
1. Giới thiệu
Sản phẩm bạn sẽ tạo ra
Gemini Motion Lab là một trải nghiệm trực tiếp trên ki-ốt dựa trên AI. Người dùng ghi lại một đoạn video ngắn về điệu nhảy hoặc chuyển động, sau đó hệ thống sẽ:
- Phân tích chuyển động bằng Gemini (bộ phận cơ thể, giai đoạn, nhịp độ, năng lượng)
- Tạo một hình ảnh đại diện cách điệu bằng Nano Banana (Hình ảnh Gemini Flash)
- Tạo video AI bằng Veo để tái tạo chuyển động bằng hình đại diện
- Tạo video song song (video gốc + video do AI tạo)
- Chia sẻ kết quả thông qua mã QR trên một trang được tối ưu hoá cho thiết bị di động
Khi kết thúc lớp học lập trình này, bạn sẽ triển khai bản minh hoạ đầy đủ lên Google Cloud Run và hiểu rõ quy trình AI hỗ trợ bản minh hoạ đó.
Tổng quan về Cấu trúc (Architecture)
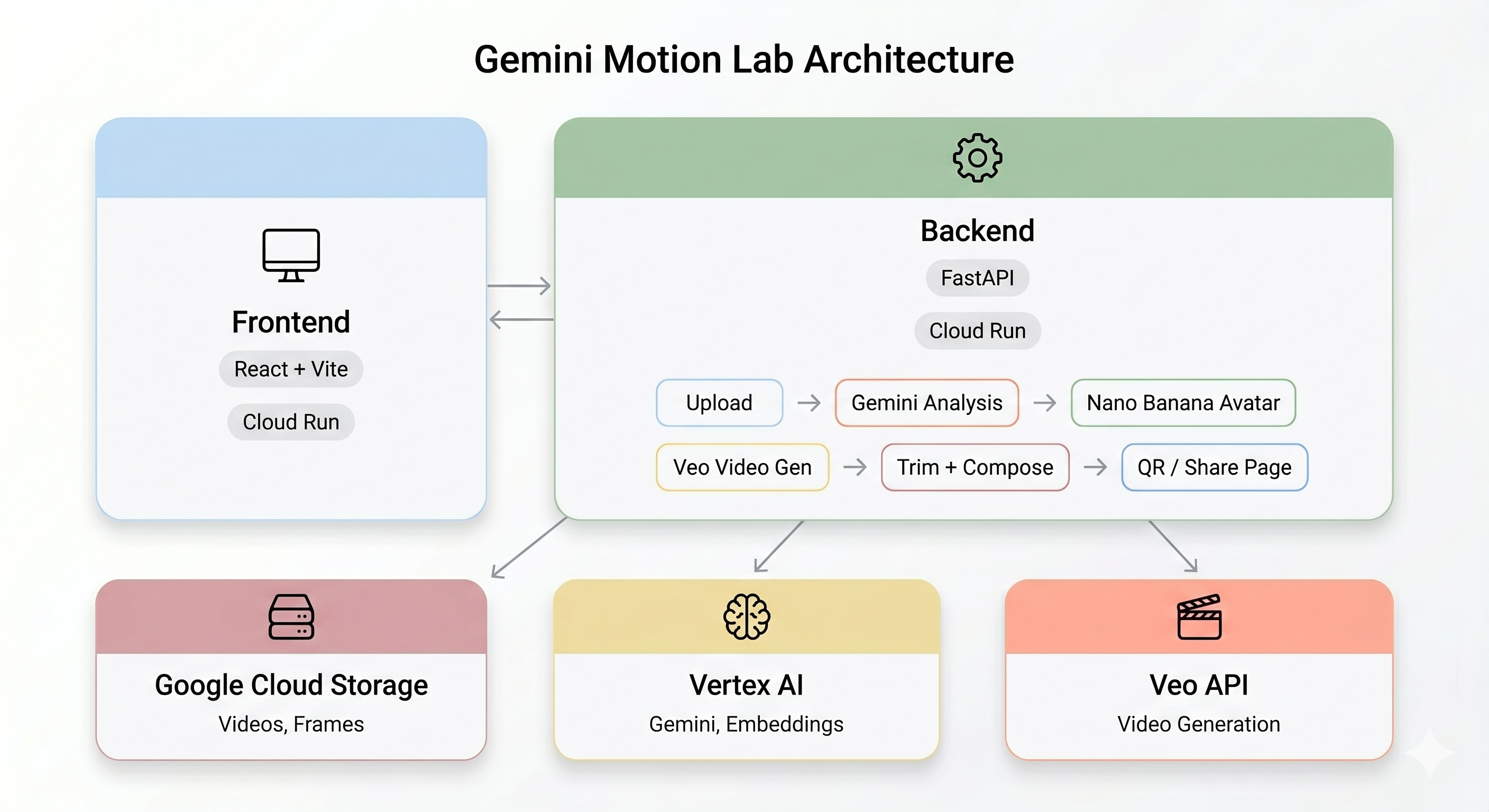
Bản minh hoạ cuối cùng:
Công nghệ cốt lõi
Thành phần | Công nghệ | Mục đích |
Phân tích chuyển động | Gemini Flash | Phân tích video về chuyển động cơ thể, các giai đoạn và phong cách |
Tạo hình đại diện | Hình ảnh Gemini Flash (Nano Banana) | Tạo hình đại diện cách điệu có kích thước 1024 x 1024 từ một khung hình chính |
Tạo video | Veo 3.1 | Tạo video AI từ hình đại diện và câu lệnh chuyển động |
Phần phụ trợ | FastAPI + Python 3.11 | Máy chủ API có tính năng điều phối quy trình không đồng bộ |
Giao diện người dùng | React + Vite + TypeScript | Giao diện người dùng của kiosk có tính năng ghi hình bằng camera và trạng thái trực tiếp |
Lưu trữ | Cloud Run | Triển khai vùng chứa không máy chủ |
Bộ nhớ | Google Cloud Storage | Video tải lên, khung hình, đầu ra đã được cắt và kết hợp |
2. 📦 Sao chép kho lưu trữ
1. Mở Trình chỉnh sửa Cloud Shell
👉 Mở Cloud Shell Editor trong trình duyệt.
Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
2. Sao chép mã
👉💻 Trong cửa sổ dòng lệnh, hãy sao chép kho lưu trữ:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. Khám phá Cấu trúc dự án
Xem nhanh bố cục kho lưu trữ:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ Yêu cầu cấp tín dụng và tạo dự án GCP
Phần 1: Nhận khoản tín dụng thanh toán
👉 Yêu cầu cấp tín dụng cho tài khoản thanh toán bằng tài khoản Gmail của bạn.
Phần 2: Tạo dự án mới
👉💻 Trong dòng lệnh, hãy thực thi tập lệnh init và kích hoạt tập lệnh đó:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
Tập lệnh init.sh sẽ:
- Tạo một dự án GCP mới có tiền tố
gemini-motion-lab - Lưu mã dự án vào
~/project_id.txt - Cài đặt các phần phụ thuộc thanh toán và tự động liên kết tài khoản thanh toán
Phần 3: Định cấu hình dự án và bật API
👉💻 Đặt mã dự án trong thiết bị đầu cuối:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Bật các Cloud APIs của Google cần thiết cho dự án này (việc này mất khoảng 1 đến 2 phút):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [CHỈ ĐỌC] Tìm hiểu về Cấu trúc
Phần này giải thích cách hoạt động của quy trình AI từ đầu đến cuối. Không cần làm gì cả – bạn chỉ cần đọc để hiểu rõ hệ thống trước khi triển khai.
