
1. סקירה כללית
בשיעור ה-Lab הזה נסביר על תשתית AI שאפשר להשתמש בה להרצת עומסי עבודה של AI. תצטרכו לעבוד עם הרכיבים הבאים:
Google Kubernetes Engine (GKE) – פלטפורמת בסיס לתזמור קונטיינרים.
GKE managed DRANET – רשת דינמית להקצאת משאבים שמקצה ישירות רשתות מהירות של קישוריות הדדית ל-TPU Pods.
GKE Inference Gateway – זהו אובייקט שער מנוהל מ-Google Cloud, שמותאם להסקת מסקנות. במקרה הזה נשתמש ביכולות של כמה אשכולות.
Tensor Processing Unit (TPU) – שבבי האצה בהתאמה אישית של Google.
Cloud Storage FUSE – ממשק אחסון שמאפשר ל-Podים לטעון קטגוריות של Cloud Storage ישירות, וכך לטעון משקלים של מודלים גדולים באופן מיידי.
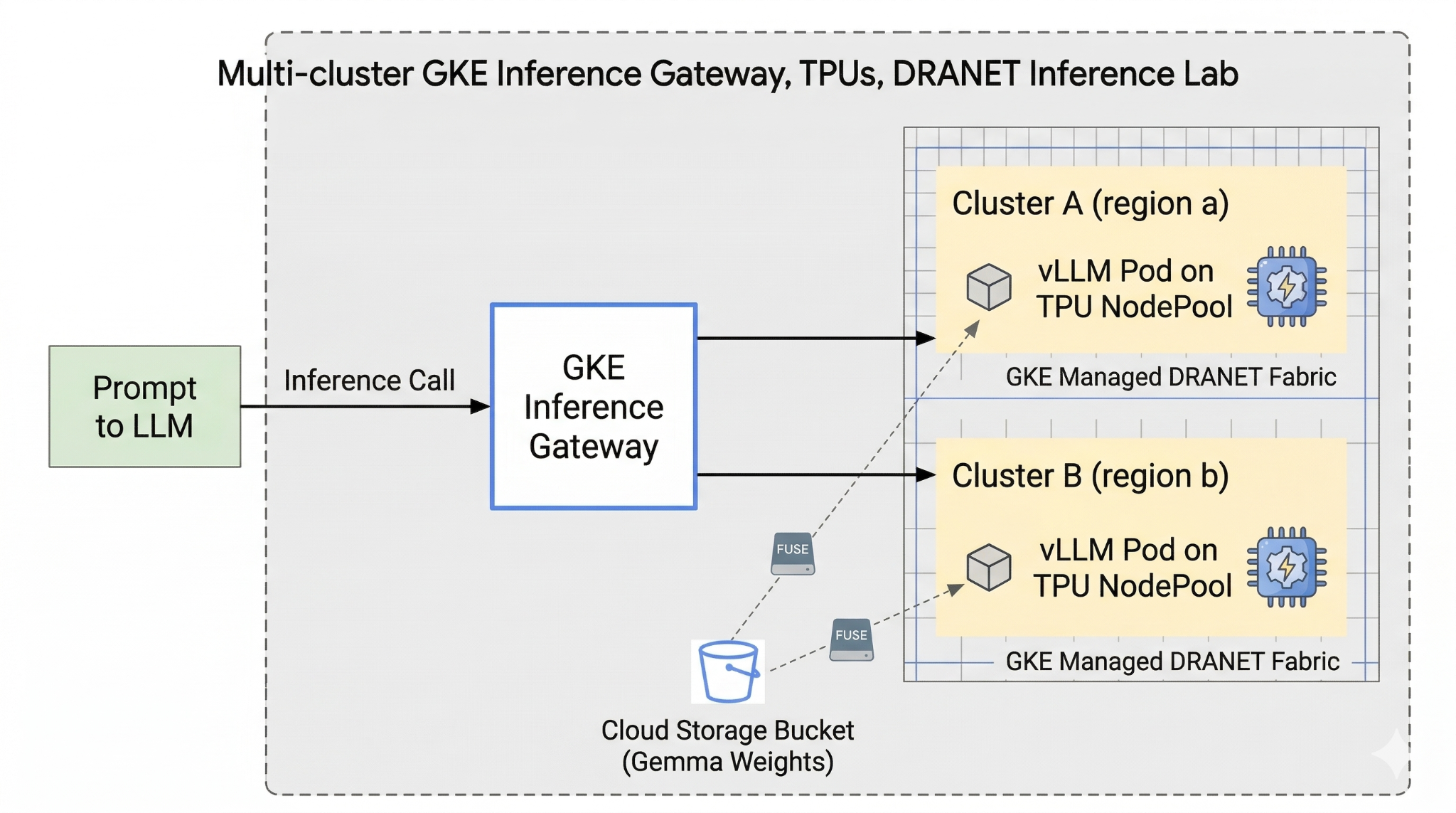
כדי להגדיר את המערכת, תפרסו VPC מותאם אישית, קטגוריה של Cloud Storage ושני אשכולות באזורים שונים. לכל אשכול יהיה מאגר צמתים של TPU שמשתמש ב-DRANET מנוהל לניהול הרשת. אחרי שמוסיפים את האשכולות ל-Fleet, המערכת שומרת במטמון את משקלי המודל של Gemma בקטגוריה ופורסת עומס עבודה של vLLM שמטעין את המשקלים האלה באופן מיידי באמצעות Cloud Storage FUSE. לבסוף, שער ההיקש של GKE יוגדר לניתוב תעבורת נתונים, ויאפשר לכם לבצע בדיקת יתירות כשל פעילה בין אזורים.
ההגדרות ישתמשו בשילוב של Terraform, gcloud ו-kubectl.
בשיעור ה-Lab הזה תלמדו איך לבצע את המשימה הבאה:
- הגדרה של VPC, רשתות ואחסון
- הגדרת אשכול GKE במצב רגיל
- יצירה של מאגר צמתים של TPU ושימוש ב-DRANET מנוהל
- הוספת אשכול ל-Fleet
- שמירת משקלים של מודלים במטמון
- הגדרה של שער GKE Inference מרובה-אשכולות ובדיקה של מעבר אוטומטי לגיבוי
בשיעור ה-Lab הזה תיצרו את התבנית הבאה.
איור 1.
2. הגדרה של שירותי Google Cloud
הגדרת סביבה בקצב אישי
- נכנסים ל-מסוף Google Cloud ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.

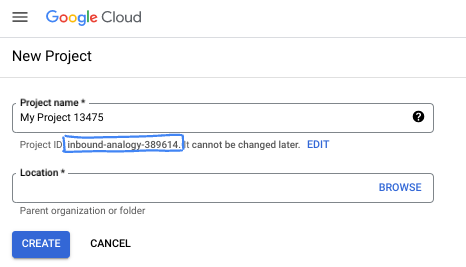
- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. זו מחרוזת תווים שלא נמצאת בשימוש ב-Google APIs. תמיד אפשר לעדכן את המיקום.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud, והוא קבוע (אי אפשר לשנות אותו אחרי שהוא מוגדר). מסוף Cloud יוצר באופן אוטומטי מחרוזת ייחודית, ובדרך כלל לא צריך לדעת מה היא. ברוב ה-Codelabs, תצטרכו להפנות למזהה הפרויקט (בדרך כלל מסומן כ-
PROJECT_ID). אם אתם לא אוהבים את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר. אפשר גם לנסות כתובת משלכם ולבדוק אם היא זמינה. אי אפשר לשנות את הערך הזה אחרי השלב הזה, והוא יישאר כזה למשך הפרויקט. - לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. במאמרי העזרה מפורט מידע נוסף על שלושת הערכים האלה.
- בשלב הבא, תצטרכו להפעיל את החיוב במסוף Cloud כדי להשתמש במשאבי Cloud או בממשקי API של Cloud. השלמת ה-codelab הזה לא תעלה לכם הרבה, אם בכלל. כדי להשבית את המשאבים ולמנוע חיובים נוספים אחרי שתסיימו את המדריך הזה, תוכלו למחוק את המשאבים שיצרתם או למחוק את הפרויקט. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. הגדרת סביבה באמצעות Terraform
כדי לבצע את ה-Lab הזה, אתם צריכים גישה ל-TPU. הגרסה המדויקת שבה נעשה שימוש היא TPU v6e.
- כדי לקבל גישה, צריך לפעול לפי מסמך התוכנית של TPU ולהפעיל את מכסת TPU.
- אנחנו משתמשים בפריסה קטנה שדורשת 4 שבבי TPU v6e (
ct6e-standard-4t)שהם 2x2 slice) בשני אזורים שונים. - טוקן Hugging Face: נדרש טוקן גישה כדי להוריד את משקלי המודל של Gemma
ניצור VPC בהתאמה אישית עם כללי חומת אש, אחסון ותת-רשת. פותחים את מסוף Cloud ובוחרים את הפרויקט שבו רוצים להשתמש.
- פותחים את Cloud Shell בפינה השמאלית העליונה של המסוף, מוודאים שמופיע מזהה הפרויקט הנכון ב-Cloud Shell ומאשרים את כל ההנחיות למתן גישה.

- צור תיקייה בשם
gke-tfועבור לתיקייה
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- עכשיו מוסיפים קובצי הגדרה. הפקודות האלה ייצרו את הקבצים הבאים: network.tf , variable.tf, providers.tf, fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
קובצי variable.tf מוסיפים את שם הפרויקט, האזורים ופרטי האזור. הערה: צריך לעדכן את המשתנה regions, default = ["europe-west4", "us-east5"] עם האזורים שבהם יש לכם מכסת TPU. מידע נוסף זמין במסמך אימות הזמינות של TPU ב-GKE.
התבנית network.tf מוסיפה רשת VPC חדשה בפרויקט עם רשתות משנה בשני אזורים שונים, רשתות משנה של שרת proxy בלבד וכללי חומת אש.
הקובץ provider.tf מוסיף את הפלאגין שמתממשק עם שירותים חיצוניים הרלוונטי כדי לתמוך ב-Terraform
fuse.tf מוסיף את קטגוריית Cloud Storage למטמון של משקלי המודל ומקצה חשבון שירות של IAM עם הרשאות objectAdmin. הוא מקשר את החשבון הזה ל-Workload Identity ב-GKE
- מוודאים שאתם נמצאים בספרייה gke-tf ומריצים את הפקודות הבאות
terraform init -מאתחלת את ספריית העבודה. בשלב הזה מתבצעת הורדה של הספקים שנדרשים להגדרה הנתונה.terraform plan -יוצרת תוכנית ביצוע שמראה אילו פעולות Terraform תבצע כדי לפרוס את התשתית. terraform apply –auto-approveמריץ את העדכונים ומאשר אותם באופן אוטומטי.
terraform init
terraform plan
- עכשיו מריצים את הפריסה (התהליך עשוי להימשך בין 3 ל-5 דקות)
terraform apply -auto-approve
- באותה תיקייה
gke-tf, יוצרים את הקובץ הבא gke.tf.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
הפקודה gke.tf מוסיפה שני אשכולות באזורים שונים, יוצרת שני מאגרי צמתים של TPU שמריצים את TPU v6e עם 4 שבבים, ומקצה את DRANET המנוהל למאגרי הצמתים.
- מריצים את הפריסה (הפעולה הזו עשויה להימשך בין 10 ל-15 דקות)
terraform apply -auto-approve
- אימות
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. רישום ה-Fleet
צריך לרשום את האשכול ב-Fleet.
- מוודאים שאתם נמצאים בספרייה
gke-tfומריצים את הפקודות הבאות.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
הקובץ fleet.tf רושם את שני האשכולות ב-GKE Fleet גלובלי ומאפשר גילוי שירותים ו-Ingress מרובי אשכולות. הוא מגדיר את אשכול ארה"ב כאשכול ההגדרות המרכזי, וכך מאפשר ל-Gateway API לעקוב אחרי תעבורת הנתונים ולנתב אותה.
- בתיקייה
gke-tfומריצים את (התהליך הזה אמור להימשך 3-5 דקות)
terraform plan
terraform apply -auto-approve
- אימות הרישום של Fleet
gcloud container fleet memberships list --project=$PROJECT_ID
5. שמירת משקלי המודל במטמון ב-FUSE
אנחנו נריץ משימת Kubernetes זמנית באשכול בארה"ב כדי להוריד בצורה מאובטחת את מודל Gemma באמצעות סקריפט Python ישירות לקטגוריה של Cloud Storage שמוגדרת ב-FUSE.
- יוצרים את המשתנים הבאים
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- הפעולה הזו משתמשת ב-google/gemma-3-27b-it model, ולכן צריך ליצור טוקן HF. מחליפים את
YOUR_ACTUAL_HUGGING_FACE_TOKENשבהמשך באסימון בפועל.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- מוודאים שאתם נמצאים בספרייה
gke-tfומריצים את הפקודות הבאות.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- מחכים שההורדה תסתיים לפני שממשיכים (ההורדה אמורה להימשך 5-10 דקות, בהתאם לגודל המודל)
kubectl logs -f job/model-downloader --context=$CTX_US
(מקישים על Ctrl+C כדי לצאת מהיומנים אחרי שמופיעה ההודעה 'ההורדה הושלמה')
6. פריסת עומס עבודה של vLLM ו-Gemma
- מוודאים שאתם נמצאים בספרייה
gke-tfומריצים את הפקודות הבאות.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- עכשיו מריצים את הסקריפט הבא (הפעולה תימשך 5-10 דקות כי הפריסה מתבצעת בשני אזורים)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- אישור הפריסה
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- אחרי שתסיימו, תוכלו לוודא שהקצאת הרשת המנוהלת של DRANET בוצעה ל-pods על ידי הפעלת הפקודה.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
יוצגו לכם ממשקי רשת נוספים eth0 עבור רשתות פוד רגילות, לצד ממשקים משניים שמייצגים את רשת ה-TPU הייעודית eth1, eth2 וכו'.
7. הגדרת Inference API ו-Gateway
עכשיו יוצרים את InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) ואת Inference Pool(gemma-pool). מאגר ההסקה נוצר באמצעות תרשים Helm. המערכת מתקינה ומאמתת את היצירה.
- מוודאים שאתם נמצאים בספרייה
gke-tfומריצים את הפקודות הבאות. האובייקט ייפרס ויתבצע אימות.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. הגדרת שער
עכשיו יוצרים את ההגדרה של השער בין האזורים. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. מאגר ההיסקים נוצר באמצעות תרשים Helm. המערכת מתקינה ומאמתת את היצירה. (יידרשו 8-10 דקות עד שהשער יהפוך לפעיל)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
מאגר הסקת מסקנות (Helm): מקבץ את שרתי המודלים משני האזורים לבק-אנד לוגי יחיד.
Gateway & HTTPRoute: יצירת מאזן העומסים הפנימי הגלובלי בפועל והגדרת הכללים לניתוב הנחיות AI נכנסות למודלים שלכם.
בדיקת תקינות ומדיניות לגבי שרתים עורפיים: מוודאים שהבקשות יישלחו רק לפודים תקינים, ומאפשרים חלוקת תעבורה חכמה שמבוססת על מדדים (כדי למנוע עומס יתר על יחידות TPU).
אימות: הסקריפט מושהה כדי לוודא ש-Google Cloud הקצה באופן מלא את כתובות ה-IP הפנימיות לפני שממשיכים.
9. בדיקת מעבר לגיבוי (failover)
עכשיו מגיע החלק הכי טוב במעבדה: בדיקת הזמינות הגבוהה של הארכיטקטורה.
הנה בדיוק מה שהבדיקה האוטומטית הזו תעשה:
- בדיקת הבסיס: המשתמש המדומה שלנו שולח הנחיה להסקת מסקנות ("מהי בירת צרפת?"). מכיוון שהמשתמש נמצא באזור הראשי, שער הכניסה מנתב את הבקשה אל יחידות ה-TPU המקומיות האלה כדי להשיג את זמן האחזור הנמוך ביותר שאפשר.
- האסון: אנחנו מדמים הפסקת שירות קטסטרופלית במרכז נתונים על ידי השבתה של כל ה-TPU Pod באזור הראשי (
replicas=0). - הזיהוי: אנחנו מחכים 45 שניות. במהלך חלון הזמן הזה, בדיקות תקינות של שער נכשלות, השער מבין שהקצה העורפי הראשי נמצא במצב אופליין לגמרי, והוא מעדכן באופן דינמי את טבלאות הניתוב הגלובליות שלו.
- המעבר לגיבוי: המשתמש שולח הנחיה שנייה ("מהי בירת גרמניה?"). המשתמש לא יודע שיש הפסקה זמנית בשירות. השער מיירט את הבקשה ומנתב אותה מחדש באופן מיידי ברחבי העולם אל יחידות ה-TPU המשניות התקינות שלכם.
- השחזור: אנחנו משחזרים את יחידות ה-TPU הראשיות, ומחזירים את הארכיטקטורה הגלובלית שלכם למצב תקין.
- פותחים את Cloud Shell ומריצים את הפקודה הבאה:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- אחרי שהבדיקה מסתיימת, אפשר לנקות את המערכת.
10. הסרת המשאבים
- ניקוי עומס העבודה
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- מפנים את התשתית. חשוב לוודא שנמצאים בתיקייה
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
אם נתקלתם בבעיות במחיקת משאבים ספציפיים, אתם צריכים להריץ מחדש את סקריפט הפקודה terraform destroy ./cleanup-tf.sh
11. מזל טוב
מעולה! פרסתם בהצלחה שער GKE Inference Gateway עם זמינות גבוהה וריבוי אשכולות, ארכיטקטורת מסקנות AI חוצה אזורים באמצעות GKE, מאיצי DRANET מנוהלים ומאיצי TPU v6e.
השילוב של Cloud Storage FUSE לטעינה מיידית של מודלים ושל Inference Gateway API לניתוב מודע-חביון בין כמה אשכולות, מאפשר לכם ליצור קצה עורפי עמיד שיכול לשרוד הפסקה זמנית בשירות מלאה במרכז נתונים אזורי בלי להפסיק את תעבורת הנתונים של משתמשים פנימיים.
השלבים הבאים / מידע נוסף
אל שיעור ה-Lab הבא
אתם יכולים להמשיך את יחידת ה-Quest ב-Google Cloud או לנסות את שיעורי ה-Lab הבאים של Google Cloud: