
1. 概览
本实验将向您介绍可用于运行 AI 工作负载的 AI 基础设施。您将使用以下内容:
Google Kubernetes Engine (GKE) - 基础容器编排平台。
GKE 代管式 DRANET - 动态资源分配网络,可将高速互连结构直接分配给您的 TPU Pod。
张量处理单元 (TPU) - Google 自行构建的加速器芯片。
如需进行配置,您将部署自定义 VPC 和 Autopilot GKE 集群。如需启用代管式 DRANET,您将创建 ComputeClass 和资源声明模板。然后,您将部署使用 vLLM、 Hugging Face、 ComputeClass 和 资源声明模板的工作负载。最后,您将测试网络设置和与 Gemma 4 模型的连接。
这些配置将结合使用 Terraform、gcloud 和 kubectl。
在本实验中,您将学习如何执行以下任务:
- 设置 VPC 网络
- 设置 GKE Autopilot 集群
- 创建 ComputeClass 和 ResourceClaimTemplate。
- 创建一个部署,该部署通过 Hugging Face 运行 TPU、vLLM、监控和 Gemma 4
- 测试与 LLM 的连接
在本实验中,您将创建以下模式。
图 1. 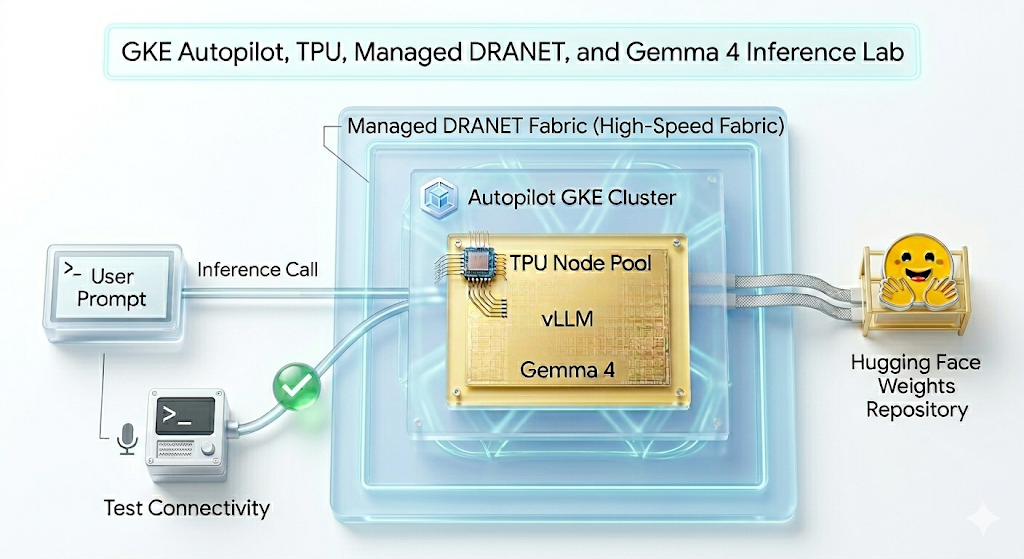
2. Google Cloud 服务设置
自定进度的环境设置
- 登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须 创建一个。

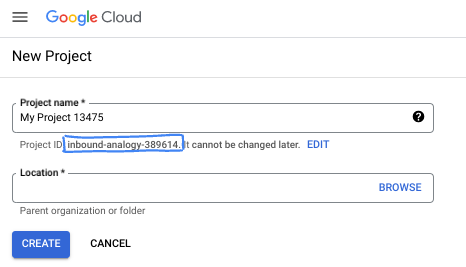
- 项目名称 是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
- 接下来,您需要在 Cloud 控制台中启用结算功能,以便使用 Cloud 资源/API。运行此 Codelab 应该不会产生太多的费用(如果有的话)。若要关闭资源以避免产生超出本教程范围的结算费用,您可以删除自己创建的资源或删除项目。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
3. 使用 Terraform 设置环境
如需完成本实验,您需要访问 TPU。使用的确切版本是 TPU v6e。
- 您应按照 TPU 计划文档中的说明 启用 TPU 配额,以获取访问权限。
- 我们使用的是小型部署,需要 4 个 TPU v6e 芯片 (
ct6e-standard-4t)这将是单个区域中的 2x2 切片。 - Hugging Face 令牌:需要 访问令牌 才能下载 Gemma 模型权重
我们将创建具有防火墙规则的自定义 VPC、子网,然后创建 Autopilot 集群。打开 Cloud 控制台,然后选择要使用的项目。
- 打开 Cloud Shell(位于控制台右上角),确保在 Cloud Shell 中看到正确的 项目 ID ,确认所有提示以允许访问。

- 创建一个名为
gke-auto-tpu的文件夹,然后移至该文件夹
mkdir -p gke-auto-tpu && cd gke-auto-tpu
export PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
- 现在,添加一些配置文件。这些文件将创建以下 terraform.tfvars 、variables.tf 和 net.tf 文件。
cat << EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat << 'EOF' > variables.tf
variable "project_id" {
type = string
}
variable "region" {
type = string
default = "us-east5"
}
variable "network_name" {
type = string
default = "tpu-gke-vpc"
}
variable "subnet_name" {
type = string
default = "tpu-sub1"
}
variable "cluster_name" {
type = string
default = "tpu-auto-dra-cluster"
}
EOF
cat << 'EOF' > net.tf
terraform {
required_version = ">= 1.5.0"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 7.32.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
resource "google_compute_network" "tpu_vpc" {
project = var.project_id
name = var.network_name
auto_create_subnetworks = false
mtu = 8896
}
resource "google_compute_subnetwork" "tpu_subnet" {
project = var.project_id
name = var.subnet_name
ip_cidr_range = "192.168.100.0/24"
region = var.region
network = google_compute_network.tpu_vpc.id
}
resource "google_compute_firewall" "allow_ssh" {
project = var.project_id
name = "${var.network_name}-allow-ssh"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "tcp"
ports = ["22"]
}
source_ranges = ["0.0.0.0/0"]
}
resource "google_compute_firewall" "allow_internal" {
project = var.project_id
name = "${var.network_name}-allow-internal"
network = google_compute_network.tpu_vpc.id
direction = "INGRESS"
priority = 1000
allow {
protocol = "all"
}
source_ranges = ["172.16.0.0/12", "192.168.0.0/16"]
}
resource "google_container_cluster" "tpu_autopilot" {
project = var.project_id
name = var.cluster_name
location = var.region
enable_autopilot = true
network = google_compute_network.tpu_vpc.id
subnetwork = google_compute_subnetwork.tpu_subnet.id
release_channel {
channel = "RAPID"
}
ip_allocation_policy {}
deletion_protection = false
}
EOF
- 确保您位于 gke-auto-tpu 目录中,然后运行以下命令
terraform init初始化工作目录。这是第一步,它会下载给定配置所需的提供程序。terraform plan -out会生成执行计划,显示 Terraform 将采取哪些操作来部署您的基础架构。借助-out,您可以将执行计划保存到命名的二进制文件中。您无需进行任何更改即可查看会发生什么情况。terraform apply运行更新。
terraform init
terraform plan -out vpc
- 现在,在运行
terraform apply后运行部署,因为您要应用已保存的执行计划,因此它会立即执行,而不会提示您进行确认(这可能需要 6 到 10 分钟)
terraform apply vpc
- 验证设置
echo -e "\n=== Verifying GKE Autopilot Cluster ==="
gcloud container clusters list --filter="name:tpu-auto-dra-cluster" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Subnetwork ==="
gcloud compute networks subnets list --filter="name:tpu-sub1" --project=$PROJECT_ID
echo -e "\n=== Verifying Firewall Rules ==="
gcloud compute firewall-rules list --filter="name~tpu-gke-vpc-allow" --project=$PROJECT_ID
4. 创建 ComputeClass 和资源声明模板
我们需要创建一个自定义 ComputeClass 资源来定义节点池的配置。在我们的示例中,我们将使用 TPU v6e 芯片 (ct6e-standard-4t) 和代管式 DRANET 网络。
- 连接到您创建的集群。(附注:将区域更改为您部署集群的区域。)
gcloud container clusters get-credentials tpu-auto-dra-cluster --region us-east5 --project=$PROJECT_ID
- 确保您位于
gke-auto-tpu目录中,然后运行以下命令。这将创建 ComputeClass 清单。请注意,如果您使用了其他区域,则需要将可用区信息更改为集群所在区域内的可用区
cat << 'EOF' > computeclass.yaml
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dranet-auto
spec:
nodePoolAutoCreation:
enabled: true
nodePoolConfig:
dra:
networking:
enabled: true
priorities:
- tpu:
type: tpu-v6e-slice
count: 4
topology: "2x2"
acceleratorNetworkProfile: auto
location:
zones:
- us-east5-b
EOF
- 现在,创建 ComputeClass。
kubectl apply -f computeclass.yaml
kubectl describe computeclass dranet-auto
- 在
gke-auto-tpu目录中,运行以下命令。这将创建支持 非 RDMA 网络设备的 ResourceClaimTemplate 清单。
cat << 'EOF' > resourceclaimtpu.yaml
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
EOF
- 现在,创建 ResourceClaimTemplate。
kubectl apply -f resourceclaimtpu.yaml
kubectl describe resourceclaimtemplate all-netdev
创建您的 Secret
- 本实验使用 google/gemma-4-31B-it ,因此您需要 创建 HF 令牌。将下面的
YOUR_ACTUAL_HUGGING_FACE_TOKEN替换为您的实际令牌。
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- 确保您位于
gke-auto-tpu目录中,然后运行以下命令。
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN}
kubectl get secrets hf-secret
5. 部署工作负载 vLLM 和 Gemma
此设置使用 ComputeClass 自动预配所需的硬件和网络(TPU v6e 和代管式 DRANET)。它使用 ResourceClaimTemplate 定义请求访问该高速网络的蓝图,以及一个部署 ,该部署通过为每个 Pod 生成单独的网络声明来将它们绑定在一起。
- 确保您位于
gke-auto-tpu目录中,然后运行以下命令。
cat << 'EOF' > gem4-auto-dra-tpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gem4-dra-auto
spec:
replicas: 1
selector:
matchLabels:
app: gemma4-tpu
template:
metadata:
labels:
app: gemma4-tpu
ai.gke.io/model: gemma-4-31b-it
ai.gke.io/inference-server: vllm-tpu
spec:
dnsPolicy: Default
resourceClaims:
- name: netdev-claim
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu-inference
image: vllm/vllm-tpu:latest
resources:
requests:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
limits:
cpu: "30"
memory: "240Gi"
ephemeral-storage: "100Gi"
google.com/tpu: "4"
claims:
- name: netdev-claim
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model=$(MODEL_ID)
- --tensor-parallel-size=4
- --host=0.0.0.0
- --port=8000
- --max-model-len=32768
- --max-num-batched-tokens=8192
env:
- name: MODEL_ID
value: google/gemma-4-31B-it
- name: HUGGING_FACE
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
volumeMounts:
- mountPath: /dev/shm
name: dshm
startupProbe:
httpGet:
path: /health
port: 8000
failureThreshold: 240
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
periodSeconds: 5
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
cloud.google.com/compute-class: dranet-auto
---
apiVersion: v1
kind: Service
metadata:
name: gem4-dra-service
spec:
selector:
app: gemma4-tpu
type: ClusterIP
ports:
- protocol: TCP
port: 8000
targetPort: 8000
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gem4-monitoring
spec:
selector:
matchLabels:
app: gemma4-tpu
endpoints:
- port: 8000
path: /metrics
interval: 30s
EOF
- 创建部署。
kubectl apply -f gem4-auto-dra-tpu.yaml
- 如需监控完成状态,请运行以下命令。Pod 将等到节点预配完成后才能继续,这可能需要 13 分钟以上 。
kubectl get pods
kubectl get deployments
kubectl describe pods -l app=gemma4-tpu
echo " __|__"
echo " --@--(_|_)--@--"
echo ""
echo "Waiting for Autopilot to register the TPU node (this takes a few minutes)..."
until kubectl get nodes -l gke.networks.io/accelerator-network-profile=auto -o name | grep -q "node/"; do
sleep 60
done
echo "TPU Node detected in cluster! Waiting for hardware to provision and become Ready..."
kubectl wait --for=condition=Ready nodes -l gke.networks.io/accelerator-network-profile=auto --timeout=900s
- 创建节点并调度 Pod 后,您可以运行该命令来查看 Pod 的日志。(附注:您可以添加 **
-f** **标志进行流式传输** )。如果您在看到字符串(APIServer pid=1) INFO: 169.254.4.6:44290 - "GET /health HTTP/1.1" 200 OK时观看日志,则完成此操作最多需要 **15 分钟以上** ,表示模型已准备好提供服务。
kubectl logs -l app=gemma4-tpu -f | sed -u '\,"GET /health HTTP/1.1" 200 OK,q'
- 部署可用后,您可以验证高速网络是否已正确连接到您的 TPU Pod。运行以下命令:
for pod in $(kubectl get pods -l app=gemma4-tpu -o name); do
echo "=== Checking Networking for $pod ==="
kubectl exec $pod -- ls /sys/class/net
echo ""
done
需要注意的事项 :您应该看到标准 eth0 以及额外的接口,例如 eth1 到 ethxx 。
这些额外的接口确认高速代管式 DRANET 结构已成功连接到您的 Pod。
6. 使用 curl 与 AI 模型互动
如需验证您部署的 gemma-4-31B 模型,请设置从服务到本地机器的端口转发。
- 在当前的 Cloud Shell 中运行此命令:
kubectl port-forward service/gem4-dra-service 8000:8000 &
- 现在,为同一项目打开一个额外的 Cloud Shell 窗口,以使用
curl与模型聊天。此命令会发送提示,并将输出直接流式传输到您的终端。
time curl -sN http://127.0.0.1:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-31B-it",
"messages": [
{
"role": "user",
"content": "How can GKE help deployment of AI workloads? Provide concise information. Keep the explanation under 300 words."
}
],
"max_tokens": 1024,
"temperature": 0.7,
"stream": true,
"stream_options": {"include_usage": true}
}' | grep '^data:' | sed 's/^data: //' | grep -v '\[DONE\]' | jq --unbuffered -j '
(.choices[0].delta.content // empty),
if .usage then "\n\n--- Usage ---\nPrompt: \(.usage.prompt_tokens)\nCompletion: \(.usage.completion_tokens)\nTotal: \(.usage.total_tokens)\n" else empty end
'
- 查看模型的回应
可观测性
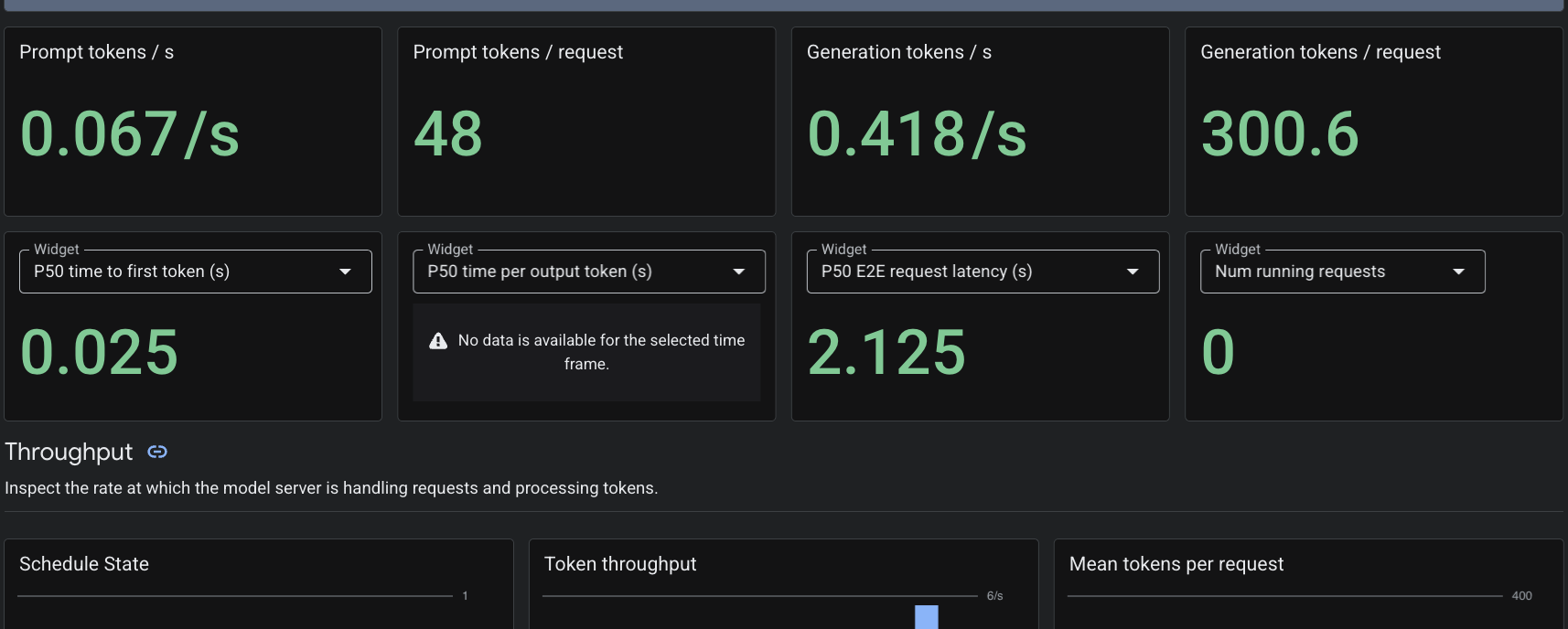
由于我们应用了 PodMonitoring 自定义资源,因此 Cloud Monitoring 将从端口 8000 上的 vLLM 容器中抓取指标。您可以前往 Google Cloud 控制台 的 监控 -> 信息中心 ,以原生方式查看令牌生成延迟时间、队列长度和 KV 缓存使用情况等指标。
7. 清理
- 运行以下命令以删除资源。
cd ~/gke-auto-tpu
kubectl delete -f gem4-auto-dra-tpu.yaml
kubectl delete -f resourceclaimtpu.yaml
kubectl delete -f computeclass.yaml
kubectl delete secret hf-secret
- 使用以下命令清理基础架构,输入
yes进行确认
terraform destroy
8. 恭喜
您已在 GKE Autopilot 上成功部署代管式 DRANET 环境,动态预配 TPU v6e 硬件,并使用 vLLM 提供 310 亿参数 Gemma 4 模型。
通过使用 GKE Autopilot,您可以让 Kubernetes 处理底层节点预配和基础架构管理,从而让您完全专注于部署 AI 工作负载。
后续步骤 / 了解详情
您可以详细了解 GKE 网络
参与下一项实验
继续探索 Google Cloud,并查看以下其他 Google Cloud 实验: