
1. Übersicht
In diesem Lab lernen Sie die KI-Infrastruktur kennen, die für die Ausführung von KI-Arbeitslasten verwendet werden kann. Sie arbeiten mit den folgenden Produkten:
Google Kubernetes Engine (GKE) : Die grundlegende Plattform für die Containerorchestrierung.
Verwaltetes DRANET von GKE : Dynamic Resource Allocation Networking, das Ihren TPU-Pods direkt Hochgeschwindigkeits-Interconnect-Fabrics zuweist.
Tensor Processing Unit (TPU) : Die von Google entwickelten Beschleunigerchips.
Zum Konfigurieren stellen Sie eine benutzerdefinierte VPC und einen GKE-Autopilot-Cluster bereit. Um verwaltetes DRANET zu aktivieren, erstellen Sie eine ComputeClass und eine ResourceClaimTemplate. Anschließend stellen Sie eine Arbeitslast bereit, die vLLM, Hugging Face, ComputeClass und ResourceClaimTemplate verwendet. Zum Schluss testen Sie die Netzwerkeinrichtung und die Verbindung zum Gemma 4-Modell.
Für die Konfigurationen wird eine Kombination aus Terraform, gcloud und kubectl verwendet.
In diesem Lab lernen Sie, wie Sie die folgende Aufgabe ausführen:
- VPC-Netzwerk einrichten
- GKE-Autopilot-Cluster einrichten
- ComputeClass und ResourceClaimTemplate erstellen.
- Bereitstellung erstellen, die TPUs, vLLM, Monitoring und Gemma 4 über Hugging Face ausführt
- Verbindung zum LLM testen
In diesem Lab erstellen Sie das folgende Muster.
Abbildung 1. 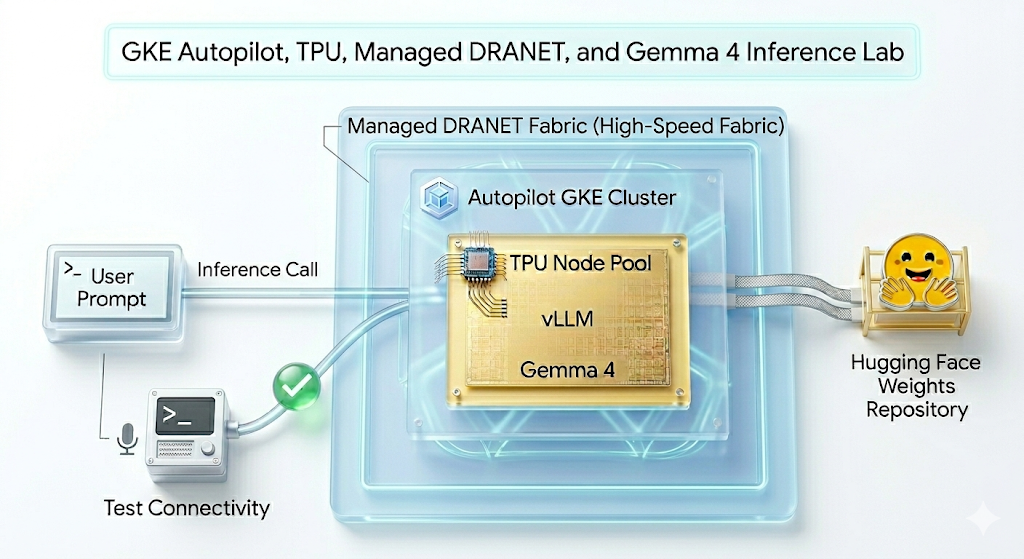
2. Google Cloud-Dienste einrichten
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Er ist ein String, der von Google APIs nicht verwendet wird. Sie können ihn jederzeit aktualisieren.
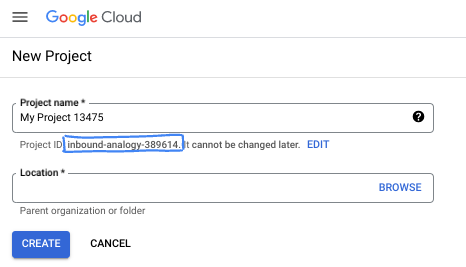
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich. Sie kann also nicht geändert werden, nachdem sie festgelegt wurde. Die Cloud Console generiert automatisch einen eindeutigen String. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie eine eigene ID verwenden und prüfen, ob sie verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Es gibt noch einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten finden Sie in der Dokumentation.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um zu vermeiden, dass nach dieser Anleitung Kosten anfallen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können das kostenlose Testprogramm im Wert von 300 $ nutzen.
Cloud Shell starten
Google Cloud kann zwar von Ihrem Laptop aus per Fernzugriff genutzt werden, in diesem Codelab verwenden Sie jedoch Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console in der Symbolleiste rechts oben auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Wenn der Vorgang abgeschlossen ist, sollte etwa Folgendes angezeigt werden:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Umgebung mit Terraform einrichten
Für dieses Lab benötigen Sie Zugriff auf TPUs. Die verwendete Version ist TPU v6e.
- Folgen Sie der TPU-Plan-Dokumentation und aktivieren Sie das TPU-Kontingent, um Zugriff zu erhalten.
- Wir verwenden eine kleine Bereitstellung mit vier TPU v6e-Chips (
ct6e-standard-4t)die ein 2x2-Slice in einer einzelnen Region umfasst. - Hugging Face-Token: Zum Herunterladen der Gemma-Modellgewichte ist ein Zugriffstoken erforderlich.
Wir erstellen eine benutzerdefinierte VPC mit Firewallregeln, ein Subnetz und dann einen Autopilot-Cluster. Öffnen Sie die Cloud Console und wählen Sie das Projekt aus, das Sie verwenden möchten.
- Öffnen Sie Cloud Shell rechts oben in der Console. Prüfen Sie, ob die richtige Projekt-ID in Cloud Shell angezeigt wird, und bestätigen Sie alle Aufforderungen, um den Zugriff zu erlauben.

- Erstellen Sie einen Ordner mit dem Namen
gke-auto-tpuund wechseln Sie zu diesem Ordner.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Fügen Sie nun einige Konfigurationsdateien hinzu. Dadurch werden die folgenden Dateien erstellt: terraform.tfvars , variables.tf und net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Achten Sie darauf, dass Sie sich im Verzeichnis gke-auto-tpu befinden, und führen Sie die folgenden Befehle aus:
terraform initinitialisiert das Arbeitsverzeichnis. Dies ist der erste Schritt. Dabei werden die für die angegebene Konfiguration erforderlichen Anbieter heruntergeladen.terraform plan -outgeneriert einen Ausführungsplan, der zeigt, welche Aktionen Terraform ausführt, um Ihre Infrastruktur bereitzustellen. Mit-outkönnen Sie den Ausführungsplan in einer benannten Binärdatei speichern. Sie können sehen, was passiert, ohne Änderungen vorzunehmen.terraform applyführt die Aktualisierungen aus.
terraform init
terraform plan -out vpc
- Führen Sie die Bereitstellung aus, nachdem Sie
terraform applyausgeführt haben. Da Sie den gespeicherten Ausführungsplan anwenden, wird er sofort ausgeführt, ohne dass Sie zur Bestätigung aufgefordert werden. Das kann 6 bis 10 Minuten dauern.
terraform apply vpc
- Einrichtung prüfen
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. ComputeClass und ResourceClaimTemplate erstellen
Wir müssen eine benutzerdefinierte ComputeClass-Ressource erstellen, um die Konfiguration für den Knotenpool zu definieren. In unserem Fall verwenden wir die TPU v6e-Chips (ct6e-standard-4t)) und verwaltete DRANET-Netzwerke.
- Stellen Sie eine Verbindung zum erstellten Cluster her. Ändern Sie die Region in die Region, in der Sie Ihren Cluster bereitgestellt haben.
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-auto-tpubefinden, und führen Sie die folgenden Befehle aus. Dadurch wird das ComputeClass-Manifest erstellt. Wenn Sie eine andere Region verwendet haben, müssen Sie die Zoneninformationen in eine Zone in der Region Ihres Clusters ändern.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Erstellen Sie nun die ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- Führen Sie im Verzeichnis
gke-auto-tpudie folgenden Befehle aus. Dadurch wird das ResourceClaimTemplate-Manifest erstellt, das Nicht-RDMA-Netzwerkgeräte unterstützt.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Erstellen Sie nun die ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Secret erstellen
- In diesem Lab wird google/gemma-4-31B-it verwendet. Daher müssen Sie ein HF-Token erstellen. Ersetzen Sie
YOUR_ACTUAL_HUGGING_FACE_TOKENunten durch Ihr tatsächliches Token.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-auto-tpubefinden, und führen Sie die folgenden Befehle aus.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Arbeitslast vLLM und Gemma bereitstellen
Bei dieser Einrichtung wird die ComputeClass verwendet, um die erforderliche Hardware und das Netzwerk (TPU v6e und verwaltetes DRANET) automatisch bereitzustellen. Mit der ResourceClaimTemplate wird ein Blueprint für das Anfordern des Zugriffs auf dieses Hochgeschwindigkeitsnetzwerk definiert. Außerdem wird eine Bereitstellung erstellt, die die beiden Elemente miteinander verbindet, indem für jeden Pod individuelle Netzwerkansprüche generiert werden, wenn sie skaliert werden.
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-auto-tpubefinden, und führen Sie Folgendes aus.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Erstellen Sie die Bereitstellung.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Führen Sie die folgenden Befehle aus, um den Abschlussstatus zu prüfen. Die Pods warten, bis der Knoten bereitgestellt ist, bevor sie fortfahren können. Das kann 13 Minuten oder länger dauern.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Nachdem der Knoten erstellt und der Pod geplant wurde, können Sie mit dem Befehl die Logs der Pods aufrufen. (Sie können das **
-f** **Flag für das Streaming hinzufügen**). Das kann bis zu **15 Minuten oder länger** dauern. Wenn Sie die Logs beobachten und den String(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKsehen, ist das Modell bereit.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Sobald die Bereitstellung verfügbar ist, können Sie prüfen, ob das Hochgeschwindigkeitsnetzwerk ordnungsgemäß an Ihre TPU-Pods angehängt ist. Führen Sie den folgenden Befehl aus:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Worauf Sie achten sollten:Neben dem Standardinterface eth0 sollten zusätzliche Interfaces wie eth1 bis ethxx angezeigt werden.
Diese zusätzlichen Interfaces bestätigen, dass das verwaltete DRANET-Fabric mit Hochgeschwindigkeit erfolgreich an Ihren Pod angehängt wurde.
6. Mit curl mit dem KI-Modell interagieren
Um das bereitgestellte Modell gemma-4-31B zu prüfen, richten Sie die Portweiterleitung vom Dienst zu Ihrem lokalen Computer ein.
- Führen Sie diesen Befehl in Ihrer aktuellen Cloud Shell aus:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Öffnen Sie nun ein zusätzliches Cloud Shell-Fenster für dasselbe Projekt, um mit
curlmit Ihrem Modell zu chatten. Mit diesem Befehl wird ein Prompt gesendet und die Ausgabe direkt an Ihr Terminal gestreamt.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Prüfen Sie die Antwort Ihres Modells.
Beobachtbarkeit
Da wir die benutzerdefinierte Ressource PodMonitoring angewendet haben, erfasst Cloud Monitoring Messwerte aus dem vLLM-Container auf Port 8000. Sie können in der Google Cloud Console zu Monitoring -> Dashboards navigieren, um Messwerte wie die Latenz bei der Tokengenerierung, die Warteschlangenlänge und die KV-Cache-Nutzung nativ aufzurufen.
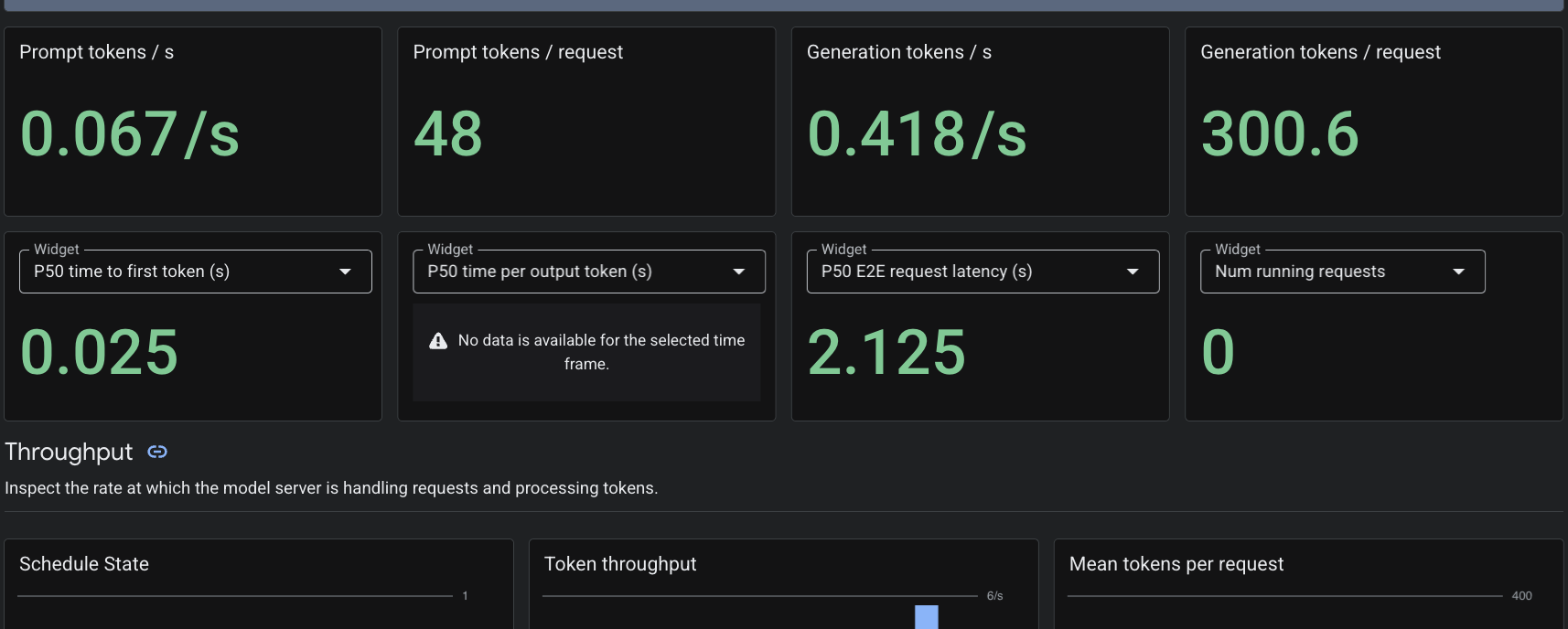
7. Bereinigen
- Löschen Sie die Ressourcen mit dem folgenden Befehl.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Bereinigen Sie die Infrastruktur mit dem folgenden Befehl. Geben Sie
yesein, um zu bestätigen.
terraform destroy
8. Glückwunsch
Sie haben erfolgreich eine verwaltete DRANET-Umgebung in GKE Autopilot bereitgestellt, TPU v6e-Hardware dynamisch bereitgestellt und das Gemma 4-Modell mit 31 Milliarden Parametern mithilfe von vLLM bereitgestellt.
Wenn Sie GKE Autopilot verwenden, können Sie Kubernetes die Bereitstellung von Knoten und die Verwaltung der Infrastruktur überlassen und sich ganz auf die Bereitstellung Ihrer KI-Arbeitslast konzentrieren.
Weitere Informationen
Weitere Informationen zum GKE-Netzwerk
Nächstes Lab absolvieren
Setzen Sie Ihre Quest mit Google Cloud fort und sehen Sie sich diese anderen Google Cloud-Labs an: