
1. Übersicht
In diesem Lab erhalten Sie eine Einführung in die KI-Infrastruktur, die für die Ausführung von KI-Arbeitslasten verwendet werden kann. Sie arbeiten mit Folgendem:
Google Kubernetes Engine (GKE): Die grundlegende Containerorchestrierungsplattform.
GKE Managed DRANET: Dynamic Resource Allocation Networking, das Ihren TPU-Pods direkt Hochgeschwindigkeits-Interconnect-Fabrics zuweist.
GKE Inference Gateway: Dies ist ein verwaltetes Gateway-Objekt von Google Cloud, das für die Inferenz angepasst ist. In diesem Fall verwenden wir die Multi-Cluster-Funktionen.
Tensor Processing Unit (TPU): von Google entwickelte Beschleunigerchips.
Cloud Storage FUSE: Eine Speicherschnittstelle, mit der Pods Cloud Storage-Buckets direkt bereitstellen können, sodass massive Modellgewichte sofort geladen werden können.
Für die Konfiguration stellen Sie eine benutzerdefinierte VPC, einen Cloud Storage-Bucket und zwei Cluster in verschiedenen Regionen bereit. Jeder Cluster hat einen TPU-Knotenpool, der für die Vernetzung verwaltetes DRANET verwendet. Nachdem Sie die Cluster einer Flotte hinzugefügt haben, werden die Gemma-Modellgewichte in Ihrem Bucket zwischengespeichert und Sie stellen eine vLLM-Arbeitslast bereit, die diese Gewichte sofort über Cloud Storage FUSE bereitstellt. Schließlich wird das GKE Inference Gateway so konfiguriert, dass Traffic weitergeleitet wird. So können Sie einen Live-Failover-Test über mehrere Regionen hinweg durchführen.
Für die Konfigurationen wird eine Kombination aus Terraform, gcloud und kubectl verwendet.
In diesem Lab lernen Sie Folgendes:
- VPC, Netzwerke und Speicher einrichten
- GKE-Cluster im Standardmodus einrichten
- TPU-Knotenpool erstellen und verwaltetes DRANET verwenden
- Cluster in Flotte aufnehmen
- Modellgewichte im Cache speichern
- Multi-Cluster-GKE-Inference-Gateway einrichten und Failover testen
In diesem Lab erstellen Sie das folgende Muster.
Abbildung 1:
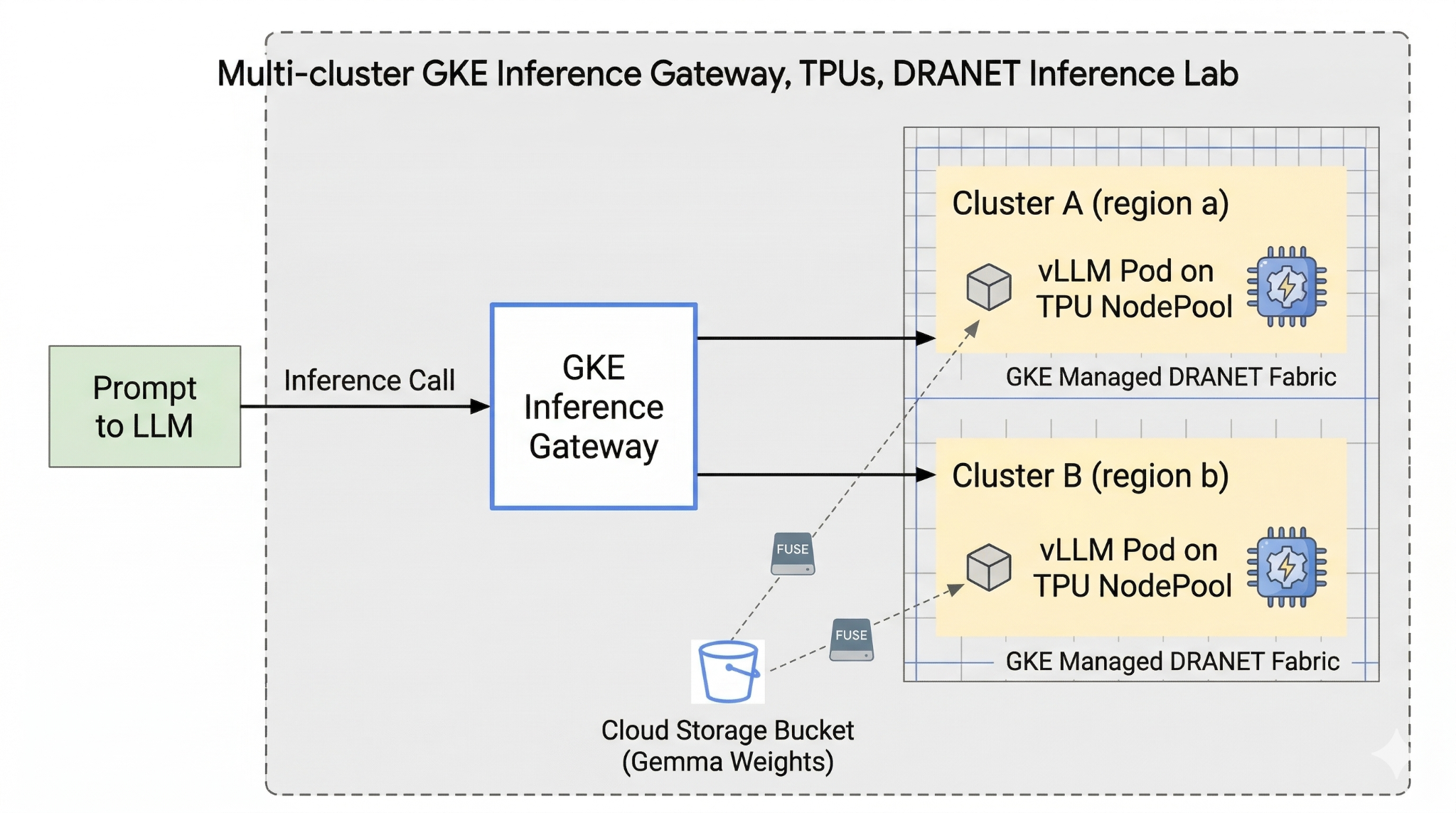
2. Google Cloud-Dienste einrichten
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Umgebung mit Terraform einrichten
Für dieses Lab benötigen Sie Zugriff auf TPUs. Die genaue verwendete Version ist TPU v6e.
- Folgen Sie der Dokumentation zum TPU-Plan und aktivieren Sie das TPU-Kontingent, um Zugriff zu erhalten.
- Wir verwenden eine kleine Bereitstellung mit 4 TPU v6e-Chips (
ct6e-standard-4t), was einem 2 × 2-Slice in zwei verschiedenen Regionen entspricht. - Hugging Face-Token: Zum Herunterladen der Gemma-Modellgewichte ist ein Zugriffstoken erforderlich.
Wir erstellen eine benutzerdefinierte VPC mit Firewallregeln, Speicher und Subnetz. Öffnen Sie die Cloud Console und wählen Sie das Projekt aus, das Sie verwenden möchten.
- Öffnen Sie Cloud Shell oben rechts in der Konsole. Prüfen Sie, ob die richtige Projekt-ID in Cloud Shell angezeigt wird, und bestätigen Sie alle Aufforderungen, den Zugriff zuzulassen.

- Erstellen Sie einen Ordner mit dem Namen
gke-tfund wechseln Sie zu diesem Ordner.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Fügen Sie nun einige Konfigurationsdateien hinzu. Dadurch werden die folgenden Dateien erstellt: network.tf, variable.tf, providers.tf und fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
In der Datei variable.tf werden der Projektname, die Regionen und die Zoneninformationen hinzugefügt. Aktualisieren Sie die Variable „regions“ , default = ["europe-west4", "us-east5"] mit den Regionen, in denen Sie ein TPU-Kontingent haben. Weitere Informationen finden Sie in diesem Dokument unter TPU-Verfügbarkeit in GKE prüfen.
Mit dem network.tf wird in Ihrem Projekt eine neue VPC mit Subnetzen in zwei verschiedenen Zonen, Nur-Proxy-Subnetzen und Firewallregeln hinzugefügt.
Mit provider.tf wird der relevante Anbieter hinzugefügt, um Terraform zu unterstützen.
Mit dem fuse.tf wird der Cloud Storage-Bucket zum Zwischenspeichern der Modellgewichte hinzugefügt und ein IAM-Dienstkonto mit „objectAdmin“-Berechtigungen bereitgestellt. Dieses Konto wird an die GKE-Workloadidentität gebunden.
- Achten Sie darauf, dass Sie sich im Verzeichnis gke-tf befinden, und führen Sie die folgenden Befehle aus.
terraform init -Initialisiert das Arbeitsverzeichnis. In diesem Schritt werden die für die angegebene Konfiguration erforderlichen Anbieter heruntergeladen.terraform plan -Generiert einen Ausführungsplan, der zeigt, welche Aktionen Terraform zum Bereitstellen Ihrer Infrastruktur ausführt.terraform apply –auto-approveführt die Updates aus und genehmigt sie automatisch.
terraform init
terraform plan
- Führen Sie nun die Bereitstellung aus. Das kann 3 bis 5 Minuten dauern.
terraform apply -auto-approve
- Erstellen Sie im selben
gke-tf-Ordner die folgende gke.tf-Datei.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
Mit dem gke.tf werden zwei Cluster in verschiedenen Regionen hinzugefügt und zwei TPU-Knotenpools erstellt, auf denen die TPU v6e mit 4 Chips ausgeführt wird. Außerdem wird der verwaltete DRANET den Knotenpools zugewiesen.
- Führen Sie nun die Bereitstellung aus. Das kann 10 bis 15 Minuten dauern.
terraform apply -auto-approve
- Bestätigen
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Flottenregistrierung
Wir müssen den Cluster in einer Flotte registrieren.
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-tfbefinden, und führen Sie die folgenden Befehle aus.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
Mit der Datei fleet.tf werden beide Cluster in einer globalen GKE Fleet registriert und Multi-Cluster-Service-Discovery und Ingress aktiviert. Damit wird der US-Cluster als zentraler Konfigurationscluster festgelegt, sodass die Gateway API Traffic überwachen und weiterleiten kann.
- Führen Sie im Ordner
gke-tfaus(dies sollte 3–5 Minuten dauern).
terraform plan
terraform apply -auto-approve
- Flottenregistrierung validieren
gcloud container fleet memberships list --project=$PROJECT_ID
5. Modellgewichte in FUSE zwischenspeichern
Wir führen einen temporären Kubernetes-Job im US-Cluster aus, um das Gemma-Modell sicher über ein Python-Script direkt in den FUSE-gemounteten Cloud Storage-Bucket herunterzuladen.
- Erstellen Sie die folgenden Variablen.
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- Dazu wird das Modell google/gemma-3-27b-it verwendet. Sie müssen also ein HF-Token erstellen. Ersetzen Sie
YOUR_ACTUAL_HUGGING_FACE_TOKENunten durch Ihr tatsächliches Token.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-tfbefinden, und führen Sie die folgenden Befehle aus.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Warten Sie, bis der Download abgeschlossen ist, bevor Sie fortfahren (das sollte je nach Modellgröße 5–10 Minuten dauern).
kubectl logs -f job/model-downloader --context=$CTX_US
Drücken Sie Ctrl+C, um die Logs zu beenden, sobald „Download abgeschlossen!“ angezeigt wird.
6. Workload-vLLM und Gemma bereitstellen
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-tfbefinden, und führen Sie die folgenden Befehle aus.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Führen Sie nun das folgende Skript aus. Die Ausführung dauert 5 bis 10 Minuten, da es in zwei Regionen bereitgestellt wird.
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Deployment bestätigen
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- Anschließend können Sie mit dem folgenden Befehl prüfen, ob den Pods das verwaltete DRANET-Netzwerk zugewiesen wurde.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Neben den sekundären Schnittstellen, die Ihr dediziertes TPU-Fabric darstellen (eth1, eth2 usw.), sehen Sie zusätzliche Netzwerkschnittstellen eth0 für das Standard-Pod-Netzwerk.
7. Inference API und Gateway-Konfiguration
Jetzt erstellen Sie die InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) und Inference Pool(gemma-pool). Der Inferenzpool wird mit einem Helm-Chart erstellt. Die Erstellung wird installiert und validiert.
- Achten Sie darauf, dass Sie sich im Verzeichnis
gke-tfbefinden, und führen Sie die folgenden Befehle aus. Dadurch wird das Objekt bereitgestellt und eine Validierung ausgeführt.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Gateway-Konfiguration
Als Nächstes erstellen Sie die Konfiguration für das Cross-Regional Gateway. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. Der Inferenzpool wird mit einem Helm-Chart erstellt. Die Erstellung wird installiert und validiert. Es dauert 8–10 Minuten, bis das Gateway aktiviert ist.
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Inference Pool (Helm): Gruppiert Ihre Modellserver aus beiden Regionen in einem einzigen logischen Backend.
Gateway & HTTPRoute: Erstellt den eigentlichen globalen internen Load Balancer und definiert die Regeln für das Weiterleiten eingehender KI-Prompts an Ihre Modelle.
Systemdiagnose- und Backend-Richtlinien: Damit werden Anfragen nur an fehlerfreie Pods gesendet und eine intelligente, auf Messwerten basierende Traffic-Verteilung ermöglicht, um überlastete TPUs zu vermeiden.
Validierung: Das Skript wird angehalten, damit Google Cloud die internen IP-Adressen vollständig bereitstellen kann, bevor Sie fortfahren.
9. Failover-Test
Nun kommt der beste Teil des Labs: die Hochverfügbarkeit Ihrer Architektur testen.
Das passiert genau bei diesem automatisierten Test:
- Basistest:Unser simulierter Nutzer sendet einen Inferenz-Prompt („Wie heißt die Hauptstadt von Frankreich?“). Da sich der Nutzer in der primären Region befindet, leitet das Gateway die Anfrage an die lokalen TPUs weiter, um die Latenz so gering wie möglich zu halten.
- Das Desaster:Wir simulieren einen katastrophalen Ausfall des Rechenzentrums, indem wir alle TPU-Pods in der primären Region (
replicas=0) deaktivieren. - Die Erkennung:Wir warten 45 Sekunden. Während dieses Zeitfensters schlägt die Systemdiagnose des Gateways fehl. Das Gateway erkennt, dass das primäre Backend vollständig offline ist, und aktualisiert seine globalen Routingtabellen dynamisch.
- Failover:Der Nutzer sendet einen zweiten Prompt („What is the capital of Germany?“). Der Nutzer weiß nicht, dass es einen Ausfall gibt. Das Gateway fängt die Anfrage ab und leitet sie sofort weltweit an Ihre fehlerfreien sekundären TPUs weiter.
- Die Wiederherstellung:Wir stellen die primären TPUs wieder her, sodass Ihre globale Architektur wieder voll funktionsfähig ist.
- Öffnen Sie Cloud Shell und führen Sie Folgendes aus:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- Nach Abschluss des Tests können Sie die Umgebung wieder aufräumen.
10. Bereinigen
- Arbeitslast bereinigen
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Infrastruktur bereinigen Sie müssen sich im Ordner
gke-tfbefinden.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Wenn beim Löschen der jeweiligen Ressourcen Probleme auftreten, sollten Sie das terraform destroy-Befehlsskript ./cleanup-tf.sh noch einmal ausführen.
11. Glückwunsch
Glückwunsch! Sie haben ein hochverfügbares, regionsübergreifendes GKE Inference Gateway mit mehreren Clustern bereitgestellt, das auf GKE, verwalteten DRANET- und TPU v6e-Beschleunigern basiert.
Durch die Kombination von Cloud Storage FUSE für das sofortige Laden von Modellen und der Inference Gateway API für latenzbewusstes Multi-Cluster-Routing haben Sie ein robustes Backend entwickelt, das einen vollständigen Ausfall eines regionalen Rechenzentrums überstehen kann, ohne dass der Traffic interner Nutzer unterbrochen wird.
Weitere Informationen
Weitere Informationen zum GKE-Netzwerk
Nächstes Lab absolvieren
Setzen Sie Ihre Aufgabenreihe mit Google Cloud fort und sehen Sie sich diese anderen Google Cloud-Labs an: