
1. บทนำ
สิ่งที่คุณจะสร้าง
Gemini Motion Lab เป็นประสบการณ์การใช้งานคีออสแบบเรียลไทม์ที่ทำงานด้วยระบบ AI ผู้ใช้บันทึกคลิปการเต้นหรือการเคลื่อนไหวสั้นๆ แล้วระบบจะทำสิ่งต่อไปนี้
- วิเคราะห์การเคลื่อนไหวโดยใช้ Gemini (ส่วนของร่างกาย ระยะ เทมโป พลังงาน)
- สร้างรูปโปรไฟล์ที่มีสไตล์โดยใช้ Nano Banana (รูปภาพ Gemini Flash)
- สร้างวิดีโอ AI โดยใช้ Veo ที่สร้างการเคลื่อนไหวใหม่ด้วยอวาตาร์
- เรียบเรียงวิดีโอแบบเทียบข้าง (ต้นฉบับ + AI สร้างขึ้น)
- แชร์ผลลัพธ์ผ่านคิวอาร์โค้ดในหน้าเว็บที่เพิ่มประสิทธิภาพสำหรับมือถือ
เมื่อสิ้นสุด Codelab นี้ คุณจะมีการติดตั้งใช้งานการสาธิตแบบเต็มใน Google Cloud Run และเข้าใจไปป์ไลน์ AI ที่ขับเคลื่อนการสาธิต
ภาพรวมสถาปัตยกรรม
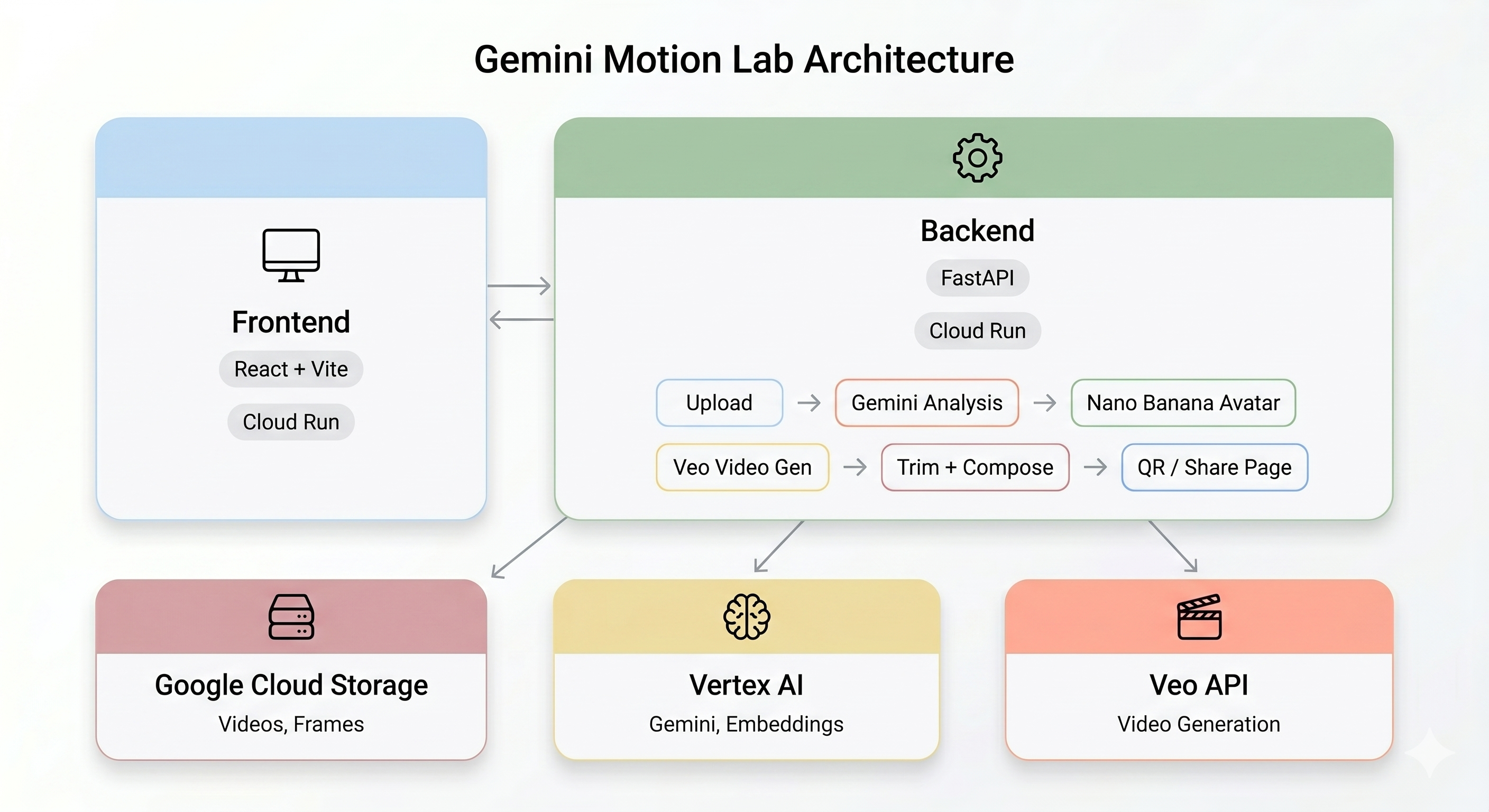
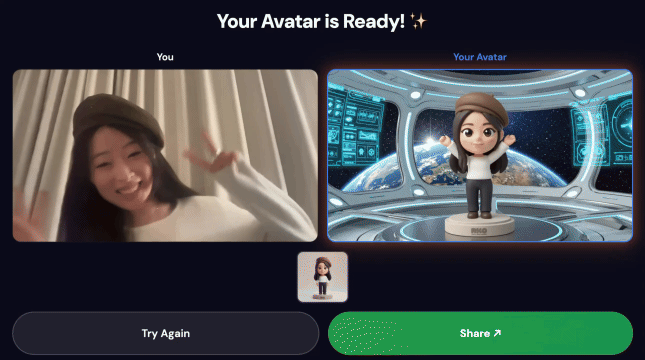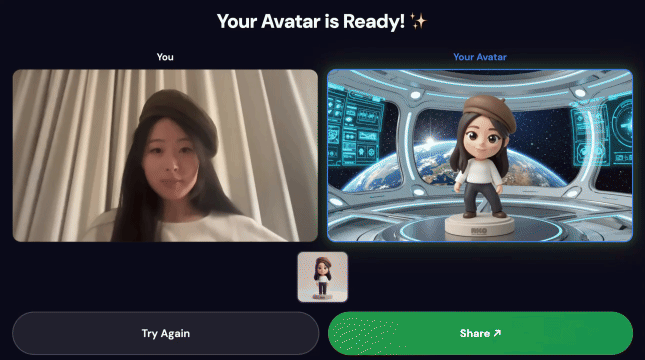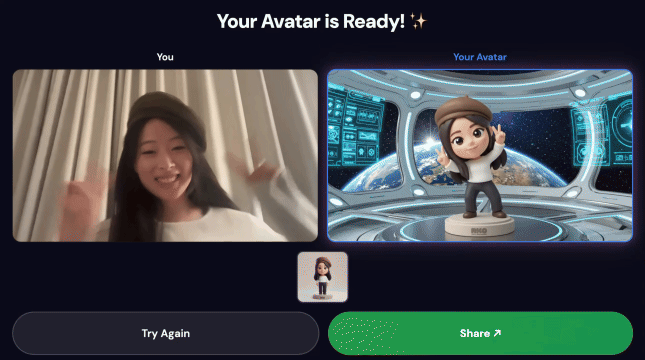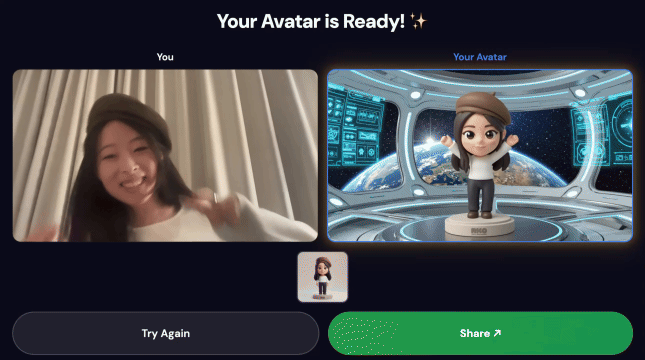
การสาธิตขั้นสุดท้าย
เทคโนโลยีหลัก
ส่วนประกอบ | เทคโนโลยี | วัตถุประสงค์ |
การวิเคราะห์การเคลื่อนไหว | Gemini Flash | วิเคราะห์วิดีโอเพื่อดูการเคลื่อนไหวของร่างกาย ระยะ และสไตล์ |
การสร้างอวาตาร์ | รูปภาพ Gemini Flash (Nano Banana) | สร้างอวาตาร์ขนาด 1024x1024 ที่ปรับแต่งสไตล์จากคีย์เฟรม |
การสร้างวิดีโอ | Veo 3.1 | สร้างวิดีโอ AI จากพรอมต์อวาตาร์ + การเคลื่อนไหว |
แบ็กเอนด์ | FastAPI + Python 3.11 | เซิร์ฟเวอร์ API ที่มีการจัดการไปป์ไลน์แบบไม่พร้อมกัน |
ฟรอนท์เอนด์ | React + Vite + TypeScript | UI ของคีออสก์ที่มีการบันทึกกล้องและสถานะแบบเรียลไทม์ |
โฮสติ้ง | Cloud Run | การติดตั้งใช้งานคอนเทนเนอร์แบบ Serverless |
พื้นที่เก็บข้อมูล | Google Cloud Storage | การอัปโหลดวิดีโอ เฟรม เอาต์พุตที่ตัดและเรียบเรียง |
2. 📦 โคลนที่เก็บ
1. เปิดเครื่องมือแก้ไข Cloud Shell
👉 เปิด Cloud Shell Editor ในเบราว์เซอร์
หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้ทำดังนี้
- คลิกดู
- คลิก Terminal
2. โคลนโค้ด
👉💻 ในเทอร์มินัล ให้โคลนที่เก็บโดยใช้คำสั่งต่อไปนี้
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. สำรวจโครงสร้างโปรเจ็กต์
ดูเลย์เอาต์ของที่เก็บอย่างรวดเร็ว
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ อ้างสิทธิ์เครดิตและสร้างโปรเจ็กต์ GCP
ส่วนที่ 1: รับเครดิตการเรียกเก็บเงิน
👉 เคลมเครดิตบัญชีสำหรับการเรียกเก็บเงินโดยใช้บัญชี Gmail
ส่วนที่ 2: สร้างโปรเจ็กต์ใหม่
👉💻 ในเทอร์มินัล ให้ตั้งค่าสคริปต์ init ให้เรียกใช้ได้ แล้วดำเนินการ
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
สคริปต์ init.sh จะทำสิ่งต่อไปนี้
- สร้างโปรเจ็กต์ GCP ใหม่โดยมีคำนำหน้าเป็น
gemini-motion-lab - บันทึกรหัสโปรเจ็กต์ไปยัง
~/project_id.txt - ติดตั้งการอ้างอิงการเรียกเก็บเงินและลิงก์บัญชีสำหรับการเรียกเก็บเงินโดยอัตโนมัติ
ส่วนที่ 3: กำหนดค่าโปรเจ็กต์และเปิดใช้ API
👉💻 ตั้งรหัสโปรเจ็กต์ในเทอร์มินัลโดยทำดังนี้
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 เปิดใช้ Google Cloud API ที่จำเป็นสำหรับโปรเจ็กต์นี้ (ใช้เวลาประมาณ 1-2 นาที)
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [อ่านอย่างเดียว] ทำความเข้าใจสถาปัตยกรรม
ส่วนนี้จะอธิบายวิธีการทำงานของไปป์ไลน์ AI แบบครบวงจร ไม่ต้องดำเนินการใดๆ เพียงอ่านเพื่อทำความเข้าใจระบบก่อนที่จะนำไปใช้
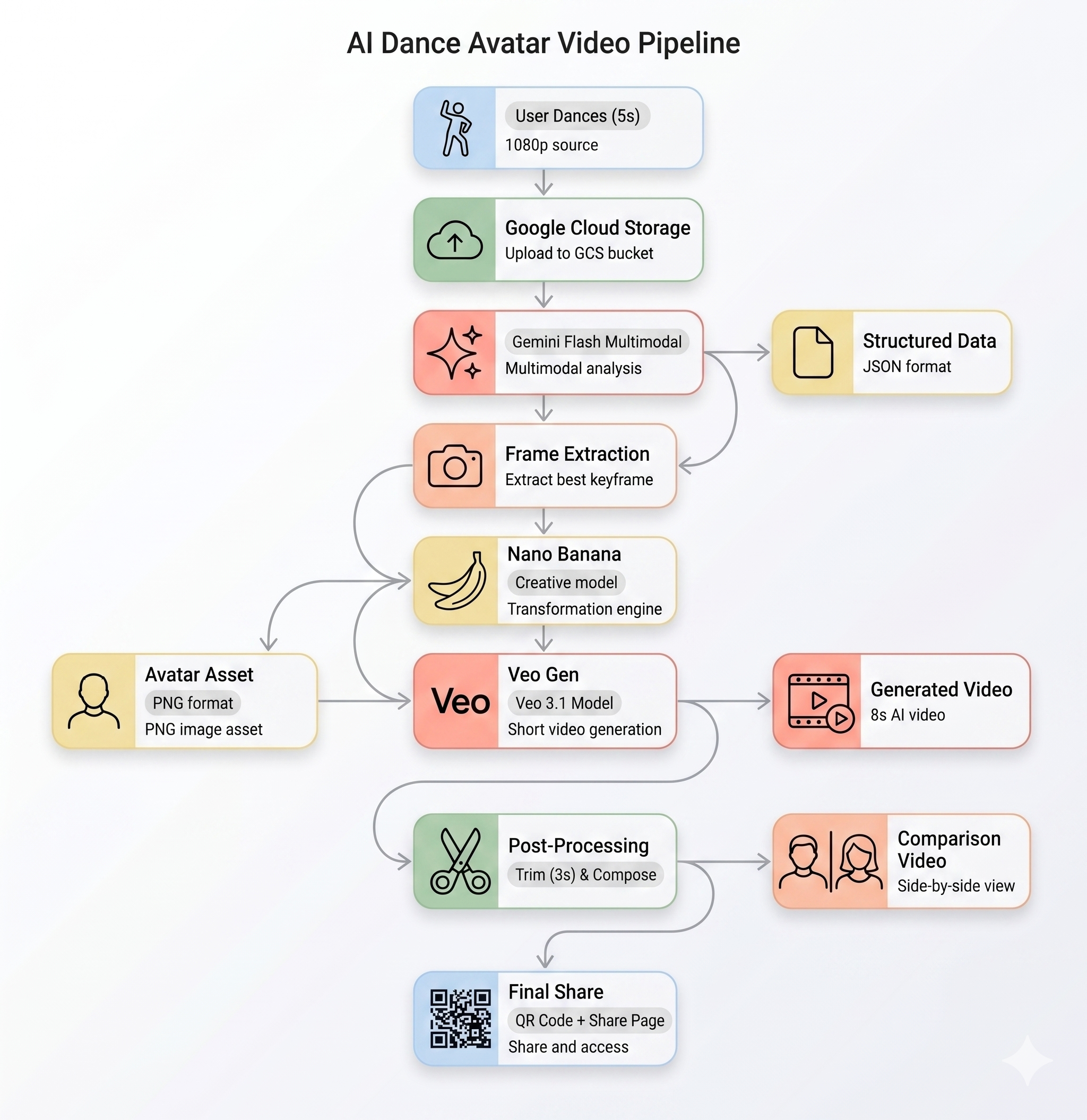
ไปป์ไลน์ AI
เมื่อผู้ใช้บันทึกวิดีโอการเคลื่อนไหวที่คีออสก์ ระบบจะเรียกใช้ 5 ขั้นตอนตามลำดับ ดังนี้

ขั้นตอนที่ 1: อัปโหลดวิดีโอ
ส่วนหน้าจะบันทึกคลิป WebM ความยาว 5 วินาทีจากกล้องของผู้ใช้และอัปโหลดไปยัง Google Cloud Storage ผ่านปลายทาง /api/upload ของแบ็กเอนด์
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
ระยะที่ 2: การวิเคราะห์การเคลื่อนไหวของ Gemini
แบ็กเอนด์จะส่งวิดีโอที่อัปโหลดไปยัง Gemini Flash (gemini-3-flash-preview) เพื่อทำการวิเคราะห์แบบมีโครงสร้าง
วิธีการทำงาน (backend/app/services/gemini_service.py)
บริการนี้ใช้ client.models.generate_content() ของ Vertex AI SDK โดยมีวิดีโอเป็นอินพุต Part.from_uri และพรอมต์ที่มีโครงสร้าง response_mime_type="application/json" ช่วยให้มั่นใจได้ว่า Gemini จะแสดง JSON ที่แยกวิเคราะห์ได้ นอกจากนี้ โมเดลยังใช้ ThinkingConfig(thinking_budget=1024) เพื่อให้เหตุผลเกี่ยวกับระยะการเคลื่อนไหวได้ดียิ่งขึ้น
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
ขั้นตอนที่ 3: การสร้างอวตาร Nano Banana
รูปภาพ Gemini Flash (gemini-3.1-flash-image-preview) จะสร้างอวตารที่มีสไตล์ขนาด 1024x1024 โดยใช้เฟรมที่ดีที่สุดที่ดึงมาจากวิดีโอ
วิธีการทำงาน (backend/app/services/nano_banana_service.py)
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
ระบบจะอัปโหลด PNG ของอวาตาร์ที่สร้างขึ้นไปยัง GCS และส่งไปยังขั้นตอนถัดไป
ขั้นตอนที่ 4: การสร้างวิดีโอด้วย Veo
ระบบจะใช้รูปภาพอวตารเป็นชิ้นงานอ้างอิงสำหรับ Veo 3.1 (veo-3.1-fast-generate-001) เพื่อสร้างวิดีโอ AI ความยาว 8 วินาที
วิธีการทำงาน (backend/app/services/veo_service.py)
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
การสร้าง Veo เป็นแบบอะซิงโครนัส ซึ่งจะแสดงรหัสการดำเนินการทันที แบ็กเอนด์จะสำรวจการดำเนินการจนกว่าจะเสร็จสมบูรณ์ (สูงสุด 10 นาที)
ขั้นตอนที่ 5: ไปป์ไลน์การประมวลผลภายหลัง
เมื่อ Veo ทำงานเสร็จแล้ว ไปป์ไลน์เบื้องหลัง (backend/app/services/pipeline.py) จะทำงานโดยอัตโนมัติ
- ตัดเอาต์พุต Veo 8 วินาทีให้เหลือ 3 วินาที
- เรียบเรียงวิดีโอแบบเทียบข้าง (วิดีโอที่บันทึกต้นฉบับอยู่ทางซ้าย วิดีโอ AI อยู่ทางขวา)
- อัปโหลดวิดีโอที่ประกอบแล้วไปยัง GCS
- ปล่อยช่องคิว
ไปป์ไลน์นี้จะทำงานเป็นasyncio.Taskเบื้องหลังasyncio.Task โดยส่วนหน้าของคีออสก์ไม่ต้องรอ
ระบบคิว
เนื่องจากการสร้าง Veo ต้องใช้ทรัพยากรจำนวนมาก ระบบจึงบังคับใช้งานที่เกิดขึ้นพร้อมกันสูงสุด 3 งาน ดังนี้
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
ส่วนหน้าจะตรวจสอบ GET /api/queue/status ก่อนอนุญาตให้ผู้ใช้ใหม่เริ่มเซสชัน เมื่อไปป์ไลน์เสร็จสมบูรณ์และเรียกใช้ complete(video_id) ช่องจะเปิดให้ผู้ใช้รายถัดไป
Cloud Run - คอนเทนเนอร์แบบ Serverless
ทั้งแบ็กเอนด์และฟรอนต์เอนด์ได้รับการทำให้ใช้งานได้เป็นบริการ Cloud Run ดังนี้
บริการ | วัตถุประสงค์ | การกำหนดค่าคีย์ |
แบ็กเอนด์ | เซิร์ฟเวอร์ API ของ FastAPI | หน่วยความจำ 2 GiB (สำหรับการประมวลผลวิดีโอผ่าน ffmpeg) |
ฟรอนท์เอนด์ | แอป React แบบคงที่ที่ Nginx แสดง | หน่วยความจำเริ่มต้น |
5. ⚙️ เรียกใช้สคริปต์การตั้งค่า
1. เรียกใช้การตั้งค่าอัตโนมัติ
setup.sh สคริปต์จะสร้างทรัพยากรระบบคลาวด์ที่จำเป็นและสร้างไฟล์ .env
👉💻 ทำให้สคริปต์เรียกใช้งานได้และดำเนินการ
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. มอบบทบาท IAM
ตอนนี้ให้สิทธิ์ที่จำเป็นแก่บัญชีบริการ
👉💻 เรียกใช้คำสั่งต่อไปนี้เพื่อตั้งค่ารหัสโปรเจ็กต์และให้สิทธิ์ทั้ง 3 บทบาท
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. ยืนยันไฟล์ .env
👉💻 ตรวจสอบไฟล์ .env ที่สร้างขึ้น
cat .env
คุณควรเห็นข้อมูลต่อไปนี้
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 ทำให้แบ็กเอนด์ใช้งานได้
1. ทำความเข้าใจ Dockerfile ของแบ็กเอนด์
มาดูกันว่าคอนเทนเนอร์มีลักษณะอย่างไรก่อนที่จะติดตั้งใช้งาน
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. ทำให้ใช้งานได้กับ Cloud Run
👉💻 โหลดตัวแปรสภาพแวดล้อมและติดตั้งใช้งาน
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
การดำเนินการนี้จะใช้เวลาประมาณ 3-5 นาที Cloud Build จะทำสิ่งต่อไปนี้
- อัปโหลดซอร์สโค้ด
- สร้างอิมเมจ Docker
- พุชไปยัง Artifact Registry
- ทำให้ใช้งานได้กับ Cloud Run
3. บันทึก URL ของแบ็กเอนด์
👉💻 เมื่อติดตั้งใช้งานแล้ว ให้บันทึก URL ของแบ็กเอนด์
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. อัปเดต URL การแชร์แบ็กเอนด์
แบ็กเอนด์จะสร้างคิวอาร์โค้ดเพื่อให้ผู้ใช้ดาวน์โหลดวิดีโอได้ โดยจะต้องทราบ URL สาธารณะของตัวเองเพื่อดำเนินการนี้
👉💻 อัปเดตการกำหนดค่าแบ็กเอนด์ด้วย URL ของตัวเอง
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. ยืนยันแบ็กเอนด์
👉💻 ทดสอบปลายทางการตรวจสอบประสิทธิภาพการทำงาน
curl $BACKEND_URL/api/health
ผลลัพธ์ที่คาดไว้:
{"status":"ok"}
👉💻 ตรวจสอบสถานะคิว
curl $BACKEND_URL/api/queue/status
ผลลัพธ์ที่คาดไว้:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 ทำให้ฟรอนท์เอนด์ใช้งานได้
1. ทำความเข้าใจ Dockerfile ของฟรอนท์เอนด์
ส่วนหน้าใช้การสร้างหลายขั้นตอน โดยสร้างแอป React ก่อน แล้วจึงแสดงด้วย Nginx
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. ทำให้ใช้งานได้กับ Cloud Run
👉💻 ก่อนอื่นให้เขียน URL ของแบ็กเอนด์ลงในไฟล์ .env เพื่อให้ Vite สามารถรวมไว้ในเวลาบิลด์ได้
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 ตอนนี้ให้ทำให้ฟรอนท์เอนด์ใช้งานได้โดยทำดังนี้
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
โดยจะใช้เวลาประมาณ 2-3 นาที
3. รับ URL ของฟรอนท์เอนด์
👉💻 ดึงและเปิด URL ของส่วนหน้า
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 เปิด URL ในเบราว์เซอร์ คุณควรเห็นอินเทอร์เฟซของคีออสค์ Gemini Motion Lab
8. 🎮 [ไม่บังคับ] เล่นเดโม
1. บันทึกการเคลื่อนไหว
- เปิด URL ของส่วนหน้าในเบราว์เซอร์ (ควรใช้ Chrome เพื่อการรองรับกล้องที่ดีที่สุด)
- คลิกเริ่มเพื่อเริ่มบันทึก
- เต้นหรือเคลื่อนไหวประมาณ 5 วินาที โดยการเคลื่อนไหวแขนขนาดใหญ่และท่าทางไดนามิกจะได้ผลดีที่สุด
- การบันทึกจะหยุดและอัปโหลดโดยอัตโนมัติ
2. ดู AI Pipeline
หลังจากอัปโหลดแล้ว คุณจะเห็นไปป์ไลน์ทำงานแบบเรียลไทม์ดังนี้
ระยะ | สิ่งที่จะเกิดขึ้น | ระยะเวลา |
กำลังวิเคราะห์... | Gemini Flash จะวิเคราะห์วิดีโอเพื่อหารูปแบบการเคลื่อนไหว | ~5-10 วินาที |
กำลังสร้างอวาตาร์... | Nano Banana สร้างอวตารที่มีสไตล์จากเฟรมที่ดีที่สุดของคุณ | ~8-12 วินาที |
กำลังสร้างวิดีโอ... | Veo 3.1 สร้างวิดีโอ AI จากพรอมต์อวาตาร์ + การเคลื่อนไหว | ~60-120 วินาที |
กำลังเขียน... | ffmpeg จะตัดและสร้างการเปรียบเทียบข้อมูลคู่กัน | ~5-10 วินาที |
3. แชร์ผลงานของคุณ
เมื่อไปป์ไลน์เสร็จสมบูรณ์แล้ว
- คิวอาร์โค้ดจะปรากฏบนหน้าจอคีออส
- สแกนคิวอาร์โค้ดด้วยโทรศัพท์
- คุณจะเห็นหน้าแชร์ที่เพิ่มประสิทธิภาพสำหรับมือถือซึ่งมีวิดีโอที่คุณสร้าง
4. ตรวจสอบบันทึกของแบ็กเอนด์
👉💻 ดูสิ่งที่เกิดขึ้นเบื้องหลัง
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
คุณจะเห็นบรรทัดบันทึกที่ติดตามไปป์ไลน์ ดังนี้
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. ตรวจสอบคิว
👉💻 ตรวจสอบจำนวนงานที่กำลังทำงานอยู่
curl $BACKEND_URL/api/queue/status
หากมีเซสชันที่ใช้งานอยู่ 3 เซสชันพร้อมกัน คำตอบจะแสดงดังนี้
{"active_jobs":3,"max_jobs":3,"available":false}
ระบบจะขอให้ผู้ใช้ใหม่รอจนกว่าจะมีที่ว่าง
9. 🎉 บทสรุป
สิ่งที่คุณสร้าง
✅ การวิเคราะห์การเคลื่อนไหวด้วย AI — Gemini Flash จะวิเคราะห์วิดีโอเพื่อดูการเคลื่อนไหว จังหวะ และสไตล์
✅ การสร้างอวตาร - Nano Banana สร้างอวตารที่มีสไตล์จากเฟรมวิดีโอ
✅ การสร้างวิดีโอ AI - Veo 3.1 สร้างวิดีโอใหม่ที่ตรงกับการเคลื่อนไหวของผู้ใช้
✅ ไปป์ไลน์แบบไม่พร้อมกัน - การประมวลผลเบื้องหลังที่มีการจัดการคิว (พร้อมกันได้สูงสุด 3 รายการ)
✅ การจัดองค์ประกอบแบบเคียงข้างกัน - การจัดองค์ประกอบวิดีโอที่ขับเคลื่อนโดย ffmpeg
✅ การทำให้ Cloud Run ใช้งานได้ - แบบ Serverless, ปรับขนาดอัตโนมัติ, ไม่ต้องจัดการเซิร์ฟเวอร์
แนวคิดสำคัญที่คุณได้เรียนรู้
- Gemini Multimodal - การส่งวิดีโอเป็นอินพุตและรับการวิเคราะห์ JSON ที่มีโครงสร้าง
- Nano Banana (การสร้างรูปภาพของ Gemini) - ใช้รูปภาพอ้างอิง + พรอมต์สไตล์เพื่อสร้างอวตาร
- Veo 3.1 - การสร้างวิดีโอแบบอะซิงโครนัสพร้อมชิ้นงานอ้างอิงและพรอมต์ข้อความ
- Cloud Run - การติดตั้งใช้งานคอนเทนเนอร์ที่มีตัวแปรสภาพแวดล้อมและการปรับขนาดอัตโนมัติ
- รูปแบบไปป์ไลน์แบบไม่พร้อมกัน - งานที่ทำอยู่เบื้องหลังแบบส่งแล้วไม่ต้องรอรับการตอบกลับด้วย
asyncio.Taskสำหรับการดำเนินการ AI ที่ใช้เวลานาน - การจัดการคิว - การจำกัดอัตราการทำงานของ AI พร้อมกันเพื่อควบคุมต้นทุนและโควต้า API
สรุปสถาปัตยกรรม
ขั้นตอนต่อไปคือ
- เพิ่มสไตล์อวตาร - แก้ไข
backend/app/prompts/avatar_generation.py - ปรับแต่งพรอมต์ของ Veo - แก้ไข
backend/app/prompts/video_generation.py - เรียกใช้ในเครื่องในโหมดจำลอง - ตั้งค่า
MOCK_AI=trueใน.envเพื่อการพัฒนาโดยไม่ต้องเรียก API - ปรับขนาดสำหรับกิจกรรม - เพิ่ม
--max-instancesและMAX_CONCURRENT_JOBS