
1. Обзор
В этой лабораторной работе вы познакомитесь с инфраструктурой искусственного интеллекта, которую можно использовать для запуска рабочих нагрузок ИИ. Вы будете работать со следующим:
Google Kubernetes Engine (GKE) — базовая платформа для оркестрации контейнеров.
DRANET, управляемый GKE, — это технология динамического распределения ресурсов в сети, которая напрямую назначает высокоскоростные межсоединительные сети вашим модулям TPU.
GKE Inference Gateway — это управляемый объект шлюза от Google Cloud, адаптированный для выполнения инференции. В данном случае мы будем использовать возможности работы с несколькими кластерами .
Tensor Processing Unit (TPU) — это разработанные компанией Google чипы-ускорители.
Cloud Storage FUSE — это интерфейс хранения данных, позволяющий модулям напрямую монтировать хранилища Cloud Storage, обеспечивая мгновенную загрузку больших объемов данных о весовых коэффициентах моделей.
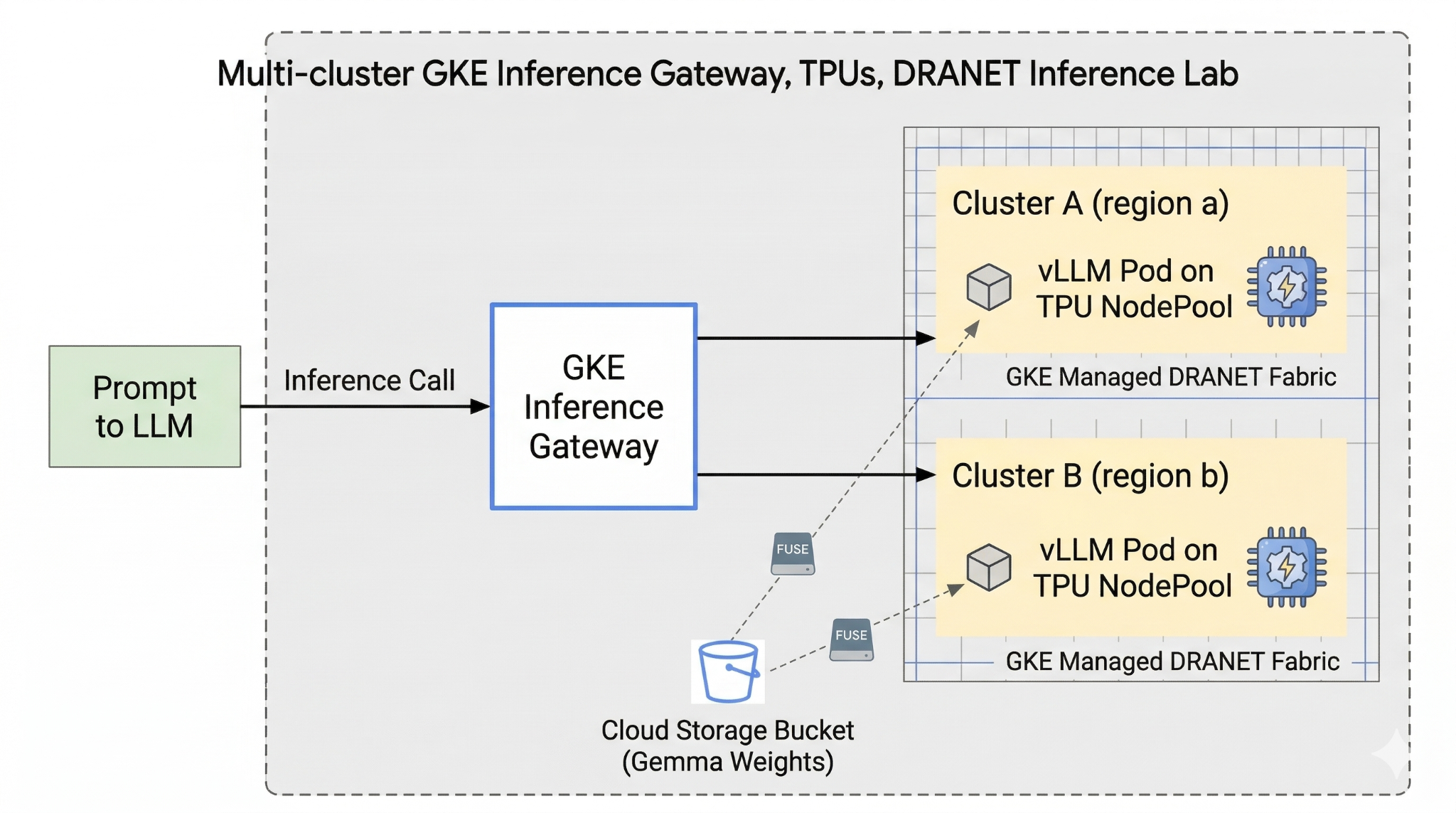
Для настройки вам потребуется развернуть пользовательскую VPC, сегмент Cloud Storage и два кластера в разных регионах. Каждый кластер будет иметь пул узлов TPU, использующий управляемую сеть DRANET. После добавления кластеров в Fleet вы кэшируете веса модели Gemma в своем сегменте и развернете рабочую нагрузку vLLM, которая мгновенно монтирует эти веса через Cloud Storage FUSE. Наконец, шлюз GKE Inference Gateway будет настроен для маршрутизации трафика, что позволит вам выполнить тест на отказоустойчивость в реальном времени между регионами.
Для настройки будут использоваться комбинация Terraform , gcloud и kubectl .
В этой лабораторной работе вы научитесь выполнять следующее задание:
- Настройка VPC, сетей и хранилища.
- Настройка кластера GKE в стандартном режиме
- Создайте пул узлов TPU и используйте управляемую сеть DRANET.
- Добавить кластер в автопарк
- Веса модели кэша
- Настройка многокластерного шлюза GKE Inference и тестирование отказоустойчивости.
В этой лабораторной работе вы создадите следующий узор.
Рисунок 1.
2. Настройка сервисов Google Cloud
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Настройка среды с помощью Terraform
Для выполнения этой лабораторной работы вам потребуется доступ к TPU. Используется точная версия TPU v6e.
- Для получения доступа вам следует следовать инструкциям в документе, описывающем тарифный план TPU, и включить квоту TPU .
- Мы используем небольшую систему, требующую 4 чипов TPU v6e (
ct6e-standard-4t), которые будут представлять собой срез 2x2 в двух разных регионах. - Токен "Обнимающее лицо": Для загрузки весов модели Джеммы необходим токен доступа .
Мы создадим пользовательскую VPC с правилами брандмауэра, хранилищем и подсетью. Откройте консоль облака и выберите проект, который вы будете использовать.
- Откройте Cloud Shell, расположенный в верхней части консоли справа, убедитесь, что в Cloud Shell отображается правильный идентификатор проекта , и подтвердите все запросы на предоставление доступа.

- Создайте папку с именем
gke-tfи перейдите в эту папку.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Теперь добавьте несколько конфигурационных файлов. В результате будут созданы следующие файлы: network.tf , variable.tf , providers.tf , fuse.tf.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
Файл variable.tf добавляет название проекта, информацию о регионах и зонах. ps Обновите переменную "regions", default = ["europe-west4", "us-east5"] с указанием регионов, в которых у вас есть квота TPU. Для получения дополнительной информации ознакомьтесь с этим документом " Проверка доступности TPU в GKE ".
Файл network.tf добавляет в ваш проект новую VPC с подсетями в двух разных зонах, подсетями только для прокси-сервера и правилами брандмауэра.
Файл provider.tf добавляет соответствующий провайдер для поддержки Terraform.
Файл fuse.tf добавляет сегмент Cloud Storage для кэширования весов модели и создает учетную запись службы IAM с правами objectAdmin. Он привязывает эту учетную запись к GKE Workload Identity.
- Убедитесь, что вы находитесь в каталоге gke-tf , и выполните следующие команды.
terraform init -Инициализирует рабочий каталог. На этом шаге загружаются провайдеры, необходимые для данной конфигурации.terraform plan -Генерирует план выполнения, показывающий, какие действия Terraform предпримет для развертывания вашей инфраструктуры.terraform apply –auto-approveзапускает обновления и автоматически утверждает их.
terraform init
terraform plan
- Теперь запустите развертывание (это может занять от 3 до 5 минут).
terraform apply -auto-approve
- В той же папке
gke-tfсоздайте следующий файл gke.tf.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
Файл gke.tf добавляет два кластера в разных регионах и создает два пула узлов TPU, работающих под управлением TPU v6e с 4 чипами, а также назначает управляемую сеть DRANET этим пулам узлов.
- Теперь запустите развертывание (это может занять от 10 до 15 минут).
terraform apply -auto-approve
- Проверять
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Регистрация автопарка
Нам необходимо зарегистрировать кластер в Fleet.
- Убедитесь, что вы находитесь в каталоге
gke-tf, и выполните следующие команды.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
Файл fleet.tf регистрирует оба кластера в глобальном парке GKE и включает обнаружение и входящий трафик для нескольких кластеров. Он назначает кластер США центральным кластером конфигурации, что позволяет API шлюза отслеживать и маршрутизировать трафик.
- Перейдите в папку
gke-tfи запустите (это займет 3-5 минут).
terraform plan
terraform apply -auto-approve
- Подтвердите регистрацию автопарка.
gcloud container fleet memberships list --project=$PROJECT_ID
5. Кэшируйте веса модели в FUSE.
Мы запустим временное задание Kubernetes в кластере США, чтобы безопасно загрузить модель Gemma с помощью скрипта Python непосредственно в хранилище Cloud Storage, подключенное через FUSE.
- Создайте следующие переменные
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- Здесь используется модель google/gemma-3-27b-it , поэтому вам потребуется создать токен HF . Замените
YOUR_ACTUAL_HUGGING_FACE_TOKENниже на ваш реальный токен.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- Убедитесь, что вы находитесь в каталоге
gke-tf, и выполните следующие команды.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Дождитесь завершения загрузки, прежде чем продолжить (это займет 5-10 минут в зависимости от размера модели).
kubectl logs -f job/model-downloader --context=$CTX_US
(Нажмите Ctrl+C , чтобы выйти из журнала после появления сообщения «Загрузка завершена!»)
6. Развертывание рабочей нагрузки vLLM и Gemma.
- Убедитесь, что вы находитесь в каталоге
gke-tf, и выполните следующие команды.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Теперь выполните следующий скрипт (это займет от 5 до 10 минут, так как развертывание будет происходить в двух регионах).
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Подтвердите развертывание
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- После завершения вы можете убедиться, что управляемая сеть DRANET была назначена подам, выполнив команду.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Вы увидите дополнительные сетевые интерфейсы eth0 для стандартной работы сети внутри подов, а также вторичные интерфейсы, представляющие вашу выделенную сеть TPU eth1, eth2 и т. д.
7. Настройка API для вывода результатов и шлюза.
Теперь вам нужно создать InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) и Inference Pool(gemma-pool) . Пул вывода создается с помощью Helm-диаграммы. Затем выполняется установка и проверка созданных объектов.
- Убедитесь, что вы находитесь в каталоге
gke-tf, и выполните следующие команды. Это развернет объект и выполнит проверку.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Настройка шлюза
Теперь вам нужно создать конфигурацию межрегионального шлюза. В ней будут указаны Gateway(cross-region-gateway), HTTPRoute (gemma-route) , HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. Пул Inference создается с помощью Helm-диаграммы. Затем выполняется установка и проверка созданных параметров. (Для активации шлюза потребуется 8-10 минут).
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Пул вывода (Helm) : Объединяет серверы моделей из обоих регионов в единый логический бэкэнд.
Gateway & HTTPRoute : Создает фактический глобальный внутренний балансировщик нагрузки и определяет правила маршрутизации входящих запросов ИИ к вашим моделям.
Проверка работоспособности и политики бэкэнда : гарантируют, что запросы отправляются только работоспособным подам, и обеспечивают интеллектуальное распределение трафика на основе метрик (предотвращая перегрузку TPU).
Проверка : Скрипт приостанавливается, чтобы убедиться, что Google Cloud полностью выделил внутренние IP-адреса, прежде чем вы продолжите.
9. Тест на отказоустойчивость
А теперь самое интересное в лаборатории: проверка высокой доступности вашей архитектуры.
Вот что именно сделает этот автоматизированный тест:
- Базовый тест: наш имитируемый пользователь отправляет запрос на определение местоположения («Какова столица Франции?»). Поскольку пользователь находится в основном регионе, шлюз направляет запрос к этим локальным TPU для обеспечения минимально возможной задержки.
- Катастрофа: Мы имитируем катастрофический сбой в работе центра обработки данных, отключая все модули TPU в основном регионе (
replicas=0). - Обнаружение: Мы ждем 45 секунд. В течение этого времени проверки работоспособности шлюза завершаются неудачей, он понимает, что основной бэкэнд полностью отключен, и динамически обновляет свои глобальные таблицы маршрутизации.
- Переключение на резервный сервер: наш пользователь отправляет второй запрос («Какова столица Германии?»). Пользователь не знает о сбое. Шлюз перехватывает запрос и мгновенно перенаправляет его по всему миру на ваши исправные резервные TPU.
- Восстановление: Мы восстанавливаем основные TPU, возвращая вашу глобальную архитектуру в полностью работоспособное состояние.
- Откройте Cloud Shell и выполните следующие действия:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- После завершения теста можно приступать к уборке.
10. Уборка
- Упорядочьте рабочую нагрузку
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Приведите инфраструктуру в порядок. Убедитесь, что вы находитесь в папке
gke-tf.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Если у вас возникнут проблемы с удалением определенных ресурсов, следует повторно запустить скрипт команды terraform destroy ./cleanup-tf.sh
11. Поздравляем!
Поздравляем! Вы успешно развернули высокодоступную многокластерную архитектуру GKE Inference Gateway для межрегионального вывода данных в области ИИ, используя GKE, управляемую сеть DRANET и ускорители TPU v6e.
Сочетание Cloud Storage FUSE для мгновенной загрузки моделей и API Inference Gateway для маршрутизации между кластерами с учетом задержек позволяет создать отказоустойчивую серверную часть, способную пережить полный сбой в работе регионального центра обработки данных без потери внутреннего пользовательского трафика.
Следующие шаги / Узнать больше
Вы можете узнать больше о сети GKE.
Пройдите следующую лабораторную работу.
Продолжите свое знакомство с Google Cloud и ознакомьтесь с другими лабораториями Google Cloud: