
1. Panoramica
Questo lab ti introduce all'infrastruttura AI che può essere utilizzata per l'esecuzione di carichi di lavoro AI. Lavorerai con i seguenti elementi:
Google Kubernetes Engine (GKE) : la piattaforma di orchestrazione dei container di base.
**DRANET gestito da GKE** : rete di allocazione dinamica delle risorse che assegna direttamente le infrastrutture di interconnessione ad alta velocità ai pod TPU.
Tensor Processing Unit (TPU) : chip acceleratori personalizzati di Google.
Per la configurazione, eseguirai il deployment di un VPC personalizzato e di un cluster GKE Autopilot. Per abilitare DRANET gestito, creerai un ComputeClass e un modello di richiesta di risorse. Eseguirai quindi il deployment di un carico di lavoro che utilizza vLLM, Hugging Face, ComputeClass e il modello di richiesta di risorse. Infine, testerai la configurazione di rete e la connettività al modello Gemma 4.
Le configurazioni utilizzeranno una combinazione di Terraform, gcloud e kubectl.
In questo lab imparerai a eseguire le seguenti attività:
- Configurare una rete VPC
- Configurare un cluster GKE Autopilot
- Creare ComputeClass e ResourceClaimTemplate.
- Creare un deployment che esegue TPU, vLLM, monitoraggio e Gemma 4 tramite Hugging Face
- Testare la connettività all'LLM
In questo lab creerai il seguente pattern.
Figura 1. 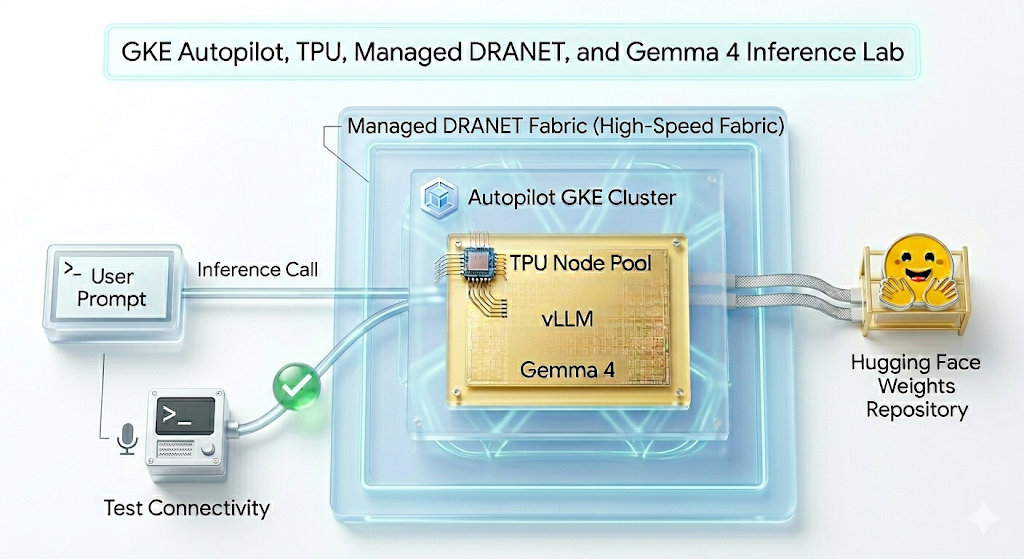
2. Configurazione dei servizi Google Cloud
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai già un account Gmail o Google Workspace, devi crearne uno.

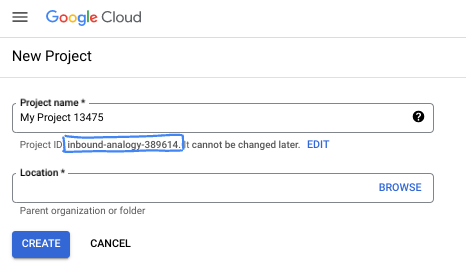
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi aggiornarla in qualsiasi momento.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca; in genere non ti interessa quale sia. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se non ti piace l'ID generato, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e verificare se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre i valori nella documentazione.
- Dopodiché, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse/API Cloud. L'esecuzione di questo codelab non costerà molto, se non nulla. Per arrestare le risorse ed evitare addebiti di fatturazione oltre questo tutorial, puoi eliminare le risorse che hai creato o eliminare il progetto. I nuovi utenti Google Cloud possono usufruire del programma di prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere qualcosa di simile a questo:

Questa macchina virtuale è dotata di tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Configurare l'ambiente con Terraform
Per eseguire questo lab, devi avere accesso alle TPU. La versione esatta utilizzata è TPU v6e.
- Per ottenere l'accesso, devi seguire il documento relativo al piano TPU e abilitare la quota TPU.
- Stiamo utilizzando un deployment di piccole dimensioni che richiede 4 chip TPU v6e (
ct6e-standard-4t)che sarà una slice 2x2 in una singola regione. - Token Hugging Face: per scaricare i pesi del modello Gemma è necessario un token di accesso
Creeremo un VPC personalizzato con regole firewall, una subnet e poi un cluster Autopilot. Apri la console Cloud e seleziona il progetto che utilizzerai.
- Apri Cloud Shell in alto a destra nella console, assicurati di visualizzare l'ID progetto corretto in Cloud Shell e conferma eventuali prompt per consentire l'accesso.

- Crea una cartella denominata
gke-auto-tpue spostati nella cartella
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Ora aggiungi alcuni file di configurazione. Verranno creati i seguenti file terraform.tfvars , variables.tf, net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Assicurati di trovarti nella directory gke-auto-tpu ed esegui i seguenti comandi:
terraform initinizializza la directory di lavoro. Questo è il primo passaggio e scarica i provider necessari per la configurazione specificata.terraform plan -outgenera un piano di esecuzione che mostra le azioni che Terraform eseguirà per eseguire il deployment dell'infrastruttura. L'opzione-outti consente di salvare il piano di esecuzione in un file binario denominato. Puoi vedere cosa succederà senza apportare modifiche.terraform applyesegue gli aggiornamenti.
terraform init
terraform plan -out vpc
- Ora esegui il deployment dopo aver eseguito
terraform apply. Poiché stai applicando il piano di esecuzione salvato, verrà eseguito immediatamente senza richiedere la conferma (l'operazione potrebbe richiedere 6-10 minuti)
terraform apply vpc
- Verifica la configurazione
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Creare ComputeClass e ResourceClaimTemplate
Dobbiamo creare una risorsa ComputeClass personalizzata per definire la configurazione del node pool. Nel nostro caso, utilizzeremo i chip TPU v6e (ct6e-standard-4t) e le reti DRANET gestite.
- Connettiti al cluster che hai creato. (p.s. cambia la regione con la regione in cui hai eseguito il deployment del cluster.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Assicurati di trovarti nella directory
gke-auto-tpued esegui i seguenti comandi. Viene creato il manifest ComputeClass. Tieni presente che, se hai utilizzato una regione diversa, devi modificare le informazioni sulla zona in modo che corrispondano a una zona all'interno della regione del cluster
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Ora crea ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- Nella directory
gke-auto-tpu, esegui i seguenti comandi. Viene creato il manifest ResourceClaimTemplate che supporta i dispositivi di rete non-RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Ora crea ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Creare il secret
- Questo lab utilizza google/gemma-4-31B-it , quindi dovrai creare un token HF. Sostituisci
YOUR_ACTUAL_HUGGING_FACE_TOKENdi seguito con il token effettivo.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Assicurati di trovarti nella directory
gke-auto-tpued esegui i seguenti comandi.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Eseguire il deployment del carico di lavoro vLLM e Gemma
Questa configurazione utilizza ComputeClass per eseguire automaticamente il provisioning dell'hardware e della rete richiesti (TPU v6e e DRANET gestito). Utilizza ResourceClaimTemplate per definire un progetto per richiedere l'accesso a questa rete ad alta velocità e un deployment che li associa generando singole richieste di rete per ogni pod man mano che vengono scalati.
- Assicurati di trovarti nella directory
gke-auto-tpued esegui i seguenti comandi.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Crea il deployment.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Per monitorare lo stato di completamento, esegui i seguenti comandi. I pod attenderanno il provisioning del nodo prima di poter procedere. Questa operazione potrebbe richiedere più di 13 minuti.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Dopo aver creato il nodo e pianificato il pod, puoi eseguire il comando per visualizzare i log dei pod. (p.s. puoi aggiungere il **
-f** **flag per lo streaming**). Se stai guardando i log, l'operazione richiederà **più di 15 minuti** . Quando vedi la stringa(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK, il modello è pronto per la pubblicazione.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Una volta che il deployment è disponibile, puoi verificare che la rete ad alta velocità sia collegata correttamente ai pod TPU. Esegui questo comando:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Cosa cercare: dovresti vedere eth0 standard insieme a interfacce aggiuntive come eth1 fino a ethxx.
Queste interfacce aggiuntive confermano che l'infrastruttura DRANET gestita ad alta velocità è collegata correttamente al pod.
6. Interagire con il modello AI utilizzando curl
Per verificare il modello gemma-4-31B di cui hai eseguito il deployment, configura l'inoltro della porta dal servizio alla tua macchina locale.
- Esegui questo comando in Cloud Shell corrente:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Ora, apri un'altra finestra di Cloud Shell per lo stesso progetto per chattare con il modello utilizzando
curl. Questo comando invia un prompt e trasmette l'output direttamente al terminale.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Dai un'occhiata alla risposta del modello
Osservabilità
Poiché abbiamo applicato la risorsa personalizzata PodMonitoring, Cloud Monitoring eseguirà lo scraping delle metriche dal container vLLM sulla porta 8000. Puoi andare a console Google Cloud Monitoring -> Dashboard per visualizzare in modo nativo metriche come la latenza di generazione dei token, la lunghezza della coda e l'utilizzo della cache KV.
7. Libera spazio
- Elimina le risorse eseguendo il comando seguente.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Pulisci l'infrastruttura con il comando seguente, digita
yesper confermare
terraform destroy
8. Complimenti
Hai eseguito il deployment di un ambiente DRANET gestito su GKE Autopilot, hai eseguito il provisioning dinamico dell'hardware TPU v6e e hai pubblicato il modello Gemma 4 con 31 miliardi di parametri utilizzando vLLM.
Utilizzando GKE Autopilot, consenti a Kubernetes di gestire il provisioning dei nodi e la gestione dell'infrastruttura sottostanti, in modo da poterti concentrare interamente sul deployment del carico di lavoro AI.
Prossimi passi / Scopri di più
Puoi leggere ulteriori informazioni sul networking GKE
Segui il prossimo lab
Continua la Quest con Google Cloud e dai un'occhiata a questi altri lab Google Cloud: