
1. Descripción general
En este lab, se presenta la infraestructura de IA que se puede usar para ejecutar cargas de trabajo de IA. Trabajarás con lo siguiente:
Google Kubernetes Engine (GKE): Es la plataforma fundamental de organización de contenedores.
DRANET administrada por GKE: Es una red de asignación dinámica de recursos que asigna directamente estructuras de interconexión de alta velocidad a tus Pods de TPU.
Unidad de procesamiento tensorial (TPU): Chips aceleradores personalizados de Google.
Para configurar, implementarás una VPC personalizada y un clúster de GKE en modo Autopilot. Para habilitar DRANET administrado, crearás una ComputeClass y una plantilla de ResourceClaim. Luego, implementarás una carga de trabajo que use vLLM, Hugging Face, ComputeClass y plantilla de reclamo de recursos. Por último, probarás la configuración de redes y la conectividad con el modelo Gemma 4.
Las configuraciones usarán una combinación de Terraform, gcloud y kubectl.
En este lab, aprenderás a realizar la siguiente tarea:
- Configura una red de VPC
- Configura un clúster de GKE Autopilot
- Crea ComputeClass y ResourceClaimTemplate.
- Crea una implementación que ejecute TPU, vLLM, supervisión y Gemma 4 a través de Hugging Face
- Prueba la conectividad con el LLM
En este lab, crearás el siguiente patrón.
Figura 1: 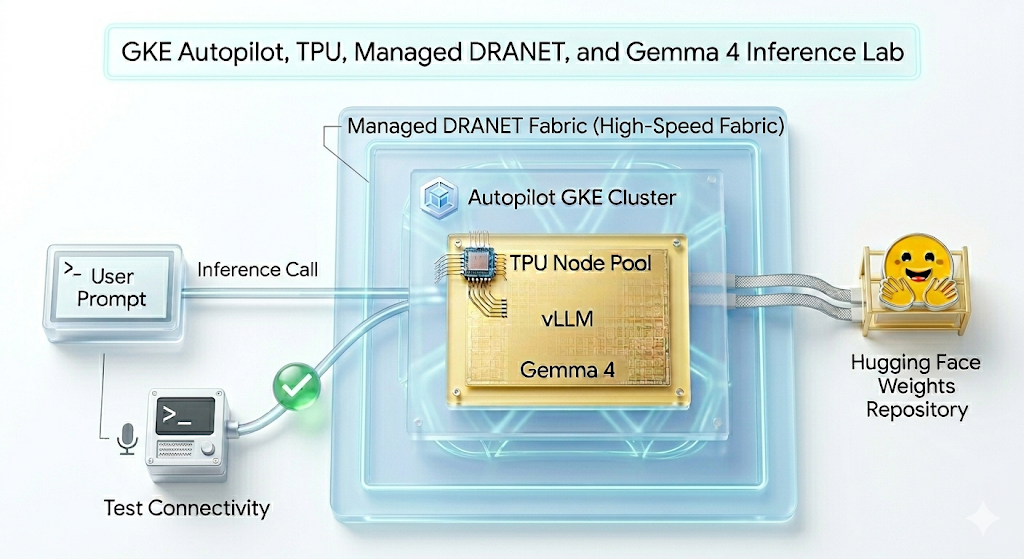
2. Configuración de los servicios de Google Cloud
Configuración del entorno de autoaprendizaje
- Accede a consola de Google Cloud y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Configura el entorno con Terraform
Para realizar este lab, necesitas acceso a las TPU. La versión exacta que se usa es la TPU v6e.
- Para obtener acceso, debes seguir el documento del plan de TPU y habilitar la cuota de TPU.
- Usaremos una implementación pequeña que requiere 4 chips de TPU v6e (
ct6e-standard-4t)que será una porción de 2 x 2 en una sola región. - Token de Hugging Face: Se necesita un token de acceso para descargar los pesos del modelo de Gemma.
Crearemos una VPC personalizada con reglas de firewall, una subred y, luego, un clúster de piloto automático. Abre la consola de Cloud y selecciona el proyecto que usarás.
- Abre Cloud Shell, que se encuentra en la parte superior derecha de la consola, asegúrate de ver el ID del proyecto correcto en Cloud Shell y confirma cualquier mensaje para permitir el acceso.

- Crea una carpeta llamada
gke-auto-tpuy muévete a ella.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Ahora, agrega algunos archivos de configuración. Esto creará los siguientes archivos terraform.tfvars, variables.tf y net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Asegúrate de estar en el directorio gke-auto-tpu y ejecuta los siguientes comandos
terraform initInicializa el directorio de trabajo. Este es el primer paso y descarga los proveedores necesarios para la configuración determinada.terraform plan -outgenera un plan de ejecución que muestra las acciones que Terraform realizará para implementar tu infraestructura. El-outte permite guardar el plan de ejecución en un archivo binario con nombre. Puedes ver lo que sucederá sin realizar ningún cambio.terraform applyejecuta las actualizaciones.
terraform init
terraform plan -out vpc
- Ahora ejecuta la implementación después de ejecutar
terraform apply, ya que aplicarás el plan de ejecución guardado, se ejecutará de inmediato sin solicitar confirmación (esto puede tardar entre 6 y 10 minutos).
terraform apply vpc
- Verifica la configuración
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Crea una clase de procesamiento y una plantilla de reclamo de recursos
Debemos crear un recurso ComputeClass personalizado para definir la configuración del grupo de nodos. En nuestro caso, usaremos los chips de TPU v6e (ct6e-standard-4t) y redes DRANET administradas.
- Conéctate al clúster que creaste. (Posdata: Cambia la región a la región en la que implementaste tu clúster).
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Asegúrate de estar en el directorio
gke-auto-tpuy ejecuta los siguientes comandos. Esto crea el manifiesto de ComputeClass. Ten en cuenta que, si usaste una región diferente, debes cambiar la información de la zona por una zona dentro de la región de tu clúster
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Ahora, crea el objeto ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- En el directorio
gke-auto-tpu, ejecuta los siguientes comandos. Esto crea el manifiesto de ResourceClaimTemplate que admite dispositivos de red que no son RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Ahora, crea el ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Crea tu secreto
- En este lab, se usa google/gemma-4-31B-it , por lo que deberás crear un token de HF. Reemplaza
YOUR_ACTUAL_HUGGING_FACE_TOKENpor tu token real.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Asegúrate de estar en el directorio
gke-auto-tpuy ejecuta los siguientes comandos.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Implementa vLLM y Gemma de Workload
Esta configuración usa ComputeClass para aprovisionar automáticamente el hardware y las redes necesarios (TPU v6e y DRANET administrada). Utiliza ResourceClaimTemplate para definir un plan para solicitar acceso a esa red de alta velocidad y una implementación que los une generando reclamos de red individuales para cada pod a medida que se escalan.
- Asegúrate de estar en el directorio
gke-auto-tpuy ejecuta el siguiente comando.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Crea la implementación.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Para supervisar el estado de finalización, ejecuta los siguientes comandos. Los Pods esperarán hasta que se aprovisione el nodo antes de poder continuar, lo que puede tardar más de 13 minutos.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Después de crear el nodo y programar el pod, puedes ejecutar el comando para ver los registros de los pods (PD: Puedes agregar la marca **
-f** **para la transmisión**). Esto tardará más de **15 minutos** en completarse si observas los registros cuando veas la cadena(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK, el modelo estará listo para entregar resultados.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Una vez que la implementación esté disponible, puedes verificar que la red de alta velocidad esté conectada correctamente a tus pods de TPU. Ejecuta el siguiente comando:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Qué buscar: Deberías ver eth0 estándar junto con interfaces adicionales, como eth1 a ethxx.
Estas interfaces adicionales confirman que la estructura de DRANET administrada de alta velocidad se adjuntó correctamente a tu pod.
6. Interactúa con el modelo de IA usando curl
Para verificar el modelo gemma-4-31B que implementaste, configura el reenvío de puertos desde el servicio a tu máquina local.
- Ejecuta el siguiente comando en tu Cloud Shell actual:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Ahora, abre una ventana adicional de Cloud Shell para el mismo proyecto y chatea con tu modelo usando
curl. Este comando envía una instrucción y transmite el resultado directamente a tu terminal.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Consulta la respuesta de tu modelo
Observabilidad
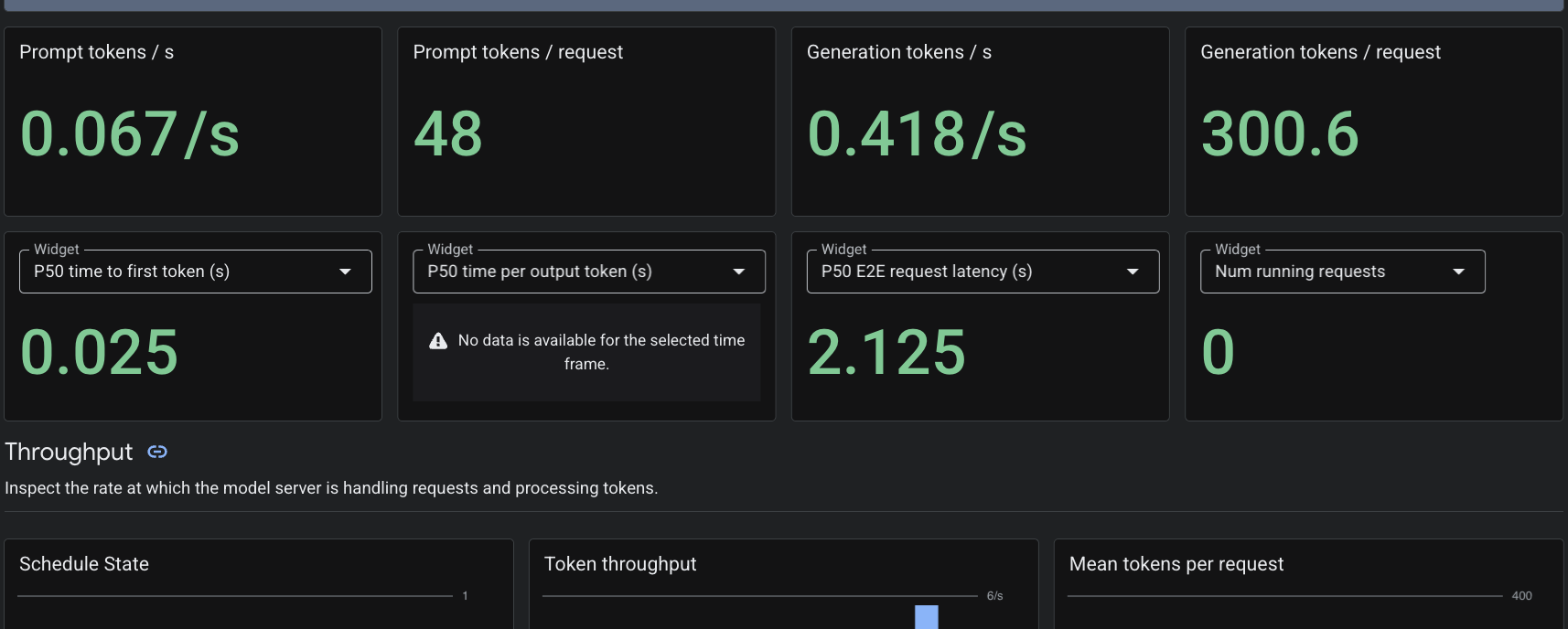
Dado que aplicamos el recurso personalizado PodMonitoring, Cloud Monitoring extraerá métricas del contenedor de vLLM en el puerto 8000. Puedes navegar a Monitoring -> Dashboards en la consola de Google Cloud para ver métricas como la latencia de generación de tokens, la longitud de la cola y el uso de la caché de KV de forma nativa.
7. Limpia
- Ejecuta el siguiente comando para borrar los recursos.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Limpia la infraestructura con el siguiente comando y escribe
yespara confirmar.
terraform destroy
8. Felicitaciones
Implementaste correctamente un entorno de DRANET administrado en GKE Autopilot, aprovisionaste hardware de TPU v6e de forma dinámica y entregaste el enorme modelo Gemma 4 de 31, 000 millones de parámetros con vLLM.
Si usas GKE Autopilot, permites que Kubernetes controle el aprovisionamiento de nodos subyacentes y la administración de la infraestructura, lo que te permite enfocarte por completo en implementar tu carga de trabajo de IA.
Próximos pasos y más información
Puedes leer más sobre las herramientas de redes de GKE.
Realiza tu próximo lab
Continúa tu Quest con Google Cloud y consulta estos otros labs de Google Cloud: