
1. نظرة عامة
يقدّم لك هذا التمرين المعملي "البنية الأساسية للذكاء الاصطناعي" التي يمكن استخدامها لتشغيل أحمال عمل الذكاء الاصطناعي. ستعمل على ما يلي:
Google Kubernetes Engine (GKE): هي منصة أساسية لتنظيم الحاويات.
شبكة DRANET المُدارة في GKE: شبكة لتخصيص الموارد الديناميكي، وتعمل على تخصيص بنى أساسية للربط البيني عالي السرعة مباشرةً لحِزم وحدات TPU.
GKE Inference Gateway: هذا كائن بوابة مُدار من Google Cloud ومكيّف للاستدلال. في هذه الحالة، سنستخدم إمكانات المجموعات المتعددة.
وحدة معالجة الموتّرات (TPU): شرائح تسريع مخصّصة من Google.
Cloud Storage FUSE: هي واجهة تخزين تتيح لوحدات pod ربط حِزم Cloud Storage مباشرةً، ما يتيح تحميل أوزان النماذج الضخمة على الفور.
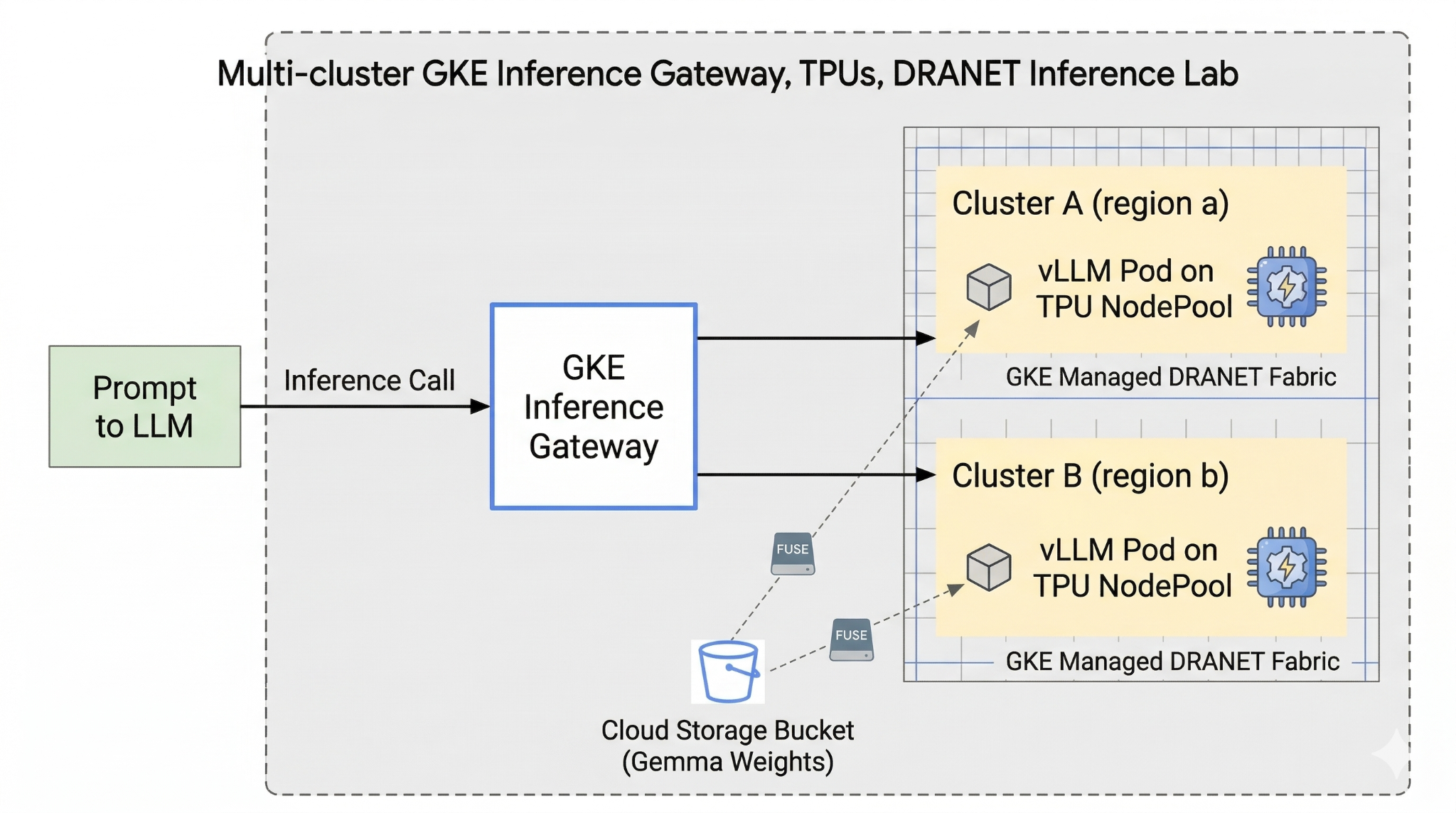
لضبط الإعدادات، عليك نشر شبكة VPC مخصّصة وحزمة Cloud Storage ومجموعتَين في مناطق مختلفة. ستحتوي كل مجموعة على مجموعة عقدة لوحدة معالجة Tensor باستخدام شبكة DRANET المُدارة للشبكات. بعد إضافة المجموعات إلى Fleet، ستخزّن أوزان نموذج Gemma مؤقتًا في الحزمة وتنشر عبء عمل vLLM الذي يركّب هذه الأوزان على الفور من خلال Cloud Storage FUSE. أخيرًا، سيتم ضبط GKE Inference Gateway لتوجيه الزيارات، ما يتيح لك إجراء اختبار مباشر لتجاوز الأعطال في مناطق متعددة.
ستستخدم الإعدادات مزيجًا من Terraform وgcloud وkubectl.
في هذه الميزة الاختبارية، ستتعرّف على كيفية تنفيذ المهمة التالية:
- إعداد شبكة VPC والشبكات ومساحة التخزين
- إعداد مجموعة GKE في الوضع العادي
- إنشاء مجموعة عقد TPU واستخدام DRANET المُدارة
- إضافة مجموعة إلى أسطول
- تخزين أوزان النماذج مؤقتًا
- إعداد بوابة GKE Inference متعددة المجموعات واختبار تجاوز الأعطال
في هذا التمرين العملي، ستنشئ النمط التالي.
الشكل 1.
2. إعداد خدمات Google Cloud
إعداد البيئة بالسرعة التي تناسبك
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.

- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديلها في أي وقت.
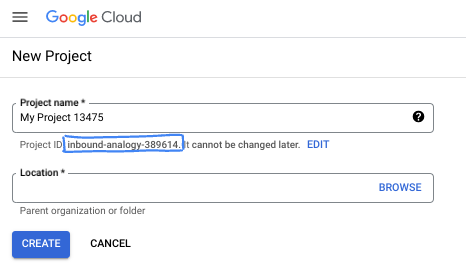
- رقم تعريف المشروع هو معرّف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره بعد ضبطه. تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك (يُشار إليه عادةً باسم
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم من اختيارك ومعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير، إن وُجدت أي تكلفة على الإطلاق. لإيقاف الموارد وتجنُّب تحمّل تكاليف فوترة تتجاوز هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:
لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- إعداد البيئة باستخدام Terraform
لإجراء هذا التدريب العملي، يجب أن يكون لديك إذن الوصول إلى وحدات TPU. الإصدار الدقيق المستخدَم هو TPU v6e.
- عليك اتّباع مستند خطة TPU وتفعيل حصة TPU للحصول على إذن الوصول.
- نستخدم عملية نشر صغيرة تتطلّب 4 شرائح TPU v6e (
ct6e-standard-4t)والتي ستكون شريحة 2x2 في منطقتَين مختلفتَين. - Hugging Face Token: يجب توفير رمز دخول لتنزيل أوزان نموذج Gemma
سننشئ شبكة VPC مخصّصة تتضمّن قواعد جدار الحماية والتخزين والشبكة الفرعية. افتح Cloud Console واختَر المشروع الذي ستستخدمه.
- افتح Cloud Shell في أعلى يسار وحدة التحكّم، وتأكَّد من ظهور رقم تعريف المشروع الصحيح في Cloud Shell، وأكِّد أي طلبات تظهر لك للسماح بالوصول.

- أنشئ مجلدًا باسم
gke-tfوانتقِل إليه
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- الآن، أضِف بعض ملفات الإعداد. سيؤدي ذلك إلى إنشاء الملفات التالية: network.tf وvariable.tf وproviders.tf وfuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
يضيف ملف variable.tf اسم المشروع والمناطق ومعلومات المنطقة. ملاحظة: عدِّل المُتغيِّر "regions" default = ["europe-west4", "us-east5"] باستخدام المناطق التي يتوفّر فيها حصة من وحدات معالجة الموتّرات. لمزيد من المعلومات، راجِع المستند " التحقّق من توفّر وحدات TPU في GKE".
يضيف الرمز network.tf شبكة VPC جديدة إلى مشروعك مع شبكات فرعية في منطقتَين مختلفتَين، وشبكات فرعية للخادم الوكيل فقط، وقواعد جدار الحماية.
يضيف provider.tf مقدّم الخدمة ذي الصلة لدعم Terraform
يضيف fuse.tf حزمة Cloud Storage لتخزين أوزان النموذج مؤقتًا، كما يوفّر حساب خدمة IAM مزوّدًا بأذونات objectAdmin. يربط هذا الحساب بميزة Workload Identity في GKE
- تأكَّد من أنّك في الدليل gke-tf ونفِّذ الأوامر التالية
terraform init -لتهيئة دليل العمل. تنزّل هذه الخطوة موفّري الخدمات المطلوبين للإعدادات المحدّدة.terraform plan -إنشاء خطة تنفيذ توضّح الإجراءات التي سيتّخذها Terraform لنشر البنية الأساسية تنفّذterraform apply –auto-approveالتحديثات وتوافق عليها تلقائيًا.
terraform init
terraform plan
- الآن، شغِّل عملية النشر (قد يستغرق ذلك بين 3 و5 دقائق).
terraform apply -auto-approve
- في مجلد
gke-tfنفسه، أنشئ ملف gke.tf التالي.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
تضيف gke.tf مجموعتَين في منطقتَين مختلفتَين، وتنشئ مجموعتَي عقد TPU تعملان على TPU v6e مع 4 شرائح، وتعيّن DRANET المُدارة لمجموعات العقد.
- الآن، شغِّل عملية النشر (قد تستغرق هذه العملية بين 10 و15 دقيقة).
terraform apply -auto-approve
- تأكيد
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. تسجيل الأسطول
علينا تسجيل المجموعة في Fleet.
- تأكَّد من أنّك في دليل
gke-tfونفِّذ الأوامر التالية.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
يسجّل ملف fleet.tf المجموعتين في أسطول GKE عالمي ويتيح ميزة "اكتشاف الخدمات المتعددة المجموعات" وIngress. يحدّد هذا الحقل مجموعة الخوادم في الولايات المتحدة كمجموعة خوادم مركزية للإعدادات، ما يتيح لواجهة Gateway API مراقبة حركة البيانات وتوجيهها.
- في المجلد
gke-tf، شغِّل (من المفترض أن يستغرق ذلك من 3 إلى 5 دقائق)
terraform plan
terraform apply -auto-approve
- التحقّق من صحة تسجيل Fleet
gcloud container fleet memberships list --project=$PROJECT_ID
5- تخزين أوزان النموذج مؤقتًا في نظام الملفات FUSE
سننفّذ مهمة Kubernetes مؤقتة في مجموعة الخوادم في الولايات المتحدة لتنزيل نموذج Gemma بشكل آمن من خلال نص برمجي بلغة Python مباشرةً إلى حزمة Cloud Storage التي تم تركيبها باستخدام نظام الملفات في مساحة المستخدم (FUSE).
- إنشاء المتغيرات التالية
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- يستخدم هذا النموذج google/gemma-3-27b-it، لذا عليك إنشاء رمز مميز على HF. استبدِل
YOUR_ACTUAL_HUGGING_FACE_TOKENأدناه بالرمز المميّز الفعلي.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- تأكَّد من أنّك في دليل
gke-tfونفِّذ الأوامر التالية.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- انتظِر إلى أن ينتهي التنزيل قبل المتابعة (من المفترض أن يستغرق ذلك من 5 إلى 10 دقائق حسب حجم النموذج)
kubectl logs -f job/model-downloader --context=$CTX_US
(اضغط على Ctrl+C للخروج من السجلات بعد ظهور الرسالة "اكتمل التنزيل").
6. نشر حمل عمل vLLM وGemma
- تأكَّد من أنّك في دليل
gke-tfونفِّذ الأوامر التالية.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- الآن، شغِّل النص البرمجي التالي (سيستغرق إكماله ما بين 5 و10 دقائق لأنّه يتم نشره في منطقتَين)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- تأكيد النشر
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- بعد اكتمال العملية، يمكنك التأكّد من أنّه تمّ تعيين شبكة DRANET المُدارة إلى وحدات pod من خلال تنفيذ ما يلي:
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
ستظهر لك واجهات شبكة إضافية eth0 للربط الشبكي العادي بين وحدات Pod، بالإضافة إلى واجهات ثانوية تمثّل بنية TPU المخصّصة eth1 وeth2 وما إلى ذلك.
7. Inference API وإعدادات البوابة
ستنشئ الآن InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) وInference Pool(gemma-pool). يتم إنشاء مجموعة الاستدلال باستخدام مخطط Helm. يتم تثبيت عملية الإنشاء والتحقّق منها.
- تأكَّد من أنّك في دليل
gke-tfونفِّذ الأوامر التالية. سيؤدي ذلك إلى نشر العنصر وتشغيل عملية التحقّق من صحته.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. إعدادات البوابة
ستنشئ الآن إعدادات Cross-Regional Gateway. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. يتم إنشاء مجموعة الاستدلال باستخدام مخطط Helm. يتم تثبيت عملية الإنشاء والتحقّق منها. (سيستغرق تفعيل البوابة من 8 إلى 10 دقائق)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
مجموعة الاستدلال (Helm): تجمع خوادم النماذج من كلتا المنطقتين في خلفية منطقية واحدة.
Gateway وHTTPRoute: ينشئان جهاز موازنة الحمل الداخلي الشامل الفعلي ويحدّدان قواعد توجيه طلبات الذكاء الاصطناعي الواردة إلى نماذجك.
سياسات HealthCheck والخلفية: تضمن إرسال الطلبات إلى وحدات صحية فقط وتتيح توزيع الزيارات الذكي المستند إلى المقاييس (ما يمنع التحميل الزائد على وحدات TPU).
التحقّق من الصحة: يتوقف النص البرمجي مؤقتًا للتأكّد من أنّ Google Cloud قد وفّر عناوين IP الداخلية بالكامل قبل الانتقال إلى الخطوة التالية.
9- اختبار تجاوز الأعطال
والآن، ننتقل إلى الجزء الأفضل من المختبر: اختبار إمكانية التوفّر العالية لبنيتك.
في ما يلي الإجراءات التي سيتّخذها هذا الاختبار المبرمَج بالضبط:
- اختبار الأداء الأساسي: يرسل المستخدم المحاكي طلب استنتاج ("ما هي عاصمة فرنسا؟"). بما أنّ المستخدم يقع في المنطقة الأساسية، يوجّه البوابة الطلب إلى وحدات TPU المحلية هذه للحصول على أقل وقت استجابة ممكن.
- الكارثة: نحاكي انقطاعًا كارثيًا في مركز البيانات من خلال إيقاف جميع وحدات TPU في المنطقة الأساسية (
replicas=0). - عملية الرصد: ننتظر 45 ثانية. خلال هذه الفترة، ستفشل عمليات التحقّق من سلامة البوابة، وستدرك أنّ الخلفية الأساسية غير متصلة بالإنترنت تمامًا، وستعدّل جداول التوجيه العامة بشكلٍ ديناميكي.
- الطلب الاحتياطي: يرسل المستخدم طلبًا ثانيًا ("ما هي عاصمة ألمانيا؟"). لا يعلم المستخدم بحدوث انقطاع. تعترض البوابة الطلب وتعيد توجيهه على الفور إلى وحدات TPU الثانوية السليمة في جميع أنحاء العالم.
- الاسترداد: نستعيد وحدات TPU الأساسية، ما يؤدي إلى استعادة سلامة البنية الأساسية العالمية بالكامل.
- افتح Cloud Shell وشغِّل ما يلي:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- بعد الانتهاء من الاختبار، يمكنك إخلاء مساحة.
10. تَنظيم
- إخلاء مساحة عبء العمل
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- إخلاء مساحة البنية الأساسية تأكَّد من أنّك في المجلد
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
في حال واجهت أي مشاكل في حذف الموارد المحدّدة، عليك إعادة تشغيل terraform destroy نص الأوامر ./cleanup-tf.sh
11. تهانينا
تهانينا! لقد تمكّنت من نشر بوابة GKE Inference Gateway عالية التوفّر ومتعددة المجموعات، وبنية استنتاج الذكاء الاصطناعي على مستوى مناطق متعددة باستخدام GKE، ومسرّعات DRANET ووحدة معالجة الموتّرات v6e المُدارة.
من خلال الجمع بين Cloud Storage FUSE لتحميل النماذج على الفور وInference Gateway API لتوجيه الطلبات إلى عدة مجموعات مع مراعاة وقت الاستجابة، تمكّنت من إنشاء نظام خلفي مرن يمكنه تجاوز انقطاع كامل في مركز البيانات الإقليمي بدون خفض عدد الزيارات من المستخدمين الداخليين.
الخطوات التالية / مزيد من المعلومات
يمكنك الاطّلاع على مزيد من المعلومات حول شبكات GKE.
الدرس التطبيقي التالي
يمكنك مواصلة رحلتك مع Google Cloud، والاطّلاع على هذه المختبرات الأخرى في Google Cloud: