
1. Genel Bakış
Bu laboratuvarda, yapay zeka iş yüklerini çalıştırmak için kullanılabilecek yapay zeka altyapısı hakkında bilgi edineceksiniz. Aşağıdakilerle çalışacaksınız:
Google Kubernetes Engine (GKE): Temel kapsayıcı düzenleme platformu.
GKE tarafından yönetilen DRANET: Yüksek hızlı ara bağlantı yapılarını doğrudan TPU kapsüllerinize atayan dinamik kaynak ayırma ağı.
Tensor İşleme Birimi (TPU): Google'ın özel olarak tasarlanmış hızlandırıcı çipleri.
Yapılandırmak için özel bir VPC ve bir Autopilot GKE kümesi dağıtmanız gerekir. Yönetilen DRANET'i etkinleştirmek için bir ComputeClass ve bir Resource Claim Template oluşturursunuz. Ardından vLLM, Hugging Face, ComputeClass ve kaynak talebi şablonu kullanan bir iş yükü dağıtırsınız. Son olarak, ağ kurulumunu ve Gemma 4 modeline bağlantıyı test edeceksiniz.
Yapılandırmalarda Terraform, gcloud ve kubectl kombinasyonu kullanılır.
Bu laboratuvarda, aşağıdaki görevi nasıl gerçekleştireceğinizi öğreneceksiniz:
- VPC ağı oluşturma
- GKE Autopilot kümesi oluşturma
- ComputeClass ve ResourceClaimTemplate oluşturun.
- Hugging Face aracılığıyla TPU'ları, vLLM'yi, izlemeyi ve Gemma 4'ü çalıştıran bir dağıtım oluşturma
- LLM'ye bağlantıyı test etme
Bu laboratuvarda aşağıdaki kalıbı oluşturacaksınız.
Şekil 1. 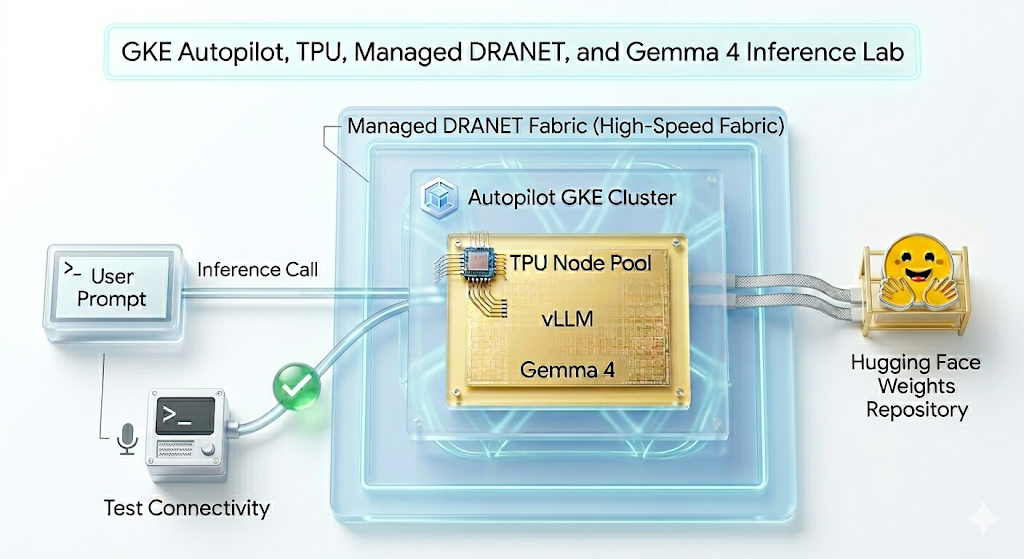
2. Google Cloud hizmetlerinin kurulumu
Yönlendirmesiz ortam kurulumu
- Google Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Gmail veya Google Workspace hesabınız yoksa hesap oluşturmanız gerekir.

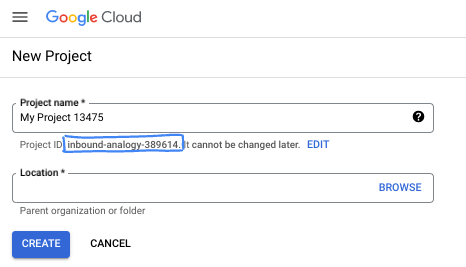
- Proje adı, bu projenin katılımcıları için görünen addır. Google API'leri tarafından kullanılmayan bir karakter dizesidir. Bu bilgiyi istediğiniz zaman güncelleyebilirsiniz.
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve sabittir (ayarlandıktan sonra değiştirilemez). Cloud Console, benzersiz bir dizeyi otomatik olarak oluşturur. Genellikle bu dizenin ne olduğuyla ilgilenmezsiniz. Çoğu codelab'de proje kimliğinize (genellikle
PROJECT_IDolarak tanımlanır) başvurmanız gerekir. Oluşturulan kimliği beğenmezseniz başka bir rastgele kimlik oluşturabilirsiniz. Dilerseniz kendi adınızı deneyerek kullanılabilir olup olmadığını kontrol edebilirsiniz. Bu adım tamamlandıktan sonra değiştirilemez ve proje süresince geçerli kalır. - Bazı API'lerin kullandığı üçüncü bir değer olan Proje Numarası hakkında bilgi edinmek için dokümanlara göz atın.
- Ardından, Cloud kaynaklarını/API'lerini kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir. Bu codelab'i tamamlamak çok fazla zamanınızı almaz. Bu eğitimin ötesinde faturalandırılmayı önlemek için kaynakları kapatmak üzere oluşturduğunuz kaynakları veya projeyi silebilirsiniz. Yeni Google Cloud kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir ancak bu codelab'de Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Ortamın temel hazırlığı ve bağlantı kurulması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir ekranla karşılaşırsınız:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarıyla birlikte gelir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
3. Terraform ile ortamı ayarlama
Bu laboratuvarı tamamlamak için TPU'lara erişmeniz gerekir. Kullanılan tam sürüm TPU v6e'dir.
- Erişim elde etmek için TPU planı dokümanını incelemeli ve TPU kotasını etkinleştirmelisiniz.
- 4 TPU v6e çipi gerektiren küçük bir dağıtım kullanıyoruz (
ct6e-standard-4t)bu, tek bir bölgede 2x2 dilim olacaktır). - Hugging Face jetonu: Gemma model ağırlıklarını indirmek için erişim jetonu gerekir.
Güvenlik duvarı kuralları, bir alt ağ ve ardından bir otomatik pilot kümesi içeren özel bir VPC oluşturacağız. Cloud Console'u açın ve kullanacağınız projeyi seçin.
- Konsolunuzun sağ üst kısmında bulunan Cloud Shell'i açın, Cloud Shell'de doğru proje kimliğini gördüğünüzden emin olun ve erişime izin verme istemlerini onaylayın.

gke-auto-tpuadlı bir klasör oluşturun ve bu klasöre gidin.
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Şimdi bazı yapılandırma dosyaları ekleyin. Bu işlemle aşağıdaki terraform.tfvars, variables.tf ve net.tf dosyası oluşturulur.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- gke-auto-tpu dizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın
terraform initÇalışma dizinini başlatır. Bu ilk adımda, belirli yapılandırma için gerekli sağlayıcılar indirilir.terraform plan -out, Terraform'un altyapınızı dağıtmak için hangi işlemleri yapacağını gösteren bir yürütme planı oluşturur.-out, yürütme planını adlandırılmış bir ikili dosyaya kaydetmenize olanak tanır. Herhangi bir değişiklik yapmadan ne olacağını görebilirsiniz.terraform applygüncellemeleri çalıştırır.
terraform init
terraform plan -out vpc
- Kaydedilen yürütme planını uyguladığınız için
terraform applykomutunu çalıştırdıktan sonra dağıtımı çalıştırın. Dağıtım, onay istemeden hemen yürütülür (Bu işlem 6-10 dakika sürebilir).
terraform apply vpc
- Kurulumu doğrulama
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Compute Class ve Resource Claim Template oluşturma
Düğüm havuzunun yapılandırmasını tanımlamak için özel bir ComputeClass kaynağı oluşturmamız gerekir. Örneğimizde TPU v6e çipleri (ct6e-standard-4t)) ve yönetilen DRANET ağlarını kullanacağız.
- Oluşturduğunuz kümeye bağlanın. (Not: Bölgeyi, kümenizi dağıttığınız bölge olarak değiştirin.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
gke-auto-tpudizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın. Bu işlem, ComputeClass manifest dosyasını oluşturur. Farklı bir bölge kullandıysanız lütfen bölge bilgilerini kümenizin bulunduğu bölgedeki bir bölgeyle değiştirmeniz gerektiğini unutmayın.
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Şimdi ComputeClass'ı oluşturun.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
gke-auto-tpudizininde aşağıdaki komutları çalıştırın. Bu komut, non-RDMA ağ cihazlarını destekleyen ResourceClaimTemplate manifestini oluşturur.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Şimdi ResourceClaimTemplate'i oluşturun.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Gizli anahtarınızı oluşturma
- Bu laboratuvarda google/gemma-4-31B-it kullanıldığından HF jetonu oluşturmanız gerekir. Aşağıdaki
YOUR_ACTUAL_HUGGING_FACE_TOKENdeğerini gerçek jetonunuzla değiştirin.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
gke-auto-tpudizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. İş yükü vLLM ve Gemma'yı dağıtma
Bu kurulumda, gerekli donanım ve ağ (TPU v6e ve yönetilen DRANET) otomatik olarak sağlanır.ComputeClass Bu ağ, yüksek hızlı ağa erişim isteğinde bulunmak için bir plan tanımlamak üzere ResourceClaimTemplate kullanır ve ölçeklendikçe her pod için ayrı ağ talepleri oluşturarak bunları birbirine bağlayan bir dağıtım gerçekleştirir.
gke-auto-tpudizininde olduğunuzdan emin olun ve aşağıdakileri çalıştırın.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Dağıtımı oluşturun.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Tamamlama durumunu izlemek için aşağıdaki komutları çalıştırın. Pod'lar işleme devam etmeden önce düğümün sağlanmasını bekler. Bu işlem 13 dakika veya daha uzun sürebilir.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Düğüm oluşturulduktan ve pod planlandıktan sonra, pod'ların günlüklerini görmek için komutu çalıştırabilirsiniz. (Not: **
-f** **Yayın için işaretini ekleyebilirsiniz**).(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OKdizesini gördüğünüzde günlükleri izliyorsanız bu işlem **15 dakikadan** uzun sürebilir.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Dağıtım kullanıma sunulduktan sonra yüksek hızlı ağın TPU kapsüllerinize doğru şekilde bağlandığını doğrulayabilirsiniz. Aşağıdaki komutu çalıştırın:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Nelere dikkat etmelisiniz? eth0 standartının yanı sıra eth1 ile ethxx arasında değişen ek arayüzler görmelisiniz.
Bu ek arayüzler, yüksek hızlı yönetilen DRANET yapısının pod'unuza başarıyla eklendiğini onaylar.
6. Curl kullanarak yapay zeka modeliyle etkileşim kurma
Dağıttığınız gemma-4-31B modelini doğrulamak için hizmetten yerel makinenize bağlantı noktası yönlendirmeyi ayarlayın.
- Mevcut Cloud Shell'inizde şunu çalıştırın:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Şimdi,
curlkullanarak modelinizle sohbet etmek için aynı proje için ek bir Cloud Shell penceresi açın. Bu komut, bir istem gönderir ve çıkışı doğrudan terminalinize aktarır.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Modelinizin yanıtını inceleyin
Gözlemlenebilirlik
PodMonitoring özel kaynağını uyguladığımız için Cloud Monitoring, 8000 numaralı bağlantı noktasındaki vLLM kapsayıcısından metrikleri kazır. Token oluşturma gecikmesi, kuyruk uzunluğu ve KV önbellek kullanımı gibi metrikleri yerel olarak görüntülemek için Google Cloud Console Monitoring -> Dashboards'a gidebilirsiniz.
7. Temizleme
- Aşağıdaki komutu çalıştırarak kaynakları silin.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Aşağıdaki komutla altyapıyı temizleyin, onaylamak için
yesyazın.
terraform destroy
8. Tebrikler
GKE Autopilot'ta yönetilen bir DRANET ortamını başarıyla dağıttınız, TPU v6e donanımını dinamik olarak sağladınız ve vLLM kullanarak 31 milyar parametreli Gemma 4 modelini sundunuz.
GKE Autopilot'u kullanarak Kubernetes'in temel düğüm sağlama ve altyapı yönetimini yapmasına izin verirsiniz. Böylece tamamen yapay zeka iş yükünüzü dağıtmaya odaklanabilirsiniz.
Sonraki adımlar / Daha fazla bilgi
GKE ağ iletişimi hakkında daha fazla bilgi edinebilirsiniz.
Sonraki laboratuvarınıza katılın
Google Cloud ile görevinize devam edin ve aşağıdaki Google Cloud laboratuvarlarına göz atın: