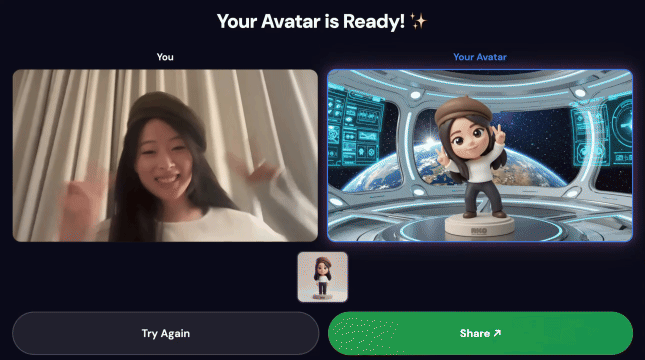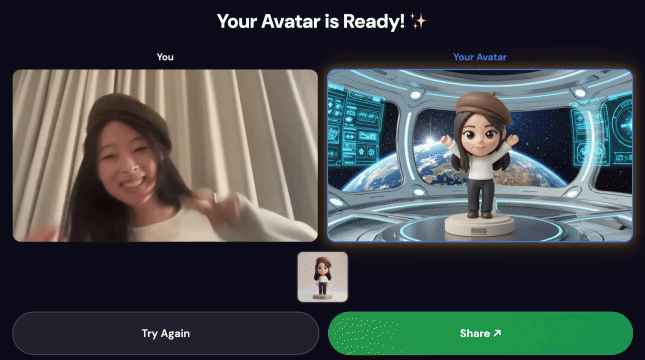
Финальная демонстрация:
Основные технологии
Компонент | Технологии | Цель |
Анализ движения | Gemini Flash | Проанализируйте видео с точки зрения движений тела, фаз и стиля. |
Создание аватара | Изображение, полученное с помощью вспышки Gemini Flash Image (Nano Banana) | Создайте стилизованный аватар размером 1024×1024 пикселей из ключевого кадра. |
Генерация видео | Veo 3.1 | Создайте видео с использованием ИИ на основе аватара и подсказки движения. |
Бэкенд | FastAPI + Python 3.11 | API-сервер с асинхронной оркестрацией конвейеров |
Внешний интерфейс | React + Vite + TypeScript | Пользовательский интерфейс киоска с записью видео с камеры и отображением статуса в реальном времени. |
Хостинг | Cloud Run | Бессерверное контейнерное развертывание |
Хранилище | Google Облачное хранилище | Загрузка видео, кадрирование, обрезка и компоновка видео. |
2. 📦 Клонируйте репозиторий
1. Откройте редактор Cloud Shell.
👉 Откройте редактор Cloud Shell в своем браузере.
Если терминал не отображается внизу экрана:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
2. Клонируйте код
👉💻 В терминале клонируйте репозиторий:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Изучите структуру проекта.
Взгляните на структуру репозитория:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Получите кредиты и создайте проект GCP
Часть 1: Запросите свои платежные компенсации
👉 Получите средства на свой расчетный счет, используя свою учетную запись Gmail .
Часть 2: Создание нового проекта
👉💻 В терминале сделайте скрипт инициализации исполняемым и запустите его:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Скрипт init.sh выполнит следующие действия:
- Создайте новый проект GCP с префиксом
gemini-motion-lab - Сохраните идентификатор проекта в файл
~/project_id.txt - Установите необходимые для выставления счетов компоненты и автоматически свяжите свой платежный аккаунт.
Часть 3: Настройка проекта и включение API.
👉💻 Укажите идентификатор вашего проекта в терминале:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Включите необходимые для этого проекта API Google Cloud (это займет примерно 1-2 минуты):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [ТОЛЬКО ДЛЯ ЧТЕНИЯ] Понимание архитектуры
В этом разделе объясняется, как работает конвейер обработки данных в системе искусственного интеллекта от начала до конца. Никаких действий не требуется — просто прочтите, чтобы понять систему, прежде чем развертывать ее.
Конвейер искусственного интеллекта
Когда пользователь записывает видеоролик на киоске, последовательно выполняются пять этапов:

Этап 1: Загрузка видео
Фронтенд записывает 5-секундный видеоролик в формате WebM с камеры пользователя и загружает его в Google Cloud Storage через конечную точку /api/upload бэкэнда.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Этап 2: Анализ движения Близнецов
Бэкенд отправляет загруженное видео в Gemini Flash ( gemini-3-flash-preview ) для структурированного анализа.
Как это работает ( backend/app/services/gemini_service.py ):
Сервис использует client.models.generate_content() из SDK Vertex AI, где видео представлено в качестве входных данных Part.from_uri , а также структурированный запрос. response_mime_type="application/json" гарантирует, что Gemini вернет JSON, пригодный для анализа. Модель также использует ThinkingConfig(thinking_budget=1024) для более эффективного анализа фаз движения.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Этап 3: Создание аватара-нанобанана
Используя лучший кадр, извлеченный из видео, Gemini Flash Image ( gemini-3.1-flash-image-preview ) генерирует стилизованный аватар размером 1024×1024 пикселей.
Как это работает ( backend/app/services/nano_banana_service.py ):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
Сгенерированный PNG-файл аватара загружается в GCS и передается на следующий этап.
Этап 4: Генерация видео Veo
Изображение аватара используется в качестве эталонного ресурса для Veo 3.1 ( veo-3.1-fast-generate-001 ) для генерации 8-секундного видеоролика с использованием ИИ.
Как это работает ( backend/app/services/veo_service.py ):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Генерация Veo происходит асинхронно — идентификатор операции возвращается немедленно. Бэкенд опрашивает операцию до её завершения (до 10 минут).
Этап 5: Конвейер постобработки
После завершения работы Veo автоматически запускается фоновый конвейер ( backend/app/services/pipeline.py ):
- Обрежьте выходной сигнал Veo (8 секунд) до 3 секунд.
- Создайте видеоролик, расположенный рядом (исходная запись слева, видео, созданное с помощью ИИ, справа).
- Загрузите созданное видео в GCS.
- Освободите слот в очереди
Этот конвейер выполняется в фоновом режиме как asyncio.Task — интерфейсу киоска не нужно ждать.
Система очередей
Поскольку генерация Veo требует значительных ресурсов, система ограничивает количество одновременно выполняемых задач до 3 :
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Фронтенд проверяет GET /api/queue/status прежде чем разрешить новому пользователю начать сессию. Когда конвейер завершается и вызывается метод complete(video_id) , слот открывается для следующего пользователя.
Cloud Run — Бессерверные контейнеры
И бэкэнд, и фронтенд развернуты как сервисы Cloud Run :
Услуга | Цель | Конфигурация ключей |
Бэкенд | Сервер FastAPI API | 2 ГБ памяти (для обработки видео с помощью ffmpeg) |
Внешний интерфейс | Статическое React-приложение, обслуживаемое Nginx. | Память по умолчанию |
5. ⚙️ Запустите скрипт установки
1. Запустите автоматическую настройку.
Скрипт setup.sh создает необходимые облачные ресурсы и генерирует файл .env .
👉💻 Сделайте скрипт исполняемым и запустите его:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Предоставление ролей IAM
Теперь предоставьте необходимые права доступа учетной записи службы.
👉💻 Выполните следующие команды, чтобы установить идентификатор проекта и предоставить все три роли:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Проверьте файл .env
👉💻 Проверьте сгенерированный файл .env :
cat .env
Вам следует увидеть:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Разверните бэкэнд
1. Разберитесь в Dockerfile для бэкэнда.
Перед развертыванием давайте разберемся, как выглядит контейнер:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Развертывание в Cloud Run
👉💻 Загрузите переменные среды и выполните развертывание:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Это займет примерно 3-5 минут. Cloud Build выполнит следующие действия:
- Загрузите свой исходный код
- Создайте образ Docker.
- Отправьте его в Реестр артефактов.
- Разверните его в Cloud Run.
3. Сохраните URL-адрес бэкэнда.
👉💻 После развертывания сохраните URL-адрес бэкэнда:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Обновите URL-адрес общего доступа в административной панели.
Серверная часть генерирует QR-коды, чтобы пользователи могли скачивать свои видео. Для этого ей необходимо знать свой собственный публичный URL-адрес.
👉💻 Обновите конфигурацию бэкэнда, указав собственный URL-адрес:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Проверьте бэкэнд.
👉💻 Проверьте конечную точку здоровья:
curl $BACKEND_URL/api/health
Ожидаемый результат:
{"status":"ok"}
👉💻 Проверьте статус очереди:
curl $BACKEND_URL/api/queue/status
Ожидаемый результат:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Разверните фронтенд
1. Разберитесь с Dockerfile для фронтенда.
Фронтенд использует многоэтапную сборку — сначала собирается приложение React, а затем оно запускается с помощью Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Развертывание в Cloud Run
👉💻 Сначала запишите URL-адрес бэкэнда в файл .env , чтобы Vite мог включить его в процесс сборки:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Теперь разверните фронтенд:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Это займет примерно 2-3 минуты.
3. Получите URL-адрес внешнего интерфейса.
👉💻 Получите и откройте URL-адрес интерфейса:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Откройте URL-адрес в браузере — вы должны увидеть интерфейс киоска Gemini Motion Lab!
8. 🎮 [НЕОБЯЗАТЕЛЬНО] Попробуйте демо-версию
1. Зафиксируйте движение.
- Откройте URL-адрес сайта в своем браузере (желательно в Chrome для наилучшей поддержки камеры).
- Нажмите кнопку «Старт» , чтобы начать запись.
- Потанцуйте или подвигайтесь в течение примерно 5 секунд — лучше всего подойдут широкие движения руками и динамичные позы.
- Запись автоматически остановится и загрузится.
2. Следите за развитием конвейера ИИ.
После загрузки вы увидите, как конвейер обработки данных работает в режиме реального времени:
Фаза | Что происходит | Продолжительность |
Анализ... | Gemini Flash анализирует ваше видео на предмет наличия движений. | ~5-10 секунд |
Создание аватара... | Nano Banana создает стилизованный аватар на основе вашего лучшего телосложения. | ~8-12 секунд |
Создание видео... | Veo 3.1 генерирует видео с использованием ИИ на основе аватара и подсказки движения. | ~60-120 секунд |
Сочинение... | ffmpeg обрезает файлы и создает сравнение «бок о бок». | ~5-10 секунд |
3. Поделитесь своим творением
После завершения работы конвейера:
- На экране киоска появляется QR-код.
- Отсканируйте QR-код с помощью телефона.
- Вы увидите оптимизированную для мобильных устройств страницу для обмена созданным вами видео.
4. Проверьте журналы бэкэнда.
👉💻 Посмотрите, что происходило за кулисами:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Вы увидите строки логов, отслеживающие работу конвейера:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Мониторинг очереди
👉💻 Проверьте, сколько заданий выполняется:
curl $BACKEND_URL/api/queue/status
Если одновременно активны 3 сессии, в ответе будет показано следующее:
{"active_jobs":3,"max_jobs":3,"available":false}
Новым пользователям будет предложено подождать, пока не освободится место.
9. 🎉 Заключение
Что вы построили
✅ Анализ движения с помощью ИИ — Gemini Flash анализирует видео на предмет движения, темпа и стиля.
✅ Создание аватаров — Nano Banana создает стилизованные аватары из видеокадров
✅ Создание видео с помощью ИИ — Veo 3.1 генерирует новые видеоролики, соответствующие движениям пользователя.
✅ Асинхронный конвейер — фоновая обработка с управлением очередью (максимум 3 одновременных процесса)
✅ Композиция «бок о бок» — видеокомпозитинг на основе ffmpeg
✅ Развертывание в облаке — бессерверная архитектура, автоматическое масштабирование, отсутствие необходимости в управлении серверами.
Основные понятия, которые вы изучили
- Gemini Multimodal — отправка видео в качестве входных данных и получение структурированного JSON-анализа.
- Nano Banana (Gemini Image Generation) — Использование эталонных изображений и стилистических подсказок для создания аватаров.
- Veo 3.1 — Асинхронная генерация видео с использованием эталонных ресурсов и текстовых подсказок.
- Cloud Run — развертывание контейнеров с переменными среды и автоматическим масштабированием.
- Шаблон асинхронного конвейера — запускайте фоновые задачи и забудьте о них с помощью
asyncio.Taskдля длительных операций ИИ. - Управление очередями — ограничение количества одновременно выполняемых задач ИИ для контроля затрат и квот API.
Краткий обзор архитектуры
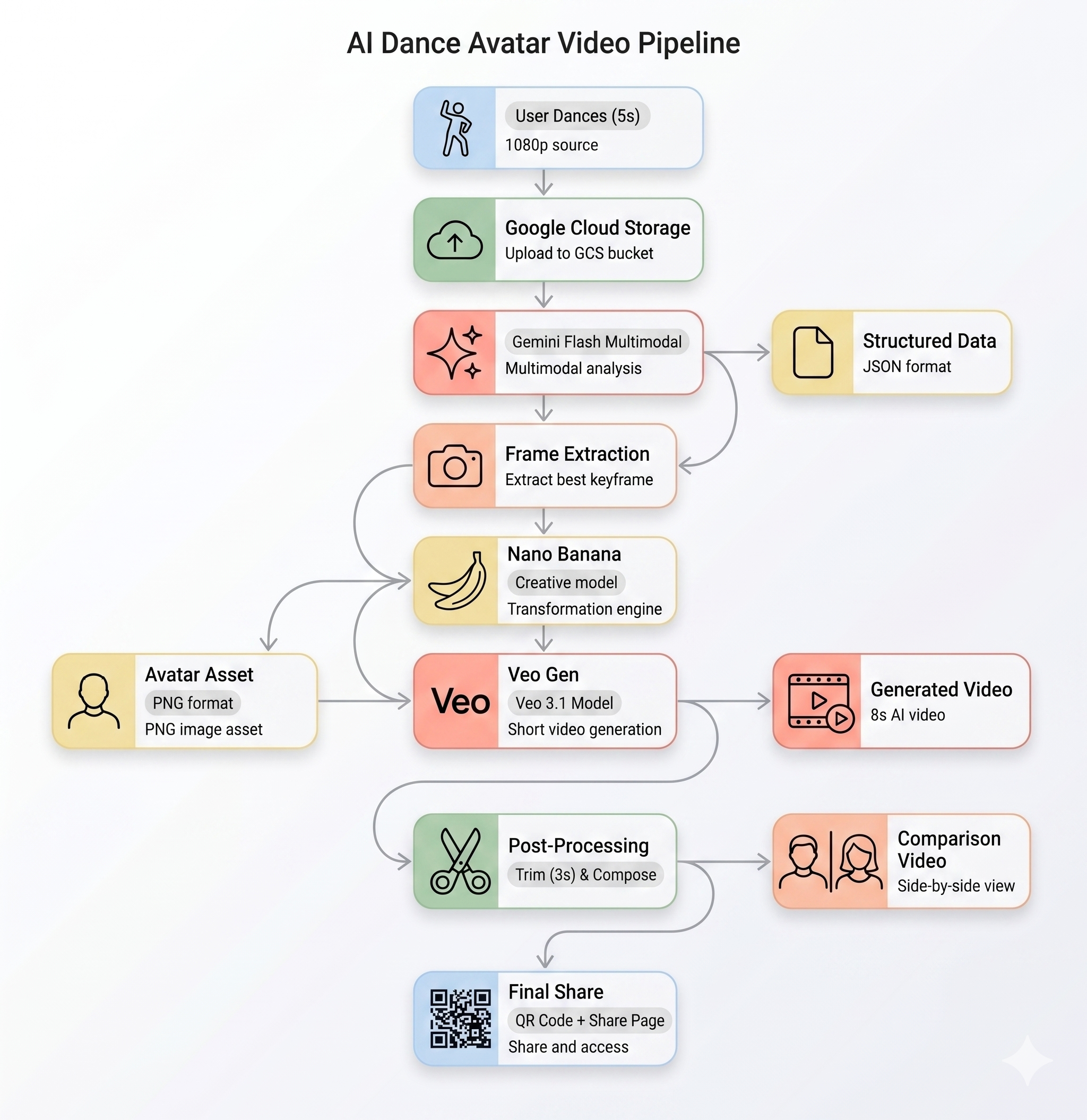
Что дальше?
- Добавить больше стилей аватара — отредактируйте файл
backend/app/prompts/avatar_generation.py - Настройка подсказок Veo — отредактируйте
backend/app/prompts/video_generation.py - Запуск локально в режиме имитации — установите
MOCK_AI=trueв.envдля разработки без вызовов API. - Масштабирование для событий — увеличьте значения
--max-instancesиMAX_CONCURRENT_JOBS