
1. Ringkasan
Lab ini memperkenalkan Infrastruktur AI yang dapat digunakan untuk menjalankan workload AI. Anda akan menggunakan hal berikut:
Google Kubernetes Engine (GKE) - Platform orkestrasi container dasar.
DRANET yang dikelola GKE - Jaringan Alokasi Resource Dinamis yang secara langsung menetapkan fabric interkoneksi berkecepatan tinggi ke pod TPU Anda.
GKE Inference Gateway - Ini adalah objek Gateway terkelola dari Google Cloud yang disesuaikan untuk Inferensi. Dalam hal ini, kita akan menggunakan kemampuan multi-cluster.
Tensor Processing Unit (TPU) - Chip akselerator buatan khusus Google.
Cloud Storage FUSE - Antarmuka penyimpanan yang memungkinkan pod memasang bucket Cloud Storage secara langsung, sehingga memungkinkan pemuatan bobot model yang sangat besar secara instan.
Untuk mengonfigurasi, Anda akan men-deploy VPC kustom, bucket Cloud Storage, dan dua cluster di region yang berbeda. Setiap cluster akan memiliki nodepool TPU yang menggunakan DRANET terkelola untuk jaringannya. Setelah menambahkan cluster ke Fleet, Anda akan menyimpan bobot model Gemma dalam cache di bucket dan men-deploy workload vLLM yang langsung memasang bobot tersebut melalui Cloud Storage FUSE. Terakhir, GKE Inference Gateway akan dikonfigurasi untuk merutekan traffic, sehingga Anda dapat melakukan uji failover lintas regional langsung.
Konfigurasi akan menggunakan kombinasi Terraform, gcloud, dan kubectl.
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
- Menyiapkan VPC, jaringan, penyimpanan
- Menyiapkan cluster GKE dalam mode standar
- Membuat node pool TPU dan menggunakan DRANET terkelola
- Menambahkan cluster ke fleet
- Bobot model cache
- Menyiapkan gateway Inferensi GKE multi-cluster dan menguji failover
Di lab ini, Anda akan membuat pola berikut.
Gambar 1.
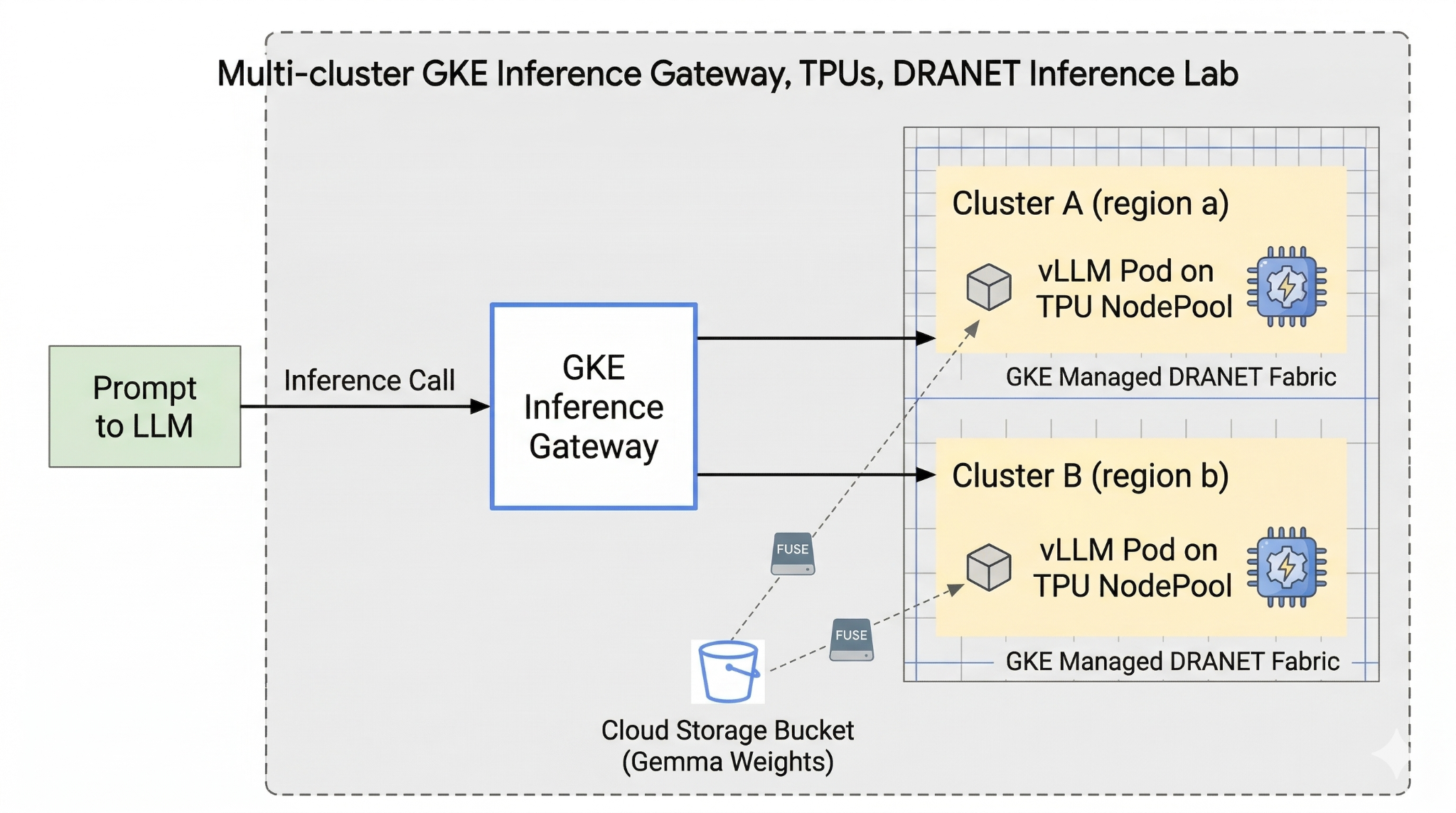
2. Penyiapan layanan Google Cloud
Penyiapan lingkungan mandiri
- Login ke Google Cloud Console dan buat project baru atau gunakan kembali project yang sudah ada. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.

- Project name adalah nama tampilan untuk peserta project ini. String ini adalah string karakter yang tidak digunakan oleh Google API. Anda dapat memperbaruinya kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Cloud Console otomatis membuat string unik; biasanya Anda tidak mementingkan kata-katanya. Di sebagian besar codelab, Anda harus merujuk Project ID-nya (umumnya diidentifikasi sebagai
PROJECT_ID). Jika tidak suka dengan ID yang dibuat, Anda dapat membuat ID acak lainnya. Atau, Anda dapat mencobanya sendiri, dan lihat apakah ID tersebut tersedia. ID tidak dapat diubah setelah langkah ini dan tersedia selama durasi project. - Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
- Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource/API Cloud. Menjalankan operasi dalam codelab ini tidak akan memakan banyak biaya, bahkan mungkin tidak sama sekali. Guna mematikan resource agar tidak menimbulkan penagihan di luar tutorial ini, Anda dapat menghapus resource yang dibuat atau menghapus project-nya. Pengguna baru Google Cloud memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai $300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
3. Menyiapkan lingkungan dengan Terraform
Untuk mengerjakan lab ini, Anda memerlukan akses ke TPU. Versi yang digunakan adalah TPU v6e.
- Anda harus mengikuti dokumen rencana TPU dan mengaktifkan kuota TPU untuk mendapatkan akses.
- Kita menggunakan deployment kecil yang memerlukan 4 chip TPU v6e (
ct6e-standard-4t)yang akan menjadi slice 2x2 di dua region yang berbeda. - Token Hugging Face: Token Akses diperlukan untuk mendownload bobot model Gemma
Kita akan membuat VPC kustom dengan aturan firewall, penyimpanan, dan subnet. Buka konsol cloud dan pilih project yang akan Anda gunakan.
- Buka Cloud Shell yang berada di bagian atas konsol Anda di sebelah kanan, pastikan Anda melihat project id yang benar di Cloud Shell, dan konfirmasi setiap perintah untuk mengizinkan akses.

- Buat folder bernama
gke-tf, lalu pindahkan ke folder tersebut
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Sekarang, tambahkan beberapa file konfigurasi. Tindakan ini akan membuat file network.tf , variable.tf, providers.tf, fuse.tf berikut.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
File variable.tf menambahkan nama project, region, dan informasi zona. p.s. Perbarui variabel "regions", default = ["europe-west4", "us-east5"] dengan region tempat Anda memiliki kuota TPU. Untuk mengetahui info selengkapnya, lihat dokumen ini " Memvalidasi ketersediaan TPU di GKE".
network.tf menambahkan VPC baru di project Anda dengan subnet di dua zona yang berbeda, subnet khusus proxy, aturan firewall.
provider.tf menambahkan penyedia yang relevan untuk mendukung Terraform
fuse.tf menambahkan bucket Cloud Storage untuk meng-cache bobot model Anda dan menyediakan Akun Layanan IAM dengan izin objectAdmin. Akun ini mengikat akun tersebut ke Workload Identity GKE
- Pastikan Anda berada di direktori gke-tf dan jalankan perintah berikut
terraform init -Menginisialisasi direktori kerja. Langkah ini mendownload penyedia yang diperlukan untuk konfigurasi tertentu.terraform plan -Membuat rencana eksekusi, yang menunjukkan tindakan yang akan dilakukan Terraform untuk men-deploy infrastruktur Anda.terraform apply –auto-approvemenjalankan update dan menyetujui secara otomatis.
terraform init
terraform plan
- Sekarang jalankan deployment (Proses ini mungkin memerlukan waktu antara 3-5 menit)
terraform apply -auto-approve
- Di folder
gke-tfyang sama, buat file gke.tf berikut.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
gke.tf menambahkan dua cluster di region yang berbeda, dan membuat dua node pool TPU yang menjalankan TPU v6e dengan 4 chip, serta menetapkan DRANET terkelola ke node pool.
- Sekarang jalankan deployment (Proses ini mungkin memerlukan waktu antara 10-15 menit)
terraform apply -auto-approve
- Verifikasi
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Pendaftaran fleet
Kita perlu mendaftarkan cluster ke Fleet.
- Pastikan Anda berada di direktori
gke-tfdan jalankan perintah berikut.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
File fleet.tf mendaftarkan kedua cluster ke GKE Fleet global dan mengaktifkan Penemuan Layanan dan Ingress Multi-Cluster. Tindakan ini menetapkan cluster AS sebagai cluster konfigurasi pusat, sehingga Gateway API dapat memantau dan merutekan traffic.
- Di folder
gke-tfdan jalankan (proses ini akan memakan waktu 3-5 menit)
terraform plan
terraform apply -auto-approve
- Memvalidasi pendaftaran Fleet
gcloud container fleet memberships list --project=$PROJECT_ID
5. Meng-cache bobot model ke FUSE
Kita akan menjalankan Tugas Kubernetes sementara di cluster AS untuk mendownload model Gemma secara aman melalui skrip Python langsung ke bucket Cloud Storage yang di-mount FUSE.
- Buat variabel berikut
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- Ini menggunakan model google/gemma-3-27b-it sehingga Anda perlu membuat token HF. Ganti
YOUR_ACTUAL_HUGGING_FACE_TOKENdi bawah dengan token Anda yang sebenarnya.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Pastikan Anda berada di direktori
gke-tfdan jalankan perintah berikut.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Tunggu hingga download selesai sebelum melanjutkan (proses ini akan memakan waktu 5-10 menit, bergantung pada ukuran model)
kubectl logs -f job/model-downloader --context=$CTX_US
(Tekan Ctrl+C untuk keluar dari log setelah muncul pesan "Download selesai!")
6. Men-deploy Workload vLLM dan Gemma
- Pastikan Anda berada di direktori
gke-tfdan jalankan perintah berikut.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Sekarang, jalankan skrip berikut (Proses ini akan memerlukan waktu antara 5 - 10 menit untuk selesai karena di-deploy di dua region)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Konfirmasi deployment
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- Setelah selesai, Anda dapat memvalidasi bahwa jaringan DRANET yang dikelola telah ditetapkan ke pod dengan menjalankan.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Anda akan melihat antarmuka jaringan tambahan eth0 untuk jaringan pod standar, bersama dengan antarmuka sekunder yang merepresentasikan fabric TPU khusus Anda eth1, eth2,, dll.
7. Konfigurasi Gateway dan API Inferensi
Sekarang, Anda akan membuat InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) dan Inference Pool(gemma-pool). Kumpulan inferensi dibuat menggunakan diagram Helm. Menginstal dan memvalidasi pembuatan.
- Pastikan Anda berada di direktori
gke-tfdan jalankan perintah berikut. Tindakan ini akan men-deploy objek dan menjalankan validasi.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Konfigurasi Gateway
Sekarang Anda akan membuat konfigurasi Cross-Regional Gateway. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. Kumpulan inferensi dibuat menggunakan diagram Helm. Menginstal dan memvalidasi pembuatan. (Proses ini akan memerlukan waktu 8-10 menit hingga Gateway menjadi aktif)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Kumpulan Inferensi (Helm): Mengelompokkan server model Anda dari kedua region ke dalam satu backend logis.
Gateway & HTTPRoute: Membuat Load Balancer internal global yang sebenarnya dan menentukan aturan untuk merutekan perintah AI yang masuk ke model Anda.
Kebijakan HealthCheck & Backend: Memastikan permintaan hanya dikirim ke pod yang berfungsi dengan baik dan memungkinkan distribusi traffic berbasis metrik yang cerdas (mencegah TPU kelebihan beban).
Validasi: Skrip akan dijeda untuk memastikan Google Cloud telah sepenuhnya menyediakan alamat IP Internal sebelum Anda melanjutkan.
9. Pengujian failover
Sekarang saatnya bagian terbaik dari lab: menguji ketersediaan tinggi arsitektur Anda.
Berikut adalah tindakan yang akan dilakukan oleh pengujian otomatis ini:
- Uji Dasar: Pengguna simulasi kami mengirimkan perintah inferensi ("Apa ibu kota Prancis?"). Karena pengguna berada di region utama, Gateway merutekan permintaan ke TPU lokal tersebut untuk mendapatkan latensi serendah mungkin.
- Bencana: Kami menyimulasikan pemadaman layanan pusat data yang parah dengan menghentikan semua pod TPU di region utama (
replicas=0). - Deteksi: Kita menunggu selama 45 detik. Selama periode ini, health check Gateway gagal, Gateway menyadari bahwa backend utama sepenuhnya offline, dan Gateway memperbarui tabel perutean globalnya secara dinamis.
- Failover: Pengguna kami mengirimkan perintah kedua ("Apa ibu kota Jerman?"). Pengguna tidak tahu bahwa ada gangguan. Gateway mencegat permintaan dan langsung mengalihkan permintaan tersebut ke seluruh dunia ke TPU sekunder yang berfungsi dengan baik.
- Pemulihan: Kami memulihkan TPU utama, sehingga arsitektur global Anda kembali berfungsi sepenuhnya.
- Buka Cloud Shell dan jalankan perintah berikut:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- Setelah pengujian selesai, Anda dapat membersihkan.
10. Pembersihan
- Membersihkan workload
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Kosongkan infrastruktur. Pastikan Anda berada di folder
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Jika Anda mengalami masalah saat menghapus resource tertentu, Anda harus menjalankan kembali skrip perintah terraform destroy ./cleanup-tf.sh
11. Selamat
Selamat! Anda telah berhasil men-deploy arsitektur inferensi AI lintas regional yang sangat tersedia dan multi-cluster menggunakan GKE Inference Gateway, DRANET terkelola, dan akselerator TPU v6e.
Dengan menggabungkan Cloud Storage FUSE untuk pemuatan model instan dan Inference Gateway API untuk perutean multi-cluster yang memperhatikan latensi, Anda telah membangun backend yang tangguh dan mampu bertahan dari gangguan pusat data regional yang lengkap tanpa menghentikan traffic pengguna internal.
Langkah berikutnya/Pelajari lebih lanjut
Anda dapat membaca lebih lanjut tentang jaringan GKE
Ikuti lab berikutnya
Lanjutkan quest Anda dengan Google Cloud, dan pelajari lab Google Cloud lainnya: