
1. Ringkasan
Lab ini memperkenalkan Anda pada Infrastruktur AI yang dapat digunakan untuk menjalankan workload AI. Anda akan menggunakan hal berikut:
Google Kubernetes Engine (GKE) - Platform orkestrasi container dasar.
GKE managed DRANET - Jaringan Alokasi Resource Dinamis yang langsung menetapkan fabric interkoneksi berkecepatan tinggi ke pod TPU Anda.
Tensor Processing Unit (TPU) - Chip akselerator buatan khusus Google.
Untuk mengonfigurasi, Anda akan men-deploy VPC kustom dan cluster GKE autopilot. Untuk mengaktifkan DRANET terkelola, Anda akan membuat ComputeClass dan Template Klaim Resource. Kemudian, Anda akan men-deploy workload yang menggunakan vLLM, Hugging Face, ComputeClass, dan template klaim resource. Terakhir, Anda akan menguji penyiapan jaringan dan konektivitas ke model Gemma 4.
Konfigurasi akan menggunakan kombinasi Terraform, gcloud, dan kubectl.
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
- Menyiapkan jaringan VPC
- Menyiapkan cluster autopilot GKE
- Membuat ComputeClass dan ResourceClaimTemplate.
- Membuat deployment yang menjalankan TPU, vLLM, pemantauan, dan Gemma 4 melalui Hugging Face
- Menguji konektivitas ke LLM
Di lab ini, Anda akan membuat pola berikut.
Gambar 1. 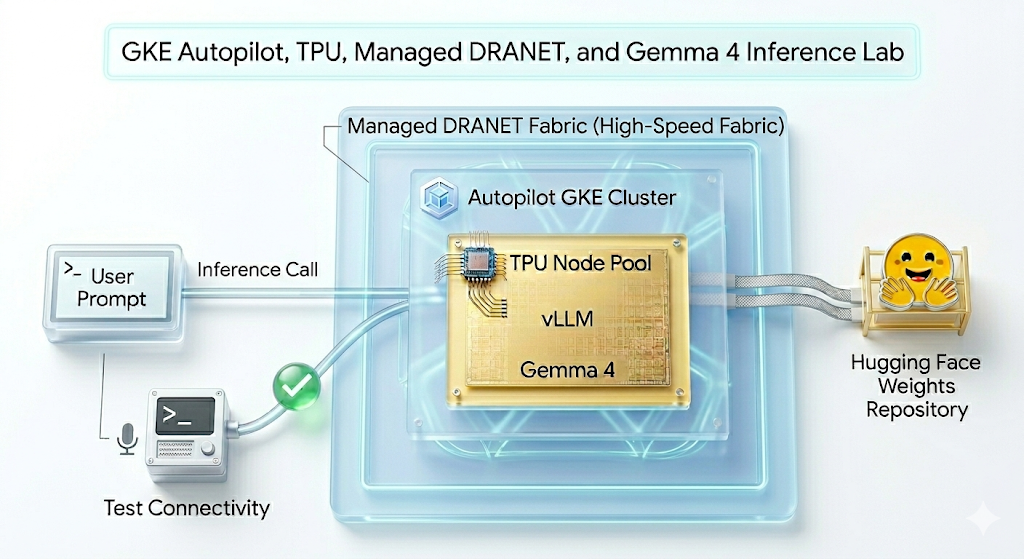
2. Penyiapan layanan Google Cloud
Penyiapan lingkungan mandiri
- Login ke Google Cloud Console dan buat project baru atau gunakan kembali project yang sudah ada. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.

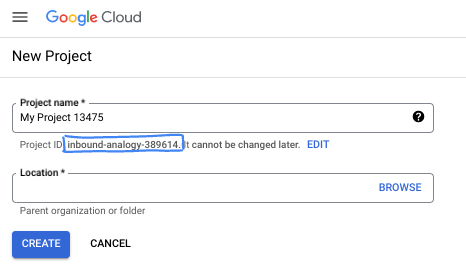
- Project name adalah nama tampilan untuk peserta project ini. String ini adalah string karakter yang tidak digunakan oleh Google API. Anda dapat memperbaruinya kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Cloud Console otomatis membuat string unik; biasanya Anda tidak mementingkan kata-katanya. Di sebagian besar codelab, Anda harus merujuk Project ID-nya (umumnya diidentifikasi sebagai
PROJECT_ID). Jika tidak suka dengan ID yang dibuat, Anda dapat membuat ID acak lainnya. Atau, Anda dapat mencobanya sendiri, dan lihat apakah ID tersebut tersedia. ID tidak dapat diubah setelah langkah ini dan tersedia selama durasi project. - Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
- Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource/API Cloud. Menjalankan operasi dalam codelab ini tidak akan memakan banyak biaya, bahkan mungkin tidak sama sekali. Guna mematikan resource agar tidak menimbulkan penagihan di luar tutorial ini, Anda dapat menghapus resource yang dibuat atau menghapus project-nya. Pengguna baru Google Cloud memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai $300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Konsol Google Cloud, klik ikon Cloud Shell di toolbar kanan atas:
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
3. Menyiapkan lingkungan dengan Terraform
Untuk melakukan lab ini, Anda memerlukan akses ke TPU. Versi yang digunakan adalah TPU v6e.
- Anda harus mengikuti dokumen rencana TPU dan mengaktifkan kuota TPU untuk mendapatkan akses.
- Kami menggunakan deployment kecil yang memerlukan 4 chip TPU v6e (
ct6e-standard-4t)yang akan menjadi slice 2x2 dalam satu region. - Token Hugging Face: Token Akses diperlukan untuk mendownload bobot model Gemma
Kita akan membuat VPC kustom dengan aturan firewall, subnet, lalu cluster autopilot. Buka konsol cloud dan pilih project yang akan Anda gunakan.
- Buka Cloud Shell yang terletak di bagian kanan atas konsol Anda, pastikan Anda melihat project id yang benar di Cloud Shell, konfirmasi perintah apa pun untuk mengizinkan akses.

- Buat folder bernama
gke-auto-tpudan pindah ke folder tersebut
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Sekarang, tambahkan beberapa file konfigurasi. Tindakan ini akan membuat file terraform.tfvars , variables.tf, net.tf berikut.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Pastikan Anda berada di direktori gke-auto-tpu dan jalankan perintah berikut
terraform initMenginisialisasi direktori kerja. Ini adalah langkah pertama dan mendownload penyedia yang diperlukan untuk konfigurasi yang diberikan.terraform plan -outmenghasilkan rencana eksekusi, yang menunjukkan tindakan yang akan dilakukan Terraform untuk men-deploy infrastruktur Anda.-outmemungkinkan Anda menyimpan rencana eksekusi ke program biner bernama. Anda dapat melihat apa yang akan terjadi tanpa melakukan perubahan apa pun.terraform applymenjalankan update.
terraform init
terraform plan -out vpc
- Sekarang, jalankan deployment setelah Anda menjalankan
terraform apply, karena Anda menerapkan rencana eksekusi yang disimpan, deployment akan segera dijalankan tanpa meminta konfirmasi (Proses ini mungkin memerlukan waktu antara 6-10 menit)
terraform apply vpc
- Verifikasi penyiapan
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Membuat Class Komputasi dan Template Klaim Resource
Kita perlu membuat resource ComputeClass kustom untuk menentukan konfigurasi untuk node pool. Dalam kasus ini, kita akan menggunakan chip TPU v6e (ct6e-standard-4t) dan jaringan DRANET terkelola.
- Hubungkan ke cluster yang Anda buat. (p.s. ubah region ke region tempat Anda men-deploy cluster.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Pastikan Anda berada di direktori
gke-auto-tpudan jalankan perintah berikut. Tindakan ini akan membuat manifes ComputeClass. Perhatikan bahwa jika Anda menggunakan region yang berbeda, Anda harus mengubah informasi zona ke zona dalam region cluster Anda
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Sekarang, buat ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- Di direktori
gke-auto-tpu, jalankan perintah berikut di bawah. Tindakan ini akan membuat manifes ResourceClaimTemplate yang mendukung perangkat jaringan non-RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Sekarang, buat ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Membuat secret
- Lab ini menggunakan google/gemma-4-31B-it sehingga Anda perlu membuat token HF. Ganti
YOUR_ACTUAL_HUGGING_FACE_TOKENdi bawah dengan token Anda yang sebenarnya.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Pastikan Anda berada di direktori
gke-auto-tpudan jalankan perintah berikut.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Men-deploy Workload vLLM dan Gemma
Penyiapan ini menggunakan ComputeClass untuk menyediakan hardware dan jaringan yang diperlukan secara otomatis (TPU v6e dan DRANET terkelola). Penyiapan ini menggunakan ResourceClaimTemplate untuk menentukan blueprint guna meminta akses ke jaringan berkecepatan tinggi tersebut, dan deployment yang mengikatnya dengan membuat klaim jaringan individual untuk setiap pod saat pod tersebut diskalakan.
- Pastikan Anda berada di direktori
gke-auto-tpudan jalankan perintah berikut.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Buat deployment.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Untuk memantau status penyelesaian, jalankan perintah berikut. Pod akan menunggu hingga node disediakan sebelum dapat melanjutkan. Proses ini mungkin memerlukan waktu 13+ menit.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Setelah node dibuat dan pod dijadwalkan, Anda dapat menjalankan perintah untuk melihat log pod. (p.s. Anda dapat menambahkan flag **
-f** **untuk streaming**). Proses ini akan memerlukan waktu hingga **15+ menit** untuk diselesaikan jika Anda melihat log saat melihat string(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK, model siap untuk ditayangkan.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Setelah deployment tersedia, Anda dapat memverifikasi bahwa jaringan berkecepatan tinggi terpasang dengan benar ke pod TPU Anda. Jalankan perintah berikut:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Yang harus dicari: Anda akan melihat eth0 standar bersama dengan antarmuka tambahan seperti eth1 melalui ethxx.
Antarmuka tambahan ini mengonfirmasi bahwa fabric DRANET terkelola berkecepatan tinggi berhasil terpasang ke pod Anda.
6. Berinteraksi dengan model AI menggunakan curl
Untuk memverifikasi model gemma-4-31B yang Anda deploy, siapkan penerusan port dari layanan ke mesin lokal Anda.
- Jalankan perintah ini di Cloud Shell Anda saat ini:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Sekarang, buka jendela Cloud Shell tambahan untuk project yang sama untuk melakukan chat dengan model Anda menggunakan
curl. Perintah ini mengirimkan perintah dan melakukan streaming output langsung ke terminal Anda.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Lihat respons dari model Anda
Kemampuan observasi
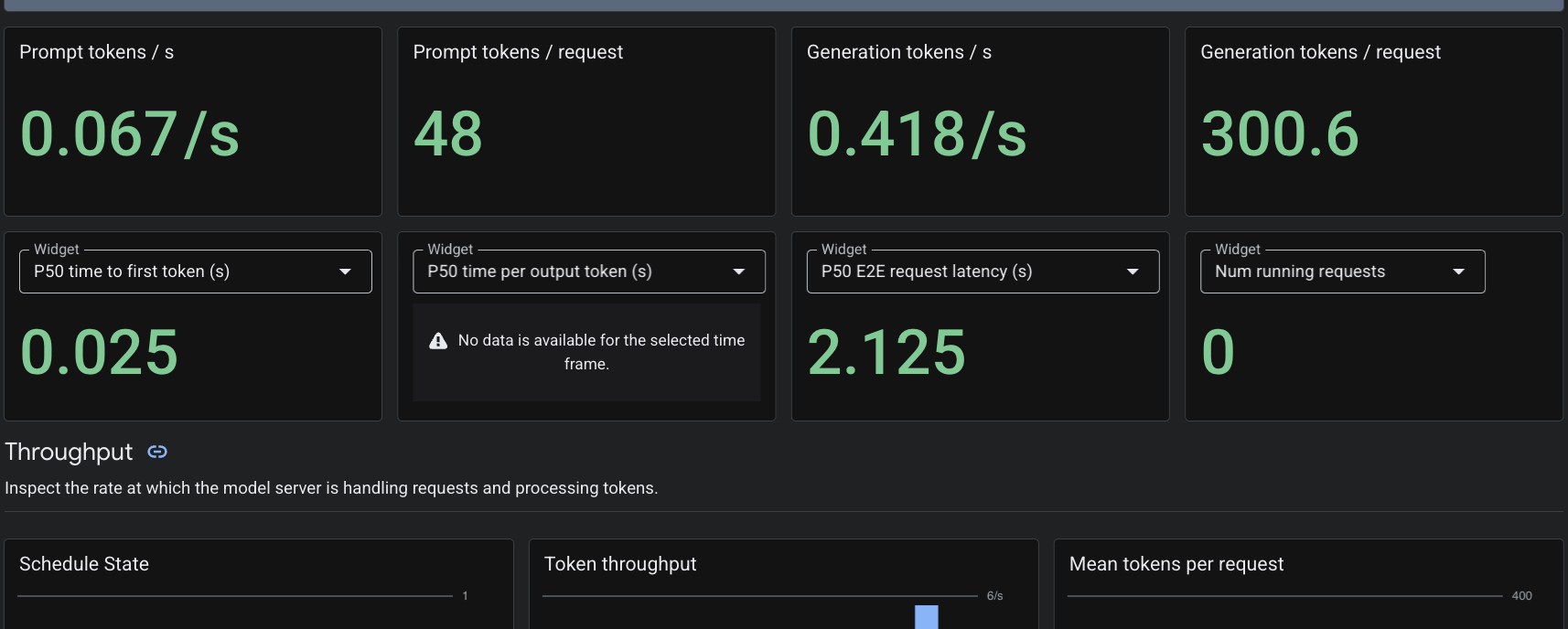
Karena kita menerapkan resource kustom PodMonitoring, Cloud Monitoring akan mengambil metrik dari container vLLM di port 8000. Anda dapat membuka Konsol Google Cloud Monitoring -> Dashboards untuk melihat metrik seperti latensi pembuatan token, panjang antrean, dan penggunaan cache KV secara native.
7. Pembersihan
- Hapus resource dengan menjalankan perintah berikut.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Bersihkan infrastruktur dengan perintah berikut, ketik
yesuntuk mengonfirmasi
terraform destroy
8. Selamat
Anda telah berhasil men-deploy lingkungan DRANET terkelola di GKE Autopilot, menyediakan hardware TPU v6e secara dinamis, dan menayangkan model Gemma 4 dengan parameter 31 miliar menggunakan vLLM.
Dengan menggunakan GKE Autopilot, Anda mengizinkan Kubernetes menangani penyediaan node dan pengelolaan infrastruktur yang mendasarinya, sehingga Anda dapat berfokus sepenuhnya pada deployment workload AI.
Langkah berikutnya / Pelajari lebih lanjut
Anda dapat membaca lebih lanjut tentang jaringan GKE
Ikuti lab berikutnya
Lanjutkan quest Anda dengan Google Cloud, dan lihat lab Google Cloud lainnya: