
1. खास जानकारी
इस लैब में, आपको एआई इन्फ़्रास्ट्रक्चर के बारे में बताया जाएगा. इसका इस्तेमाल, एआई वर्कलोड को चलाने के लिए किया जा सकता है. आपको इन चीज़ों के साथ काम करना होगा:
Google Kubernetes Engine (GKE) - यह कंटेनर आयोजन सेवाओं का बुनियादी प्लैटफ़ॉर्म है.
GKE मैनेज किया गया DRANET - यह डाइनैमिक रिसोर्स ऐलोकेशन नेटवर्किंग है. यह आपके टीपीयू पॉड को सीधे तौर पर हाई-स्पीड इंटरकनेक्ट फ़ैब्रिक असाइन करता है.
टेंसर प्रोसेसिंग यूनिट (टीपीयू) - Google के कस्टम-बिल्ट ऐक्सलरेटर चिप.
आपको कस्टम वीपीसी और ऑटोपायलट GKE क्लस्टर डिप्लॉय करना है. मैनेज किए गए DRANET को चालू करने के लिए, ComputeClass और ResourceClaimTemplate बनाया जाएगा. इसके बाद, आपको एक ऐसा वर्कलोड डिप्लॉय करना होगा जो vLLM, Hugging Face, ComputeClass, और resource claim template का इस्तेमाल करता हो. आखिर में, आपको नेटवर्किंग सेटअप और Gemma 4 मॉडल से कनेक्टिविटी की जांच करनी होगी.
कॉन्फ़िगरेशन में Terraform, gcloud, और kubectl का इस्तेमाल किया जाएगा.
इस लैब में, आपको यह टास्क पूरा करने का तरीका बताया जाएगा:
- वीपीसी नेटवर्क सेट अप करना
- GKE Autopilot क्लस्टर सेट अप करना
- ComputeClass और ResourceClaimTemplate बनाएं.
- Hugging Face के ज़रिए, टीपीयू, vLLM, मॉनिटरिंग, और Gemma 4 को चलाने वाला डिप्लॉयमेंट बनाना
- एलएलएम से कनेक्टिविटी की जांच करना
इस लैब में, आपको यह पैटर्न बनाना है.
पहली इमेज. 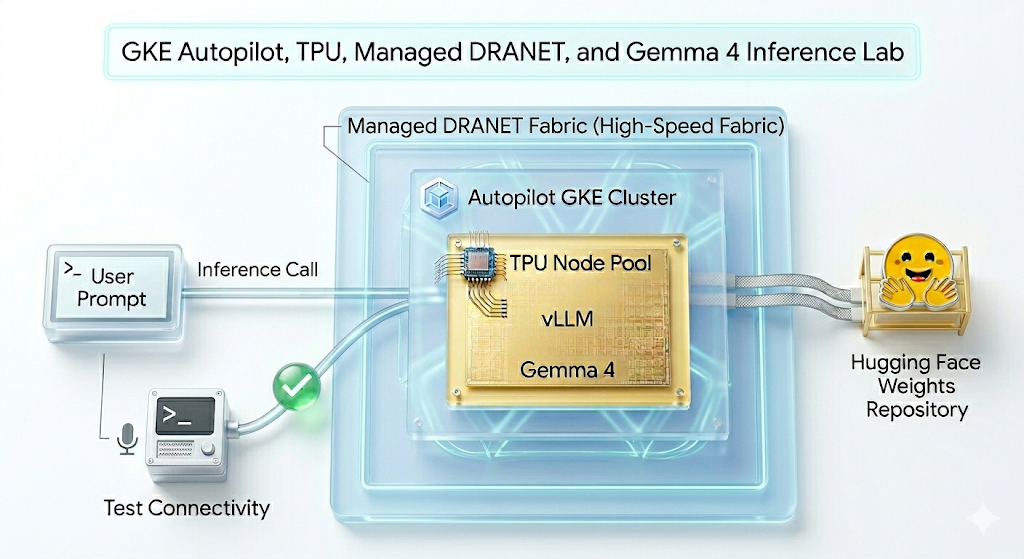
2. Google Cloud की सेवाओं का सेटअप
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

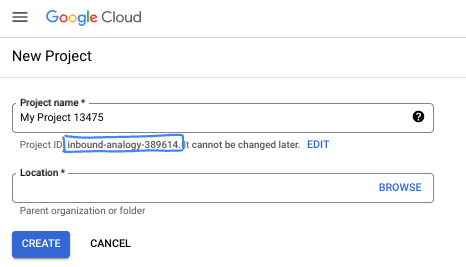
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग की सुविधा चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मुफ़्त में आज़माने का प्रोग्राम मिलता है.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. Terraform की मदद से एनवायरमेंट सेट अप करना
इस लैब को पूरा करने के लिए, आपके पास टीपीयू का ऐक्सेस होना चाहिए. इस्तेमाल किया गया वर्शन, टीपीयू v6e है.
- ऐक्सेस पाने के लिए, आपको टीपीयू प्लान के दस्तावेज़ में दिए गए निर्देशों का पालन करना होगा. साथ ही, टीपीयू कोटा चालू करना होगा.
- हम एक छोटा डिप्लॉयमेंट इस्तेमाल कर रहे हैं. इसके लिए, 4 टीपीयू v6e चिप की ज़रूरत होती है.
ct6e-standard-4t)यह एक ही क्षेत्र में 2x2 स्लाइस होगा. - Hugging Face टोकन: Gemma मॉडल के वेट डाउनलोड करने के लिए, ऐक्सेस टोकन ज़रूरी है
हम फ़ायरवॉल के नियमों, सबनेट, और फिर ऑटोपायलट क्लस्टर के साथ एक कस्टम वीपीसी बनाएंगे. क्लाउड कंसोल खोलें और वह प्रोजेक्ट चुनें जिसका आपको इस्तेमाल करना है.
- अपनी कंसोल के सबसे ऊपर दाईं ओर मौजूद Cloud Shell खोलें. पक्का करें कि आपको Cloud Shell में सही प्रोजेक्ट आईडी दिख रहा हो. साथ ही, ऐक्सेस की अनुमति देने के लिए दिए गए किसी भी प्रॉम्प्ट की पुष्टि करें.

gke-auto-tpuनाम का फ़ोल्डर बनाओ और उसमें ले जाओ
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- अब कुछ कॉन्फ़िगरेशन फ़ाइलें जोड़ें. इनसे terraform.tfvars , variables.tf, net.tf फ़ाइल बन जाएगी.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- पक्का करें कि आप gke-auto-tpu डायरेक्ट्री में हों और यहां दी गई कमांड चलाएं
terraform initइससे वर्किंग डायरेक्ट्री शुरू होती है. यह पहला चरण है. इसमें दिए गए कॉन्फ़िगरेशन के लिए ज़रूरी प्रोवाइडर डाउनलोड किए जाते हैं.terraform plan -outएक एक्ज़ीक्यूशन प्लान जनरेट करता है. इससे पता चलता है कि Terraform, आपके इन्फ़्रास्ट्रक्चर को डिप्लॉय करने के लिए कौनसी कार्रवाइयां करेगा.-outकी मदद से, एक्ज़ीक्यूशन प्लान को नाम वाले बाइनरी में सेव किया जा सकता है. इससे आपको यह पता चल जाएगा कि बदलाव किए बिना क्या होगा.terraform applyअपडेट चलाता है.
terraform init
terraform plan -out vpc
- अब
terraform applyचलाने के बाद, डिप्लॉयमेंट चलाएं. सेव किए गए एक्ज़ीक्यूशन प्लान को लागू किया जा रहा है. इसलिए, यह पुष्टि के लिए कहे बिना तुरंत लागू हो जाएगा (इसमें 6 से 10 मिनट लग सकते हैं)
terraform apply vpc
- सेट अप की पुष्टि करना
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. ComputeClass और ResourceClaimTemplate बनाना
हमें नोड पूल के कॉन्फ़िगरेशन को तय करने के लिए, कस्टम ComputeClass संसाधन बनाना होगा. इस मामले में, हम टीपीयू v6e चिप (ct6e-standard-4t) और मैनेज किए गए DRANET नेटवर्क का इस्तेमाल करेंगे.
- उस क्लस्टर से कनेक्ट करें जिसे आपने बनाया है. (ध्यान दें: क्षेत्र को उस क्षेत्र में बदलें जहां आपने अपना क्लस्टर डिप्लॉय किया है.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- पक्का करें कि आप
gke-auto-tpuडायरेक्ट्री में हों और ये कमांड चलाएं. इससे ComputeClass मेनिफ़ेस्ट बनता है. कृपया ध्यान दें कि अगर आपने किसी दूसरे क्षेत्र का इस्तेमाल किया है, तो आपको ज़ोन की जानकारी को अपने क्लस्टर के क्षेत्र के ज़ोन में बदलना होगा
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- अब ComputeClass बनाएं.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
gke-auto-tpuडायरेक्ट्री में, यहां दी गई कमांड चलाएं. इससे ResourceClaimTemplate मेनिफ़ेस्ट बनता है. यह नॉन-आरडीएमए नेटवर्क डिवाइसों के साथ काम करता है.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- अब ResourceClaimTemplate बनाएं.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
अपना सीक्रेट बनाएं
- इस लैब में google/gemma-4-31B-it का इस्तेमाल किया जाता है. इसलिए, आपको एक एचएफ़ टोकन बनाना होगा. नीचे दिए गए
YOUR_ACTUAL_HUGGING_FACE_TOKENको अपने असल टोकन से बदलें.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- पक्का करें कि आप
gke-auto-tpuडायरेक्ट्री में हों और ये कमांड चलाएं.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. vLLM और Gemma को डिप्लॉय करना
इस सेटअप में, ComputeClass का इस्तेमाल करके ज़रूरी हार्डवेयर और नेटवर्किंग (TPU v6e और मैनेज किया गया DRANET) को अपने-आप उपलब्ध कराया जाता है. इसमें ResourceClaimTemplate का इस्तेमाल करके, तेज़ स्पीड वाले नेटवर्क का ऐक्सेस पाने के लिए ब्लूप्रिंट तय किया जाता है. साथ ही, एक डिप्लॉयमेंट का इस्तेमाल किया जाता है, जो उन्हें एक साथ जोड़ता है. इसके लिए, हर पॉड के लिए अलग-अलग नेटवर्क के दावे जनरेट किए जाते हैं, ताकि उन्हें स्केल किया जा सके.
- पक्का करें कि आप
gke-auto-tpuडायरेक्ट्री में हों और यह कमांड चलाएं.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- डिप्लॉयमेंट बनाएं.
kubectl apply -f gem4-auto-dra-tpu.yaml
- पूरा होने की स्थिति को मॉनिटर करने के लिए, यहां दिए गए निर्देश चलाएं. पॉड तब तक इंतज़ार करेंगे, जब तक नोड उपलब्ध नहीं हो जाता. इसमें 13 मिनट से ज़्यादा लग सकते हैं.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- नोड बनाने और पॉड शेड्यूल करने के बाद, पॉड के लॉग देखने के लिए कमांड चलाई जा सकती है. (p.s.**
-f** **फ़्लैग को स्ट्रीमिंग के लिए जोड़ा जा सकता है**). अगर(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKस्ट्रिंग दिखने पर लॉग देखे जा रहे हैं, तो इसे पूरा होने में **15 मिनट से ज़्यादा** लग सकते हैं.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- डप्लॉयमेंट उपलब्ध होने के बाद, यह पुष्टि की जा सकती है कि हाई-स्पीड नेटवर्किंग, आपके टीपीयू पॉड से सही तरीके से जुड़ी है. यह कमांड चलाएं:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
क्या देखना है: आपको ethxx से लेकर eth1 जैसे अतिरिक्त इंटरफ़ेस के साथ-साथ स्टैंडर्ड eth0 दिखना चाहिए.
इन अतिरिक्त इंटरफ़ेस से यह पुष्टि होती है कि हाई-स्पीड मैनेज किए गए DRANET फ़ैब्रिक को आपके पॉड से अटैच कर दिया गया है.
6. curl का इस्तेमाल करके, एआई मॉडल के साथ इंटरैक्ट करना
तैनात किए गए gemma-4-31B मॉडल की पुष्टि करने के लिए, सेवा से अपनी लोकल मशीन पर पोर्ट फ़ॉरवर्डिंग सेट अप करें.
- इसे अपने मौजूदा Cloud Shell में चलाएं:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- अब उसी प्रोजेक्ट के लिए, एक और Cloud Shell विंडो खोलें. इसके बाद,
curlका इस्तेमाल करके अपने मॉडल से चैट करें. इस कमांड से एक प्रॉम्प्ट भेजा जाता है और आउटपुट को सीधे आपके टर्मिनल पर स्ट्रीम किया जाता है.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- अपने मॉडल से मिले जवाब को देखें
जांचने की क्षमता
हमने PodMonitoring कस्टम रिसॉर्स लागू किया है. इसलिए, Cloud Monitoring, पोर्ट 8000 पर vLLM कंटेनर से मेट्रिक स्क्रैप करेगा. टोकन जनरेट होने में लगने वाला समय, कतार की लंबाई, और KV कैश के इस्तेमाल जैसी मेट्रिक को नेटिव तौर पर देखने के लिए, Google Cloud Console Monitoring -> Dashboards पर जाएं.
7. व्यवस्थित करें
- नीचे दिए गए कमांड को चलाकर संसाधनों को मिटाएं.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- नीचे दिए गए कमांड का इस्तेमाल करके, इंफ़्रास्ट्रक्चर को क्लीन अप करें. पुष्टि करने के लिए,
yesटाइप करें
terraform destroy
8. बधाई हो
आपने GKE Autopilot पर मैनेज किया गया DRANET एनवायरमेंट डिप्लॉय कर लिया है. साथ ही, टीपीयू v6e हार्डवेयर को डाइनैमिक तरीके से उपलब्ध करा दिया है. इसके अलावा, vLLM का इस्तेमाल करके, 31 अरब पैरामीटर वाले Gemma 4 मॉडल को इस्तेमाल किया जा सकता है.
GKE Autopilot का इस्तेमाल करने पर, Kubernetes को नोड प्रोविज़निंग और बुनियादी ढांचे को मैनेज करने की अनुमति मिल जाती है. इससे आपको एआई वर्कलोड को डिप्लॉय करने पर पूरी तरह से फ़ोकस करने में मदद मिलती है.
अगले चरण / ज़्यादा जानें
GKE नेटवर्किंग के बारे में ज़्यादा जानें
अगली लैब पर जाएं
Google Cloud के साथ अपनी क्वेस्ट जारी रखें. साथ ही, Google Cloud के इन अन्य लैब को आज़माएं: