
1. Przegląd
W tym module poznasz infrastrukturę AI, której można używać do uruchamiania zadań AI. Będziesz pracować z tymi elementami:
Google Kubernetes Engine (GKE) – podstawowa platforma do orkiestracji kontenerów.
Zarządzana sieć DRANET w GKE – dynamiczne przydzielanie zasobów sieciowych, które bezpośrednio przypisuje szybkie połączenia międzysieciowe do podów TPU.
Jednostka Tensor Processing Unit (TPU) – opracowany przez Google akcelerator.
Aby skonfigurować, wdrożysz niestandardową sieć VPC i klaster GKE w trybie Autopilota. Aby włączyć zarządzaną sieć DRANET, utworzysz ComputeClass i szablon Resource Claim Template. Następnie wdrożysz zbiór zadań, który korzysta z vLLM, Hugging Face, ComputeClass i szablonu Resource Claim Template. Na koniec przetestujesz konfigurację sieci i połączenie z modelem Gemma 4.
Konfiguracje będą korzystać z kombinacji Terraform, gcloud i kubectl.
W tym module dowiesz się, jak wykonać te zadania:
- Konfigurowanie sieci VPC
- Konfigurowanie klastra GKE w trybie Autopilota
- Tworzenie ComputeClass i ResourceClaimTemplate.
- Tworzenie wdrożenia, które uruchamia TPU, vLLM, monitorowanie i Gemma 4 za pomocą Hugging Face
- Testowanie połączenia z LLM
W tym module utworzysz ten wzorzec.
Rysunek 1. 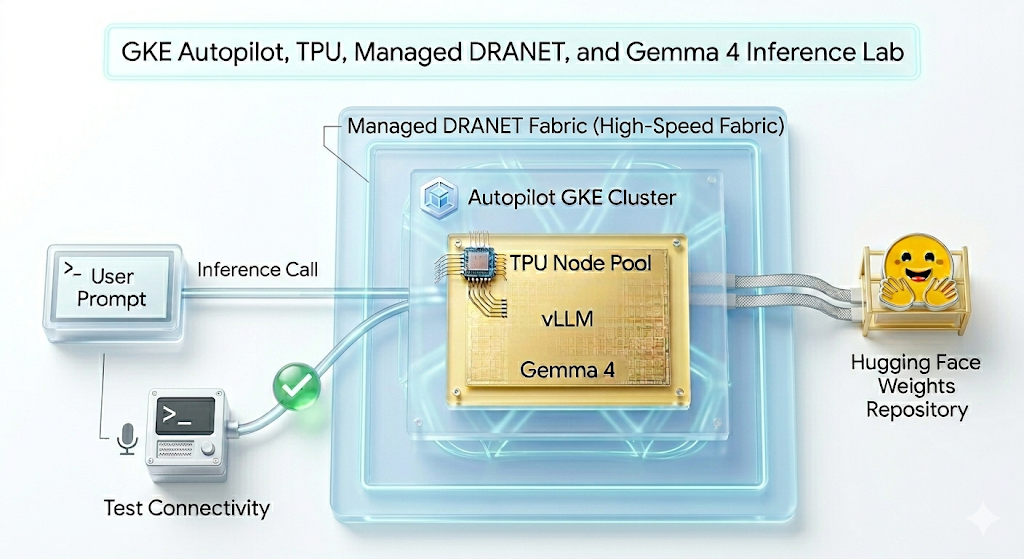
2. Konfigurowanie usług Google Cloud
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail lub Google Workspace, musisz je utworzyć.

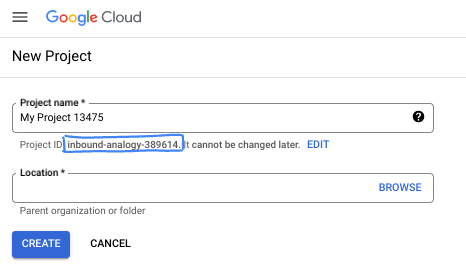
- Nazwa projektu to nazwa wyświetlana dla uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Możesz go w każdej chwili zaktualizować.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i niezmienny (nie można go zmienić po ustawieniu). Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się nim przejmować. W większości modułów będziesz musiał odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować użyć własnego identyfikatora i sprawdzić, czy jest dostępny. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Dla Twojej informacji istnieje trzecia wartość – numer projektu , której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby móc korzystać z zasobów i interfejsów API Cloud. Wykonanie tego modułu nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub usunąć projekt. Nowi użytkownicy Google Cloud mogą skorzystać z programu bezpłatnego okresu próbnego o wartości 300 USD.
Uruchamianie Cloud Shell
Chociaż Google Cloud można obsługiwać zdalnie z laptopa, w tym module będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinien pojawić się taki komunikat:

Ta maszyna wirtualna jest wyposażona we wszystkie narzędzia programistyczne, których będziesz potrzebować. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym module możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Konfigurowanie środowiska za pomocą Terraform
Aby wykonać ten moduł, musisz mieć dostęp do TPU. Używana wersja to TPU v6e.
- Aby uzyskać dostęp, postępuj zgodnie z instrukcjami w dokumencie dotyczącym planu TPU i włącz limit TPU.
- Używamy małego wdrożenia wymagającego 4 układów TPU v6e (
ct6e-standard-4t)które będą wycinkiem 2x2 w jednym regionie. - Token Hugging Face: do pobrania wag modelu Gemma wymagany jest token dostępu.
Utworzymy niestandardową sieć VPC z regułami zapory sieciowej i podsiecią, a następnie klaster w trybie Autopilota. Otwórz konsolę Cloud i wybierz projekt, którego będziesz używać.
- Otwórz Cloud Shell w prawym górnym rogu konsoli. Sprawdź, czy w Cloud Shell widzisz prawidłowy identyfikator projektu, i potwierdź wszystkie prośby o zezwolenie na dostęp.

- Utwórz folder o nazwie
gke-auto-tpui przejdź do niego.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Teraz dodaj pliki konfiguracyjne. Spowoduje to utworzenie plików terraform.tfvars , variables.tf i net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Upewnij się, że jesteś w katalogu gke-auto-tpu , i uruchom te polecenia:
terraform initinicjuje katalog roboczy. Jest to pierwszy krok, który pobiera dostawców wymaganych do danej konfiguracji.terraform plan -outgeneruje plan wykonania, który pokazuje, jakie działania Terraform podejmie w celu wdrożenia Twojej infrastruktury. Parametr-outumożliwia zapisanie planu wykonania w nazwanym pliku binarnym. Możesz zobaczyć, co się stanie, bez wprowadzania żadnych zmian.terraform applyuruchamia aktualizacje.
terraform init
terraform plan -out vpc
- Teraz uruchom wdrożenie po uruchomieniu polecenia
terraform apply. Ponieważ stosujesz zapisany plan wykonania, zostanie on wykonany natychmiast bez wyświetlania prośby o potwierdzenie (może to potrwać od 6 do 10 minut).
terraform apply vpc
- Sprawdź konfigurację.
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Tworzenie Compute Class i Resource Claim Template
Musimy utworzyć niestandardowy ComputeClass zasób, aby zdefiniować konfigurację puli węzłów. W naszym przypadku będziemy używać układów TPU v6e (ct6e-standard-4t)) i zarządzanych sieci DRANET.
- Połącz się z utworzonym klastrem. (P.S. Zmień region na ten, w którym został wdrożony klaster.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Upewnij się, że jesteś w katalogu
gke-auto-tpu, i uruchom te polecenia. Spowoduje to utworzenie manifestu ComputeClass. Pamiętaj, że jeśli używasz innego regionu, musisz zmienić informacje o strefie na strefę w regionie klastra.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Teraz utwórz ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- W katalogu
gke-auto-tpuuruchom te polecenia: Spowoduje to utworzenie manifestu ResourceClaimTemplate, który obsługuje urządzenia sieciowe inne niż RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Teraz utwórz ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Tworzenie obiektu tajnego
- W tym module używamy google/gemma-4-31B-it , więc musisz utworzyć token HF. Zastąp
YOUR_ACTUAL_HUGGING_FACE_TOKENponiżej swoim tokenem.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Upewnij się, że jesteś w katalogu
gke-auto-tpu, i uruchom te polecenia.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Wdrażanie zbioru zadań vLLM i Gemma
Ta konfiguracja używa ComputeClass do automatycznego udostępniania wymaganego sprzętu i sieci (TPU v6e i zarządzanej sieci DRANET). Używa ResourceClaimTemplate do zdefiniowania planu żądania dostępu do tej szybkiej sieci oraz wdrożenia, które łączy je ze sobą przez generowanie indywidualnych żądań sieciowych dla każdego poda w miarę ich skalowania.
- Upewnij się, że jesteś w katalogu
gke-auto-tpu, i uruchom to polecenie.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Utwórz wdrożenie.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Aby monitorować stan ukończenia, uruchom te polecenia. Pody będą czekać, aż węzeł zostanie udostępniony, zanim będą mogły kontynuować. Może to potrwać ponad 13 minut.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Po utworzeniu węzła i zaplanowaniu poda możesz uruchomić polecenie, aby wyświetlić logi podów. (P.S. Możesz dodać flagę **
-f** **do przesyłania strumieniowego**). Jeśli obserwujesz logi, gdy zobaczysz ciąg znaków(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK, model będzie gotowy do obsługi. Może to potrwać **ponad 15 minut**.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Gdy wdrożenie będzie dostępne, możesz sprawdzić, czy szybka sieć jest prawidłowo połączona z podami TPU. Uruchom to polecenie:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Czego szukać: oprócz standardowego interfejsu eth0 powinny być widoczne dodatkowe interfejsy, takie jak eth1 do ethxx.
Te dodatkowe interfejsy potwierdzają, że szybka zarządzana sieć DRANET jest prawidłowo połączona z Twoim podem.
6. Interakcja z modelem AI za pomocą curl
Aby zweryfikować wdrożony model gemma-4-31B, skonfiguruj przekierowanie portów z usługi na komputer lokalny.
- Uruchom to polecenie w bieżącym Cloud Shell:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Teraz otwórz dodatkowe okno Cloud Shell dla tego samego projektu, aby rozmawiać z modelem za pomocą
curl. To polecenie wysyła prompt i przesyła strumieniowo dane wyjściowe bezpośrednio do terminala.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Sprawdź odpowiedź modelu.
Dostrzegalność
Ponieważ zastosowaliśmy zasób niestandardowy PodMonitoring, Cloud Monitoring będzie pobierać dane z kontenera vLLM na porcie 8000. Aby wyświetlić natywnie takie dane jak opóźnienie generowania tokena, długość kolejki i wykorzystanie pamięci podręcznej KV, możesz otworzyć konsolę Google Cloud i wybrać Monitorowanie -> Panele.
7. Zwalnianie miejsca
- Aby usunąć zasoby, uruchom to polecenie:
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Aby zwolnić miejsce w infrastrukturze, uruchom to polecenie i wpisz
yes, aby potwierdzić.
terraform destroy
8. Gratulacje
Udało Ci się wdrożyć zarządzane środowisko DRANET w GKE w trybie Autopilota, dynamicznie udostępnić sprzęt TPU v6e i obsługiwać model Gemma 4 z 31 miliardami parametrów za pomocą vLLM.
Dzięki GKE w trybie Autopilota możesz pozwolić Kubernetes na obsługę udostępniania węzłów i zarządzania infrastrukturą, co pozwoli Ci skupić się wyłącznie na wdrażaniu zbioru zadań AI.
Kolejne kroki / Więcej informacji
Więcej informacji o sieci GKE
Przejdź do kolejnego modułu
Kontynuuj naukę w Google Cloud i zapoznaj się z tymi modułami Google Cloud: