
1. Visão geral
Neste laboratório, você vai conhecer a infraestrutura de IA que pode ser usada para executar cargas de trabalho de IA. Você vai trabalhar com o seguinte:
Google Kubernetes Engine (GKE): a plataforma básica de orquestração de contêineres.
DRANET gerenciado pelo GKE: rede de alocação dinâmica de recursos que atribui diretamente estruturas de interconexão de alta velocidade aos seus pods de TPU.
Unidade de processamento de tensor (TPU): chips aceleradores personalizados do Google.
Para configurar, você vai implantar uma VPC personalizada e um cluster do GKE do Autopilot. Para ativar o DRANET gerenciado, crie uma ComputeClass e um modelo de solicitação de recurso. Em seguida, você vai implantar uma carga de trabalho que usa vLLM, Hugging Face, ComputeClass e modelo de solicitação de recurso. Por fim, você vai testar a configuração de rede e a conectividade com o modelo Gemma 4.
As configurações vão usar uma combinação de Terraform, gcloud e kubectl.
Neste laboratório, você vai aprender a:
- Configurar uma rede VPC
- Configurar um cluster do GKE Autopilot
- Crie ComputeClass e ResourceClaimTemplate.
- Criar uma implantação que execute TPUs, vLLM, monitoramento e Gemma 4 usando o Hugging Face
- Testar a conectividade com o LLM
Neste laboratório, você vai criar o seguinte padrão:
Figura 1. 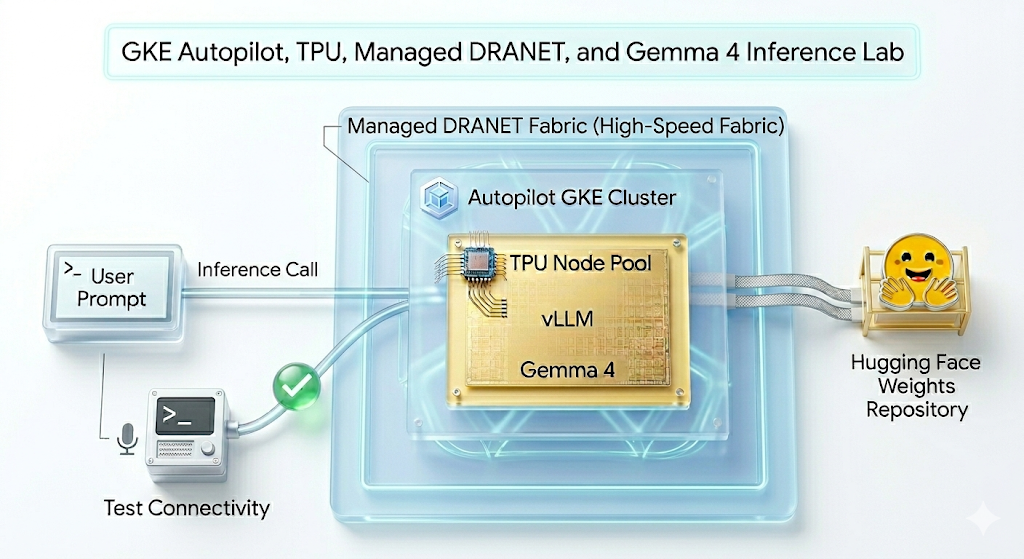
2. Configuração dos serviços do Google Cloud
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

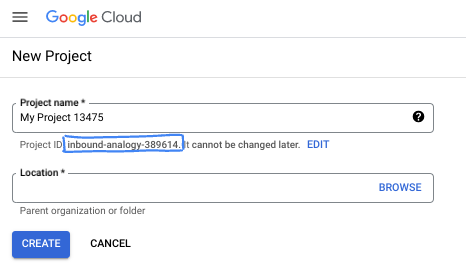
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Configurar o ambiente com o Terraform
Para fazer este laboratório, você precisa de acesso às TPUs. A versão exata usada é a TPU v6e.
- Siga o documento do plano de TPU e ative a cota de TPU para ter acesso.
- Estamos usando uma implantação pequena que exige quatro chips de TPU v6e (
ct6e-standard-4t), que será uma fração 2x2 em uma única região. - Token do Hugging Face: um token de acesso é necessário para fazer o download dos pesos do modelo Gemma.
Vamos criar uma VPC personalizada com regras de firewall, uma sub-rede e um cluster do Autopilot. Abra o console do Cloud e selecione o projeto que você vai usar.
- Abra o Cloud Shell, localizado na parte superior direita do console. Verifique se o ID do projeto correto aparece no Cloud Shell e confirme todas as solicitações para permitir o acesso.

- Crie uma pasta chamada
gke-auto-tpue acesse-a.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Agora adicione alguns arquivos de configuração. Isso vai criar os seguintes arquivos terraform.tfvars, variables.tf e net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Verifique se você está no diretório gke-auto-tpu e execute os seguintes comandos
terraform init: inicializa o diretório de trabalho. Esta é a primeira etapa e faz o download dos provedores necessários para a configuração especificada.terraform plan -out: gera um plano de execução, mostrando quais ações o Terraform vai realizar para implantar sua infraestrutura. O-outpermite salvar o plano de execução em um binário nomeado. Você pode ver o que vai acontecer sem fazer nenhuma mudança.terraform apply: executa as atualizações.
terraform init
terraform plan -out vpc
- Agora execute a implantação depois de executar
terraform apply. Como você está aplicando o plano de execução salvo, ele será executado imediatamente sem pedir confirmação (isso pode levar de 6 a 10 minutos).
terraform apply vpc
- Verificar a configuração
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Criar uma classe de computação e um modelo de reivindicação de recurso
É necessário criar um recurso ComputeClass personalizado para definir a configuração do pool de nós. No nosso caso, vamos usar os chips TPU v6e (ct6e-standard-4t) e redes DRANET gerenciadas.
- Conecte-se ao cluster que você criou. Observação: mude a região para aquela em que você implantou o cluster.
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Verifique se você está no diretório
gke-auto-tpue execute os seguintes comandos. Isso cria o manifesto ComputeClass. Se você usou uma região diferente, mude as informações da zona para uma zona dentro da região do cluster.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Agora crie a ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- No diretório
gke-auto-tpu, execute os comandos abaixo. Isso cria o manifesto ResourceClaimTemplate, que oferece suporte a dispositivos de rede não RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Agora crie o ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Criar seu secret
- Este laboratório usa google/gemma-4-31B-it . Portanto, você precisa criar um token do HF. Substitua
YOUR_ACTUAL_HUGGING_FACE_TOKENabaixo pelo seu token real.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Verifique se você está no diretório
gke-auto-tpue execute os seguintes comandos.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Implantar vLLM e Gemma de carga de trabalho
Essa configuração usa o ComputeClass para provisionar automaticamente o hardware e a rede necessários (TPU v6e e DRANET gerenciado). Ele usa o ResourceClaimTemplate para definir um modelo de solicitação de acesso a essa rede de alta velocidade e uma implantação que os vincula gerando reivindicações de rede individuais para cada pod à medida que eles são escalonados.
- Verifique se você está no diretório
gke-auto-tpue execute o seguinte.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Crie a implantação.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Para monitorar o status de conclusão, execute os comandos a seguir. Os pods vão aguardar até que o nó seja provisionado antes de prosseguir. Isso pode levar mais de 13 minutos.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Depois que o nó for criado e o pod for programado, execute o comando para conferir os registros dos pods. (P.S.: você pode adicionar a flag **
-f** **para streaming**). Isso vai levar até **15 minutos ou mais** para ser concluído se você estiver assistindo os registros quando vir a string(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK, o modelo estará pronto para ser disponibilizado.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Quando a implantação estiver disponível, verifique se a rede de alta velocidade está anexada corretamente aos pods de TPU. Execute este comando:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
O que procurar:você vai encontrar eth0 padrão e interfaces extras, como eth1 a ethxx.
Essas interfaces adicionais confirmam que a estrutura DRANET gerenciada de alta velocidade está anexada ao seu pod.
6. Interagir com o modelo de IA usando curl
Para verificar o modelo gemma-4-31B implantado, configure o encaminhamento de portas do serviço para sua máquina local.
- Execute este comando no Cloud Shell atual:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Agora, abra outra janela do Cloud Shell para o mesmo projeto e converse com seu modelo usando
curl. Esse comando envia uma solicitação e transmite a saída diretamente para o terminal.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Confira a resposta do modelo
Observabilidade
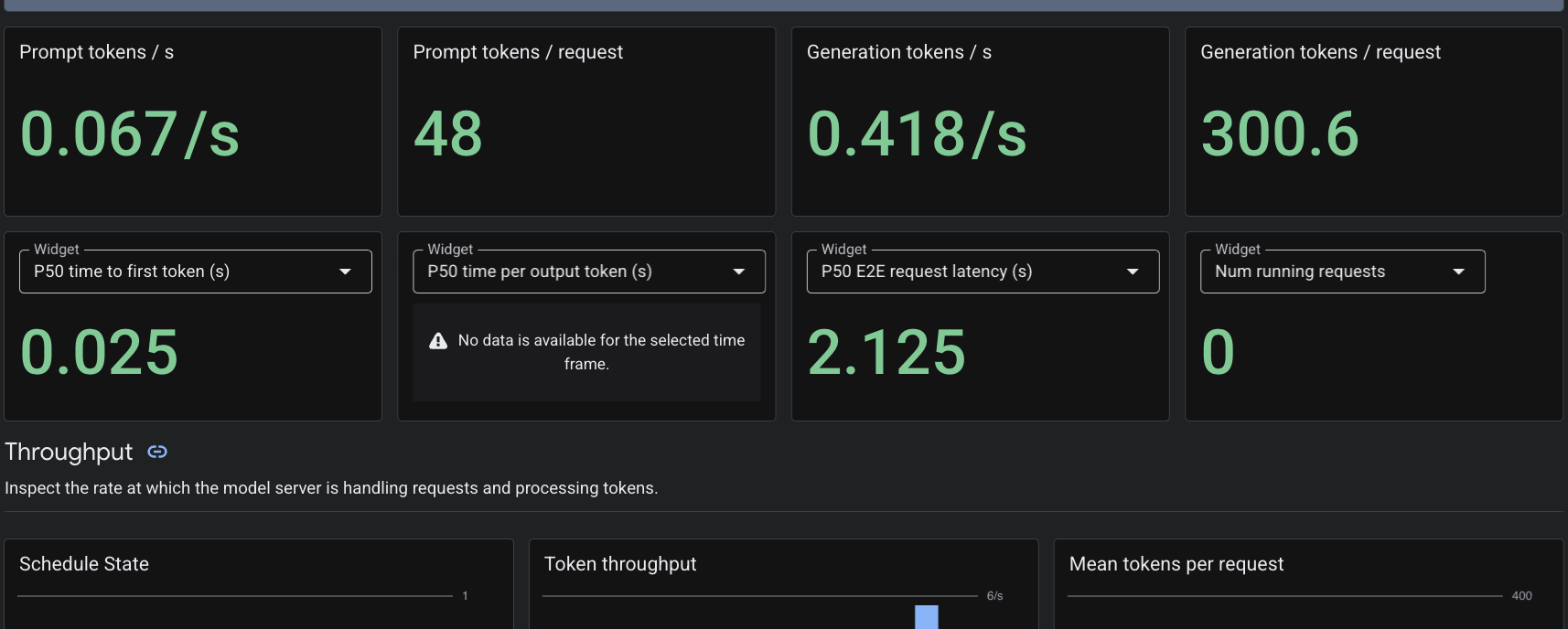
Como aplicamos o recurso personalizado PodMonitoring, o Cloud Monitoring vai extrair métricas do contêiner vLLM na porta 8000. Acesse o Console do Google Cloud Monitoring -> Painéis para conferir métricas como latência de geração de tokens, tamanho da fila e uso do cache KV de forma nativa.
7. Limpar
- Exclua os recursos executando o seguinte.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Limpe a infraestrutura com o seguinte comando e digite
yespara confirmar:
terraform destroy
8. Parabéns
Você implantou um ambiente DRANET gerenciado no GKE Autopilot, provisionou hardware de TPU v6e de forma dinâmica e disponibilizou o modelo Gemma 4 de 31 bilhões de parâmetros usando o vLLM.
Ao usar o Autopilot do GKE, você permite que o Kubernetes processe o provisionamento de nós e o gerenciamento de infraestrutura, para que você possa se concentrar totalmente na implantação da sua carga de trabalho de IA.
Próximas etapas / Saiba mais
Leia mais sobre a rede do GKE.
Comece o próximo laboratório
Continue sua Quest com o Google Cloud e confira estes outros laboratórios do Google Cloud: