
1. ภาพรวม
แล็บนี้จะแนะนำให้คุณรู้จักโครงสร้างพื้นฐาน AI ที่ใช้เรียกใช้งานภาระงาน AI ได้ คุณจะต้องทำงานร่วมกับสิ่งต่อไปนี้
Google Kubernetes Engine (GKE) - แพลตฟอร์มการจัดการคอนเทนเนอร์เป็นกลุ่มพื้นฐาน
DRANET ที่มีการจัดการของ GKE - การเชื่อมต่อเครือข่ายการจัดสรรทรัพยากรแบบไดนามิกที่กำหนดโครงสร้างการเชื่อมต่อความเร็วสูงให้กับพ็อด TPU โดยตรง
GKE Inference Gateway - นี่คือออบเจ็กต์เกตเวย์ที่มีการจัดการจาก Google Cloud ซึ่งปรับให้เหมาะกับการอนุมาน ในกรณีนี้ เราจะใช้ความสามารถแบบหลายคลัสเตอร์
Tensor Processing Unit (TPU) - ชิปเร่งความเร็วที่ Google สร้างขึ้นเอง
Cloud Storage FUSE - อินเทอร์เฟซการจัดเก็บที่ช่วยให้พ็อดต่อเชื่อม Bucket ของ Cloud Storage ได้โดยตรง ซึ่งจะช่วยให้โหลดน้ำหนักของโมเดลขนาดใหญ่ได้ทันที
หากต้องการกำหนดค่า คุณจะต้องทำให้ใช้งานได้ VPC ที่กำหนดเอง, Bucket ของ Cloud Storage และคลัสเตอร์ 2 รายการในภูมิภาคต่างๆ แต่ละคลัสเตอร์จะมี Node Pool ของ TPU ที่ใช้ DRANET ที่มีการจัดการสำหรับการเชื่อมต่อเครือข่าย หลังจากเพิ่มคลัสเตอร์ลงใน Fleet แล้ว คุณจะแคชน้ำหนักของโมเดล Gemma ใน Bucket และทำให้ใช้งานได้ภาระงาน vLLM ที่ต่อเชื่อมน้ำหนักเหล่านั้นทันทีผ่าน Cloud Storage FUSE สุดท้ายนี้ ระบบจะกำหนดค่า GKE Inference Gateway เพื่อกำหนดเส้นทางการรับส่งข้อมูล ซึ่งจะช่วยให้คุณทำการทดสอบการทำงานล้มเหลวข้ามภูมิภาคแบบสดได้
การกำหนดค่าจะใช้ร่วมกันระหว่าง Terraform, gcloud และ kubectl
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- ตั้งค่า VPC, เครือข่าย, พื้นที่เก็บข้อมูล
- ตั้งค่าคลัสเตอร์ GKE ในโหมดมาตรฐาน
- สร้าง Node Pool ของ TPU และใช้ DRANET ที่มีการจัดการ
- เพิ่มคลัสเตอร์ไปยังฟลีท
- น้ำหนักของโมเดลแคช
- ตั้งค่าเกตเวย์การอนุมาน GKE แบบหลายคลัสเตอร์และทดสอบการทำงานเมื่อเกิดข้อผิดพลาด
ในแล็บนี้ คุณจะได้สร้างรูปแบบต่อไปนี้
รูปที่ 1
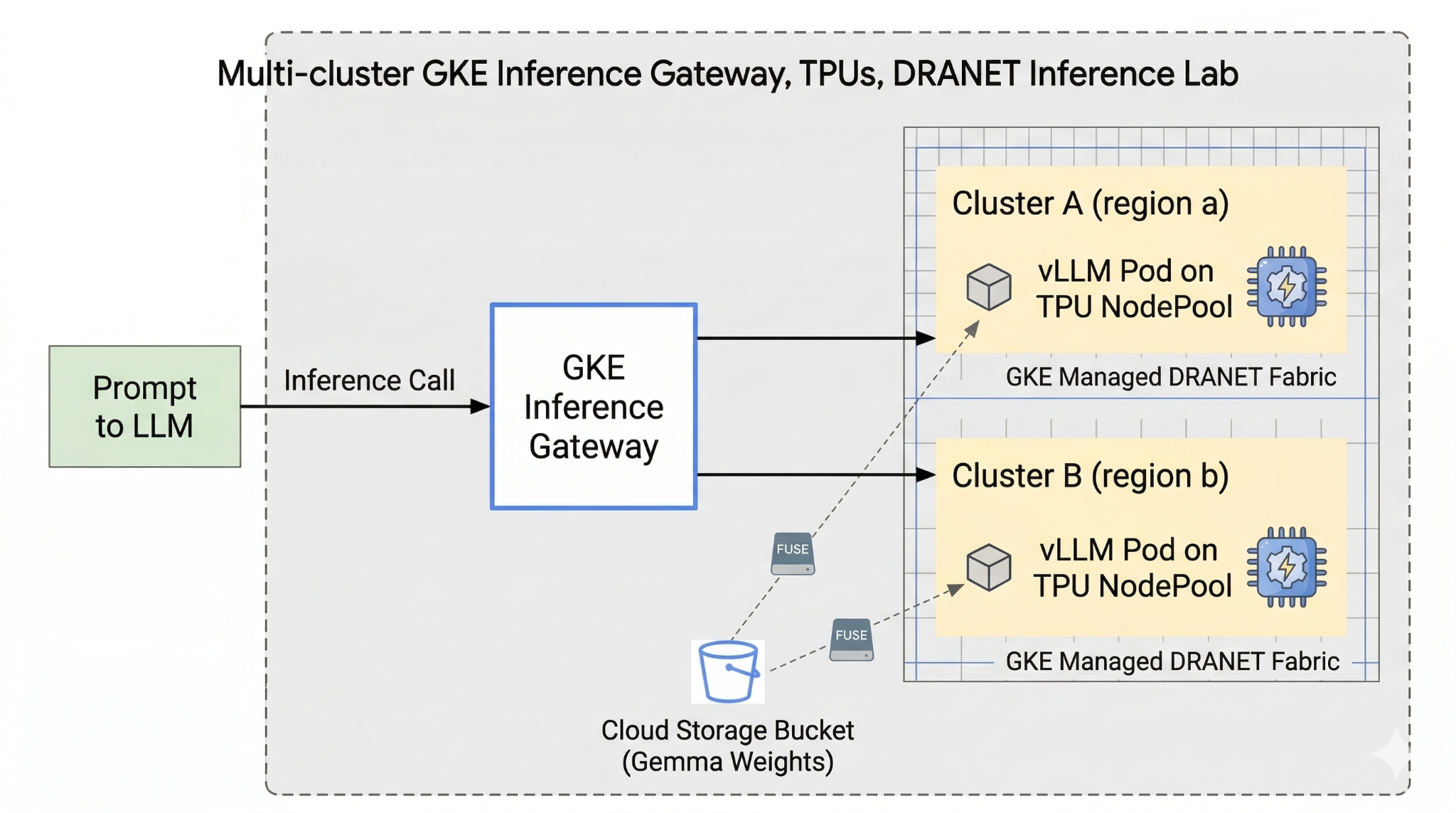
2. การตั้งค่าบริการ Google Cloud
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
- ลงชื่อเข้าใช้ Google Cloud Console แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี

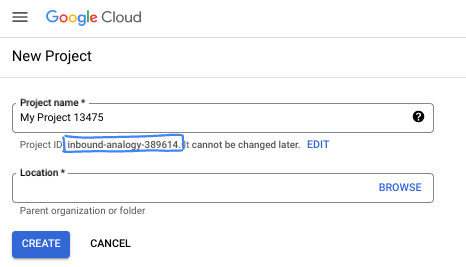
- ชื่อโปรเจ็กต์คือชื่อที่แสดงสำหรับผู้เข้าร่วมโปรเจ็กต์นี้ ซึ่งเป็นสตริงอักขระที่ Google APIs ไม่ได้ใช้ คุณอัปเดตได้ทุกเมื่อ
- รหัสโปรเจ็กต์จะไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมดและเปลี่ยนแปลงไม่ได้ (เปลี่ยนไม่ได้หลังจากตั้งค่าแล้ว) Cloud Console จะสร้างสตริงที่ไม่ซ้ำกันโดยอัตโนมัติ ซึ่งโดยปกติแล้วคุณไม่จำเป็นต้องสนใจว่าสตริงนั้นคืออะไร ใน Codelab ส่วนใหญ่ คุณจะต้องอ้างอิงรหัสโปรเจ็กต์ (โดยทั่วไปจะระบุเป็น
PROJECT_ID) หากไม่ชอบรหัสที่สร้างขึ้น คุณอาจสร้างรหัสแบบสุ่มอีกรหัสหนึ่งได้ หรือคุณอาจลองใช้ชื่อของคุณเองและดูว่ามีชื่อนั้นหรือไม่ คุณจะเปลี่ยนแปลงรหัสนี้หลังจากขั้นตอนนี้ไม่ได้ และรหัสจะคงอยู่ตลอดระยะเวลาของโปรเจ็กต์ - โปรดทราบว่ายังมีค่าที่ 3 ซึ่งคือหมายเลขโปรเจ็กต์ที่ API บางตัวใช้ ดูข้อมูลเพิ่มเติมเกี่ยวกับค่าทั้ง 3 นี้ได้ในเอกสารประกอบ
- จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร/API ของ Cloud การทำตาม Codelab นี้จะไม่มีค่าใช้จ่ายมากนัก หรืออาจไม่มีค่าใช้จ่ายเลย หากต้องการปิดทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ คุณสามารถลบทรัพยากรที่สร้างขึ้นหรือลบโปรเจ็กต์ได้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก Google Cloud Console ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
3. ตั้งค่าสภาพแวดล้อมด้วย Terraform
คุณต้องมีสิทธิ์เข้าถึง TPU เพื่อทำแล็บนี้ เวอร์ชันที่ใช้คือ TPU v6e
- คุณควรทำตามเอกสารแผน TPU และเปิดใช้โควต้า TPU เพื่อรับสิทธิ์เข้าถึง
- เราใช้การติดตั้งใช้งานขนาดเล็กที่ต้องใช้ชิป TPU v6e 4 ตัว (
ct6e-standard-4t)ซึ่งจะเป็นสไลซ์ 2x2 ใน 2 ภูมิภาคที่แตกต่างกัน - โทเค็น Hugging Face: ต้องใช้โทเค็นเพื่อการเข้าถึงเพื่อดาวน์โหลดน้ำหนักของโมเดล Gemma
เราจะสร้าง VPC ที่กำหนดเองพร้อมกฎไฟร์วอลล์ พื้นที่เก็บข้อมูล และซับเน็ต เปิด Cloud Console แล้วเลือกโปรเจ็กต์ที่จะใช้
- เปิด Cloud Shell ที่ด้านบนของคอนโซลทางด้านขวา ตรวจสอบว่าคุณเห็นรหัสโปรเจ็กต์ที่ถูกต้องใน Cloud Shell และยืนยันข้อความแจ้งเพื่ออนุญาตการเข้าถึง

- สร้างโฟลเดอร์ชื่อ
gke-tfแล้วย้ายไปที่โฟลเดอร์
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- ตอนนี้ให้เพิ่มไฟล์การกำหนดค่า ซึ่งจะสร้างไฟล์ network.tf , variable.tf, providers.tf, fuse.tf
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
variable.tf ไฟล์จะเพิ่มชื่อโปรเจ็กต์ ภูมิภาค และข้อมูลโซน ป.ล. อัปเดตตัวแปร "regions" default = ["europe-west4", "us-east5"] ด้วยภูมิภาคที่คุณมีโควต้า TPU ดูข้อมูลเพิ่มเติมได้ที่เอกสาร "ตรวจสอบความพร้อมใช้งานของ TPU ใน GKE"
network.tf จะเพิ่ม VPC ใหม่ในโปรเจ็กต์ของคุณพร้อมซับเน็ตใน 2 โซนที่แตกต่างกัน ซับเน็ตเฉพาะพร็อกซี และกฎไฟร์วอลล์
provider.tf เพิ่มผู้ให้บริการที่เกี่ยวข้องเพื่อรองรับ Terraform
fuse.tf จะเพิ่ม Bucket ของ Cloud Storage เพื่อแคชน้ำหนักของโมเดลและจัดสรรบัญชีบริการ IAM ที่มีสิทธิ์ objectAdmin ซึ่งจะเชื่อมโยงบัญชีนี้กับ Workload Identity ของ GKE
- ตรวจสอบว่าคุณอยู่ในไดเรกทอรี gke-tf แล้วเรียกใช้คำสั่งต่อไปนี้
terraform init -เริ่มต้นไดเรกทอรีการทำงาน ขั้นตอนนี้จะดาวน์โหลดผู้ให้บริการที่จำเป็นสำหรับการกำหนดค่าที่ระบุterraform plan -สร้างแผนการดำเนินการ ซึ่งแสดงการดำเนินการที่ Terraform จะใช้เพื่อทำให้โครงสร้างพื้นฐานใช้งานได้terraform apply –auto-approveจะเรียกใช้การอัปเดตและอนุมัติโดยอัตโนมัติ
terraform init
terraform plan
- ตอนนี้ให้เรียกใช้การติดตั้งใช้งาน (การดำเนินการนี้อาจใช้เวลา 3-5 นาที)
terraform apply -auto-approve
- สร้างไฟล์ gke.tf ต่อไปนี้ใน
gke-tfโฟลเดอร์เดียวกัน
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
gke.tf เพิ่มคลัสเตอร์ 2 รายการในภูมิภาคต่างๆ และสร้าง TPU Nodepool 2 รายการที่เรียกใช้ TPU v6e ที่มีชิป 4 ตัว และกำหนด DRANET ที่มีการจัดการให้กับ Node Pool
- ตอนนี้ให้เรียกใช้การติดตั้งใช้งาน (การดำเนินการนี้อาจใช้เวลา 10-15 นาที)
terraform apply -auto-approve
- ยืนยัน
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. การจดทะเบียนกลุ่ม
เราต้องลงทะเบียนคลัสเตอร์กับฟลีต
- ตรวจสอบว่าคุณอยู่ในไดเรกทอรี
gke-tfแล้วเรียกใช้คำสั่งต่อไปนี้
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
fleet.tf ไฟล์จะลงทะเบียนทั้ง 2 คลัสเตอร์กับ GKE Fleet ทั่วโลก และเปิดใช้ Service Discovery และ Ingress แบบหลายคลัสเตอร์ โดยจะกำหนดให้คลัสเตอร์ในสหรัฐอเมริกาเป็นคลัสเตอร์การกำหนดค่าส่วนกลาง ซึ่งจะช่วยให้ Gateway API ตรวจสอบและกำหนดเส้นทางการรับส่งข้อมูลได้
- ในโฟลเดอร์
gke-tfแล้วเรียกใช้ (การดำเนินการนี้อาจใช้เวลา 3-5 นาที)
terraform plan
terraform apply -auto-approve
- ตรวจสอบการจดทะเบียนกองยานพาหนะ
gcloud container fleet memberships list --project=$PROJECT_ID
5. แคชน้ำหนักโมเดลไปยัง FUSE
เราจะเรียกใช้ Kubernetes Job ชั่วคราวในคลัสเตอร์ของสหรัฐอเมริกาเพื่อดาวน์โหลดโมเดล Gemma อย่างปลอดภัยผ่านสคริปต์ Python ลงในที่เก็บข้อมูล Cloud Storage ที่ติดตั้ง FUSE โดยตรง
- สร้างตัวแปรต่อไปนี้
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- โดยจะใช้โมเดล google/gemma-3-27b-it ดังนั้นคุณจะต้องสร้างโทเค็น HF แทนที่
YOUR_ACTUAL_HUGGING_FACE_TOKENด้านล่างด้วยโทเค็นจริง
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
- ตรวจสอบว่าคุณอยู่ในไดเรกทอรี
gke-tfแล้วเรียกใช้คำสั่งต่อไปนี้
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- รอให้การดาวน์โหลดเสร็จสิ้นก่อนดำเนินการต่อ (ขั้นตอนนี้ควรใช้เวลา 5-10 นาที ขึ้นอยู่กับขนาดโมเดล)
kubectl logs -f job/model-downloader --context=$CTX_US
(กด Ctrl+C เพื่อออกจากบันทึกเมื่อระบบแจ้งว่า "ดาวน์โหลดเสร็จสมบูรณ์")
6. ทำให้ภาระงาน vLLM และ Gemma ใช้งานได้
- ตรวจสอบว่าคุณอยู่ในไดเรกทอรี
gke-tfแล้วเรียกใช้คำสั่งต่อไปนี้
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- ตอนนี้ให้เรียกใช้สคริปต์ต่อไปนี้ (การดำเนินการนี้จะใช้เวลา 5-10 นาทีเนื่องจากมีการติดตั้งใช้งานใน 2 ภูมิภาค)
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- ยืนยันการติดตั้งใช้งาน
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- เมื่อดำเนินการเสร็จแล้ว คุณสามารถตรวจสอบว่าระบบได้กำหนดการเชื่อมต่อเครือข่าย DRANET ที่มีการจัดการให้กับพ็อดแล้วโดยการเรียกใช้
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
คุณจะเห็นอินเทอร์เฟซเครือข่ายเพิ่มเติม eth0 สำหรับการเชื่อมต่อเครือข่ายพ็อดมาตรฐาน พร้อมกับอินเทอร์เฟซรองที่แสดงถึง Fabric ของ TPU เฉพาะ eth1, eth2 ฯลฯ
7. การกำหนดค่า Inference API และเกตเวย์
ตอนนี้คุณจะสร้าง InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) และ Inference Pool(gemma-pool) โดย Inference Pool จะสร้างขึ้นโดยใช้แผนภูมิ Helm การติดตั้งและตรวจสอบการสร้าง
- ตรวจสอบว่าคุณอยู่ในไดเรกทอรี
gke-tfแล้วเรียกใช้คำสั่งต่อไปนี้ ซึ่งจะทำให้ระบบทำให้ใช้งานได้ออบเจ็กต์และเรียกใช้การตรวจสอบ
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. การกำหนดค่าเกตเวย์
ตอนนี้คุณจะสร้างการกำหนดค่าเกตเวย์ข้ามภูมิภาค Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. พูลการอนุมานสร้างขึ้นโดยใช้แผนภูมิ Helm การติดตั้งและตรวจสอบการสร้าง (ระบบจะใช้เวลา 8-10 นาทีเพื่อให้เกตเวย์ทำงาน)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
พูลการอนุมาน (Helm): จัดกลุ่มเซิร์ฟเวอร์โมเดลจากทั้ง 2 ภูมิภาคเป็นแบ็กเอนด์เชิงตรรกะเดียว
Gateway และ HTTPRoute: สร้างตัวจัดสรรภาระงานภายในส่วนกลางจริงและกำหนดกฎสำหรับการกำหนดเส้นทางพรอมต์ AI ขาเข้าไปยังโมเดล
นโยบายการตรวจสอบสถานะและแบ็กเอนด์: ตรวจสอบว่าได้ส่งคำขอไปยังพ็อดที่ทำงานอยู่เท่านั้น และเปิดใช้การกระจายการเข้าชมอัจฉริยะตามเมตริก (ป้องกันไม่ให้ TPU ทำงานหนักเกินไป)
การตรวจสอบความถูกต้อง: สคริปต์จะหยุดชั่วคราวเพื่อให้แน่ใจว่า Google Cloud จัดสรรที่อยู่ IP ภายในอย่างเต็มรูปแบบก่อนที่คุณจะดำเนินการต่อ
9. การทดสอบเฟลโอเวอร์
มาถึงส่วนที่ดีที่สุดของแล็บแล้ว นั่นคือการทดสอบความพร้อมใช้งานสูงของสถาปัตยกรรม
การทดสอบอัตโนมัตินี้จะทำสิ่งต่อไปนี้
- การทดสอบพื้นฐาน: ผู้ใช้จำลองของเราจะส่งพรอมต์การอนุมาน ("เมืองหลวงของฝรั่งเศสคืออะไร") เนื่องจากผู้ใช้อยู่ในภูมิภาคหลัก เกตเวย์จึงกำหนดเส้นทางการส่งคำขอไปยัง TPU ในพื้นที่เหล่านั้นเพื่อให้เกิดเวลาในการตอบสนองที่ต่ำที่สุด
- เหตุการณ์ภัยพิบัติ: เราจำลองการหยุดทำงานของศูนย์ข้อมูลที่ร้ายแรงโดยการปิดพ็อด TPU ทั้งหมดในภูมิภาคหลัก (
replicas=0) - การตรวจหา: เรารอ 45 วินาที ในระหว่างช่วงเวลานี้ การตรวจสอบสถานะของเกตเวย์จะล้มเหลว เกตเวย์จะทราบว่าแบ็กเอนด์หลักออฟไลน์โดยสมบูรณ์ และจะอัปเดตตารางการกำหนดเส้นทางส่วนกลางแบบไดนามิก
- เฟลโอเวอร์: ผู้ใช้ส่งพรอมต์ที่ 2 ("เมืองหลวงของเยอรมนีคืออะไร") ผู้ใช้ไม่ทราบว่าเกิดการหยุดทำงาน เกตเวย์จะสกัดกั้นคำขอและเปลี่ยนเส้นทางคำขอไปยัง TPU สำรองที่ทำงานได้ดีทั่วโลกในทันที
- การกู้คืน: เราจะกู้คืน TPU หลักเพื่อให้สถาปัตยกรรมทั่วโลกกลับมาทำงานได้อย่างเต็มประสิทธิภาพ
- เปิด Cloud Shell แล้วเรียกใช้คำสั่งต่อไปนี้
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- เมื่อการทดสอบเสร็จสมบูรณ์แล้ว คุณสามารถล้างข้อมูลได้
10. ล้างข้อมูล
- ล้างข้อมูลภาระงาน
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- ล้างข้อมูลโครงสร้างพื้นฐาน ตรวจสอบว่าคุณอยู่ในโฟลเดอร์
gke-tf
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
หากพบปัญหาในการลบทรัพยากรที่เฉพาะเจาะจง คุณควรเรียกใช้terraform destroyสคริปต์คำสั่ง./cleanup-tf.shอีกครั้ง
11. ขอแสดงความยินดี
ยินดีด้วย คุณได้ติดตั้งใช้งาน GKE Inference Gateway แบบหลายคลัสเตอร์ที่มีความพร้อมใช้งานสูง สถาปัตยกรรมการอนุมาน AI แบบข้ามภูมิภาคโดยใช้ GKE, DRANET ที่มีการจัดการ และตัวเร่ง TPU v6e เรียบร้อยแล้ว
การผสานรวม Cloud Storage FUSE เพื่อการโหลดโมเดลทันทีและ Inference Gateway API เพื่อการกำหนดเส้นทางแบบหลายคลัสเตอร์ที่คำนึงถึงเวลาในการตอบสนองจะช่วยให้คุณสร้างแบ็กเอนด์ที่ยืดหยุ่นซึ่งสามารถรับมือกับการหยุดทำงานของศูนย์ข้อมูลระดับภูมิภาคได้อย่างสมบูรณ์โดยไม่ทำให้การรับส่งข้อมูลของผู้ใช้ภายในลดลง
ขั้นตอนถัดไป / ดูข้อมูลเพิ่มเติม
อ่านข้อมูลเพิ่มเติมเกี่ยวกับเครือข่าย GKE
เข้าร่วมแล็บถัดไป
ทำภารกิจต่อด้วย Google Cloud และดูแล็บอื่นๆ ของ Google Cloud เหล่านี้