
1. Обзор
В этой лабораторной работе вы познакомитесь с инфраструктурой искусственного интеллекта, которую можно использовать для запуска рабочих нагрузок ИИ. Вы будете работать со следующим:
Google Kubernetes Engine (GKE) — базовая платформа для оркестрации контейнеров.
DRANET, управляемый GKE, — это технология динамического распределения ресурсов в сети, которая напрямую назначает высокоскоростные межсоединительные сети вашим модулям TPU.
Tensor Processing Unit (TPU) — это разработанные компанией Google чипы-ускорители.
Для настройки вам потребуется развернуть пользовательскую VPC и кластер GKE с автопилотом. Чтобы включить управляемый DRANET, вы создадите ComputeClass и Resource Claim Template. Затем вы развернете рабочую нагрузку, использующую vLLM , Hugging Face , ComputeClass и Resource Claim Template . Наконец, вы протестируете настройку сети и подключение к модели Gemma 4 .
Для настройки будут использоваться комбинация Terraform , gcloud и kubectl .
В этой лабораторной работе вы научитесь выполнять следующее задание:
- Настройте сеть VPC.
- Настройка кластера автопилота GKE
- Создайте классы ComputeClass и ResourceClaimTemplate.
- Создайте развертывание, которое запускает TPU, vLLM, мониторинг и Gemma 4 с помощью Hugging Face.
- Проверьте подключение к LLM.
В этой лабораторной работе вы создадите следующий узор.
Рисунок 1. 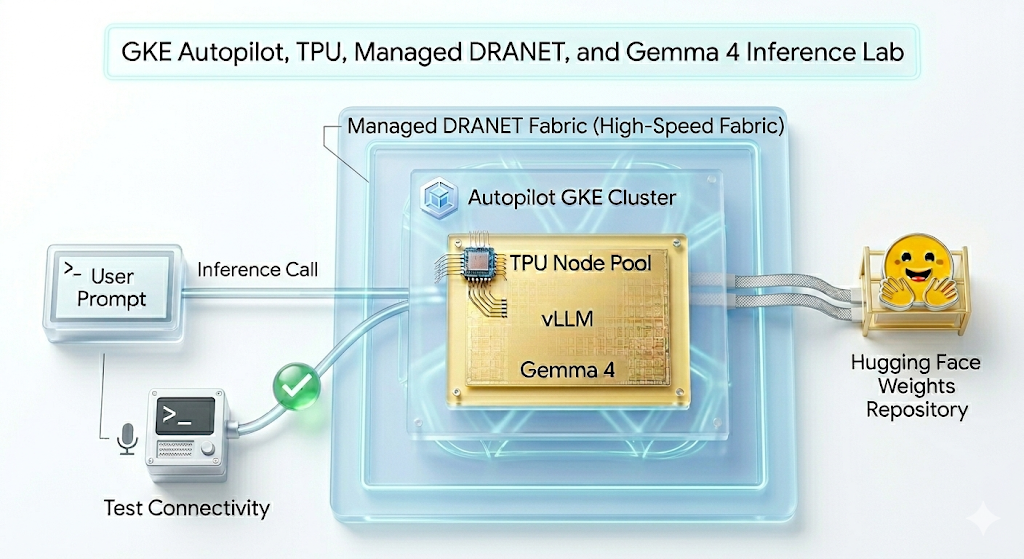
2. Настройка сервисов Google Cloud
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Настройка среды с помощью Terraform
Для выполнения этой лабораторной работы вам потребуется доступ к TPU. Используется точная версия TPU v6e.
- Для получения доступа вам следует следовать инструкциям в документе, описывающем тарифный план TPU, и включить квоту TPU .
- Мы используем небольшую систему, требующую 4 чипов TPU v6e (
ct6e-standard-4t), которые образуют срез 2x2 в одном регионе. - Токен "Обнимающее лицо": Для загрузки весов модели Джеммы необходим токен доступа .
Мы создадим пользовательскую VPC с правилами брандмауэра, подсетью, а затем кластером Autopilot. Откройте консоль облака и выберите проект, который вы будете использовать.
- Откройте Cloud Shell, расположенный в верхней части консоли справа, убедитесь, что в Cloud Shell отображается правильный идентификатор проекта , и подтвердите все запросы на предоставление доступа.

- Создайте папку с именем
gke-auto-tpuи перейдите в эту папку.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Теперь добавьте несколько конфигурационных файлов. В результате будут созданы следующие файлы: terraform.tfvars , variables.tf и net.tf.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Убедитесь, что вы находитесь в каталоге gke-auto-tpu , и выполните следующие команды.
terraform initинициализирует рабочий каталог. Это первый шаг, и он загружает необходимые для данной конфигурации провайдеры.
terraform plan -outгенерирует план выполнения, показывающий, какие действия Terraform предпримет для развертывания вашей инфраструктуры. Параметр-outпозволяет сохранить план выполнения в именованный исполняемый файл. Вы можете увидеть, что произойдет, не внося никаких изменений.
terraform applyзапускает обновления.
terraform init
terraform plan -out vpc
- Теперь запустите развертывание после выполнения
terraform apply. Поскольку вы применяете сохраненный план выполнения, он будет выполнен немедленно без запроса подтверждения (это может занять от 6 до 10 минут).
terraform apply vpc
- Проверьте настройки.
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Создайте класс вычислительных ресурсов и шаблон запроса на выделение ресурсов.
Нам необходимо создать пользовательский ресурс ComputeClass для определения конфигурации пула узлов. В нашем случае мы будем использовать чипы TPU v6e ( ct6e-standard-4t) и управляемые сети DRANET.
- Подключитесь к созданному вами кластеру. ( P.S. измените регион на регион, в котором вы развернули свой кластер. )
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Убедитесь, что вы находитесь в каталоге
gke-auto-tpu, и выполните следующие команды. Это создаст манифест ComputeClass. Обратите внимание: если вы использовали другой регион, вам необходимо изменить информацию о зоне на зону в пределах региона вашего кластера.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Теперь создайте класс ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- В каталоге
gke-auto-tpuвыполните следующие команды. Это создаст манифест ResourceClaimTemplate, который поддерживает сетевые устройства, не использующие RDMA .
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Теперь создайте ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Создайте свой секрет
- В этой лабораторной работе используется google/gemma-4-31B-it, поэтому вам потребуется создать токен HF . Замените
YOUR_ACTUAL_HUGGING_FACE_TOKENниже на ваш реальный токен.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Убедитесь, что вы находитесь в каталоге
gke-auto-tpu, и выполните следующие команды.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Развертывание рабочей нагрузки vLLM и Gemma.
В этой конфигурации используется ComputeClass для автоматического выделения необходимого оборудования и сетевых ресурсов (TPU v6e и управляемая сеть DRANET). ResourceClaimTemplate используется для определения схемы запроса доступа к высокоскоростной сети, а развертывание связывает их вместе, генерируя отдельные запросы на доступ к сети для каждого пода по мере их масштабирования.
- Убедитесь, что вы находитесь в каталоге
gke-auto-tpu, и выполните следующую команду.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Создайте развертывание.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Для отслеживания статуса завершения выполните следующие команды. Поды будут ждать завершения подготовки узла, прежде чем смогут продолжить, это может занять более 13 минут.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- После создания узла и планирования пода вы можете запустить команду, чтобы просмотреть логи подов. ( Примечание: вы можете добавить флаг **
-f** для потоковой передачи ). Это может занять до 15 минут и более, если вы следите за логами, когда видите строку(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKмодель готова к запуску.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- После того, как развертывание станет доступно, вы сможете убедиться, что высокоскоростная сеть правильно подключена к вашим модулям TPU. Выполните следующую команду:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
На что обратить внимание: Вы должны увидеть стандартный интерфейс eth0 наряду с дополнительными интерфейсами, такими как eth1 и ethxx .
Эти дополнительные интерфейсы подтверждают, что высокоскоростная управляемая сеть DRANET успешно подключена к вашему модулю.
6. Взаимодействие с моделью ИИ с помощью curl.
Для проверки развернутой вами модели gemma-4-31B настройте переадресацию портов с сервиса на ваш локальный компьютер.
- Выполните этот код в вашей текущей оболочке Cloud Shell:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Теперь откройте дополнительное окно Cloud Shell для того же проекта, чтобы общаться с вашей моделью, используя
curl. Эта команда отправляет приглашение командной строки и передает вывод непосредственно в ваш терминал.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Проверьте ответ вашей модели.
Наблюдаемость
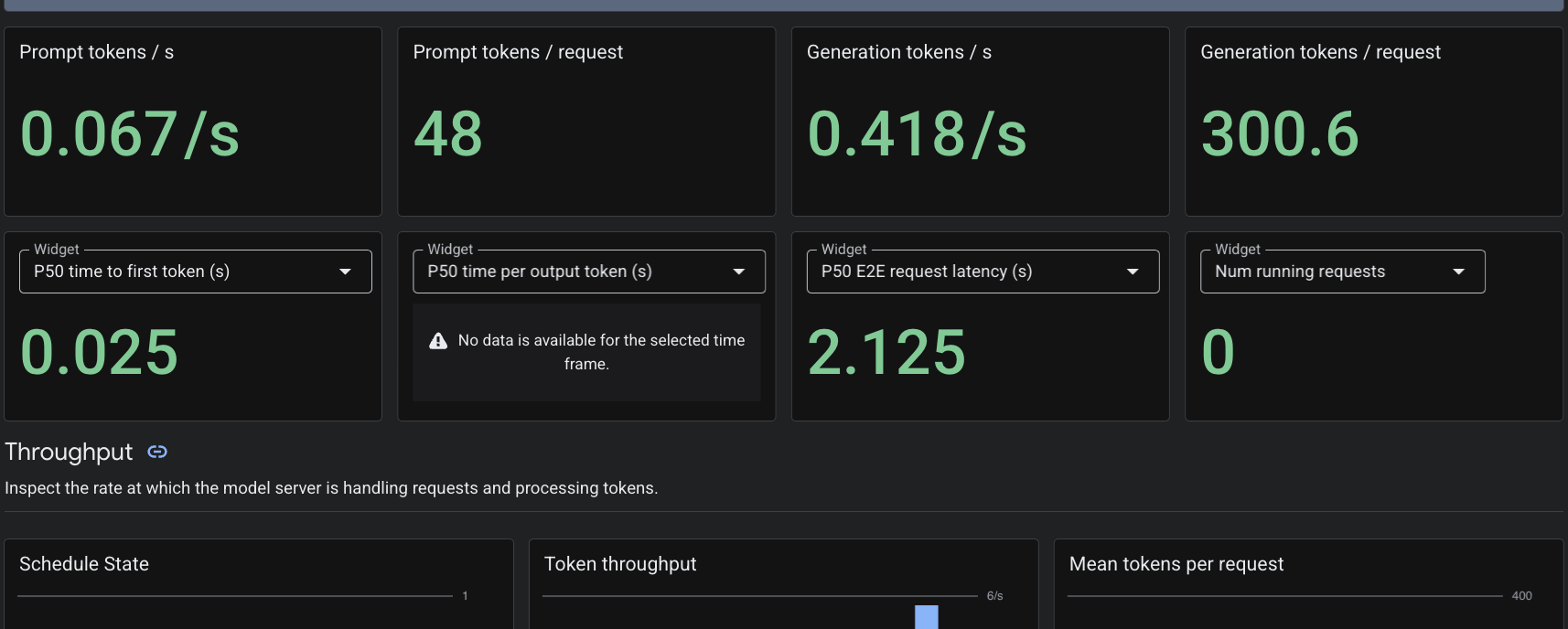
Поскольку мы применили пользовательский ресурс PodMonitoring , Cloud Monitoring будет собирать метрики из контейнера vLLM на порту 8000. Вы можете перейти в консоль Google Cloud «Мониторинг» -> «Панели мониторинга» , чтобы просмотреть такие метрики, как задержка генерации токенов, длина очереди и использование кэша ключ-значение.
7. Уборка
- Удалите ресурсы, выполнив следующую команду.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Очистите инфраструктуру с помощью следующей команды, для подтверждения введите
yes
terraform destroy
8. Поздравляем!
Вы успешно развернули управляемую среду DRANET на GKE Autopilot, динамически выделили оборудование TPU v6e и запустили масштабную модель Gemma 4 с 31 миллиардом параметров, используя vLLM.
Использование GKE Autopilot позволяет Kubernetes самостоятельно управлять выделением узлов и инфраструктурой, что дает вам возможность полностью сосредоточиться на развертывании рабочих нагрузок ИИ.
Следующие шаги / Узнать больше
Вы можете узнать больше о сети GKE.
Пройдите следующую лабораторную работу.
Продолжите свое знакомство с Google Cloud и ознакомьтесь с другими лабораториями Google Cloud: