
1. खास जानकारी
इस लैब में, आपको एआई इन्फ़्रास्ट्रक्चर के बारे में बताया गया है. इसका इस्तेमाल, एआई वर्कलोड को चलाने के लिए किया जा सकता है. आपको इन चीज़ों के साथ काम करना होगा:
Google Kubernetes Engine (GKE) - यह कंटेनर ऑर्केस्ट्रेशन का बुनियादी प्लैटफ़ॉर्म है.
GKE मैनेज किया गया DRANET - यह डाइनैमिक रिसोर्स ऐलोकेशन नेटवर्किंग है. यह आपके टीपीयू पॉड को सीधे तौर पर हाई-स्पीड इंटरकनेक्ट फ़ैब्रिक असाइन करता है.
GKE Inference Gateway - यह Google Cloud का मैनेज किया गया गेटवे ऑब्जेक्ट है, जिसे अनुमान लगाने के लिए बनाया गया है. इस मामले में, हम मल्टी-क्लस्टर की सुविधाओं का इस्तेमाल करेंगे.
टेंसर प्रोसेसिंग यूनिट (टीपीयू) - Google के कस्टम-बिल्ट एक्सेलरेटर चिप.
Cloud Storage FUSE - यह एक स्टोरेज इंटरफ़ेस है. इसकी मदद से पॉड, Cloud Storage बकेट को सीधे तौर पर माउंट कर सकते हैं. इससे मॉडल के बड़े साइज़ वाले डेटा को तुरंत लोड किया जा सकता है.
आपको एक कस्टम वीपीसी, एक Cloud Storage बकेट, और अलग-अलग क्षेत्रों में दो क्लस्टर डिप्लॉय करने हैं. हर क्लस्टर में एक टीपीयू नोडपूल होगा. यह नोडपूल, नेटवर्किंग के लिए मैनेज किए गए DRANET का इस्तेमाल करेगा. फ़्लीट में क्लस्टर जोड़ने के बाद, Gemma मॉडल के वज़न को अपनी बकेट में कैश किया जाएगा. इसके बाद, vLLM वर्कलोड को डिप्लॉय किया जाएगा. यह वर्कलोड, Cloud Storage FUSE के ज़रिए उन वज़न को तुरंत माउंट करता है. आखिर में, GKE Inference Gateway को ट्रैफ़िक को रूट करने के लिए कॉन्फ़िगर किया जाएगा. इससे आपको लाइव क्रॉस-रीजनल फ़ेलओवर टेस्ट करने की अनुमति मिलेगी.
कॉन्फ़िगरेशन में Terraform, gcloud, और kubectl का इस्तेमाल किया जाएगा.
इस लैब में, आपको यह काम करने का तरीका बताया जाएगा:
- वीपीसी, नेटवर्क, और स्टोरेज सेट अप करना
- स्टैंडर्ड मोड में GKE क्लस्टर सेट अप करना
- टीपीयू नोडपूल बनाना और मैनेज किए जा रहे DRANET का इस्तेमाल करना
- फ़्लीट में क्लस्टर जोड़ना
- मॉडल के वेट को कैश मेमोरी में सेव करना
- कई क्लस्टर वाले GKE इन्फ़रेंस गेटवे को सेट अप करना और फ़ेल ओवर की जांच करना
इस लैब में, आपको यह पैटर्न बनाना है.
इमेज 1.
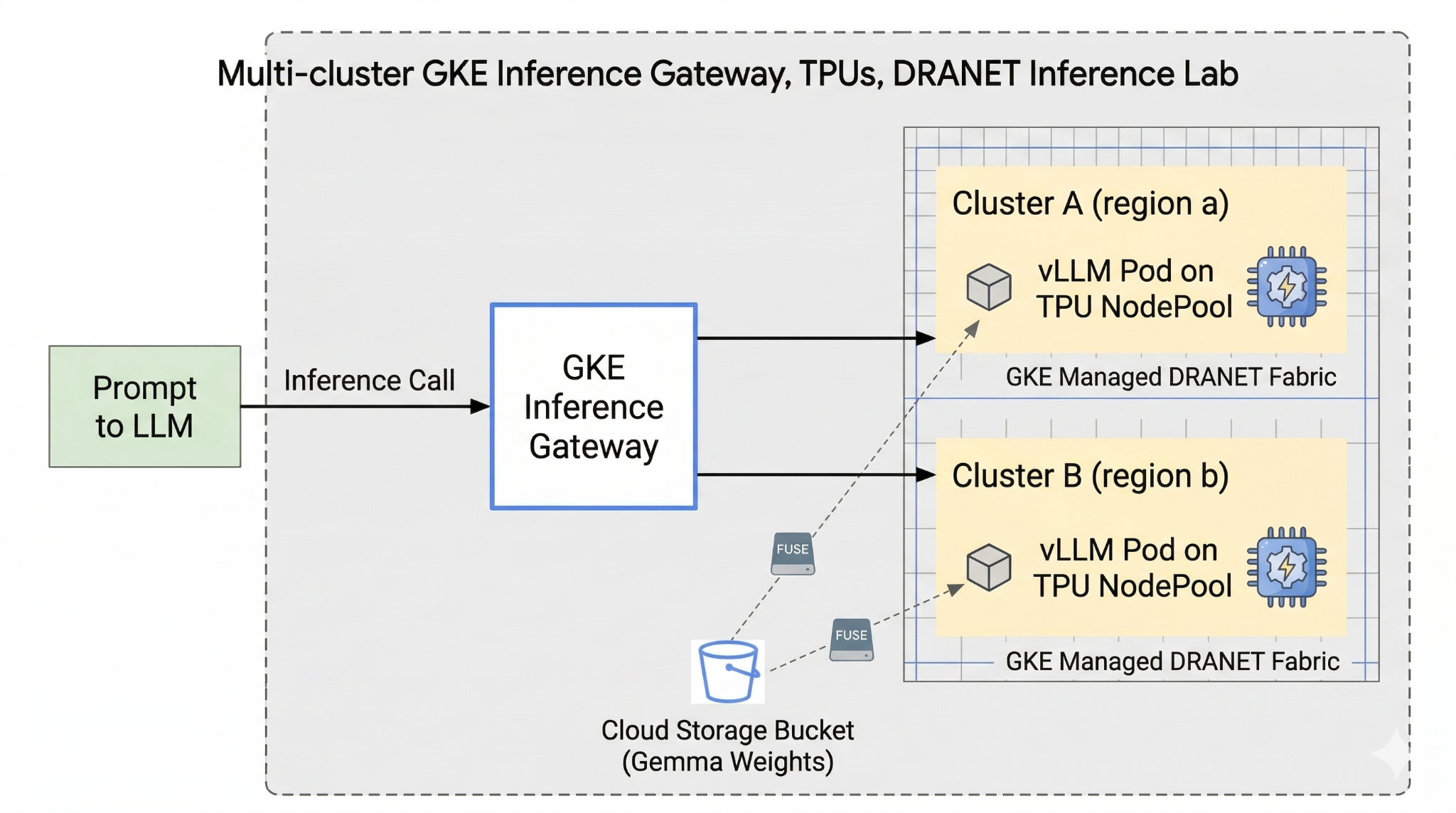
2. Google Cloud की सेवाओं का सेटअप
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

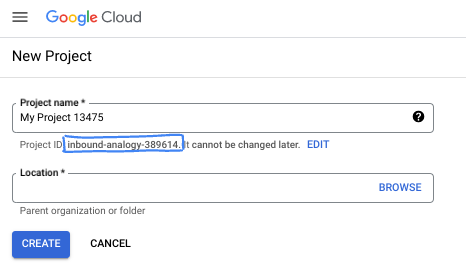
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. Terraform की मदद से एनवायरमेंट सेट अप करना
इस लैब को पूरा करने के लिए, आपके पास टीपीयू का ऐक्सेस होना चाहिए. इस्तेमाल किया गया वर्शन, टीपीयू v6e है.
- ऐक्सेस पाने के लिए, आपको टीपीयू प्लान के दस्तावेज़ में दिए गए निर्देशों का पालन करना होगा. साथ ही, टीपीयू कोटा चालू करना होगा.
- हम एक छोटा डिप्लॉयमेंट इस्तेमाल कर रहे हैं. इसके लिए, हमें चार टीपीयू v6e चिप की ज़रूरत है.
ct6e-standard-4t)ये दो अलग-अलग क्षेत्रों में 2x2 स्लाइस होंगे. - Hugging Face टोकन: Gemma मॉडल के वेट डाउनलोड करने के लिए, ऐक्सेस टोकन ज़रूरी है
हम फ़ायरवॉल के नियमों, स्टोरेज, और सबनेट के साथ एक कस्टम वीपीसी बनाएंगे. क्लाउड कंसोल खोलें और वह प्रोजेक्ट चुनें जिसका आपको इस्तेमाल करना है.
- अपनी कंसोल के सबसे ऊपर दाईं ओर मौजूद Cloud Shell खोलें. पक्का करें कि आपको Cloud Shell में सही प्रोजेक्ट आईडी दिख रहा हो. साथ ही, ऐक्सेस की अनुमति देने के लिए दिए गए किसी भी प्रॉम्प्ट की पुष्टि करें.

gke-tfनाम का फ़ोल्डर बनाओ और उसमें ले जाओ
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- अब कुछ कॉन्फ़िगरेशन फ़ाइलें जोड़ें. इनसे ये फ़ाइलें बनेंगी: network.tf , variable.tf, providers.tf, fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
variable.tf फ़ाइल में प्रोजेक्ट का नाम, क्षेत्र, और ज़ोन की जानकारी जोड़ी जाती है. ध्यान दें: "regions" वैरिएबल default = ["europe-west4", "us-east5"] को उन क्षेत्रों के हिसाब से अपडेट करें जहां आपके पास टीपीयू का कोटा है. ज़्यादा जानकारी के लिए, " GKE में टीपीयू की उपलब्धता की पुष्टि करना" दस्तावेज़ देखें.
network.tf आपके प्रोजेक्ट में एक नया वीपीसी जोड़ता है. इसमें दो अलग-अलग ज़ोन पर सबनेट, सिर्फ़ प्रॉक्सी सबनेट, और फ़ायरवॉल के नियम होते हैं.
provider.tf, Terraform के साथ काम करने के लिए ज़रूरी प्रोवाइडर जोड़ता है
fuse.tf, Cloud Storage बकेट में आपके मॉडल के वेट को कैश मेमोरी में सेव करता है. साथ ही, objectAdmin अनुमतियों के साथ IAM सेवा खाता उपलब्ध कराता है. यह कुकी, इस खाते को GKE Workload Identity से बाइंड करती है
- पक्का करें कि आप gke-tf डायरेक्ट्री में हों और यहां दी गई कमांड चलाएं
terraform init -इससे वर्किंग डायरेक्ट्री शुरू होती है. इस चरण में, दिए गए कॉन्फ़िगरेशन के लिए ज़रूरी प्रोवाइडर डाउनलोड किए जाते हैं.terraform plan -यह एक एक्ज़ीक्यूशन प्लान जनरेट करता है. इसमें दिखाया जाता है कि Terraform, आपके इन्फ़्रास्ट्रक्चर को डिप्लॉय करने के लिए कौनसी कार्रवाइयां करेगा.terraform apply –auto-approveअपडेट करता है और उन्हें अपने-आप स्वीकार कर लेता है.
terraform init
terraform plan
- अब डिप्लॉयमेंट शुरू करें (इसमें 3 से 5 मिनट लग सकते हैं)
terraform apply -auto-approve
- उसी
gke-tfफ़ोल्डर में, यह gke.tf फ़ाइल बनाएं.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
gke.tf अलग-अलग क्षेत्रों में दो क्लस्टर जोड़ता है. साथ ही, दो टीपीयू नोडपूल बनाता है, जो चार चिप वाले टीपीयू v6e को चलाते हैं. इसके अलावा, मैनेज किए गए DRANET को नोड पूल असाइन करता है.
- अब डिप्लॉयमेंट शुरू करें (इसमें 10 से 15 मिनट लग सकते हैं)
terraform apply -auto-approve
- पुष्टि करें
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. फ़्लीट का रजिस्ट्रेशन
हमें क्लस्टर को फ़्लीट में रजिस्टर करना होगा.
- पक्का करें कि आप
gke-tfडायरेक्ट्री में हों और यहां दी गई कमांड चलाएं.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
fleet.tf फ़ाइल, दोनों क्लस्टर को ग्लोबल GKE फ्लीट में रजिस्टर करती है. साथ ही, मल्टी-क्लस्टर सर्विस डिस्कवरी और इनग्रेस को चालू करती है. यह यूएस क्लस्टर को सेंट्रल कॉन्फ़िगरेशन क्लस्टर के तौर पर तय करता है. इससे Gateway API, ट्रैफ़िक को मॉनिटर और रूट कर पाता है.
gke-tfफ़ोल्डर में जाकर, इसे चलाएं(इसमें 3 से 5 मिनट लगेंगे)
terraform plan
terraform apply -auto-approve
- फ़्लीट के रजिस्ट्रेशन की पुष्टि करना
gcloud container fleet memberships list --project=$PROJECT_ID
5. मॉडल के वज़न को FUSE में कैश मेमोरी में सेव करना
हम अमेरिका के क्लस्टर में कुछ समय के लिए Kubernetes जॉब चलाएंगे. इससे Python स्क्रिप्ट के ज़रिए, Gemma मॉडल को सीधे तौर पर FUSE-माउंट किए गए Cloud Storage बकेट में सुरक्षित तरीके से डाउनलोड किया जा सकेगा.
- ये वैरिएबल बनाएं
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- यह google/gemma-3-27b-it मॉडल का इस्तेमाल करता है. इसलिए, आपको HF टोकन बनाना होगा. यहां दिए गए
YOUR_ACTUAL_HUGGING_FACE_TOKENकी जगह अपना असल टोकन डालें.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- पक्का करें कि आप
gke-tfडायरेक्ट्री में हों और यहां दी गई कमांड चलाएं.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- डाउनलोड पूरा होने का इंतज़ार करें. इसके बाद, आगे बढ़ें (मॉडल के साइज़ के हिसाब से, इसमें 5 से 10 मिनट लग सकते हैं)
kubectl logs -f job/model-downloader --context=$CTX_US
(जब "डाउनलोड पूरा हो गया!" मैसेज दिखे, तब लॉग से बाहर निकलने के लिए Ctrl+C दबाएं)
6. Workload vLLM और Gemma को डिप्लॉय करना
- पक्का करें कि आप
gke-tfडायरेक्ट्री में हों और यहां दी गई कमांड चलाएं.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- अब यहां दी गई स्क्रिप्ट को लागू करें (इसे लागू होने में 5 से 10 मिनट लगेंगे, क्योंकि इसे दो क्षेत्रों में डिप्लॉय किया जाता है)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- तैनात करने की पुष्टि करें
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- सेट अप पूरा होने के बाद, यह पुष्टि की जा सकती है कि मैनेज किए गए DRANET नेटवर्क को पॉड असाइन किए गए थे. इसके लिए, यह कमांड चलाएं.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
आपको स्टैंडर्ड पॉड नेटवर्किंग के लिए, अतिरिक्त नेटवर्क इंटरफ़ेस eth0 दिखेगा. इसके साथ ही, आपके टीपीयू फ़ैब्रिक eth1,eth2 वगैरह को दिखाने वाले सेकंडरी इंटरफ़ेस भी दिखेंगे.
7. Inference API और Gateway Configuration
अब आपको InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) और Inference Pool(gemma-pool) बनाना होगा. इन्फ़रेंस पूल, हेल्म चार्ट का इस्तेमाल करके बनाया जाता है. यह कुकी, ऐप्लिकेशन इंस्टॉल करती है और पुष्टि करती है कि ऐप्लिकेशन बनाया गया है.
- पक्का करें कि आप
gke-tfडायरेक्ट्री में हों और यहां दी गई कमांड चलाएं. इससे ऑब्जेक्ट डिप्लॉय हो जाएगा और पुष्टि की प्रक्रिया शुरू हो जाएगी.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. गेटवे कॉन्फ़िगरेशन
अब आपको क्रॉस-रीजनल गेटवे कॉन्फ़िगरेशन बनाना होगा. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. इन्फ़रेंस पूल, Helm चार्ट का इस्तेमाल करके बनाया जाता है. यह कुकी, ऐप्लिकेशन इंस्टॉल करती है और पुष्टि करती है कि ऐप्लिकेशन बनाया गया है. (गेटवे को चालू होने में 8 से 10 मिनट लगेंगे)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
इन्फ़रेंस पूल (Helm): यह दोनों क्षेत्रों के मॉडल सर्वर को एक ही लॉजिकल बैकएंड में ग्रुप करता है.
Gateway & HTTPRoute: यह ग्लोबल इंटरनल लोड बैलेंसर बनाता है. साथ ही, एआई प्रॉम्प्ट को आपके मॉडल पर रूट करने के नियम तय करता है.
HealthCheck और बैकएंड नीतियां: यह पक्का करती हैं कि अनुरोध सिर्फ़ सही पॉड को भेजे जाएं. साथ ही, यह मेट्रिक पर आधारित ट्रैफ़िक डिस्ट्रिब्यूशन को स्मार्ट तरीके से मैनेज करती हैं, ताकि टीपीयू पर ज़्यादा लोड न पड़े.
पुष्टि करना: स्क्रिप्ट तब तक रुकती है, जब तक Google Cloud इंटरनल आईपी पतों को पूरी तरह से उपलब्ध नहीं करा देता. इसके बाद ही, स्क्रिप्ट आगे बढ़ती है.
9. फ़ेलओवर टेस्ट
अब लैब का सबसे अहम हिस्सा: अपने आर्किटेक्चर की हाई अवेलेबिलिटी की जांच करना.
ऑटोमेटेड टेस्ट से ये काम होंगे:
- बेसलाइन टेस्ट: हमारा सिम्युलेटेड उपयोगकर्ता, अनुमान लगाने के लिए प्रॉम्प्ट भेजता है ("फ़्रांस की राजधानी क्या है?"). उपयोगकर्ता प्राइमरी क्षेत्र में है. इसलिए, Gateway अनुरोध को कम से कम समय में पूरा करने के लिए, उन लोकल टीपीयू पर भेजता है.
- समस्या: हमने प्राइमरी रीजन (
replicas=0) में मौजूद सभी टीपीयू पॉड को बंद करके, डेटा सेंटर में आने वाली बड़ी समस्या को सिम्युलेट किया. - डिटेक्शन: हम 45 सेकंड तक इंतज़ार करते हैं. इस विंडो के दौरान, गेटवे के हेल्थ चेक फ़ेल हो जाते हैं. इससे पता चलता है कि प्राइमरी बैकएंड पूरी तरह से ऑफ़लाइन है. साथ ही, यह अपनी ग्लोबल राउटिंग टेबल को डाइनैमिक तरीके से अपडेट करता है.
- फ़ेलओवर: हमारा उपयोगकर्ता दूसरा प्रॉम्प्ट ("जर्मनी की राजधानी क्या है?") भेजता है. उपयोगकर्ता को इस बारे में कोई जानकारी नहीं है कि सेवा काम नहीं कर रही है. गेटवे, अनुरोध को इंटरसेप्ट करता है और उसे दुनिया भर में आपके सही तरीके से काम कर रहे सेकंडरी टीपीयू पर तुरंत रीडायरेक्ट कर देता है.
- रिकवरी: हम प्राइमरी टीपीयू को पहले जैसा कर देते हैं. इससे आपका ग्लोबल आर्किटेक्चर पूरी तरह से ठीक हो जाता है.
- Cloud Shell खोलें और यह कमांड चलाएं:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- जांच पूरी होने के बाद, क्लीन अप किया जा सकता है.
10. व्यवस्थित करें
- वर्कलोड को मैनेज करना
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- इन्फ़्रास्ट्रक्चर को साफ़ करें. पक्का करें कि आप
gke-tfफ़ोल्डर में हों.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
अगर आपको किसी संसाधन को मिटाने में कोई समस्या आ रही है, तो आपको terraform destroy कमांड स्क्रिप्ट ./cleanup-tf.sh को फिर से चलाना चाहिए
11. बधाई हो
बधाई हो! आपने GKE का इस्तेमाल करके, एक से ज़्यादा क्लस्टर वाला GKE Inference Gateway डिप्लॉय किया है. यह हर समय उपलब्ध रहता है. साथ ही, आपने GKE का इस्तेमाल करके, अलग-अलग क्षेत्रों में एआई इन्फ़्रेंस आर्किटेक्चर डिप्लॉय किया है. इसके अलावा, आपने मैनेज किए गए DRANET और TPU v6e ऐक्सलरेटर डिप्लॉय किए हैं.
मॉडल को तुरंत लोड करने के लिए Cloud Storage FUSE और कम समय में नतीजे पाने के लिए Inference Gateway API का इस्तेमाल करके, आपने एक ऐसा बैकएंड बनाया है जो किसी रीजनल डेटा सेंटर के पूरी तरह से बंद होने पर भी काम करता रहता है. साथ ही, इससे इंटरनल यूज़र ट्रैफ़िक में भी कोई गिरावट नहीं आती.
अगले चरण / ज़्यादा जानें
GKE नेटवर्किंग के बारे में ज़्यादा जानें
अगली लैब पर जाएं
Google Cloud के साथ अपनी क्वेस्ट जारी रखें. साथ ही, Google Cloud के इन अन्य लैब को आज़माएं: