
۱. مرور کلی
این آزمایشگاه شما را با زیرساخت هوش مصنوعی که میتواند برای اجرای بارهای کاری هوش مصنوعی استفاده شود، آشنا میکند. شما با موارد زیر کار خواهید کرد:
موتور گوگل کوبرنتیز (GKE) - پلتفرم اساسی هماهنگسازی کانتینر.
GKE DRANET را مدیریت کرد - شبکه تخصیص منابع پویا که مستقیماً فابریکهای اتصال پرسرعت را به غلافهای TPU شما اختصاص میدهد.
واحد پردازش تنسور (TPU) - تراشههای شتابدهنده سفارشی گوگل.
برای پیکربندی، شما یک VPC سفارشی و یک کلاستر GKE با قابلیت هدایت خودکار مستقر خواهید کرد. برای فعالسازی DRANET مدیریتشده، یک ComputeClass و یک Resource Claim Template ایجاد خواهید کرد. سپس یک بار کاری که از vLLM ، Hugging Face ، ComputeClass و resource Claim Template استفاده میکند، مستقر خواهید کرد. در نهایت، راهاندازی شبکه و اتصال به مدل Gemma 4 را آزمایش خواهید کرد.
این پیکربندیها از ترکیبی از Terraform ، gcloud و kubectl استفاده خواهند کرد.
در این آزمایشگاه یاد خواهید گرفت که چگونه وظایف زیر را انجام دهید:
- راه اندازی شبکه VPC
- یک خوشه خلبان خودکار GKE راهاندازی کنید
- کلاس ComputeClass و قالب ResourceClaim را ایجاد کنید.
- ایجاد یک استقرار که TPUها، vLLM، مانیتورینگ و Gemma 4 را از طریق Hugging Face اجرا میکند
- اتصال به LLM را آزمایش کنید
در این آزمایش، شما قرار است الگوی زیر را ایجاد کنید.
شکل ۱. 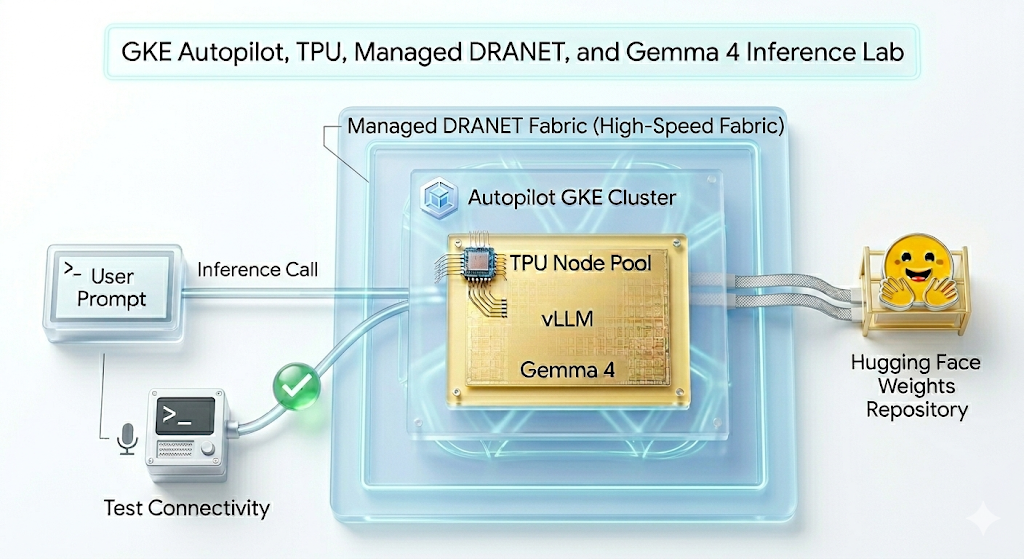
۲. راهاندازی سرویسهای ابری گوگل
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
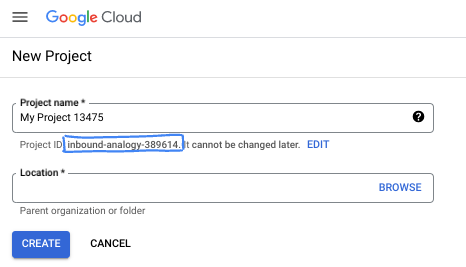
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. راهاندازی محیط با Terraform
برای انجام این آزمایش، به TPU نیاز دارید. نسخه دقیق مورد استفاده TPU نسخه ۶e است.
- برای دسترسی باید طبق دستورالعمل طرح TPU عمل کنید و سهمیه TPU را فعال کنید .
- ما از یک سیستم کوچک استفاده میکنیم که به ۴ تراشه TPU v6e (
ct6e-standard-4t)نیاز دارد که یک برش ۲x۲ در یک ناحیه واحد خواهد بود. - توکن چهره در آغوش گرفته: برای دانلود وزنهای مدل Gemma به یک توکن دسترسی نیاز است.
ما یک VPC سفارشی با قوانین فایروال، یک زیرشبکه و سپس یک خوشه خودکار ایجاد خواهیم کرد. کنسول ابری را باز کنید و پروژهای را که استفاده خواهید کرد انتخاب کنید.
- Cloud Shell را که در بالای کنسول شما در سمت راست قرار دارد باز کنید، مطمئن شوید که شناسه پروژه صحیح را در Cloud Shell مشاهده میکنید، هرگونه درخواستی را برای اجازه دسترسی تأیید کنید.

- یک پوشه به نام
gke-auto-tpuایجاد کنید و به پوشه مورد نظر بروید.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- حالا چند فایل پیکربندی اضافه کنید. این فایلها فایلهای terraform.tfvars ، variables.tf و net.tf زیر را ایجاد میکنند.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- مطمئن شوید که در پوشه gke-auto-tpu هستید و دستورات زیر را اجرا کنید
terraform initدایرکتوری کاری را مقداردهی اولیه میکند. این اولین قدم است و ارائهدهندگان مورد نیاز برای پیکربندی داده شده را دانلود میکند.
terraform plan -outیک طرح اجرایی ایجاد میکند که نشان میدهد Terraform چه اقداماتی را برای استقرار زیرساخت شما انجام خواهد داد. دستور terraform-outبه شما امکان میدهد طرح اجرایی را در یک فایل باینری نامگذاری شده ذخیره کنید. میتوانید بدون ایجاد هیچ تغییری، ببینید چه اتفاقی خواهد افتاد.
terraform applyبهروزرسانیها را اجرا میکند.
terraform init
terraform plan -out vpc
- اکنون پس از اجرای
terraform apply، عملیات استقرار را اجرا کنید، از آنجایی که شما در حال اعمال طرح اجرایی ذخیره شده هستید، بلافاصله و بدون درخواست تأیید اجرا خواهد شد (این ممکن است بین ۶ تا ۱۰ دقیقه طول بکشد).
terraform apply vpc
- تنظیمات را تأیید کنید
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
۴. ایجاد کلاس محاسبه و الگوی درخواست منابع
ما باید یک منبع ComputeClass سفارشی ایجاد کنیم تا پیکربندی مربوط به node pool را تعریف کنیم. در مورد ما، از تراشههای TPU v6e ( ct6e-standard-4t) و شبکههای DRANET مدیریتشده استفاده خواهیم کرد.
- به کلاستری که ایجاد کردهاید متصل شوید. ( برای تغییر منطقه به منطقهای که کلاستر خود را در آن مستقر کردهاید، این کار را انجام دهید. )
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- مطمئن شوید که در دایرکتوری
gke-auto-tpuهستید و دستورات زیر را اجرا کنید. این کار مانیفست ComputeClass را ایجاد میکند. لطفاً توجه داشته باشید که اگر از منطقهی دیگری استفاده کردهاید، باید اطلاعات منطقه را به منطقهای در محدودهی خوشهی خود تغییر دهید.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- حالا کلاس ComputeClass را ایجاد کنید.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- در دایرکتوری
gke-auto-tpuدستورات زیر را اجرا کنید. این کار مانیفست ResourceClaimTemplate را ایجاد میکند که از دستگاههای شبکه غیر RDMA پشتیبانی میکند.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- حالا ResourceClaimTemplate را ایجاد کنید.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
راز خود را خلق کنید
- این آزمایشگاه از google/gemma-4-31B-it استفاده میکند، بنابراین شما باید یک توکن HF ایجاد کنید .
YOUR_ACTUAL_HUGGING_FACE_TOKENرا در زیر با توکن واقعی خود جایگزین کنید.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- مطمئن شوید که در دایرکتوری
gke-auto-tpuهستید و دستورات زیر را اجرا کنید.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
۵. استقرار حجم کاری vLLM و Gemma
این تنظیمات از ComputeClass برای تأمین خودکار سختافزار و شبکه مورد نیاز (TPU v6e و DRANET مدیریتشده) استفاده میکند. از ResourceClaimTemplate برای تعریف طرحی برای درخواست دسترسی به آن شبکه پرسرعت و استقراری که آنها را با ایجاد Claimهای شبکهای مجزا برای هر pod در حین مقیاسپذیری به هم متصل میکند، استفاده میکند.
- مطمئن شوید که در دایرکتوری
gke-auto-tpuهستید و دستور زیر را اجرا کنید.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- استقرار را ایجاد کنید.
kubectl apply -f gem4-auto-dra-tpu.yaml
- برای نظارت بر وضعیت تکمیل، دستورات زیر را اجرا کنید. پادها منتظر میمانند تا گره آماده شود و سپس میتوانند ادامه دهند، این ممکن است بیش از ۱۳ دقیقه طول بکشد.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- پس از ایجاد گره و زمانبندی پاد، میتوانید دستور را برای مشاهدهی لاگهای پادها اجرا کنید. ( توجه داشته باشید که میتوانید برای استریمینگ از فلگ**
-f**استفاده کنید). اگر در حال مشاهدهی لاگها باشید و رشتهی (APIServer pid=1) را ببینید، تکمیل این فرآیند تا ۱۵+ دقیقه طول خواهد کشید(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKمدل آمادهی سرویسدهی است.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- پس از آماده شدن استقرار، میتوانید تأیید کنید که شبکه پرسرعت به درستی به غلافهای TPU شما متصل شده است. دستور زیر را اجرا کنید:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
به دنبال چه چیزی باشیم: شما باید eth0 استاندارد را در کنار رابطهای اضافی مانند eth1 تا ethxx ببینید.
این رابطهای اضافی تأیید میکنند که شبکه DRANET مدیریتشده با سرعت بالا با موفقیت به پاد شما متصل شده است.
۶. تعامل با مدل هوش مصنوعی با استفاده از curl
برای تأیید مدل gemma-4-31B که مستقر کردهاید، ارسال پورت را از سرویس به دستگاه محلی خود تنظیم کنید.
- این را در Cloud Shell فعلی خود اجرا کنید:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- حالا، یک پنجره Cloud Shell اضافی برای همان پروژه باز کنید تا با استفاده از
curlبا مدل خود چت کنید. این دستور یک اعلان ارسال میکند و خروجی را مستقیماً به ترمینال شما پخش میکند.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- پاسخ مدل خود را بررسی کنید
مشاهدهپذیری
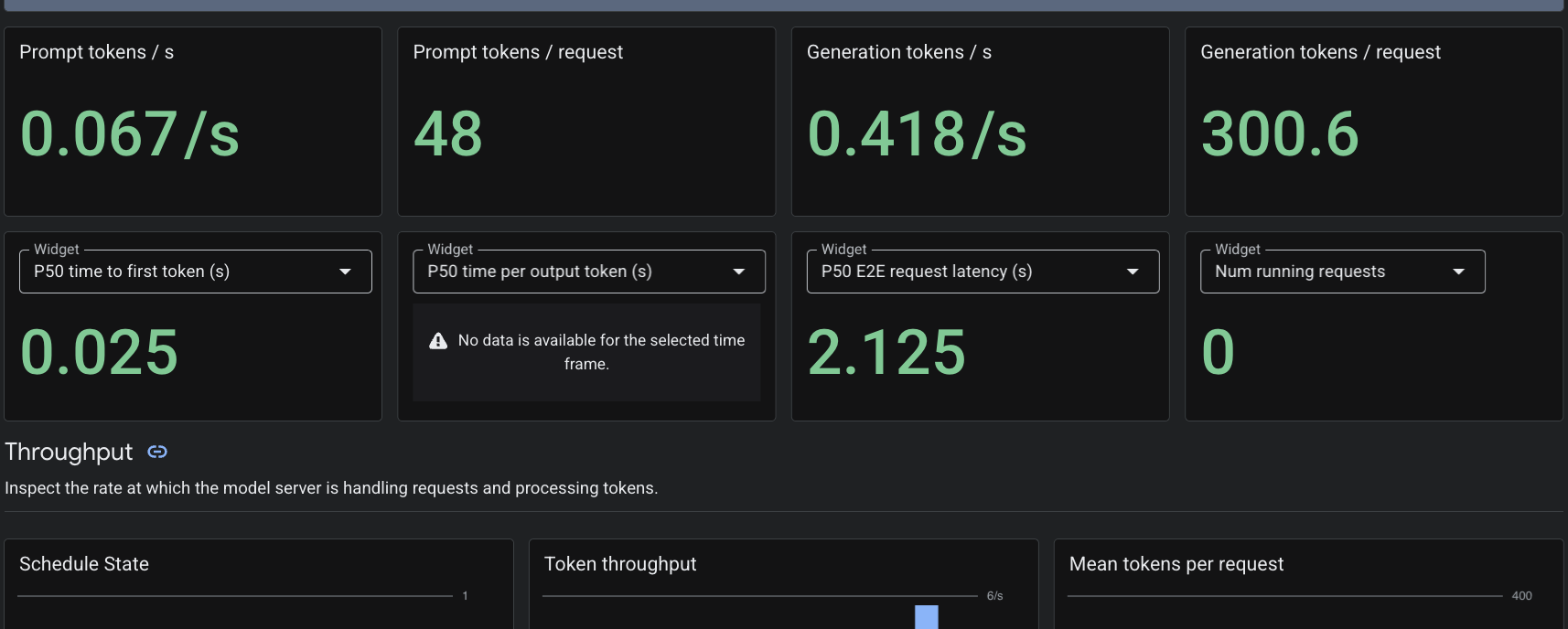
از آنجایی که ما منبع سفارشی PodMonitoring اعمال کردهایم، Cloud Monitoring معیارها را از کانتینر vLLM روی پورت ۸۰۰۰ استخراج میکند. میتوانید به Google Cloud Console Monitoring -> Dashboards بروید تا معیارهایی مانند تأخیر تولید توکن، طول صف و میزان استفاده از حافظه نهان KV را به صورت بومی مشاهده کنید.
۷. تمیز کردن
- با اجرای دستور زیر منابع را حذف کنید.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- زیرساخت را با دستور زیر پاکسازی کنید، برای تأیید،
yesرا تایپ کنید
terraform destroy
۸. تبریک
شما با موفقیت یک محیط DRANET مدیریتشده را روی GKE Autopilot مستقر کردهاید، سختافزار TPU v6e را به صورت پویا آمادهسازی کردهاید و مدل عظیم ۳۱ میلیارد پارامتری Gemma 4 را با استفاده از vLLM ارائه دادهاید.
با استفاده از GKE Autopilot، به Kubernetes اجازه میدهید تا تأمین گرههای زیربنایی و مدیریت زیرساخت را مدیریت کند و به شما امکان میدهد تا کاملاً بر استقرار بار کاری هوش مصنوعی خود تمرکز کنید.
مراحل بعدی / اطلاعات بیشتر
میتوانید درباره شبکهسازی GKE بیشتر بخوانید
آزمایشگاه بعدی خود را انجام دهید
به جستجوی خود با Google Cloud ادامه دهید و این آزمایشگاههای دیگر Google Cloud را بررسی کنید: