
1. סקירה כללית
בשיעור ה-Lab הזה נציג תשתית AI שאפשר להשתמש בה להרצת עומסי עבודה של AI. תעבדו עם הרכיבים הבאים:
Google Kubernetes Engine (GKE) – פלטפורמת בסיס לתזמור קונטיינרים.
GKE managed DRANET – רשת דינמית להקצאת משאבים שמקצה ישירות רשתות מהירות של חיבורים הדדיים ל-TPU pods.
Tensor Processing Unit (TPU) – שבבי האצה בהתאמה אישית של Google.
כדי להגדיר, תפרסו VPC בהתאמה אישית ואשכול GKE במצב Autopilot. כדי להפעיל DRANET מנוהל, תיצרו ComputeClass ותבנית Resource Claim. לאחר מכן תפרסו עומס עבודה שמשתמש ב-vLLM, ב-Hugging Face, ב-ComputeClass וב-תבנית Resource Claim. לבסוף, תבדקו את הגדרת הרשת ואת הקישוריות למודל Gemma 4.
ההגדרות ישתמשו בשילוב של Terraform, gcloud ו-kubectl.
בשיעור ה-Lab הזה תלמדו איך לבצע את המשימה הבאה:
- הגדרת רשת VPC
- הגדרת אשכול GKE Autopilot
- יוצרים ComputeClass ו-ResourceClaimTemplate.
- יצירת פריסה שמריצה TPU, vLLM, ניטור ו-Gemma 4 באמצעות Hugging Face
- בדיקת הקישוריות ל-LLM
בשיעור ה-Lab הזה תיצרו את התבנית הבאה.
איור 1. 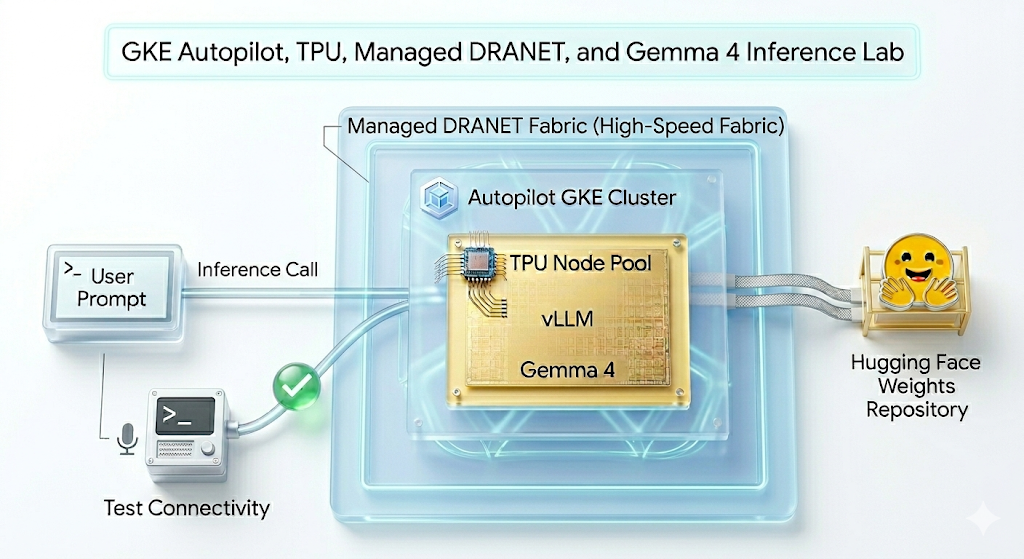
2. הגדרה של שירותי Google Cloud
הגדרת סביבה בקצב אישי
- נכנסים ל-מסוף Google Cloud ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.

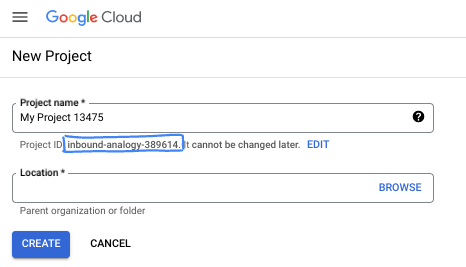
- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. זו מחרוזת תווים שלא נמצאת בשימוש ב-Google APIs. תמיד אפשר לעדכן את המיקום.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud ואי אפשר לשנות אותו אחרי שהוא מוגדר. מסוף Cloud יוצר באופן אוטומטי מחרוזת ייחודית, ובדרך כלל לא צריך לדעת מה היא. ברוב המדריכים המעשיים, תצטרכו להפנות למזהה הפרויקט (בדרך כלל מסומן כ-
PROJECT_ID). אם אתם לא אוהבים את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר. אפשר גם לנסות כתובת משלכם ולבדוק אם היא זמינה. אי אפשר לשנות את ההגדרה הזו אחרי השלב הזה, והיא נשארת לאורך הפרויקט. - לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. מידע נוסף על שלושת הערכים האלה מופיע במאמרי העזרה.
- לאחר מכן, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבי Cloud או בממשקי API. ההשתתפות ב-codelab הזה לא תעלה לכם הרבה, אם בכלל. כדי להשבית את המשאבים ולמנוע חיובים מעבר למדריך הזה, אתם יכולים למחוק את המשאבים שיצרתם או למחוק את הפרויקט. משתמשים חדשים ב-Google Cloud זכאים להשתתף בתוכנית תקופת הניסיון בחינם בסך 300$.
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, יופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. הגדרת סביבה באמצעות Terraform
כדי לבצע את ה-Lab הזה, אתם צריכים גישה ל-TPU. הגרסה המדויקת שבה נעשה שימוש היא TPU v6e.
- כדי לקבל גישה, צריך לפעול לפי מסמך התוכנית של TPU ולהפעיל את מכסת TPU.
- אנחנו משתמשים בפריסה קטנה שדורשת 4 שבבי TPU v6e (
ct6e-standard-4t)שהם 2x2 slice באזור יחיד. - Hugging Face Token: נדרש Access Token כדי להוריד את משקלי המודל של Gemma
ניצור VPC בהתאמה אישית עם כללים של חומת אש, רשת משנה ואז אשכול טייס אוטומטי. פותחים את מסוף Cloud ובוחרים את הפרויקט שבו רוצים להשתמש.
- פותחים את Cloud Shell בפינה השמאלית העליונה של המסוף, מוודאים שמופיע מזהה הפרויקט הנכון ב-Cloud Shell ומאשרים את כל ההנחיות למתן גישה.

- צור תיקייה בשם
gke-auto-tpuועבור לתיקייה
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- עכשיו מוסיפים קובצי הגדרה. הפעולות האלה ייצרו את הקבצים הבאים: terraform.tfvars , variables.tf, net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- מוודאים שאתם בספרייה gke-auto-tpu ומריצים את הפקודות הבאות
terraform initכדי להפעיל את ספריית העבודה. זה השלב הראשון, ובמהלכו מורידים את הספקים שנדרשים להגדרות שצוינו.הפקודהterraform plan -outיוצרת תוכנית ביצוע שמראה אילו פעולות Terraform תבצע כדי לפרוס את התשתית. הפקודה-outמאפשרת לשמור את תוכנית הביצוע בקובץ בינארי עם שם. תוכלו לראות מה יקרה בלי לבצע שינויים.terraform applyמפעיל את העדכונים.
terraform init
terraform plan -out vpc
- עכשיו מריצים את הפריסה אחרי שמריצים את
terraform apply. מכיוון שמחילים את תוכנית ההרצה שנשמרה, היא תורץ באופן מיידי בלי לבקש אישור (הפעולה הזו עשויה להימשך בין 6 ל-10 דקות).
terraform apply vpc
- אימות ההגדרה
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. יצירת Compute Class ותבנית Resource Claim
צריך ליצור משאב מותאם אישית של ComputeClass כדי להגדיר את התצורה של מאגר הצמתים. במקרה שלנו, נשתמש בשבבי TPU v6e (ct6e-standard-4t)) וברשתות DRANET מנוהלות.
- מתחברים לאשכול שיצרתם. (נ.ב. צריך לשנות את האזור לאזור שבו פרסתם את האשכול).
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- מוודאים שאתם נמצאים בספרייה
gke-auto-tpuומריצים את הפקודות הבאות. הפעולה הזו יוצרת את מניפסט ComputeClass. חשוב לשים לב: אם השתמשתם באזור אחר, אתם צריכים לשנות את פרטי האזור לאזור בתוך האזור של האשכול
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- עכשיו יוצרים את ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- בספרייה
gke-auto-tpuמריצים את הפקודות הבאות. הפעולה הזו יוצרת את מניפסט ResourceClaimTemplate שתומך במכשירי רשת שאינם RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- עכשיו יוצרים את ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
יצירת סוד
- במעבדה הזו נעשה שימוש ב-google/gemma-4-31B-it , ולכן צריך ליצור אסימון HF. מחליפים את
YOUR_ACTUAL_HUGGING_FACE_TOKENלמטה באסימון בפועל.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- מוודאים שאתם נמצאים בספרייה
gke-auto-tpuומריצים את הפקודות הבאות.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. פריסת עומס העבודה vLLM ו-Gemma
במסגרת ההגדרה הזו נעשה שימוש ב-ComputeClass כדי להקצות באופן אוטומטי את החומרה והרשת הנדרשות (TPU v6e ו-DRANET מנוהל). נעשה שימוש ב-ResourceClaimTemplate כדי להגדיר תוכנית לבקשת גישה לרשת המהירה הזו, ופריסה שמקשרת ביניהם על ידי יצירת תביעות רשת נפרדות לכל pod כשהם גדלים.
- מוודאים שאתם נמצאים בספרייה
gke-auto-tpuומריצים את הפקודה הבאה.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- יוצרים את הפריסה.
kubectl apply -f gem4-auto-dra-tpu.yaml
- כדי לעקוב אחרי סטטוס הסיום, מריצים את הפקודות הבאות. הפודים ימתינו עד שהצומת יוקצה לפני שיוכלו להמשיך. התהליך הזה עשוי להימשך 13 דקות ומעלה.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- אחרי שיוצרים את הצומת ומקצים את הפוד, אפשר להריץ את הפקודה כדי לראות את היומנים של הפודים. (נ.ב. אפשר להוסיף את הדגל **
-f** כדי להפעיל סטרימינג). התהליך יימשך עד **15 דקות ומעלה** אם צופים ביומנים כשרואים את המחרוזת(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKthe model is ready to serve.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- אחרי שהפריסה זמינה, אפשר לוודא שהרשת המהירה מחוברת בצורה תקינה ל-TPU pods. מריצים את הפקודה הבאה:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
מה לחפש: אמורים להופיע מאפיינים רגילים eth0 לצד ממשקי תוספים כמו eth1 עד ethxx.
הממשקים הנוספים האלה מאשרים שרשת ה-DRANET המנוהלת במהירות גבוהה מצורפת בהצלחה ל-Pod.
6. אינטראקציה עם מודל AI באמצעות curl
כדי לאמת את מודל gemma-4-31B שפרסתם, צריך להגדיר העברת ליציאה אחרת מהשירות למחשב המקומי.
- מריצים את הפקודה הבאה ב-Cloud Shell הנוכחי:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- עכשיו פותחים חלון נוסף של Cloud Shell לאותו פרויקט כדי לשוחח עם המודל באמצעות
curl. הפקודה הזו שולחת הנחיה ומשדרת את הפלט ישירות לטרמינל.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- בדיקת התשובה מהמודל
ניראות (observability)
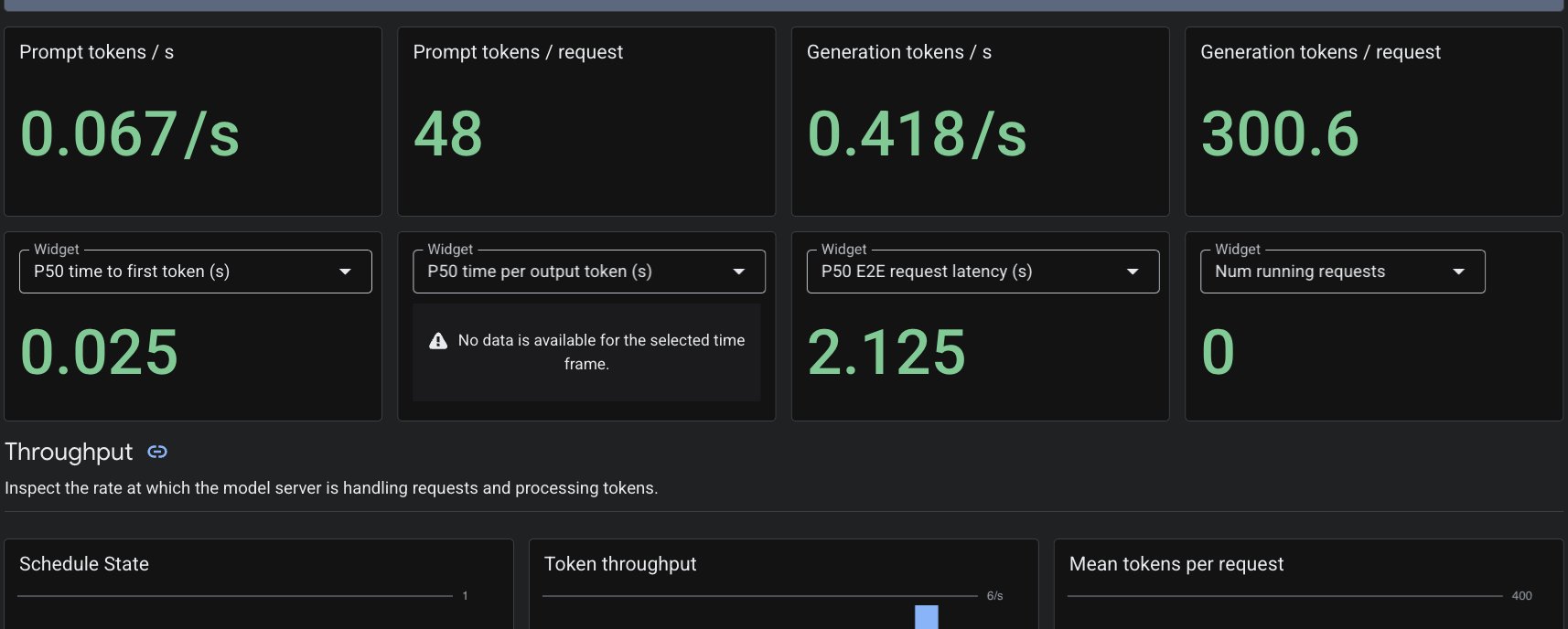
מאחר שהשתמשנו במשאב המותאם אישית PodMonitoring, Cloud Monitoring יאסוף מדדים ממכולת vLLM ביציאה 8000. אפשר לעבור אל מסוף Google Cloud Monitoring -> Dashboards כדי לראות מדדים כמו זמן האחזור של יצירת טוקנים, אורך התור והשימוש במטמון KV באופן מקורי.
7. הסרת המשאבים
- מריצים את הפקודה הבאה כדי למחוק את המשאבים.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- מנקים את התשתית באמצעות הפקודה הבאה, מקלידים
yesכדי לאשר
terraform destroy
8. מזל טוב
הצלחתם לפרוס סביבת DRANET מנוהלת ב-GKE Autopilot, להקצות באופן דינמי חומרת TPU v6e ולמלא בקשות באמצעות מודל Gemma 4 עם 31 מיליארד פרמטרים באמצעות vLLM.
שימוש ב-GKE Autopilot מאפשר ל-Kubernetes לטפל בהקצאת הצמתים הבסיסית ובניהול התשתית, כך שתוכלו להתמקד לחלוטין בפריסת עומס העבודה של ה-AI.
השלבים הבאים / מידע נוסף
אל שיעור ה-Lab הבא
אתם יכולים להמשיך את יחידת ה-Quest ב-Google Cloud או לנסות את שיעורי ה-Lab הבאים של Google Cloud: