
1. Présentation
Cet atelier vous présente l'infrastructure d'IA qui peut être utilisée pour exécuter des charges de travail d'IA. Vous allez travailler avec les éléments suivants :
Google Kubernetes Engine (GKE) : plate-forme d'orchestration de conteneurs de base.
DRANET géré par GKE : mise en réseau avec allocation dynamique des ressources qui attribue directement des fabrics d'interconnexion haut débit à vos pods TPU.
Tensor Processing Unit (TPU) : puces d'accélération conçues sur mesure par Google.
Pour configurer, vous allez déployer un VPC personnalisé et un cluster GKE Autopilot. Pour activer DRANET géré, vous devez créer une ComputeClass et un modèle de demande de ressource. Vous allez ensuite déployer une charge de travail qui utilise vLLM, Hugging Face, ComputeClass et resource claim template. Enfin, vous testerez la configuration réseau et la connectivité au modèle Gemma 4.
Les configurations utiliseront une combinaison de Terraform, gcloud et kubectl.
Dans cet atelier, vous allez apprendre à effectuer la tâche suivante :
- Configurer un réseau VPC
- Configurer un cluster GKE Autopilot
- Créez ComputeClass et ResourceClaimTemplate.
- Créer un déploiement qui exécute des TPU, vLLM, la surveillance et Gemma 4 via Hugging Face
- Tester la connectivité au LLM
Dans cet atelier, vous allez créer le modèle suivant.
Figure 1. 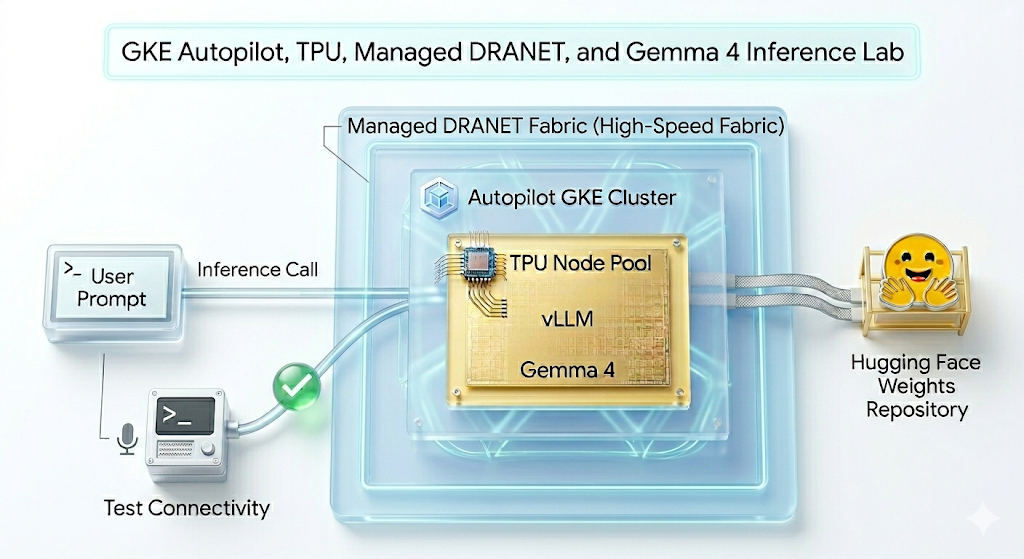
2. Configurer les services Google Cloud
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Configurer l'environnement avec Terraform
Pour suivre cet atelier, vous devez avoir accès aux TPU. La version exacte utilisée est TPU v6e.
- Pour y accéder, vous devez suivre le document sur le plan TPU et activer le quota TPU.
- Nous utilisons un petit déploiement nécessitant quatre puces TPU v6e (
ct6e-standard-4t), qui sera une tranche 2x2 dans une seule région). - Jeton Hugging Face : un jeton d'accès est nécessaire pour télécharger les poids du modèle Gemma.
Nous allons créer un VPC personnalisé avec des règles de pare-feu, un sous-réseau, puis un cluster Autopilot. Ouvrez la console Cloud et sélectionnez le projet que vous allez utiliser.
- Ouvrez Cloud Shell en haut à droite de la console. Assurez-vous que le bon ID de projet s'affiche dans Cloud Shell, puis confirmez les éventuelles invites pour autoriser l'accès.

- Créez un dossier nommé
gke-auto-tpuet accédez-y.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Ajoutez maintenant des fichiers de configuration. Cela créera les fichiers terraform.tfvars, variables.tf et net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Assurez-vous d'être dans le répertoire gke-auto-tpu, puis exécutez les commandes suivantes :
terraform initinitialise le répertoire de travail. Il s'agit de la première étape, qui consiste à télécharger les fournisseurs requis pour la configuration donnée.terraform plan -outgénère un plan d'exécution, qui indique les actions que Terraform effectuera pour déployer votre infrastructure.-outvous permet d'enregistrer le plan d'exécution dans un binaire nommé. Vous pouvez voir ce qui se passera sans apporter de modifications.terraform applyexécute les mises à jour.
terraform init
terraform plan -out vpc
- Maintenant, exécutez le déploiement après avoir exécuté
terraform apply. Étant donné que vous appliquez le plan d'exécution enregistré, il s'exécutera immédiatement sans demander de confirmation (cela peut prendre entre 6 et 10 minutes).
terraform apply vpc
- Vérifier la configuration
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Créer un modèle de classe de calcul et de revendication de ressources
Nous devons créer une ressource ComputeClass personnalisée pour définir la configuration du pool de nœuds. Dans notre cas, nous utiliserons les puces TPU v6e (ct6e-standard-4t)) et les réseaux DRANET gérés.
- Connectez-vous au cluster que vous avez créé. (PS : Remplacez la région par celle dans laquelle vous avez déployé votre cluster.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Assurez-vous de vous trouver dans le répertoire
gke-auto-tpu, puis exécutez les commandes suivantes. Cela crée le fichier manifeste ComputeClass. Notez que si vous avez utilisé une autre région, vous devez remplacer les informations de zone par une zone de la région de votre cluster.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Créez maintenant la ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- Dans le répertoire
gke-auto-tpu, exécutez les commandes ci-dessous. Cela crée le fichier manifeste ResourceClaimTemplate qui est compatible avec les périphériques réseau non RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Créez maintenant le ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Créer votre secret
- Cet atelier utilise google/gemma-4-31B-it . Vous devez donc créer un jeton HF. Remplacez
YOUR_ACTUAL_HUGGING_FACE_TOKENci-dessous par votre jeton.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Assurez-vous d'être dans le répertoire
gke-auto-tpu, puis exécutez les commandes suivantes.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Déployer les charges de travail vLLM et Gemma
Cette configuration utilise ComputeClass pour provisionner automatiquement le matériel et le réseau requis (TPU v6e et DRANET géré). Elle utilise ResourceClaimTemplate pour définir un blueprint permettant de demander l'accès à ce réseau haut débit, ainsi qu'un déploiement qui les lie en générant des revendications de réseau individuelles pour chaque pod à mesure de sa mise à l'échelle.
- Assurez-vous d'être dans le répertoire
gke-auto-tpuet exécutez la commande suivante.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Créez le déploiement.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Pour surveiller l'état d'exécution, exécutez les commandes suivantes. Les pods attendront que le nœud soit provisionné avant de pouvoir continuer. Cela peut prendre 13 minutes ou plus.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Une fois le nœud créé et le pod planifié, vous pouvez exécuter la commande pour afficher les journaux des pods. (PS : Vous pouvez ajouter l'indicateur**
-f** **pour le streaming**.) Cette opération prendra au moins **15 minutes**. Si vous surveillez les journaux, le modèle est prêt à être diffusé lorsque la chaîne(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKs'affiche.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Une fois le déploiement disponible, vous pouvez vérifier que la mise en réseau haut débit est correctement associée à vos pods TPU. Exécutez la commande suivante :
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Éléments à rechercher : vous devriez voir l'interface standard eth0 ainsi que des interfaces supplémentaires telles que eth1 à ethxx.
Ces interfaces supplémentaires confirment que le réseau DRANET géré à haut débit est correctement associé à votre pod.
6. Interagir avec le modèle d'IA à l'aide de curl
Pour vérifier le modèle gemma-4-31B que vous avez déployé, configurez le transfert de port du service vers votre ordinateur local.
- Exécutez la commande suivante dans votre Cloud Shell actuel :
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Ouvrez une autre fenêtre Cloud Shell pour le même projet afin de discuter avec votre modèle à l'aide de
curl. Cette commande envoie une requête et diffuse la sortie directement dans votre terminal.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Examiner la réponse de votre modèle
Observabilité
Étant donné que nous avons appliqué la ressource personnalisée PodMonitoring, Cloud Monitoring récupère les métriques du conteneur vLLM sur le port 8000. Vous pouvez accéder à la console Google Cloud Monitoring > Tableaux de bord pour afficher de manière native des métriques telles que la latence de génération de jetons, la longueur de la file d'attente et l'utilisation du cache KV.
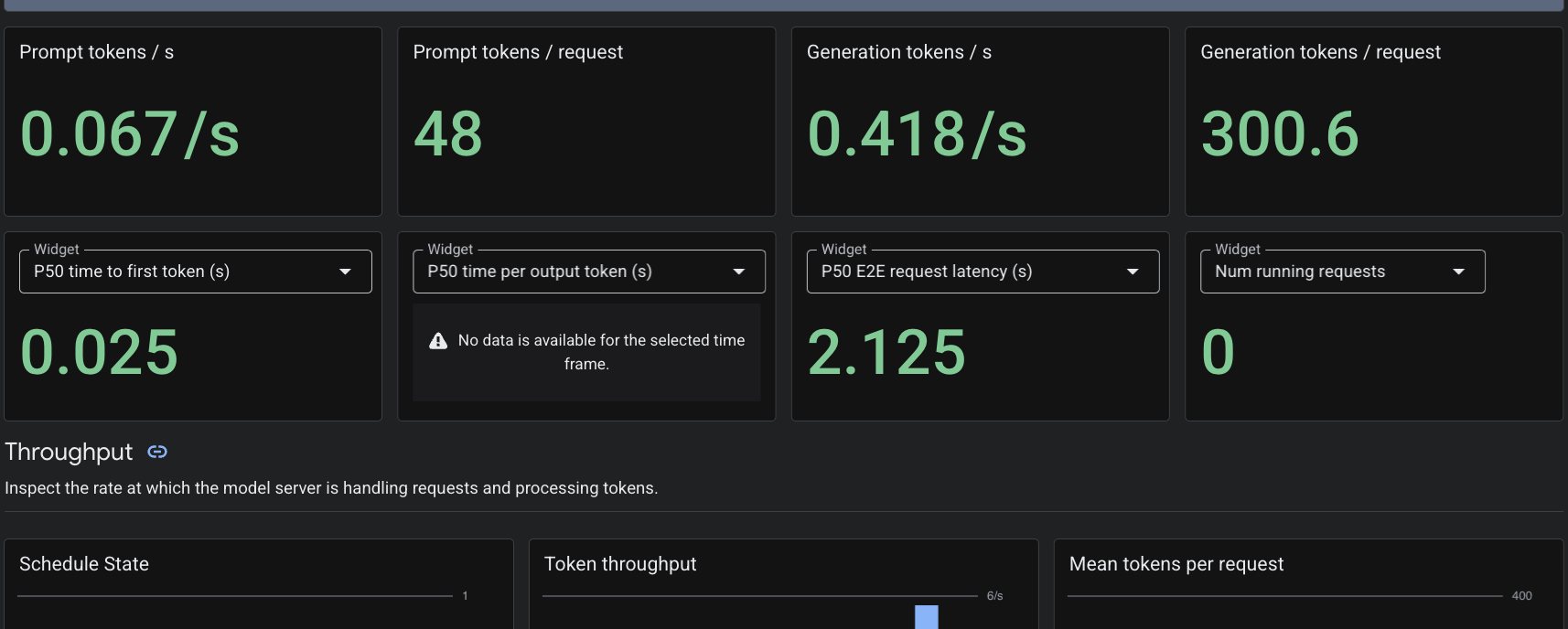
7. Effectuer un nettoyage
- Supprimez les ressources en exécutant la commande suivante.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Nettoyez l'infrastructure à l'aide de la commande suivante, puis saisissez
yespour confirmer.
terraform destroy
8. Félicitations
Vous avez déployé un environnement DRANET géré sur GKE Autopilot, provisionné du matériel TPU v6e de manière dynamique et diffusé le modèle Gemma 4 de 31 milliards de paramètres à l'aide de vLLM.
En utilisant GKE Autopilot, vous permettez à Kubernetes de gérer le provisionnement des nœuds et la gestion de l'infrastructure sous-jacente, ce qui vous permet de vous concentrer entièrement sur le déploiement de votre charge de travail d'IA.
Étapes suivantes et informations supplémentaires
Pour en savoir plus sur la mise en réseau GKE
Atelier suivant
Continuez sur votre lancée avec Google Cloud et découvrez ces autres ateliers Google Cloud :