
1. Przegląd
W tym module zapoznasz się z infrastrukturą AI, której można używać do uruchamiania zadań AI. Będziesz pracować z tymi elementami:
Google Kubernetes Engine (GKE) – podstawowa platforma do orkiestracji kontenerów.
Zarządzana przez GKE sieć DRANET – dynamiczna alokacja zasobów sieciowych, która bezpośrednio przypisuje szybkie połączenia międzysieciowe do podów TPU.
Brama wnioskowania GKE – zarządzany obiekt bramy z Google Cloud, który jest dostosowany do wnioskowania. W tym przypadku użyjemy funkcji wieloklastrowych.
Jednostka Tensor Processing Unit (TPU) – opracowane przez Google specjalne układy akceleratorów.
Cloud Storage FUSE – interfejs pamięci masowej, który umożliwia podom bezpośrednie podłączanie zasobników Cloud Storage, co pozwala na natychmiastowe wczytywanie ogromnych wag modelu.
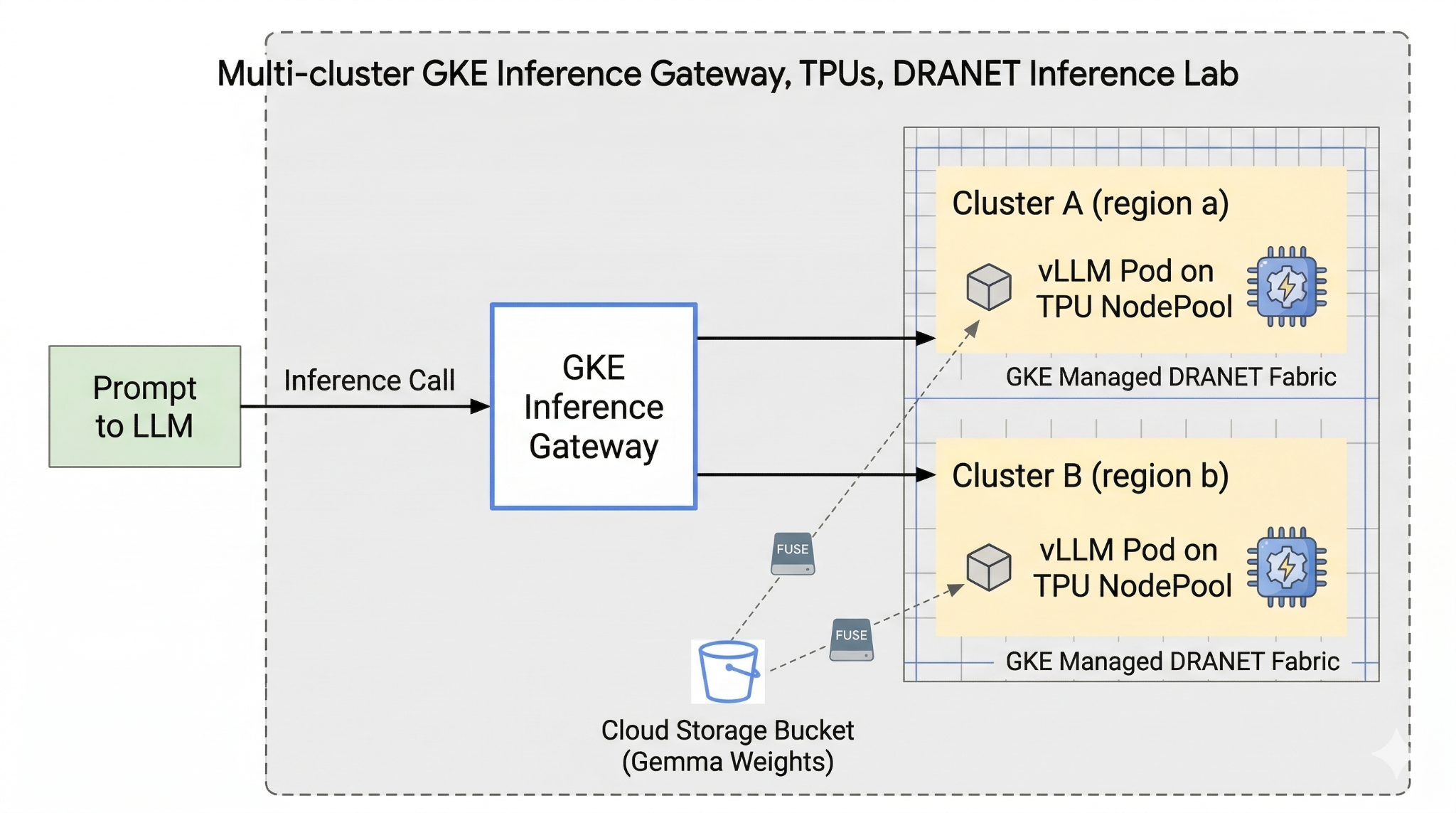
Aby skonfigurować wdrożenie niestandardowej sieci VPC, zasobnika Cloud Storage i 2 klastrów w różnych regionach: Każdy klaster będzie miał pulę węzłów TPU korzystającą z zarządzanej sieci DRANET. Po dodaniu klastrów do floty zapiszesz wagi modelu Gemma w zasobniku i wdrożysz zadanie vLLM, które natychmiast zamontuje te wagi za pomocą Cloud Storage FUSE. Na koniec skonfigurujemy bramę wnioskowania GKE do kierowania ruchem, co umożliwi przeprowadzenie testu przełączania awaryjnego w różnych regionach.
Konfiguracje będą korzystać z połączenia Terraform, gcloud i kubectl.
W tym laboratorium dowiesz się, jak wykonać następujące zadanie:
- Konfigurowanie sieci VPC, sieci i pamięci masowej
- Konfigurowanie klastra GKE w trybie standardowym
- Tworzenie puli węzłów TPU i korzystanie z zarządzanej sieci DRANET
- Dodawanie klastra do floty
- Pamięć podręczna wag modelu
- Konfigurowanie bramy wnioskowania GKE w wielu klastrach i testowanie przełączania awaryjnego
W tym laboratorium utworzysz ten wzorzec.
Rysunek 1.
2. Konfigurowanie usług Google Cloud
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
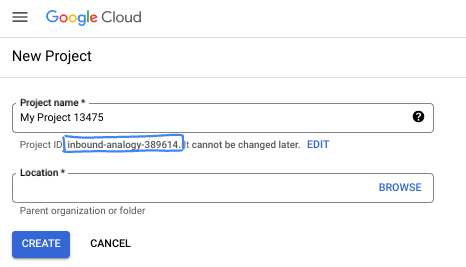
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego ćwiczenia nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym ćwiczeniu w Codelabs możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Konfigurowanie środowiska za pomocą Terraform
Aby ukończyć ten moduł, musisz mieć dostęp do układów TPU. Używana jest wersja TPU v6e.
- Aby uzyskać dostęp, postępuj zgodnie z dokumentem dotyczącym planu TPU i włącz limit TPU.
- Używamy małego wdrożenia, które wymaga 4 chipów TPU v6e (
ct6e-standard-4t)będzie to wycinek 2x2 w 2 różnych regionach). - Token Hugging Face: do pobrania wag modelu Gemma potrzebny jest token dostępu.
Utworzymy niestandardową sieć VPC z regułami zapory sieciowej, pamięcią masową i podsiecią. Otwórz konsolę Google Cloud i wybierz projekt, którego będziesz używać.
- Otwórz Cloud Shell w prawym górnym rogu konsoli. Sprawdź, czy w Cloud Shell widzisz prawidłowy identyfikator projektu, i potwierdź wszystkie prośby o przyznanie dostępu.

- Utwórz folder o nazwie
gke-tfi przenieś do niego plik.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Teraz dodaj pliki konfiguracji. Spowoduje to utworzenie plików network.tf, variable.tf, providers.tf i fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
Plik variable.tf dodaje nazwę projektu, regiony i informacje o strefie. P.S. Zaktualizuj zmienną „regions” default = ["europe-west4", "us-east5"] o regiony, w których masz limit jednostek TPU. Więcej informacji znajdziesz w dokumencie „Sprawdzanie dostępności TPU w GKE”.
network.tf dodaje do projektu nową sieć VPC z podsieciami w 2 różnych strefach, podsieciami tylko dla serwerów proxy i regułami zapory sieciowej.
Symbol provider.tf dodaje odpowiedniego dostawcę, aby obsługiwać Terraform.
fuse.tf dodaje zasobnik Cloud Storage do buforowania wag modelu i udostępnia konto usługi z uprawnieniami objectAdmin. Łączy to konto z Workload Identity w GKE.
- Upewnij się, że jesteś w katalogu gke-tf, i uruchom te polecenia:
terraform init -Inicjuje katalog roboczy. Ten krok pobiera dostawców wymaganych w danej konfiguracji.terraform plan -Generuje plan wykonania, który pokazuje, jakie działania Terraform podejmie w celu wdrożenia infrastruktury.terraform apply –auto-approveprzeprowadza aktualizacje i automatycznie je zatwierdza.
terraform init
terraform plan
- Teraz uruchom wdrożenie (może to potrwać 3–5 minut).
terraform apply -auto-approve
- W tym samym folderze
gke-tfutwórz ten plik gke.tf.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
Polecenie gke.tf dodaje 2 klastry w różnych regionach i tworzy 2 pule węzłów TPU, które uruchamiają TPU w wersji 6e z 4 chipami, a także przypisuje zarządzaną sieć DRANET do pul węzłów.
- Teraz uruchom wdrożenie (może to potrwać od 10 do 15 minut).
terraform apply -auto-approve
- Zweryfikuj
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Rejestracja floty
Musimy zarejestrować klaster we flocie.
- Upewnij się, że jesteś w katalogu
gke-tf, i uruchom te polecenia.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
Plik fleet.tf rejestruje oba klastry w globalnej flocie GKE i włącza wieloklastrowe wykrywanie usług oraz Multi Cluster Ingress. Wyznacza klaster w Stanach Zjednoczonych jako centralny klaster konfiguracji, co umożliwia interfejsowi Gateway API monitorowanie i kierowanie ruchem.
- W folderze
gke-tfuruchom (powinno to zająć 3–5 minut).
terraform plan
terraform apply -auto-approve
- Weryfikowanie rejestracji floty
gcloud container fleet memberships list --project=$PROJECT_ID
5. Zapisywanie wag modelu w pamięci podręcznej FUSE
W klastrze w USA uruchomimy tymczasowe zadanie Kubernetes, aby bezpiecznie pobrać model Gemma za pomocą skryptu w Pythonie bezpośrednio do zasobnika Cloud Storage zamontowanego za pomocą FUSE.
- Utwórz te zmienne:
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- W tym celu używany jest model google/gemma-3-27b-it, więc musisz utworzyć token HF. Zastąp ciąg
YOUR_ACTUAL_HUGGING_FACE_TOKENponiżej rzeczywistym tokenem.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Upewnij się, że jesteś w katalogu
gke-tf, i uruchom te polecenia.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Zanim przejdziesz dalej, poczekaj, aż pobieranie się zakończy (w zależności od rozmiaru modelu powinno to potrwać 5–10 minut).
kubectl logs -f job/model-downloader --context=$CTX_US
(Gdy pojawi się komunikat „Pobieranie zakończone!”, naciśnij Ctrl+C, aby zamknąć dzienniki).
6. Wdrażanie zadań vLLM i Gemma
- Upewnij się, że jesteś w katalogu
gke-tf, i uruchom te polecenia.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Teraz wykonaj ten skrypt (może to potrwać od 5 do 10 minut, ponieważ wdrażanie odbywa się w 2 regionach).
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Potwierdzanie wdrożenia
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- Po zakończeniu możesz sprawdzić, czy zarządzana sieć DRANET została przypisana do zasobników, uruchamiając:
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Zobaczysz dodatkowe interfejsy sieci eth0 dla standardowej sieci podów oraz interfejsy dodatkowe reprezentujące dedykowaną sieć TPU eth1, eth2 itp.
7. Konfiguracja interfejsu Inference API i bramy
Teraz utworzysz InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) i Inference Pool(gemma-pool). Pula wnioskowania jest tworzona za pomocą wykresu Helm. Instaluje i weryfikuje utworzoną usługę.
- Upewnij się, że jesteś w katalogu
gke-tf, i uruchom te polecenia. Spowoduje to wdrożenie obiektu i przeprowadzenie weryfikacji.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Konfiguracja bramy
Teraz utworzysz konfigurację bramy międzyregionalnej. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. Pula wnioskowania jest tworzona za pomocą karty Helm. Instaluje i weryfikuje utworzoną usługę. (aktywacja bramy zajmie 8–10 minut)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Pula wnioskowania (Helm): grupuje serwery modeli z obu regionów w jeden logiczny backend.
Gateway i HTTPRoute: tworzy rzeczywisty globalny wewnętrzny system równoważenia obciążenia i definiuje reguły kierowania przychodzących promptów AI do Twoich modeli.
Zasady kontroli stanu i backendu: zapewniają wysyłanie żądań tylko do sprawnych zasobników i umożliwiają inteligentną dystrybucję ruchu na podstawie danych (zapobiegając przeciążeniu jednostek TPU).
Weryfikacja: skrypt wstrzymuje działanie, aby upewnić się, że Google Cloud w pełni udostępnił wewnętrzne adresy IP, zanim przejdziesz dalej.
9. Test przełączania awaryjnego
Teraz przejdźmy do najlepszej części laboratorium: testowania wysokiej dostępności architektury.
Oto co dokładnie zrobi ten automatyczny test:
- Test podstawowy: nasz symulowany użytkownik wysyła prompta z prośbą o wyciągnięcie wniosków („Jaka jest stolica Francji?”). Ponieważ użytkownik znajduje się w regionie podstawowym, brama kieruje żądanie do lokalnych układów TPU, aby zapewnić jak najmniejsze opóźnienie.
- Katastrofa: symulujemy katastrofalną awarię centrum danych, wyłączając wszystkie pody TPU w regionie podstawowym (
replicas=0). - Wykrywanie: czekamy 45 sekund. W tym czasie testy stanu bramy kończą się niepowodzeniem, brama stwierdza, że podstawowy backend jest całkowicie niedostępny, i dynamicznie aktualizuje globalne tabele routingu.
- Przełączenie awaryjne: użytkownik wysyła drugi prompt („Jaka jest stolica Niemiec?”). Użytkownik nie wie, że wystąpiła awaria. Brama przechwytuje żądanie i natychmiast przekierowuje je na całym świecie do zdrowych drugorzędnych jednostek TPU.
- Przywracanie: przywracamy podstawowe jednostki TPU, dzięki czemu Twoja globalna architektura znów działa w pełni.
- Otwórz Cloud Shell i uruchom to polecenie:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- Po zakończeniu testu możesz zwolnić miejsce.
10. Czyszczenie danych
- Zwalnianie miejsca w zadaniu
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Zwolnij miejsce w infrastrukturze. Upewnij się, że jesteś w folderze
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Jeśli podczas usuwania określonych zasobów napotkasz problemy, ponownie uruchom terraform destroyskrypt poleceń./cleanup-tf.sh.
11. Gratulacje
Gratulacje! Udało Ci się wdrożyć wysoce dostępną architekturę wnioskowania AI w wielu klastrach GKE i wielu regionach, która korzysta z GKE, zarządzanych akceleratorów DRANET i TPU v6e.
Dzięki połączeniu Cloud Storage FUSE do natychmiastowego wczytywania modeli i interfejsu Inference Gateway API do routingu w wielu klastrach z uwzględnieniem opóźnień udało Ci się stworzyć odporny backend, który może przetrwać całkowitą awarię regionalnego centrum danych bez utraty ruchu użytkowników wewnętrznych.
Kolejne kroki / Więcej informacji
Więcej informacji o zarządzaniu siecią GKE
Przejdź do kolejnego modułu
Kontynuuj naukę w Google Cloud i zapoznaj się z tymi modułami Google Cloud: