
۱. مرور کلی
این آزمایشگاه شما را با زیرساخت هوش مصنوعی که میتواند برای اجرای بارهای کاری هوش مصنوعی استفاده شود، آشنا میکند. شما با موارد زیر کار خواهید کرد:
موتور گوگل کوبرنتیز (GKE) - پلتفرم اساسی هماهنگسازی کانتینر.
GKE DRANET را مدیریت کرد - شبکه تخصیص منابع پویا که مستقیماً فابریکهای اتصال پرسرعت را به غلافهای TPU شما اختصاص میدهد.
GKE Inference Gateway - این یک شیء Gateway مدیریتشده از Google Cloud است که برای Inference اقتباس شده است. در این مورد ما از قابلیتهای چندخوشهای استفاده خواهیم کرد.
واحد پردازش تنسور (TPU) - تراشههای شتابدهنده سفارشی گوگل.
Cloud Storage FUSE - یک رابط ذخیرهسازی که به پادها اجازه میدهد تا سطلهای Cloud Storage را مستقیماً نصب کنند و امکان بارگذاری فوری وزنهای عظیم مدل را فراهم کنند.
برای پیکربندی، شما یک VPC سفارشی، یک باکت ذخیرهسازی ابری و دو کلاستر در مناطق مختلف مستقر خواهید کرد. هر کلاستر یک گره TPU خواهد داشت که از DRANET مدیریتشده برای شبکهسازی خود استفاده میکند. پس از افزودن کلاسترها به یک Fleet ، وزنهای مدل Gemma را در باکت خود ذخیره (cache) میکنید و یک بار کاری vLLM مستقر میکنید که آن وزنها را فوراً از طریق Cloud Storage FUSE نصب میکند. در نهایت، GKE Inference Gateway برای مسیریابی ترافیک پیکربندی میشود و به شما امکان میدهد یک تست failover بین منطقهای را به صورت زنده انجام دهید.
این پیکربندیها از ترکیبی از Terraform ، gcloud و kubectl استفاده خواهند کرد.
در این آزمایشگاه یاد خواهید گرفت که چگونه وظایف زیر را انجام دهید:
- راهاندازی VPC، شبکهها، ذخیرهسازی
- تنظیم کلاستر GKE در حالت استاندارد
- ایجاد گره TPU و استفاده از DRANET مدیریتشده
- اضافه کردن کلاستر به ناوگان
- وزنهای مدل کش
- راهاندازی دروازه استنتاج GKE چندخوشهای و تست failover
در این آزمایش، شما قرار است الگوی زیر را ایجاد کنید.
شکل ۱.
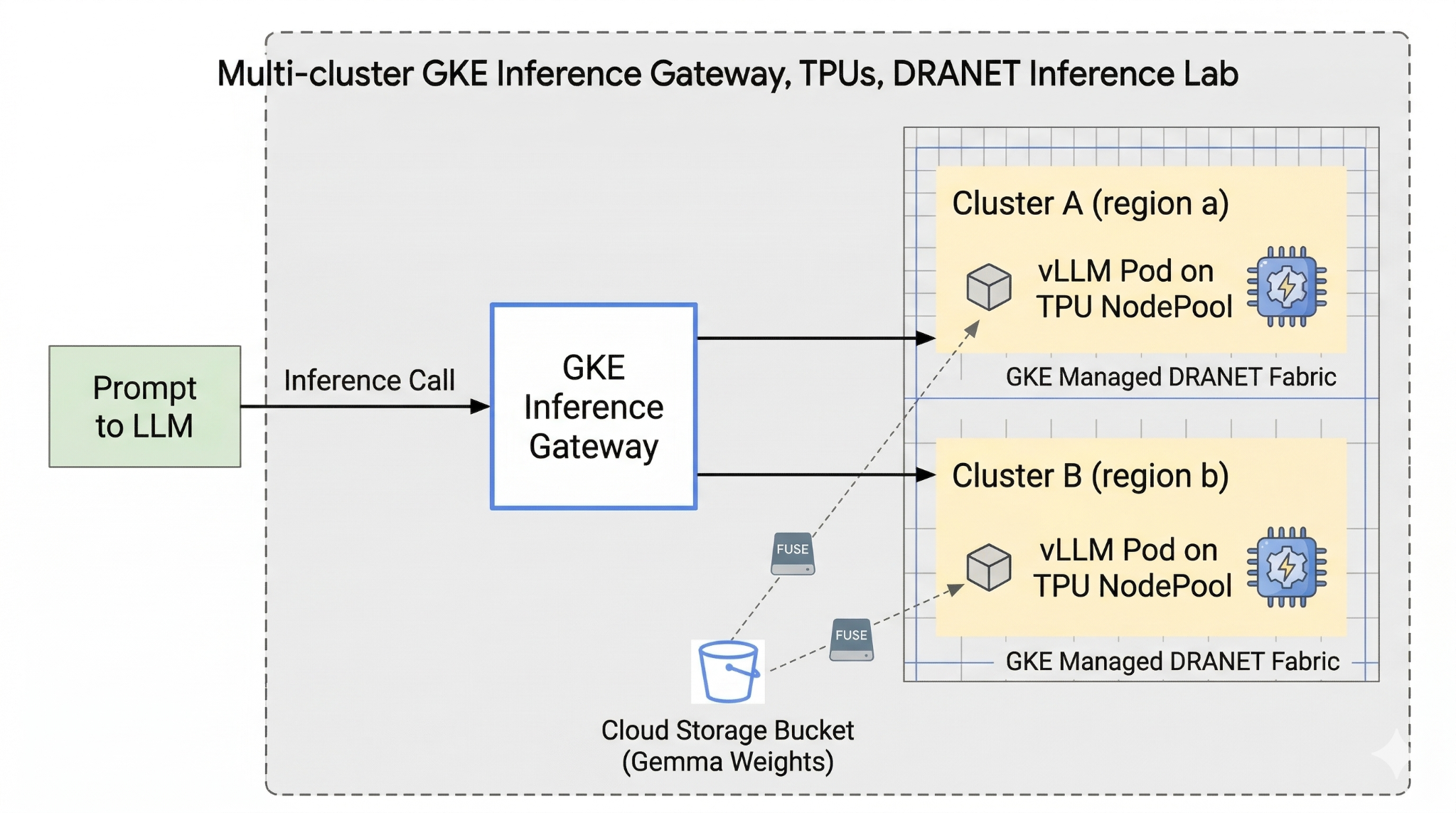
۲. راهاندازی سرویسهای ابری گوگل
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

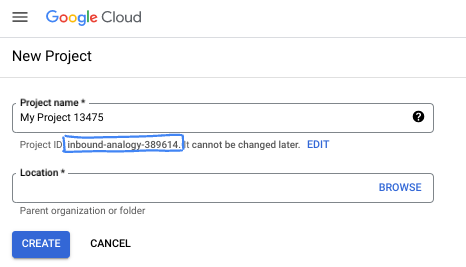
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. راهاندازی محیط با Terraform
برای انجام این آزمایش، به TPU نیاز دارید. نسخه دقیق مورد استفاده TPU نسخه ۶e است.
- برای دسترسی باید طبق دستورالعمل طرح TPU عمل کنید و سهمیه TPU را فعال کنید .
- ما از یک سیستم کوچک استفاده میکنیم که به ۴ تراشه TPU v6e (
ct6e-standard-4t)نیاز دارد که به صورت یک برش ۲x۲ در دو ناحیه مختلف خواهد بود. - توکن چهره در آغوش گرفته: برای دانلود وزنهای مدل Gemma به یک توکن دسترسی نیاز است.
ما یک VPC سفارشی با قوانین فایروال، فضای ذخیرهسازی و زیرشبکه ایجاد خواهیم کرد. کنسول ابری را باز کنید و پروژهای را که استفاده خواهید کرد انتخاب کنید.
- Cloud Shell را که در بالای کنسول شما در سمت راست قرار دارد باز کنید، مطمئن شوید که شناسه پروژه صحیح را در Cloud Shell مشاهده میکنید، هرگونه درخواستی را برای اجازه دسترسی تأیید کنید.

- یک پوشه به نام
gke-tfایجاد کنید و به پوشه مورد نظر بروید.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- حالا چند فایل پیکربندی اضافه کنید. این فایلها فایلهای network.tf ، variable.tf ، providers.tf و fuse.tf زیر را ایجاد میکنند.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
فایلهای variable.tf نام پروژه، مناطق و اطلاعات منطقه را اضافه میکنند. ps متغیر "regions" که default = ["europe-west4", "us-east5"] را با مناطقی که سهمیه TPU در آنها دارید، بهروزرسانی کنید. برای اطلاعات بیشتر، این سند " اعتبارسنجی در دسترس بودن TPU در GKE " را بررسی کنید.
فایل network.tf یک VPC جدید به پروژه شما اضافه میکند که شامل زیرشبکههایی در دو منطقه مختلف، زیرشبکههای فقط پروکسی و قوانین فایروال است.
فایل provider.tf ارائهدهندهی مربوطه را برای پشتیبانی از Terraform اضافه میکند.
فایل fuse.tf فضای ذخیرهسازی ابری را برای ذخیره وزنهای مدل شما اضافه میکند و یک حساب کاربری سرویس IAM با مجوزهای objectAdmin فراهم میکند. این حساب کاربری به GKE Workload Identity متصل میشود.
- مطمئن شوید که در دایرکتوری gke-tf هستید و دستورات زیر را اجرا کنید
terraform init -دایرکتوری کاری را مقداردهی اولیه میکند. این مرحله ارائهدهندگان مورد نیاز برای پیکربندی داده شده را دانلود میکند.terraform plan -یک طرح اجرایی ایجاد میکند که نشان میدهد Terraform چه اقداماتی را برای استقرار زیرساخت شما انجام خواهد داد.terraform apply –auto-approveبهروزرسانیها را اجرا کرده و بهطور خودکار تأیید میکند.
terraform init
terraform plan
- حالا عملیات نصب را اجرا کنید (این کار ممکن است بین ۳ تا ۵ دقیقه طول بکشد)
terraform apply -auto-approve
- در همان پوشه
gke-tfفایل gke.tf زیر را ایجاد کنید.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
gke.tf دو خوشه را در مناطق مختلف اضافه میکند و دو گره TPU ایجاد میکند که TPU v6e را با ۴ تراشه اجرا میکنند و DRANET مدیریتشده را به گرههای گره اختصاص میدهد.
- حالا عملیات نصب را اجرا کنید (این کار ممکن است بین ۱۰ تا ۱۵ دقیقه طول بکشد)
terraform apply -auto-approve
- تأیید
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
۴. ثبت ناوگان
ما باید خوشه را در یک ناوگان ثبت کنیم.
- مطمئن شوید که در دایرکتوری
gke-tfهستید و دستورات زیر را اجرا کنید.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
فایل fleet.tf هر دو خوشه را در یک ناوگان جهانی GKE ثبت میکند و امکان کشف و ورود سرویس چندخوشهای را فراهم میکند. این فایل، خوشه ایالات متحده را به عنوان خوشه پیکربندی مرکزی تعیین میکند و به Gateway API اجازه میدهد تا ترافیک را نظارت و مسیریابی کند.
- در پوشه
gke-tfقرار دهید و اجرا کنید (این کار باید ۳-۵ دقیقه طول بکشد)
terraform plan
terraform apply -auto-approve
- ثبت نام ناوگان را تأیید کنید
gcloud container fleet memberships list --project=$PROJECT_ID
۵. وزنهای مدل را در FUSE ذخیره کنید
ما یک Kubernetes Job موقت در کلاستر ایالات متحده اجرا خواهیم کرد تا مدل Gemma را به طور ایمن از طریق یک اسکریپت پایتون مستقیماً در مخزن ذخیرهسازی ابری نصب شده روی FUSE دانلود کنیم.
- متغیرهای زیر را ایجاد کنید
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- این از مدل google/gemma-3-27b-it استفاده میکند، بنابراین باید یک توکن HF ایجاد کنید .
YOUR_ACTUAL_HUGGING_FACE_TOKENرا در زیر با توکن واقعی خود جایگزین کنید.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- مطمئن شوید که در دایرکتوری
gke-tfهستید و دستورات زیر را اجرا کنید.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- قبل از ادامه، منتظر بمانید تا دانلود تمام شود (این کار بسته به اندازه مدل، ۵ تا ۱۰ دقیقه طول میکشد)
kubectl logs -f job/model-downloader --context=$CTX_US
(برای خروج از گزارشها، پس از نمایش پیام «دانلود کامل شد!» Ctrl+C را فشار دهید.)
۶. استقرار حجم کاری vLLM و Gemma
- مطمئن شوید که در دایرکتوری
gke-tfهستید و دستورات زیر را اجرا کنید.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- حالا اسکریپت زیر را اجرا کنید (این کار بین ۵ تا ۱۰ دقیقه طول میکشد زیرا در دو منطقه مستقر میشود)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- تأیید استقرار
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- پس از تکمیل، میتوانید با اجرای دستور زیر، تأیید کنید که شبکه مدیریتشده DRANET به پادها اختصاص داده شده است.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
رابطهای شبکه اضافی eth0 را برای شبکهبندی استاندارد پاد، در کنار رابطهای ثانویه که نشاندهنده ساختار TPU اختصاصی شما eth1، eth2 و غیره هستند، مشاهده خواهید کرد.
۷. API استنتاج و پیکربندی دروازه
اکنون InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) و Inference Pool(gemma-pool) را ایجاد خواهید کرد. Inference Pool با استفاده از نمودار Helm ایجاد میشود. این نمودار نصب و اعتبارسنجی میشود.
- مطمئن شوید که در دایرکتوری
gke-tfهستید و دستورات زیر را اجرا کنید. این کار شیء را مستقر کرده و اعتبارسنجی را اجرا میکند.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
۸. پیکربندی دروازه
اکنون پیکربندی Cross-Regional Gateway را ایجاد خواهید کرد. Gateway(cross-region-gateway), HTTPRoute (gemma-route) , HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. مجموعه استنتاج با استفاده از نمودار Helm ایجاد میشود. این مجموعه نصب و اعتبارسنجی میشود. (فعال شدن Gateway 8 تا 10 دقیقه طول میکشد)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
استخر استنتاج (Helm) : سرورهای مدل شما را از هر دو منطقه در یک backend منطقی واحد گروهبندی میکند.
Gateway & HTTPRoute : متعادلکننده بار داخلی سراسری واقعی را ایجاد میکند و قوانینی را برای مسیریابی درخواستهای هوش مصنوعی ورودی به مدلهای شما تعریف میکند.
سیاستهای بررسی سلامت و بکاند : تضمین میکند که درخواستها فقط به پادهای سالم ارسال میشوند و توزیع هوشمند و مبتنی بر معیار ترافیک را امکانپذیر میسازد (از بارگذاری بیش از حد TPUها جلوگیری میکند).
اعتبارسنجی : اسکریپت متوقف میشود تا مطمئن شود که Google Cloud آدرسهای IP داخلی را قبل از ادامه کار به طور کامل تأمین کرده است.
۹. تست غلبه بر خرابی
حالا به بهترین بخش آزمایشگاه میرسیم: آزمایش میزان دسترسیپذیری بالای معماری شما.
دقیقاً کاری که این تست خودکار انجام خواهد داد به شرح زیر است:
- آزمون پایه: کاربر شبیهسازیشده ما یک درخواست استنتاج ("پایتخت فرانسه کجاست؟") ارسال میکند. از آنجا که کاربر در منطقه اصلی قرار دارد، Gateway درخواست را برای کمترین تأخیر ممکن به آن TPUهای محلی هدایت میکند.
- فاجعه: ما با از کار انداختن تمام پادهای TPU در ناحیه اصلی (
replicas=0) یک قطعی فاجعهبار در مرکز داده را شبیهسازی میکنیم. - تشخیص: ما ۴۵ ثانیه صبر میکنیم. در طول این پنجره، بررسیهای سلامت Gateway با شکست مواجه میشود، متوجه میشود که backend اصلی کاملاً آفلاین است و جداول مسیریابی سراسری خود را به صورت پویا بهروزرسانی میکند.
- Failover: کاربر ما درخواست دوم را ارسال میکند ("پایتخت آلمان کجاست؟"). کاربر اصلاً نمیداند که قطعی وجود دارد. Gateway درخواست را رهگیری میکند و فوراً آن را در سراسر جهان به TPU های ثانویه سالم شما هدایت میکند.
- بازیابی: ما TPU های اولیه را بازیابی میکنیم و معماری سراسری شما را به سلامت کامل بازمیگردانیم.
- Cloud Shell را باز کنید و دستور زیر را اجرا کنید:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- پس از اتمام آزمایش، میتوانید آن را تمیز کنید.
۱۰. تمیز کردن
- حجم کار را تمیز کنید
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- زیرساخت را پاکسازی کنید. مطمئن شوید که در پوشه
gke-tfهستید.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
اگر در حذف منابع خاص با مشکلی مواجه شدید، باید اسکریپت دستور terraform destroy ./cleanup-tf.sh را دوباره اجرا کنید.
۱۱. تبریک
تبریک! شما با موفقیت یک GKE Inference Gateway چندخوشهای با قابلیت دسترسی بالا و معماری استنتاج هوش مصنوعی بین منطقهای را با استفاده از GKE، شتابدهندههای DRANET مدیریتشده و TPU v6e مستقر کردهاید.
با ترکیب Cloud Storage FUSE برای بارگذاری فوری مدل و Inference Gateway API برای مسیریابی چندخوشهای و آگاه از تأخیر، شما یک backend انعطافپذیر ساختهاید که قادر است از قطع کامل مرکز داده منطقهای بدون افت ترافیک کاربر داخلی جان سالم به در ببرد.
مراحل بعدی / اطلاعات بیشتر
میتوانید درباره شبکهسازی GKE بیشتر بخوانید
آزمایشگاه بعدی خود را انجام دهید
به جستجوی خود با Google Cloud ادامه دهید و این آزمایشگاههای دیگر Google Cloud را بررسی کنید: