
1. Tổng quan
Lớp học lập trình này giới thiệu cho bạn về Cơ sở hạ tầng AI có thể dùng để chạy khối lượng công việc AI. Bạn sẽ làm việc với những nội dung sau:
Google Kubernetes Engine (GKE) – Nền tảng điều phối vùng chứa cơ bản.
**DRANET do GKE quản lý** – Mạng phân bổ tài nguyên động trực tiếp chỉ định các cấu trúc liên kết tốc độ cao cho các nhóm TPU của bạn.
Bộ xử lý Tensor (TPU) – Chip tăng tốc do Google xây dựng tuỳ chỉnh.
Để định cấu hình, bạn sẽ triển khai một VPC tuỳ chỉnh và một cụm GKE tự động điều khiển. Để bật DRANET được quản lý, bạn sẽ tạo một ComputeClass và một Mẫu yêu cầu tài nguyên. Sau đó, bạn sẽ triển khai một khối lượng công việc sử dụng vLLM, Hugging Face, ComputeClass và mẫu yêu cầu tài nguyên. Cuối cùng, bạn sẽ kiểm thử thiết lập mạng và khả năng kết nối với mô hình Gemma 4.
Các cấu hình sẽ sử dụng kết hợp Terraform, gcloud và kubectl.
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách thực hiện các tác vụ sau:
- Thiết lập mạng VPC
- Thiết lập cụm tự động điều khiển GKE
- Tạo ComputeClass và ResourceClaimTemplate.
- Tạo một quá trình triển khai chạy, TPU, vLLM, giám sát và Gemma 4 thông qua Hugging Face
- Kiểm thử khả năng kết nối với LLM
Trong lớp học lập trình này, bạn sẽ tạo mẫu sau.
Hình 1. 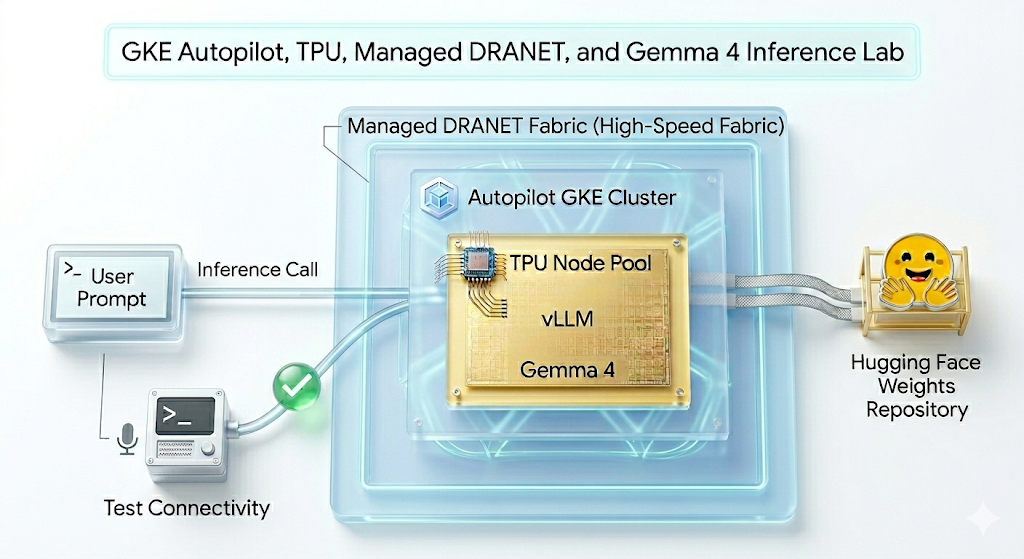
2. Thiết lập dịch vụ Google Cloud
Thiết lập môi trường tự học
- Đăng nhập vào Google Cloud Console rồi tạo một dự án mới hoặc sử dụng lại dự án hiện có. Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.

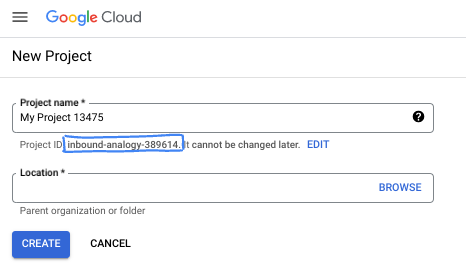
- Tên dự án là tên hiển thị cho những người tham gia dự án này. Đây là một chuỗi ký tự mà các API của Google không sử dụng. Bạn luôn có thể cập nhật tên này.
- Mã dự án là duy nhất trên tất cả các dự án của Google Cloud và là bất biến (không thể thay đổi sau khi đã đặt). Cloud Console tự động tạo một chuỗi duy nhất; thường thì bạn không cần quan tâm đến chuỗi này. Trong hầu hết các lớp học lập trình, bạn sẽ cần tham chiếu đến Mã dự án (thường được xác định là
PROJECT_ID). Nếu không thích mã đã tạo, bạn có thể tạo một mã ngẫu nhiên khác. Ngoài ra, bạn có thể thử mã của riêng mình và xem mã đó có dùng được hay không. Bạn không thể thay đổi mã này sau bước này và mã này sẽ giữ nguyên trong suốt thời gian của dự án. - Để bạn tham khảo, có một giá trị thứ ba là Số dự án mà một số API sử dụng. Tìm hiểu thêm về cả 3 giá trị này trong tài liệu.
- Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên/API trên Cloud. Việc thực hiện lớp học lập trình này sẽ không tốn nhiều chi phí, thậm chí là không tốn chi phí nào. Để tắt các tài nguyên nhằm tránh phát sinh chi phí thanh toán ngoài hướng dẫn này, bạn có thể xoá các tài nguyên đã tạo hoặc xoá dự án. Người dùng mới của Google Cloud đủ điều kiện tham gia chương trình Dùng thử miễn phí trị giá 300 USD.
Bắt đầu Cloud Shell
Mặc dù bạn có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Google Cloud Console, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Bạn chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi hoàn tất, bạn sẽ thấy nội dung tương tự như sau:

Máy ảo này được tải sẵn tất cả các công cụ phát triển mà bạn cần. Máy ảo này cung cấp một thư mục chính liên tục 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và quy trình xác thực. Bạn có thể thực hiện tất cả công việc trong lớp học lập trình này trong một trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
3. Thiết lập môi trường bằng Terraform
Để thực hiện lớp học lập trình này, bạn cần có quyền truy cập vào TPU. Phiên bản chính xác được sử dụng là TPU v6e.
- Bạn nên làm theo tài liệu về gói TPU và bật hạn mức TPU để có quyền truy cập.
- Chúng tôi đang sử dụng một quá trình triển khai nhỏ yêu cầu 4 chip TPU v6e (
ct6e-standard-4t)sẽ là một phần 2x2 trong một khu vực. - Mã thông báo Hugging Face: Bạn cần có Mã truy cập để tải trọng số của mô hình Gemma xuống
Chúng ta sẽ tạo một VPC tuỳ chỉnh có quy tắc tường lửa, một mạng con rồi tạo một cụm tự động điều khiển. Mở Cloud Console rồi chọn dự án mà bạn sẽ sử dụng.
- Mở Cloud Shell ở trên cùng bên phải của bảng điều khiển, đảm bảo bạn thấy mã dự án chính xác trong Cloud Shell, xác nhận mọi lời nhắc để cho phép truy cập.

- Tạo một thư mục có tên là
gke-auto-tpurồi chuyển đến thư mục đó
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- Bây giờ, hãy thêm một số tệp cấu hình. Các tệp này sẽ tạo tệp terraform.tfvars , variables.tf, net.tf sau đây.
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- Đảm bảo bạn đang ở trong thư mục gke-auto-tpu rồi chạy các lệnh sau
terraform initKhởi chạy thư mục làm việc. Đây là bước đầu tiên và bước này sẽ tải các nhà cung cấp cần thiết cho cấu hình đã cho.terraform plan -outtạo một kế hoạch thực thi, cho biết những hành động mà Terraform sẽ thực hiện để triển khai cơ sở hạ tầng của bạn.-outcho phép bạn lưu kế hoạch thực thi vào một tệp nhị phân được đặt tên. Bạn có thể xem những gì sẽ xảy ra mà không cần thực hiện bất kỳ thay đổi nào.terraform applychạy các bản cập nhật.
terraform init
terraform plan -out vpc
- Bây giờ, hãy chạy quá trình triển khai sau khi bạn chạy
terraform apply, vì bạn đang áp dụng kế hoạch thực thi đã lưu, nên quá trình này sẽ thực thi ngay lập tức mà không cần bạn xác nhận (Quá trình này có thể mất từ 6 đến 10 phút)
terraform apply vpc
- Xác minh quá trình thiết lập
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. Tạo Lớp tính toán và Mẫu yêu cầu tài nguyên
Chúng ta cần tạo một tài nguyên ComputeClass tuỳ chỉnh để xác định cấu hình cho bộ nút. Trong trường hợp này, chúng ta sẽ sử dụng chip TPU v6e (ct6e-standard-4t) và mạng DRANET được quản lý.
- Kết nối với cụm mà bạn đã tạo. (p.s. thay đổi khu vực thành khu vực mà bạn đã triển khai cụm.)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- Đảm bảo bạn đang ở trong thư mục
gke-auto-tpurồi chạy các lệnh sau. Thao tác này sẽ tạo tệp kê khai ComputeClass. Xin lưu ý rằng nếu bạn đã sử dụng một khu vực khác, bạn cần thay đổi thông tin về khu vực thành một khu vực trong khu vực của cụm
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- Bây giờ, hãy tạo ComputeClass.
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- Trong thư mục
gke-auto-tpu, hãy chạy các lệnh sau. Thao tác này sẽ tạo tệp kê khai ResourceClaimTemplate hỗ trợ các thiết bị mạng không phải RDMA.
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- Bây giờ, hãy tạo ResourceClaimTemplate.
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
Tạo khoá bí mật
- Lớp học lập trình này sử dụng google/gemma-4-31B-it nên bạn cần tạo mã thông báo HF. Thay thế
YOUR_ACTUAL_HUGGING_FACE_TOKENbên dưới bằng mã thông báo thực tế của bạn.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Đảm bảo bạn đang ở trong thư mục
gke-auto-tpurồi chạy các lệnh sau.
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. Triển khai khối lượng công việc vLLM và Gemma
Quá trình thiết lập này sử dụng ComputeClass để tự động cung cấp phần cứng và mạng cần thiết (TPU v6e và DRANET được quản lý). Quá trình này sử dụng ResourceClaimTemplate để xác định bản thiết kế cho việc yêu cầu quyền truy cập vào mạng tốc độ cao đó và một quá trình triển khai liên kết các mạng này với nhau bằng cách tạo các yêu cầu mạng riêng lẻ cho từng nhóm khi các mạng này mở rộng quy mô.
- Đảm bảo bạn đang ở trong thư mục
gke-auto-tpurồi chạy lệnh sau.
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- Tạo quá trình triển khai.
kubectl apply -f gem4-auto-dra-tpu.yaml
- Để theo dõi trạng thái hoàn tất, hãy chạy các lệnh sau. Các nhóm sẽ đợi cho đến khi nút được cung cấp rồi mới có thể tiếp tục. Quá trình này có thể mất 13 phút trở lên.
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- Sau khi nút được tạo và nhóm được lên lịch, bạn có thể chạy lệnh để xem nhật ký của các nhóm. (p.s. Bạn có thể thêm cờ **
-f** **để phát trực tuyến**). Quá trình này sẽ mất tối đa **15 phút trở lên** để hoàn tất nếu bạn đang xem nhật ký khi thấy chuỗi(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK. Mô hình đã sẵn sàng để phân phát.
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- Sau khi quá trình triển khai có sẵn, bạn có thể xác minh rằng mạng tốc độ cao được đính kèm đúng cách vào các nhóm TPU của bạn. Chạy lệnh sau:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
Những nội dung cần tìm: Bạn sẽ thấy eth0 tiêu chuẩn cùng với các giao diện bổ sung như eth1 thông qua ethxx.
Các giao diện bổ sung này xác nhận rằng cấu trúc DRANET được quản lý tốc độ cao đã được đính kèm thành công vào nhóm của bạn.
6. Tương tác với mô hình AI bằng curl
Để xác minh mô hình gemma-4-31B mà bạn đã triển khai, hãy thiết lập tính năng chuyển tiếp cổng từ dịch vụ đến máy cục bộ của bạn.
- Chạy lệnh này trong Cloud Shell hiện tại:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- Bây giờ, hãy mở một cửa sổ Cloud Shell bổ sung cho cùng một dự án để trò chuyện với mô hình của bạn bằng cách sử dụng
curl. Lệnh này sẽ gửi một lời nhắc và phát trực tuyến đầu ra trực tiếp đến thiết bị đầu cuối của bạn.
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- Kiểm tra phản hồi từ mô hình của bạn
Khả năng ghi nhận
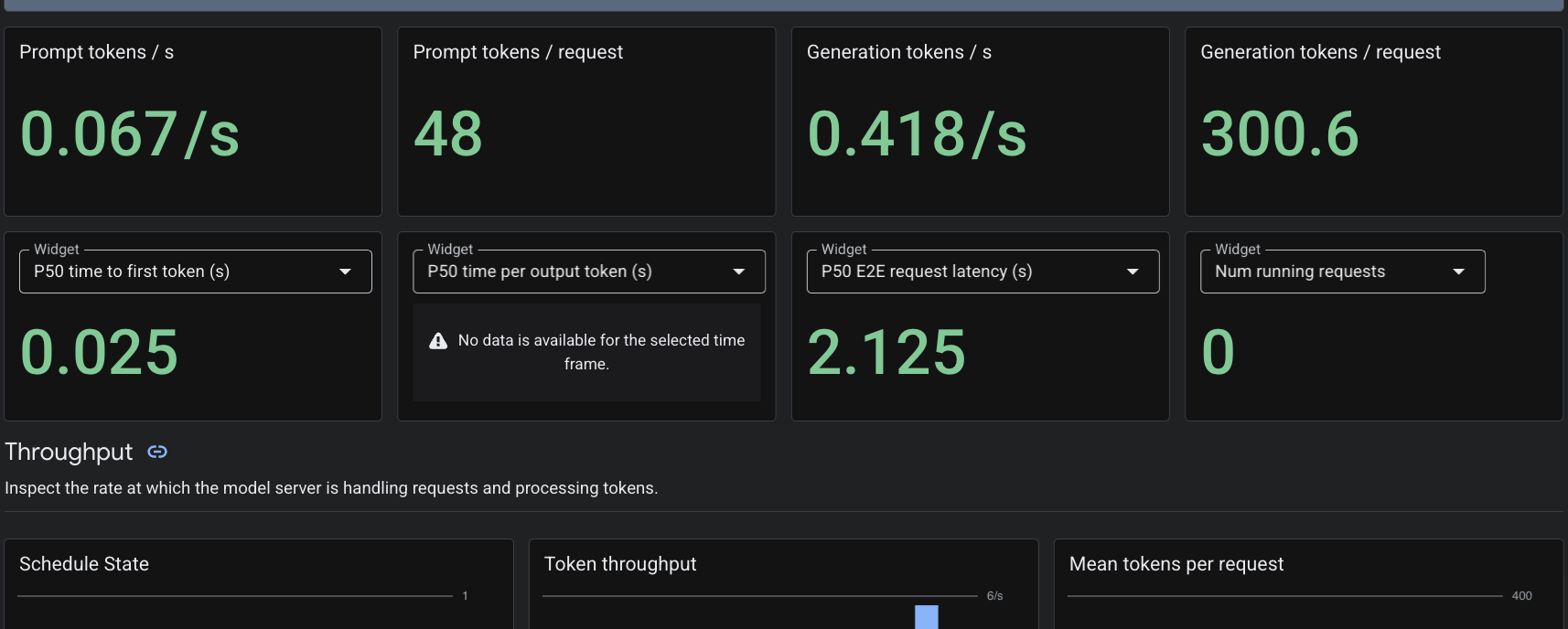
Vì chúng ta đã áp dụng tài nguyên tuỳ chỉnh PodMonitoring, nên Cloud Monitoring sẽ thu thập các chỉ số từ vùng chứa vLLM trên cổng 8000. Bạn có thể chuyển đến Google Cloud Console Giám sát -> Trang tổng quan để xem các chỉ số như độ trễ tạo mã thông báo, độ dài hàng đợi và mức sử dụng bộ nhớ đệm KV một cách tự nhiên.
7. Dọn dẹp
- Xoá các tài nguyên bằng cách chạy lệnh sau.
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- Dọn dẹp cơ sở hạ tầng bằng lệnh sau, nhập
yesđể xác nhận
terraform destroy
8. Xin chúc mừng
Bạn đã triển khai thành công môi trường DRANET được quản lý trên GKE Autopilot, cung cấp phần cứng TPU v6e một cách linh hoạt và phân phát mô hình Gemma 4 có 31 tỷ tham số khổng lồ bằng vLLM.
Bằng cách sử dụng GKE Autopilot, bạn cho phép Kubernetes xử lý việc cung cấp nút cơ bản và quản lý cơ sở hạ tầng, giúp bạn hoàn toàn tập trung vào việc triển khai khối lượng công việc AI.
Các bước tiếp theo / Tìm hiểu thêm
Bạn có thể đọc thêm về mạng GKE
Thực hiện lớp học lập trình tiếp theo
Tiếp tục hành trình của bạn với Google Cloud và xem các lớp học lập trình khác của Google Cloud sau: