
1. Visão geral
Este laboratório apresenta a infraestrutura de IA que pode ser usada para executar cargas de trabalho de IA. Você vai trabalhar com o seguinte:
Google Kubernetes Engine (GKE): a plataforma básica de orquestração de contêineres.
DRANET gerenciado pelo GKE: rede de alocação dinâmica de recursos que atribui diretamente estruturas de interconexão de alta velocidade aos seus pods de TPU.
GKE Inference Gateway: um objeto de gateway gerenciado do Google Cloud adaptado para inferência. Neste caso, vamos usar os recursos de vários clusters.
Unidade de Processamento de Tensor (TPU): chips aceleradores personalizados do Google.
Cloud Storage FUSE: uma interface de armazenamento que permite que pods ativem buckets do Cloud Storage diretamente, possibilitando o carregamento instantâneo de pesos de modelos massivos.
Para configurar, você vai implantar uma VPC personalizada, um bucket do Cloud Storage e dois clusters em regiões diferentes. Cada cluster terá um pool de nós de TPU usando DRANET gerenciado para a rede. Depois de adicionar os clusters a uma frota, você vai armazenar em cache os pesos do modelo Gemma no bucket e implantar uma carga de trabalho vLLM que monta esses pesos instantaneamente usando o Cloud Storage FUSE. Por fim, o GKE Inference Gateway será configurado para rotear o tráfego, permitindo que você execute um teste de failover entre regiões em tempo real.
As configurações vão usar uma combinação de Terraform, gcloud e kubectl.
Neste laboratório, você vai aprender a:
- Configurar VPC, redes e armazenamento
- Configurar um cluster do GKE no modo padrão
- Criar um pool de nós da TPU e usar o DRANET gerenciado
- Adicionar cluster à frota
- Armazenar em cache os pesos do modelo
- Configurar o gateway de inferência do GKE de vários clusters e testar o failover
Neste laboratório, você vai criar o seguinte padrão:
Figura 1.
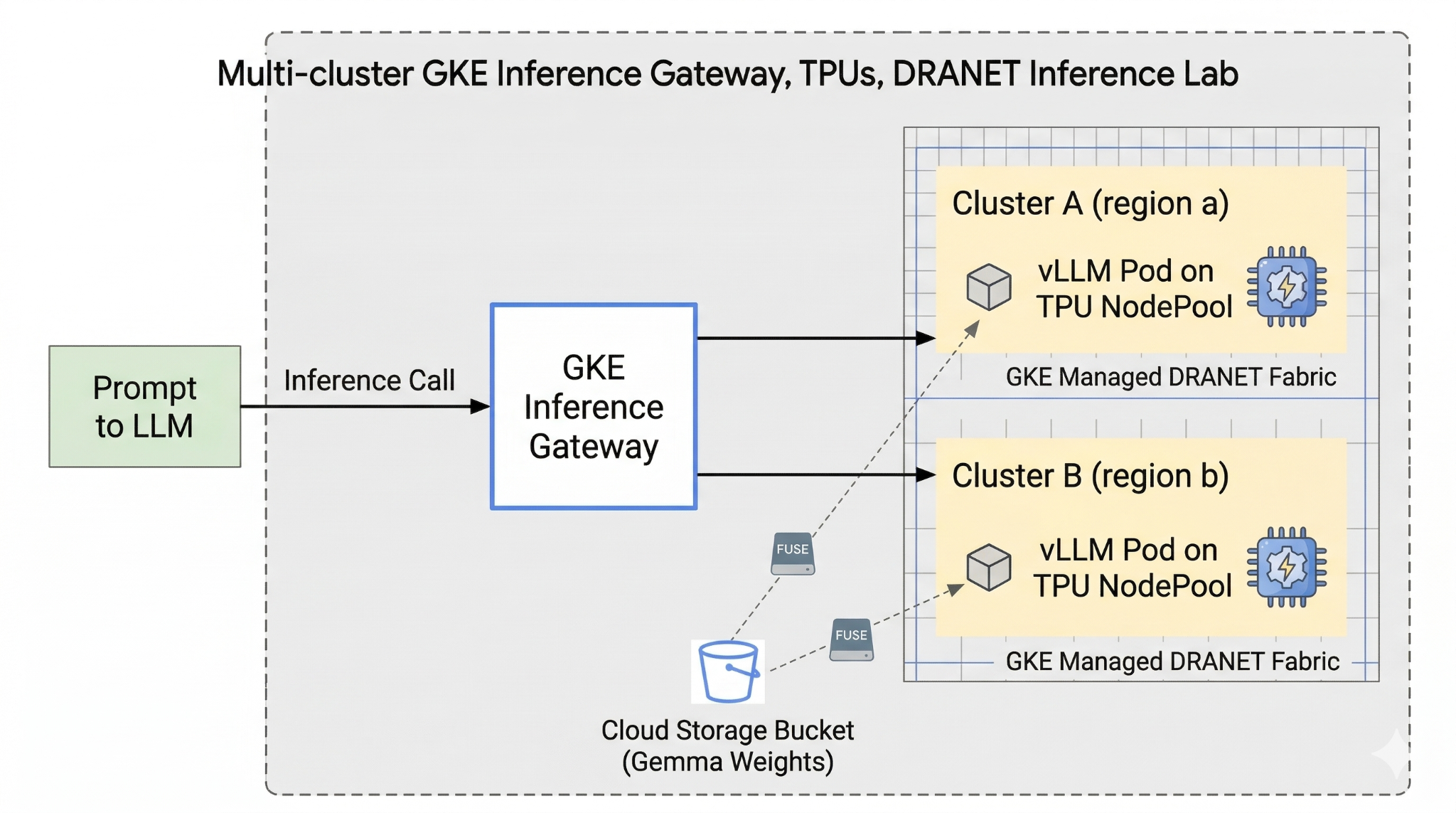
2. Configuração dos serviços do Google Cloud
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
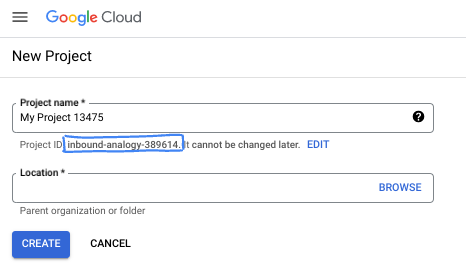
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Configurar o ambiente com o Terraform
Para fazer este laboratório, você precisa de acesso às TPUs. A versão exata usada é a TPU v6e.
- Siga o documento do plano de TPU e ative a cota de TPU para ter acesso.
- Estamos usando uma implantação pequena que exige quatro chips de TPU v6e (
ct6e-standard-4t), que será uma fração 2x2 em duas regiões diferentes. - Token do Hugging Face: um token de acesso é necessário para fazer o download dos pesos do modelo Gemma.
Vamos criar uma VPC personalizada com regras de firewall, armazenamento e sub-rede. Abra o console do Cloud e selecione o projeto que você vai usar.
- Abra o Cloud Shell, localizado na parte superior direita do console. Verifique se o ID do projeto correto aparece no Cloud Shell e confirme todas as solicitações para permitir o acesso.

- Crie uma pasta chamada
gke-tfe acesse-a.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Agora adicione alguns arquivos de configuração. Isso vai criar os seguintes arquivos: network.tf, variable.tf, providers.tf e fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
Os arquivos variable.tf adicionam o nome do projeto, as regiões e as informações de zona. Observação: atualize a variável "regions", default = ["europe-west4", "us-east5"] com as regiões em que você tem cota de TPU. Para mais informações, consulte o documento Validar a disponibilidade da TPU no GKE.
O network.tf adiciona uma nova VPC ao seu projeto com sub-redes em duas zonas diferentes, sub-redes somente proxy e regras de firewall.
O provider.tf adiciona o provedor relevante para oferecer suporte ao Terraform
O fuse.tf adiciona o bucket do Cloud Storage para armazenar em cache as ponderações do modelo e provisiona uma conta de serviço do IAM com permissões de objectAdmin. Ela vincula essa conta à Identidade da carga de trabalho do GKE.
- Verifique se você está no diretório gke-tf e execute os seguintes comandos
terraform init -: inicializa o diretório de trabalho. Essa etapa faz o download dos provedores necessários para a configuração especificada.terraform plan -Gera um plano de execução, mostrando quais ações o Terraform vai realizar para implantar sua infraestrutura. Oterraform apply –auto-approveexecuta as atualizações e aprova automaticamente.
terraform init
terraform plan
- Agora execute a implantação (isso pode levar de 3 a 5 minutos)
terraform apply -auto-approve
- Na mesma pasta
gke-tf, crie o seguinte arquivo gke.tf.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
O gke.tf adiciona dois clusters em regiões diferentes, cria dois pools de nós de TPU que executam a TPU v6e com quatro chips e atribui o DRANET gerenciado aos pools de nós.
- Agora execute a implantação (isso pode levar de 10 a 15 minutos)
terraform apply -auto-approve
- Verificar
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Registro de frota
Precisamos registrar o cluster em uma frota.
- Verifique se você está no diretório
gke-tfe execute os seguintes comandos.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
O arquivo fleet.tf registra os dois clusters em uma frota global do GKE e ativa a descoberta de serviços e a entrada de vários clusters. Ele designa o cluster dos EUA como o cluster de configuração central, permitindo que a API Gateway monitore e roteie o tráfego.
- Na pasta
gke-tf, execute (isso leva de 3 a 5 minutos)
terraform plan
terraform apply -auto-approve
- Validar o registro da frota
gcloud container fleet memberships list --project=$PROJECT_ID
5. Fazer cache dos pesos do modelo para FUSE
Vamos executar um job temporário do Kubernetes no cluster dos EUA para fazer o download seguro do modelo Gemma usando um script Python diretamente no bucket do Cloud Storage montado com FUSE.
- Crie as variáveis a seguir
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- Isso usa o modelo google/gemma-3-27b-it. Portanto, é necessário criar um token do HF. Substitua
YOUR_ACTUAL_HUGGING_FACE_TOKENabaixo pelo seu token real.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Verifique se você está no diretório
gke-tfe execute os seguintes comandos.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Aguarde a conclusão do download antes de continuar (isso deve levar de 5 a 10 minutos, dependendo do tamanho do modelo).
kubectl logs -f job/model-downloader --context=$CTX_US
Pressione Ctrl+C para sair dos registros quando aparecer a mensagem "Download concluído".
6. Implantar vLLM e Gemma de carga de trabalho
- Verifique se você está no diretório
gke-tfe execute os seguintes comandos.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Agora, execute o script a seguir (isso vai levar de 5 a 10 minutos para ser concluído, já que é implantado em duas regiões):
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Confirmar implantação
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- Depois de concluir, execute o comando a seguir para validar se a rede DRANET gerenciada foi atribuída aos pods.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Você vai encontrar outras interfaces de rede eth0 para a rede de pods padrão, além de interfaces secundárias que representam a estrutura de TPU dedicada eth1, eth2 etc.
7. API de inferência e configuração do gateway
Agora você vai criar o InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) e o Inference Pool(gemma-pool). O pool de inferência é criado usando um gráfico do Helm. O comando instala e valida a criação.
- Verifique se você está no diretório
gke-tfe execute os seguintes comandos. Isso vai implantar o objeto e executar uma validação.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Configuração do gateway
Agora você vai criar a configuração do gateway cross-regional. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. O pool de inferência é criado usando um gráfico do Helm. O comando instala e valida a criação. Isso leva de 8 a 10 minutos para o gateway ficar ativo.
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Pool de inferência (Helm): agrupa os servidores de modelos das duas regiões em um único back-end lógico.
Gateway e HTTPRoute: cria o balanceador de carga interno global real e define as regras para rotear comandos de IA recebidos para seus modelos.
Políticas de verificação de integridade e back-end: garante que as solicitações sejam enviadas apenas para pods íntegros e permite a distribuição inteligente de tráfego com base em métricas, evitando sobrecarga nas TPUs.
Validação: o script é pausado para garantir que o Google Cloud tenha provisionado totalmente os endereços IP internos antes de você continuar.
9. Teste de failover
Agora, a melhor parte do laboratório: testar a alta disponibilidade da sua arquitetura.
Veja exatamente o que esse teste automatizado vai fazer:
- Teste de comparativo:nosso usuário simulado envia um comando de inferência ("Qual é a capital da França?"). Como o usuário está localizado na região principal, o gateway encaminha a solicitação para essas TPUs locais para a menor latência possível.
- O desastre:simulamos uma interrupção catastrófica do data center ao encerrar todos os pods de TPU na região principal (
replicas=0). - A detecção:aguardamos 45 segundos. Durante essa janela, as verificações de integridade do gateway falham, ele percebe que o back-end principal está completamente off-line e atualiza dinamicamente as tabelas de roteamento globais.
- O failover:o usuário envia um segundo comando ("Qual é a capital da Alemanha?"). O usuário não tem ideia de que há uma interrupção do serviço. O gateway intercepta a solicitação e a redireciona instantaneamente pelo mundo para as TPUs secundárias íntegras.
- A recuperação:restauramos as TPUs principais, trazendo sua arquitetura global de volta à integridade total.
- Abra o Cloud Shell e execute o seguinte:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- Depois que o teste for concluído, você poderá liberar espaço.
10. Limpar
- Liberar memória da carga de trabalho
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Libere espaço na infraestrutura. Verifique se você está na pasta
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Se você tiver problemas para excluir os recursos específicos, execute novamente o script de comando terraform destroy ./cleanup-tf.sh
11. Parabéns
Parabéns! Você implantou com sucesso um gateway de inferência do GKE altamente disponível e de vários clusters, uma arquitetura de inferência de IA entre regiões usando o GKE e aceleradores gerenciados do DRANET e da TPU v6e.
Ao combinar o Cloud Storage FUSE para carregamento instantâneo de modelos e a API Inference Gateway para roteamento multicluster com reconhecimento de latência, você criou um back-end resiliente capaz de sobreviver a uma interrupção completa do data center regional sem perder o tráfego interno de usuários.
Próximas etapas / Saiba mais
Leia mais sobre a rede do GKE.
Comece o próximo laboratório
Continue sua Quest com o Google Cloud e confira estes outros laboratórios do Google Cloud: