
1. 简介
构建内容
Gemini Motion Lab 是一项由 AI 赋能的实时信息亭体验。用户录制一段简短的舞蹈或动作视频,然后系统会:
- 使用 Gemini 分析动作(身体部位、阶段、节奏、能量)
- 使用 Nano Banana (Gemini Flash Image) 生成风格化头像图片
- 使用 Veo 创建 AI 视频,通过虚拟形象重现动作
- 合成并排视频(原始视频 + AI 生成的视频)
- 通过针对移动设备进行了优化的网页上的二维码分享结果
完成本 Codelab 后,您将能够将完整的演示部署到 Google Cloud Run,并了解为其提供支持的 AI 流水线。
架构概览
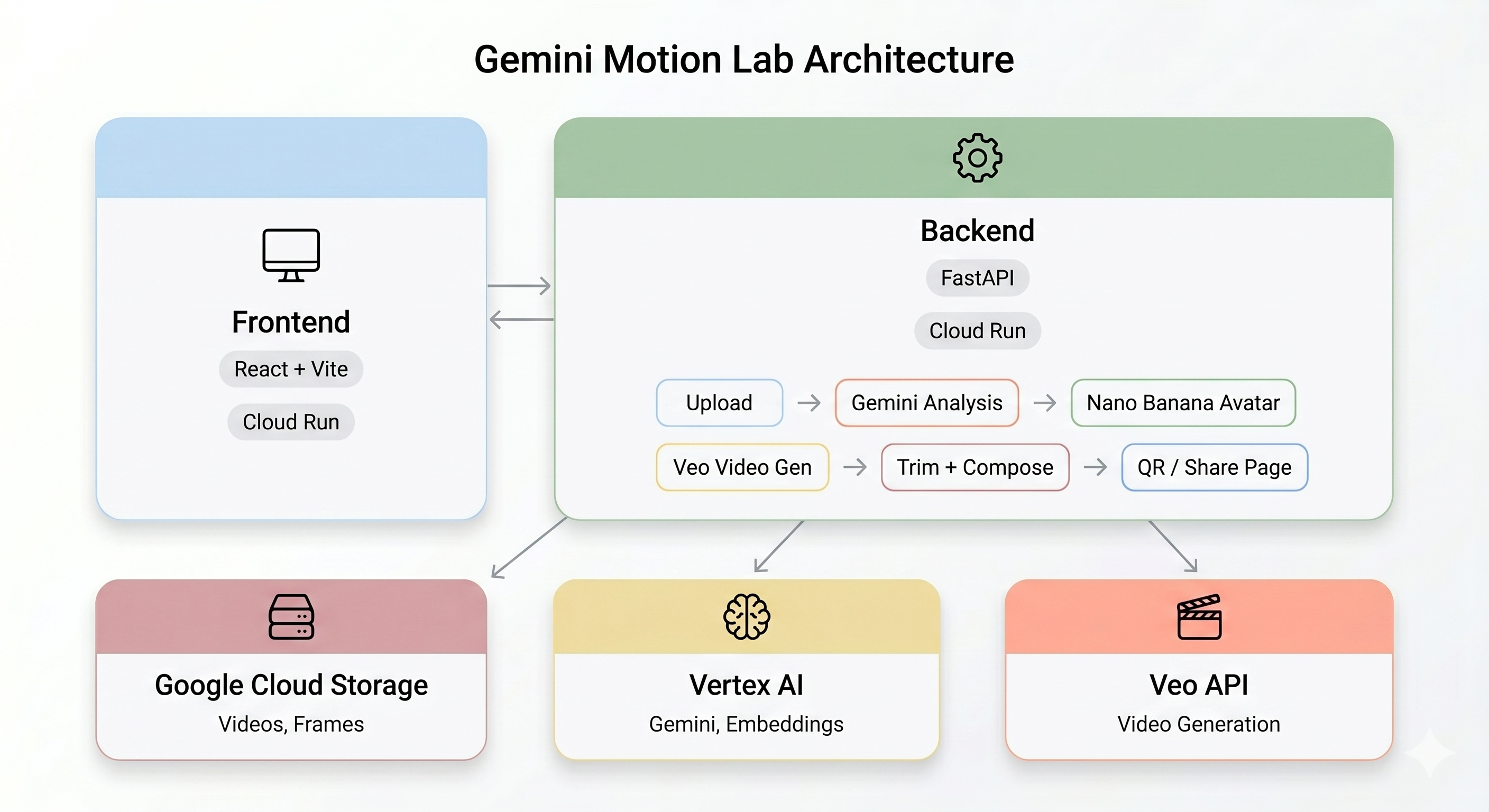
最终演示:
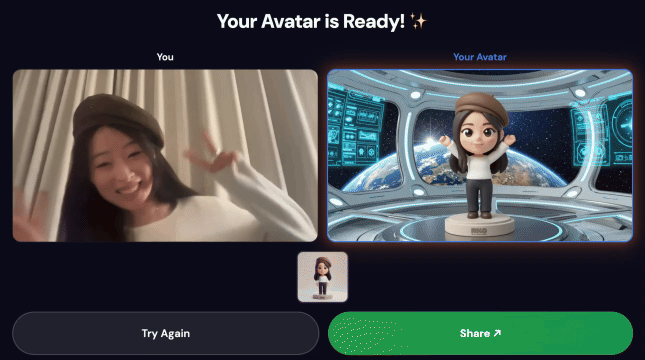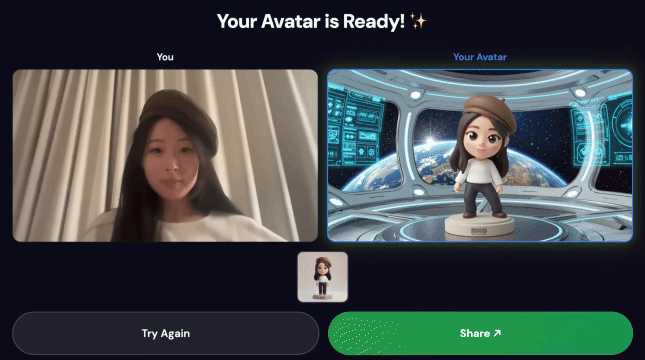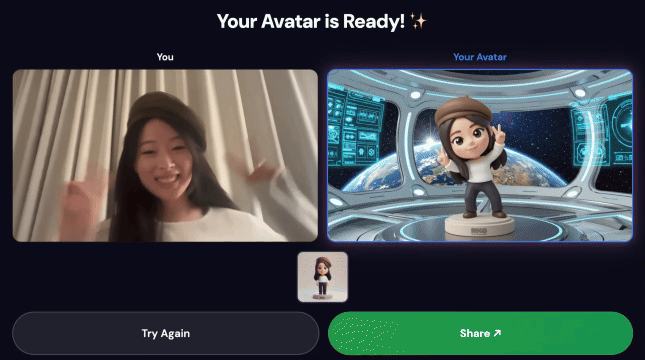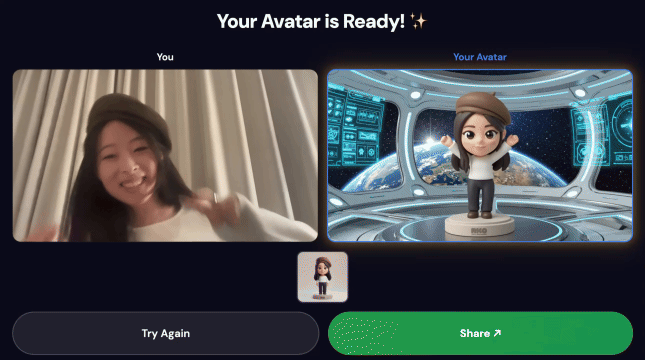
核心技术
组件 | 技术 | 用途 |
运动分析 | Gemini Flash | 分析视频中的身体动作、阶段和风格 |
虚拟形象生成 | Gemini Flash Image (Nano Banana) | 根据关键帧生成 1024x1024 的风格化虚拟形象 |
视频生成 | Veo 3.1 | 根据虚拟形象和动作提示创建 AI 视频 |
后端 | FastAPI + Python 3.11 | 具有异步流水线编排功能的 API 服务器 |
前端 | React + Vite + TypeScript | 具有摄像头录制和实时状态的自助服务终端界面 |
托管 | Cloud Run | 无服务器容器化部署 |
存储 | Google Cloud Storage | 视频上传、帧、剪辑和合成输出 |
2. 📦 克隆代码库
1. 打开 Cloud Shell Editor
👉 在浏览器中打开 Cloud Shell 编辑器。
如果终端未显示在屏幕底部:
- 点击查看
- 点击终端
2. 克隆代码
👉💻 在终端中,克隆代码库:
cd ~
git clone https://github.com/cuppibla/gemini-motion-lab-starter.git
cd gemini-motion-lab-starter
3. 探索项目结构
快速浏览代码库布局:
gemini-motion-lab-starter/
├── backend/ # FastAPI backend (Python 3.11)
│ ├── app/
│ │ ├── main.py # FastAPI app entry point
│ │ ├── config.py # Environment-based settings
│ │ ├── routers/ # API endpoints (upload, analyze, generate, share...)
│ │ ├── services/ # Business logic (Gemini, Veo, storage, pipeline...)
│ │ └── prompts/ # AI prompt templates
│ ├── Dockerfile
│ └── pyproject.toml
├── frontend/ # React + Vite + TypeScript
│ ├── src/ # React components
│ ├── public/ # Static assets
│ ├── Dockerfile
│ └── nginx.conf
├── init.sh # Create GCP project & link billing
├── billing-enablement.py # Auto-link billing account
├── setup.sh # Create GCS bucket, service account, .env
└── scripts/ # Utility scripts
3. 🛠️ 申领赠金并创建 GCP 项目
第 1 部分:领取结算赠金
👉 使用您的 Gmail 账号申领结算账号抵扣。
第 2 部分:创建新项目
👉💻 在终端中,将初始化脚本设为可执行,然后运行该脚本:
cd ~/gemini-motion-lab-starter
chmod +x init.sh
./init.sh
init.sh 脚本将执行以下操作:
- 创建以
gemini-motion-lab为前缀的新 GCP 项目 - 将项目 ID 保存到
~/project_id.txt - 安装结算依赖项并自动关联结算账号
第 3 部分:配置项目并启用 API
👉💻 在终端中设置项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 启用此项目所需的 Google Cloud API(这需要大约 1-2 分钟):
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
storage.googleapis.com \
artifactregistry.googleapis.com
4. 🧠 [只读] 了解架构
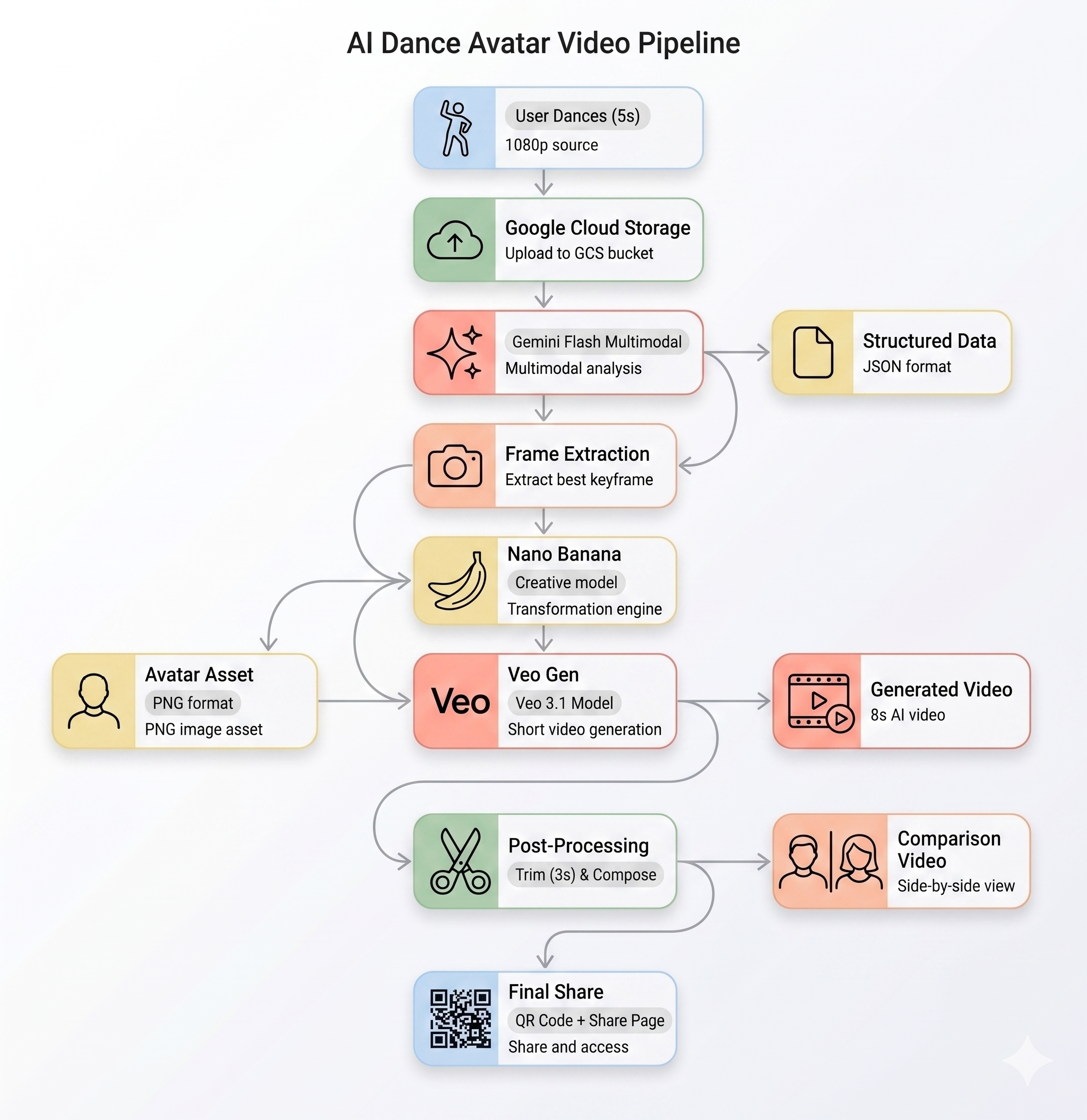
本部分介绍了 AI 流水线的端到端工作方式。无需采取任何行动 - 只需阅读本文,以便在部署之前了解该系统。
AI Pipeline
当用户在自助服务终端上录制动态短片时,系统会按顺序运行五个阶段:

第 1 阶段:视频上传
前端会从用户的摄像头录制一段 5 秒的 WebM 短片,并通过后端的 /api/upload 端点将其上传到 Google Cloud Storage。
POST /api/upload/{video_id} → gs://BUCKET/uploads/{video_id}.webm
第 2 阶段:Gemini 运动分析
后端会将上传的视频发送给 Gemini Flash (gemini-3-flash-preview) 进行结构化分析。
运作方式 (backend/app/services/gemini_service.py):
该服务使用 Vertex AI SDK 的 client.models.generate_content(),其中视频作为 Part.from_uri 输入,并使用结构化提示。response_mime_type="application/json" 可确保 Gemini 返回可解析的 JSON。该模型还使用 ThinkingConfig(thinking_budget=1024) 来更好地推理运动阶段。
# Simplified from gemini_service.py
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Part.from_uri(file_uri=gcs_uri, mime_type="video/webm"),
MOTION_ANALYSIS_PROMPT, # detailed prompt template
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
thinking_config=types.ThinkingConfig(thinking_budget=1024),
),
)
analysis = json.loads(response.text)
第 3 阶段:Nano Banana 虚拟形象生成
Gemini Flash Image (gemini-3.1-flash-image-preview) 会使用从视频中提取的最佳帧生成 1024×1024 的风格化头像。
运作方式 (backend/app/services/nano_banana_service.py):
# Simplified from nano_banana_service.py
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
types.Content(role="user", parts=[
types.Part.from_bytes(data=frame_bytes, mime_type="image/png"),
types.Part.from_text(text=avatar_prompt),
])
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="1:1",
output_mime_type="image/png",
),
),
)
生成的头像 PNG 会上传到 GCS 并传递到下一阶段。
第 4 阶段:Veo 视频生成
头像图片用作 Veo 3.1 (veo-3.1-fast-generate-001) 的参考素材资源,用于生成 8 秒的 AI 视频。
运作方式 (backend/app/services/veo_service.py):
# Simplified from veo_service.py
config = GenerateVideosConfig(
reference_images=[
VideoGenerationReferenceImage(
image=Image(gcs_uri=avatar_gcs_uri, mime_type="image/png"),
reference_type="ASSET",
)
],
aspect_ratio="16:9",
duration_seconds=8,
output_gcs_uri=f"gs://{BUCKET}/output/{video_id}/",
)
operation = client.models.generate_videos(
model="veo-3.1-fast-generate-001",
prompt=veo_prompt,
config=config,
)
Veo 生成是异步的,会立即返回操作 ID。后端会轮询操作,直到完成(最多 10 分钟)。
第 5 阶段:后处理流水线
Veo 完成后,后台流水线 (backend/app/services/pipeline.py) 会自动运行:
- 将 8 秒的 Veo 输出剪辑为 3 秒
- 合成并排视频(左侧为原始录制内容,右侧为 AI 视频)
- 将合成的视频上传到 GCS
- 释放队列 slot
此流水线作为后台 asyncio.Task 运行,自助服务终端前端无需等待。
队列系统
由于 Veo 生成需要大量资源,因此系统会强制执行最多 3 个并发作业的限制:
# backend/app/routers/queue.py
MAX_CONCURRENT_JOBS = 3
@router.get("/queue/status")
async def queue_status():
return {
"active_jobs": len(_active_jobs),
"max_jobs": MAX_CONCURRENT_JOBS,
"available": len(_active_jobs) < MAX_CONCURRENT_JOBS,
}
前端会在允许新用户开始会话之前检查 GET /api/queue/status。当流水线完成并调用 complete(video_id) 时,该 slot 会为下一个用户打开。
Cloud Run - 无服务器容器
后端和前端均部署为 Cloud Run 服务:
服务 | 用途 | 密钥配置 |
后端 | FastAPI API 服务器 | 2 GiB 内存(用于通过 ffmpeg 进行视频处理) |
前端 | 由 Nginx 提供的静态 React 应用 | 默认内存 |
5. ⚙️ 运行设置脚本
1. 运行自动设置
setup.sh 脚本会创建所需的云资源并生成 .env 文件。
👉💻 将脚本设为可执行,然后运行该脚本:
cd ~/gemini-motion-lab-starter
chmod +x setup.sh
./setup.sh
2. 授予 IAM 角色
现在,向服务账号授予所需权限。
👉💻 运行以下命令,设置项目 ID 并授予所有这三个角色:
export PROJECT_ID=$(cat ~/project_id.txt)
# 1. Storage Admin — upload/download videos and frames
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.admin"
# 2. Vertex AI User — call Gemini and Veo models
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
# 3. Service Account Token Creator — generate signed URLs for GCS
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
gcloud iam service-accounts add-iam-policy-binding \
gemini-motion-lab-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--project=$PROJECT_ID \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
3. 验证您的 .env 文件
👉💻 检查生成的 .env 文件:
cat .env
您应该会看到:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=us-central1
GCS_BUCKET=gemini-motion-lab-your-project-id
GCS_SIGNING_SA=gemini-motion-lab-sa@your-project-id.iam.gserviceaccount.com
GOOGLE_GENAI_USE_VERTEXAI=true
MOCK_AI=false
6. 🚀 部署后端
1. 了解后端 Dockerfile
在部署之前,我们先来了解一下容器的结构:
# backend/Dockerfile
FROM python:3.11-slim # Python base image
RUN apt-get update && apt-get install -y \
ffmpeg libgl1 libglib2.0-0 \ # ffmpeg for video processing
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY pyproject.toml .
RUN pip install --no-cache-dir . # Install Python dependencies
COPY app/ ./app/ # Copy application code
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
2. 部署到 Cloud Run
👉💻 加载环境变量并进行部署:
source .env
cd ~/gemini-motion-lab-starter/backend
gcloud run deploy gemini-motion-lab-backend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--memory 2Gi \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--set-env-vars "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,GCS_BUCKET=$GCS_BUCKET,GCS_SIGNING_SA=$GCS_SIGNING_SA,GOOGLE_GENAI_USE_VERTEXAI=$GOOGLE_GENAI_USE_VERTEXAI,MOCK_AI=$MOCK_AI"
此过程大约需要 3-5 分钟。Cloud Build 将:
- 上传源代码
- 构建 Docker 映像
- 将其推送到 Artifact Registry
- 将其部署到 Cloud Run
3. 保存后端网址
👉💻 部署完成后,保存后端网址:
BACKEND_URL=$(gcloud run services describe gemini-motion-lab-backend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "Backend URL: $BACKEND_URL"
4. 更新后端共享网址
后端会生成二维码,以便用户下载视频。为此,它需要知道自己的公开网址。
👉💻 使用后端自己的网址更新后端配置:
gcloud run services update gemini-motion-lab-backend \
--region us-central1 \
--update-env-vars PUBLIC_BASE_URL=$BACKEND_URL \
--project $GOOGLE_CLOUD_PROJECT
5. 验证后端
👉💻 测试健康端点:
curl $BACKEND_URL/api/health
预期输出:
{"status":"ok"}
👉💻 检查队列状态:
curl $BACKEND_URL/api/queue/status
预期输出:
{"active_jobs":0,"max_jobs":3,"available":true}
7. 🎨 部署前端
1. 了解前端 Dockerfile
前端使用多阶段构建 - 先构建 React 应用,然后使用 Nginx 提供该应用:
# frontend/Dockerfile
FROM node:20-alpine AS builder # Stage 1: Build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
ARG VITE_API_BASE=https://... # Backend URL baked at build time
ENV VITE_API_BASE=$VITE_API_BASE
RUN npm run build # Produces static files in /app/dist
FROM nginx:alpine # Stage 2: Serve
COPY --from=builder /app/dist /usr/share/nginx/html
COPY nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 8080
2. 部署到 Cloud Run
👉💻 首先,将后端网址写入 .env 文件,以便 Vite 在构建时将其嵌入:
cd ~/gemini-motion-lab-starter/frontend
echo "VITE_API_BASE=$BACKEND_URL" > .env
👉💻 现在部署前端:
gcloud run deploy gemini-motion-lab-frontend \
--source . \
--region us-central1 \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 3 \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT
此过程大约需要 2-3 分钟。
3. 获取前端网址
👉💻 检索并打开前端网址:
FRONTEND_URL=$(gcloud run services describe gemini-motion-lab-frontend \
--region us-central1 \
--format="value(status.url)" \
--project $GOOGLE_CLOUD_PROJECT)
echo "🎬 Your Gemini Motion Lab is live at: $FRONTEND_URL"
👉 在浏览器中打开该网址 - 您应该会看到 Gemini Motion Lab 信息亭界面!
8. 🎮 [可选] 试玩演示版
1. 录制动作
- 在浏览器中打开前端网址(最好使用 Chrome,以获得最佳摄像头支持)
- 点击开始即可开始录制
- 跳舞或移动约 5 秒钟 - 大幅度的手臂动作和动态姿势效果最佳
- 录制会自动停止并上传
2. 观看 AI Pipeline
上传后,您会实时看到流水线运行情况:
阶段 | 发生了什么 | 时长 |
正在分析… | Gemini Flash 会分析视频中的运动模式 | 大约 5-10 秒 |
正在生成头像… | Nano Banana 可根据您最满意的照片生成风格化头像 | 大约 8-12 秒 |
正在制作视频… | Veo 3.1 根据虚拟形象和动作提示生成 AI 视频 | 大约 60-120 秒 |
正在撰写… | ffmpeg 会剪裁并创建对照比较 | 大约 5-10 秒 |
3. 分享您的作品
流水线完成后:
- 信息亭屏幕上会显示一个二维码
- 使用手机扫描二维码
- 您将看到一个针对移动设备进行了优化的分享页面,其中包含您制作的视频
4. 检查后端日志
👉💻 了解幕后故事:
gcloud logging read \
"resource.type=cloud_run_revision AND resource.labels.service_name=gemini-motion-lab-backend" \
--limit=30 \
--project $GOOGLE_CLOUD_PROJECT \
--format="value(timestamp,textPayload)" \
--freshness=10m
您将看到跟踪流水线的日志行:
Pipeline started for video_id=abc123
Gemini model used: gemini-3-flash-preview
Avatar generated: style=pixel-hero size=450KB time=8.2s
Veo model used: veo-3.1-fast-generate-001
Pipeline: Veo complete for video_id=abc123
Pipeline: trimmed video uploaded
Pipeline: composed video uploaded
Pipeline complete for video_id=abc123
5. 监控队列
👉💻 检查有多少作业正在运行:
curl $BACKEND_URL/api/queue/status
如果 3 个会话同时处于有效状态,则响应将显示:
{"active_jobs":3,"max_jobs":3,"available":false}
新用户需要等待有空位时才能加入。
9. 🎉 总结
您已构建的内容
✅ AI 运动分析 - Gemini Flash 分析视频中的动作、节奏和风格
✅ 虚拟形象生成 - Nano Banana 可根据视频帧创建风格化的虚拟形象
✅ AI 视频制作 - Veo 3.1 可生成与用户动作相符的新视频
✅ 异步流水线 - 通过队列管理进行后台处理(最多 3 个并发)
✅ 并排合成 - 基于 ffmpeg 的视频合成
✅ Cloud Run 部署 - 无服务器、自动扩缩、无需服务器管理
您学到的主要概念
- Gemini Multimodal - 将视频作为输入发送并接收结构化 JSON 分析
- Nano Banana(Gemini 图片生成)- 使用参考图片 + 风格提示生成头像
- Veo 3.1 - 使用参考素材和文本提示异步生成视频
- Cloud Run - 部署具有环境变量和自动扩缩功能的容器
- 异步流水线模式 - 使用
asyncio.Task执行长时间运行的 AI 操作的 Fire-and-forget 后台任务 - 队列管理 - 限制并发 AI 作业的速率,以控制费用和 API 配额
架构回顾
后续步骤
- 添加更多头像样式 - 修改
backend/app/prompts/avatar_generation.py - 自定义 Veo 提示 - 修改
backend/app/prompts/video_generation.py - 以模拟模式在本地运行 - 在
.env中设置MOCK_AI=true以进行不含 API 调用的开发 - 活动规模 - 增加
--max-instances和MAX_CONCURRENT_JOBS