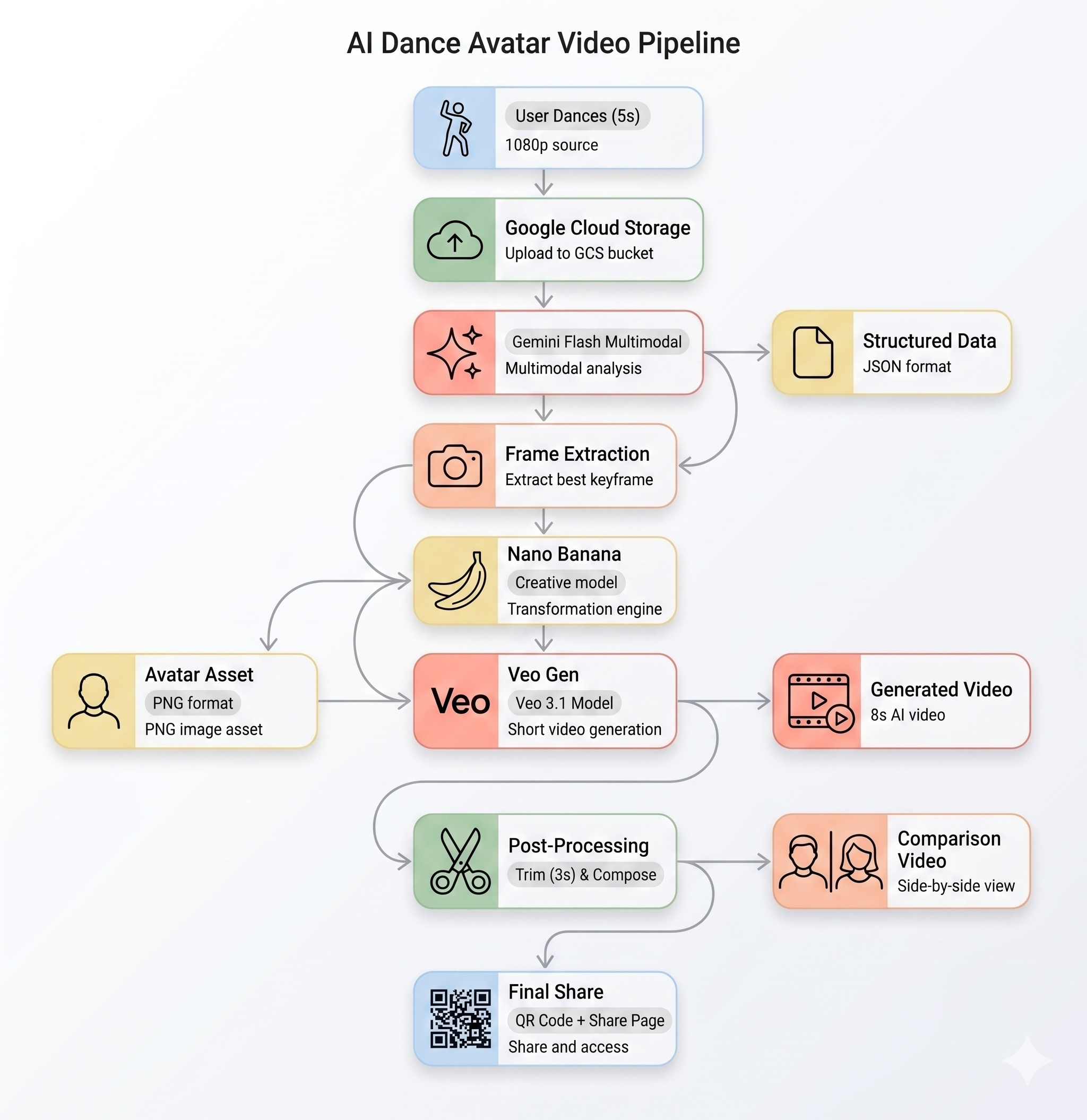
Quy trình AI
Khi người dùng ghi lại một đoạn video chuyển động tại kiosk, 5 giai đoạn sẽ diễn ra theo trình tự:

Giai đoạn 1: Tải video lên
Giao diện người dùng ghi lại một đoạn video WebM dài 5 giây từ camera của người dùng và tải đoạn video đó lên Google Cloud Storage thông qua điểm cuối /api/upload của phần phụ trợ.
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
Giai đoạn 2: Phân tích chuyển động bằng Gemini
Phần phụ trợ sẽ gửi video đã tải lên đến Gemini Flash (gemini-3-flash-preview) để phân tích có cấu trúc.
Cách hoạt động (backend/app/services/gemini_service.py):
Dịch vụ này sử dụng client.models.generate_content() của Vertex AI SDK với video làm đầu vào Part.from_uri và một câu lệnh có cấu trúc. response_mime_type="application/json" đảm bảo Gemini trả về JSON có thể phân tích cú pháp. Mô hình này cũng sử dụng ThinkingConfig(thinking_budget=1024) để suy luận tốt hơn về các giai đoạn chuyển động.
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
Giai đoạn 3: Tạo hình đại diện bằng Nano Banana
Bằng cách sử dụng khung hình đẹp nhất được trích xuất từ video, Gemini Flash Image (gemini-3.1-flash-image-preview) sẽ tạo ra một hình đại diện cách điệu có kích thước 1024×1024.
Cách hoạt động (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
PNG của ảnh đại diện được tạo sẽ được tải lên GCS và chuyển sang giai đoạn tiếp theo.
Giai đoạn 4: Tạo video bằng Veo
Hình ảnh đại diện được dùng làm tài sản tham khảo cho Veo 3.1 (veo-3.1-fast-generate-001) để tạo video AI dài 8 giây.
Cách hoạt động (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Veo tạo video không đồng bộ – tức là trả về mã nhận dạng thao tác ngay lập tức. Phần phụ trợ sẽ thăm dò hoạt động cho đến khi hoàn tất (tối đa 10 phút).
Giai đoạn 5: Quy trình xử lý hậu kỳ
Sau khi Veo hoàn tất, quy trình xử lý ở chế độ nền (backend/app/services/pipeline.py) sẽ tự động chạy:
- Cắt đầu ra của Veo (dài 8 giây) thành 3 giây
- Tạo video cạnh nhau (bản ghi gốc ở bên trái, video do AI tạo ở bên phải)
- Tải video đã ghép lên GCS
- Hủy đặt trước vị trí trong hàng đợi
Quy trình này chạy ở chế độ nền asyncio.Task – giao diện người dùng của kiosk không cần phải chờ.
Hệ thống hàng đợi
Vì việc tạo video bằng Veo tốn nhiều tài nguyên, nên hệ thống áp dụng tối đa 3 lệnh đồng thời:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
Giao diện người dùng kiểm tra GET /api/queue/status trước khi cho phép người dùng mới bắt đầu một phiên. Khi một quy trình hoàn tất và gọi complete(video_id), vị trí sẽ mở ra cho người dùng tiếp theo.
Cloud Run – Vùng chứa không máy chủ
Cả phần phụ trợ và giao diện người dùng đều được triển khai dưới dạng dịch vụ Cloud Run:
Dịch vụ | Mục đích | Cấu hình khoá |
Phụ trợ | Máy chủ API FastAPI | Bộ nhớ 2 GiB (để xử lý video thông qua ffmpeg) |
Giao diện người dùng | Ứng dụng React tĩnh do Nginx phân phát | Bộ nhớ mặc định |
5. ⚙️ Chạy tập lệnh thiết lập
1. Chạy quy trình Thiết lập tự động
Tập lệnh setup.sh sẽ tạo các tài nguyên đám mây cần thiết và tạo tệp .env.
👉💻 Chạy tập lệnh và kích hoạt tập lệnh:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. Cấp vai trò IAM
Bây giờ, hãy cấp các quyền cần thiết cho tài khoản dịch vụ.
👉💻 Chạy các lệnh sau để đặt mã dự án và cấp cả 3 vai trò:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. Xác minh tệp .env của bạn
👉💻 Kiểm tra tệp .env đã tạo:
cat .env
Bạn sẽ thấy:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 Triển khai phần phụ trợ
1. Tìm hiểu về Dockerfile phụ trợ
Trước khi triển khai, hãy tìm hiểu xem vùng chứa trông như thế nào:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. Triển khai lên Cloud Run
👉💻 Tải các biến môi trường và triển khai:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
Quá trình này mất khoảng 3 đến 5 phút. Cloud Build sẽ:
- Tải mã nguồn lên
- Tạo hình ảnh Docker
- Đẩy đến Artifact Registry
- Triển khai ứng dụng đó lên Cloud Run
3. Lưu URL phụ trợ
👉💻 Sau khi triển khai, hãy lưu URL phụ trợ:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. Cập nhật URL chia sẻ phụ trợ
Hệ thống phụ trợ tạo mã QR để người dùng có thể tải video xuống. Để làm được việc này, ứng dụng cần biết URL công khai của chính nó.
👉💻 Cập nhật cấu hình phụ trợ bằng URL riêng:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. Xác minh phần phụ trợ
👉💻 Kiểm thử điểm cuối về tình trạng:
curl $BACKEND_URL/api/health
Kết quả đầu ra dự kiến:
{"status":"ok"}
👉💻 Kiểm tra trạng thái hàng đợi:
curl $BACKEND_URL/api/queue/status
Kết quả đầu ra dự kiến:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 Triển khai giao diện người dùng
1. Tìm hiểu về Frontend Dockerfile
Giao diện người dùng sử dụng bản dựng nhiều giai đoạn – trước tiên là tạo ứng dụng React, sau đó phân phát ứng dụng đó bằng Nginx:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. Triển khai lên Cloud Run
👉💻 Trước tiên, hãy ghi URL phụ trợ vào tệp .env để Vite có thể tạo URL đó tại thời gian xây dựng:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 Giờ hãy triển khai giao diện người dùng:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
Quá trình này mất khoảng 2 đến 3 phút.
3. Lấy URL giao diện người dùng
👉💻 Truy xuất và mở URL giao diện người dùng:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 Mở URL trong trình duyệt – bạn sẽ thấy giao diện ki-ốt của Gemini Motion Lab!
8. 🎮 [KHÔNG BẮT BUỘC] Chơi bản minh hoạ
1. Ghi lại chuyển động
- Mở URL giao diện người dùng trong trình duyệt (tốt nhất là Chrome để có khả năng hỗ trợ camera tốt nhất)
- Nhấp vào Bắt đầu để bắt đầu ghi
- Nhảy hoặc di chuyển trong khoảng 5 giây – những động tác tay lớn và tư thế năng động sẽ mang lại hiệu quả tốt nhất
- Quá trình ghi sẽ tự động dừng và tải lên
2. Xem AI Pipeline
Sau khi tải lên, bạn sẽ thấy quy trình chạy theo thời gian thực:
Pha ban đầu | Vấn đề hiện tại | Thời lượng |
Đang phân tích... | Gemini Flash phân tích video của bạn để tìm các mẫu chuyển động | ~5-10 giây |
Đang tạo hình đại diện... | Nano Banana tạo một hình đại diện cách điệu từ khung hình đẹp nhất của bạn | ~8-12 giây |
Đang tạo video... | Veo 3.1 tạo video AI từ hình đại diện và câu lệnh chuyển động | ~60-120 giây |
Đang soạn... | ffmpeg cắt và tạo bản so sánh song song | ~5-10 giây |
3. Chia sẻ tác phẩm của bạn
Sau khi quy trình hoàn tất:
- Một mã QR sẽ xuất hiện trên màn hình ki-ốt
- Quét mã QR bằng điện thoại
- Bạn sẽ thấy một trang chia sẻ được tối ưu hoá cho thiết bị di động có video bạn đã tạo
4. Kiểm tra nhật ký phụ trợ
👉💻 Xem những gì đã diễn ra ở hậu trường:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
Bạn sẽ thấy các dòng nhật ký theo dõi quy trình:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. Theo dõi hàng đợi
👉💻 Kiểm tra số lượng công việc đang chạy:
curl $BACKEND_URL/api/queue/status
Nếu có 3 phiên hoạt động đồng thời, thì phản hồi sẽ cho thấy:
{"active_jobs":3,"max_jobs":3,"available":false}
Người dùng mới sẽ được yêu cầu đợi cho đến khi có một vị trí trống.
9. 🎉 Kết luận
Những gì bạn đã tạo
✅ Phân tích chuyển động bằng AI – Gemini Flash phân tích video về chuyển động, nhịp độ và phong cách
✅ Tạo hình đại diện – Nano Banana tạo hình đại diện cách điệu từ các khung hình trong video
✅ Video AI — Veo 3.1 tạo video mới phù hợp với chuyển động của người dùng
✅ Quy trình không đồng bộ – Xử lý ở chế độ nền bằng tính năng quản lý hàng đợi (tối đa 3 quy trình đồng thời)
✅ Thành phần cạnh nhau – tính năng kết hợp video dựa trên ffmpeg
✅ Triển khai Cloud Run – Không máy chủ, tự động cấp tài nguyên bổ sung, không cần quản lý máy chủ
Các khái niệm chính bạn đã học
- Gemini Multimodal – Gửi video làm dữ liệu đầu vào và nhận được thông tin phân tích JSON có cấu trúc
- Nano Banana (Tính năng tạo ảnh trong Gemini) – Dùng hình ảnh tham khảo và câu lệnh về phong cách để tạo hình đại diện
- Veo 3.1 – Tạo video không đồng bộ bằng tài sản tham chiếu và câu lệnh văn bản
- Cloud Run – Triển khai các vùng chứa có biến môi trường và tính năng tự động cấp tài nguyên bổ sung
- Mô hình quy trình không đồng bộ – Các tác vụ ở chế độ nền theo kiểu "bắn và quên" bằng
asyncio.Taskcho các hoạt động AI diễn ra trong thời gian dài - Quản lý hàng đợi – Giới hạn tốc độ cho các tác vụ AI đồng thời để kiểm soát chi phí và hạn mức API
Architecture Recap
Tiếp theo là gì?
- Thêm các kiểu hình đại diện khác – Chỉnh sửa
backend/app/prompts/avatar_generation.py - Tuỳ chỉnh câu lệnh cho Veo – Chỉnh sửa
backend/app/prompts/video_generation.py - Chạy cục bộ ở chế độ mô phỏng – Đặt
MOCK_AI=truetrong.envđể phát triển mà không cần lệnh gọi API - Mở rộng quy mô cho sự kiện – Tăng
--max-instancesvàMAX_CONCURRENT_JOBS