
1. Genel Bakış
Bu laboratuvarda, yapay zeka iş yüklerini çalıştırmak için kullanılabilecek yapay zeka altyapısı hakkında bilgi edineceksiniz. Aşağıdakilerle çalışacaksınız:
Google Kubernetes Engine (GKE): Temel kapsayıcı düzenleme platformu.
GKE tarafından yönetilen DRANET: Yüksek hızlı ara bağlantı yapılarını doğrudan TPU kapsüllerinize atayan dinamik kaynak ayırma ağı.
GKE Inference Gateway: Bu, Google Cloud'un Inference için uyarlanmış yönetilen bir Gateway nesnesidir. Bu durumda çoklu küme özelliklerini kullanacağız.
Tensor İşleme Birimi (TPU): Google'ın özel olarak tasarlanmış hızlandırıcı çipleri.
Cloud Storage FUSE: Pod'ların Cloud Storage paketlerini doğrudan bağlamasına olanak tanıyan bir depolama arayüzüdür. Bu sayede, büyük model ağırlıkları anında yüklenebilir.
Yapılandırmak için özel bir VPC, bir Cloud Storage paketi ve farklı bölgelerde iki küme dağıtmanız gerekir. Her kümenin, ağ oluşturma için yönetilen DRANET'i kullanan bir TPU düğüm havuzu olacaktır. Kümeleri bir filoya ekledikten sonra Gemma model ağırlıklarını paketinize önbelleğe alacak ve bu ağırlıkları Cloud Storage FUSE aracılığıyla anında bağlayan bir vLLM iş yükü dağıtacaksınız. Son olarak, GKE Inference Gateway trafiği yönlendirecek şekilde yapılandırılır. Bu sayede, bölgeler arası canlı bir yük devretme testi gerçekleştirebilirsiniz.
Yapılandırmalarda Terraform, gcloud ve kubectl kombinasyonu kullanılır.
Bu laboratuvarda, aşağıdaki görevi nasıl gerçekleştireceğinizi öğreneceksiniz:
- VPC, ağlar ve depolama alanını ayarlama
- GKE kümesini standart modda ayarlama
- TPU düğüm havuzu oluşturma ve yönetilen DRANET'i kullanma
- Filoya küme ekleme
- Önbellek modeli ağırlıkları
- Çok kümeli GKE çıkarım ağ geçidini ayarlama ve yük devretmeyi test etme
Bu laboratuvarda aşağıdaki kalıbı oluşturacaksınız.
Şekil 1.
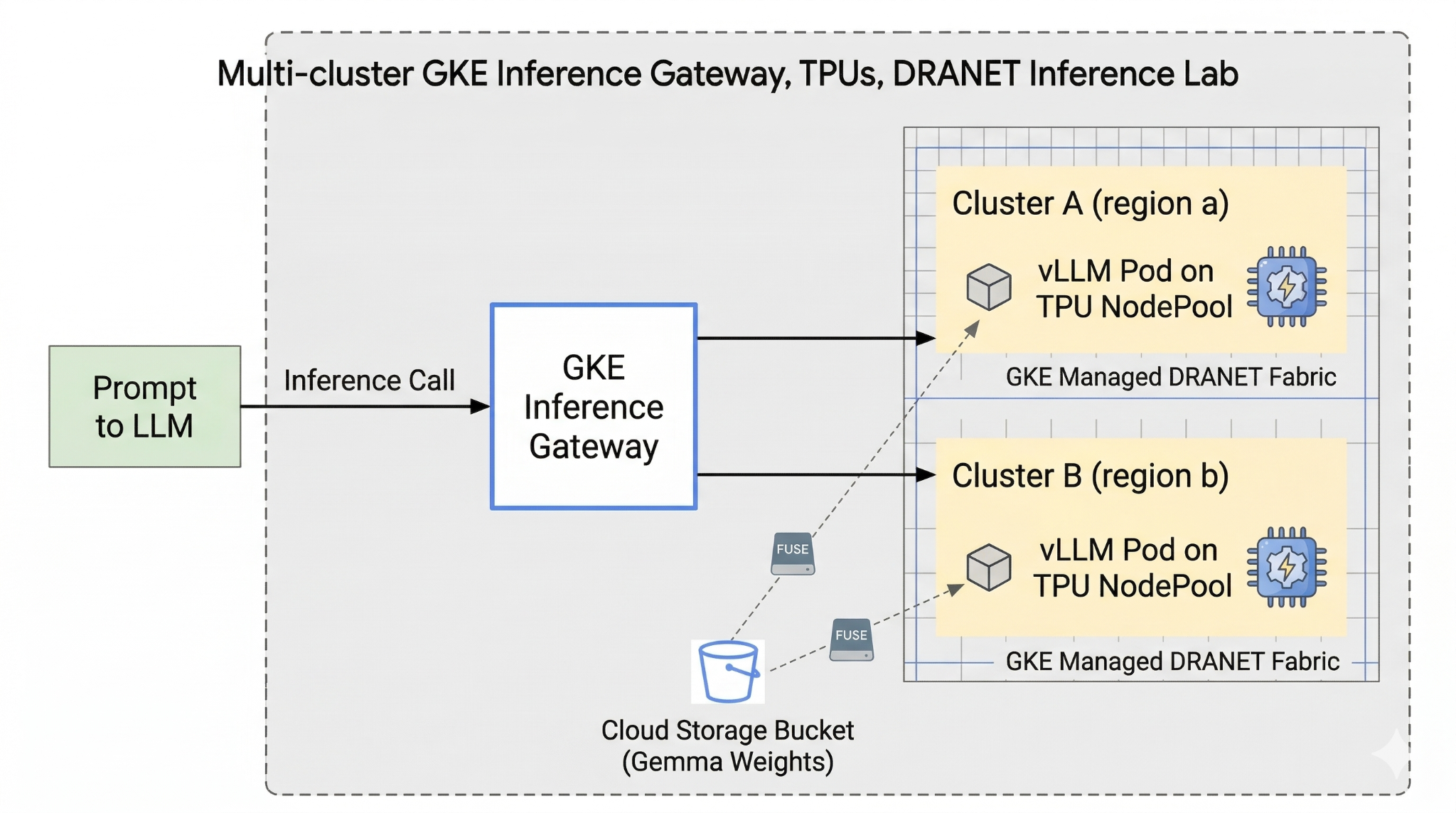
2. Google Cloud hizmetlerinin kurulumu
Yönlendirmesiz ortam kurulumu
- Google Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Gmail veya Google Workspace hesabınız yoksa hesap oluşturmanız gerekir.

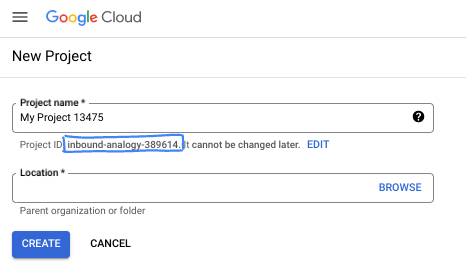
- Proje adı, bu projenin katılımcıları için görünen addır. Google API'leri tarafından kullanılmayan bir karakter dizesidir. Bu bilgiyi istediğiniz zaman güncelleyebilirsiniz.
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve sabittir (ayarlandıktan sonra değiştirilemez). Cloud Console, benzersiz bir dizeyi otomatik olarak oluşturur. Genellikle bu dizenin ne olduğuyla ilgilenmezsiniz. Çoğu codelab'de proje kimliğinize (genellikle
PROJECT_IDolarak tanımlanır) başvurmanız gerekir. Oluşturulan kimliği beğenmezseniz başka bir rastgele kimlik oluşturabilirsiniz. Dilerseniz kendi adınızı deneyerek kullanılabilir olup olmadığını kontrol edebilirsiniz. Bu adım tamamlandıktan sonra değiştirilemez ve proje süresince geçerli kalır. - Bazı API'lerin kullandığı üçüncü bir değer olan Proje Numarası da vardır. Bu üç değer hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
- Ardından, Cloud kaynaklarını/API'lerini kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir. Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırılmayı önlemek için kaynakları kapatmak üzere oluşturduğunuz kaynakları veya projeyi silebilirsiniz. Yeni Google Cloud kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir ancak bu codelab'de Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Ortamın temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir ekranla karşılaşırsınız:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
3. Terraform ile ortamı ayarlama
Bu laboratuvarı tamamlamak için TPU'lara erişmeniz gerekir. Kullanılan tam sürüm TPU v6e'dir.
- Erişim elde etmek için TPU planı dokümanını incelemeli ve TPU kotasını etkinleştirmelisiniz.
- 4 TPU v6e çip gerektiren küçük bir dağıtım kullanıyoruz (
ct6e-standard-4t)bu, iki farklı bölgede 2x2 dilim olacaktır). - Hugging Face jetonu: Gemma model ağırlıklarını indirmek için erişim jetonu gerekir.
Güvenlik duvarı kuralları, depolama ve alt ağ içeren özel bir VPC oluşturacağız. Cloud Console'u açın ve kullanacağınız projeyi seçin.
- Konsolunuzun sağ üst kısmında bulunan Cloud Shell'i açın, Cloud Shell'de doğru proje kimliğini gördüğünüzden emin olun ve erişime izin vermek için tüm istemleri onaylayın.

gke-tfadlı bir klasör oluşturun ve bu klasöre gidin.
mkdir -p gke-tf && cd gke-tf
PROJECT_ID=$(gcloud config get-value project)
- Şimdi bazı yapılandırma dosyaları ekleyin. Bu komutlar aşağıdaki network.tf , variable.tf, providers.tf, fuse.tf dosyasını oluşturur.
cat <<EOF > terraform.tfvars
project_id = "${PROJECT_ID}"
EOF
cat <<EOF > variables.tf
variable "project_id" { type = string }
variable "network_prefix" { default = "tpu-gke-dranet" }
variable "regions" { default = ["europe-west4", "us-east5"] }
variable "region_to_tpu_zone" {
default = {
"europe-west4" = "europe-west4-a"
"us-east5" = "us-east5-b"
}
}
EOF
cat <<EOF > providers.tf
terraform {
required_version = ">= 1.5.7"
required_providers {
google-beta = { source = "hashicorp/google-beta", version = "~> 7.0" }
time = { source = "hashicorp/time", version = "~> 0.11.0" }
}
}
provider "google-beta" { project = var.project_id }
resource "google_project_service" "base_apis" {
for_each = toset([
"compute.googleapis.com",
"container.googleapis.com",
"cloudresourcemanager.googleapis.com",
"storage.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
EOF
cat <<EOF > network.tf
resource "google_compute_network" "vpc" {
name = "\${var.network_prefix}-vpc"
auto_create_subnetworks = false
mtu = 8896
depends_on = [google_project_service.base_apis]
}
resource "google_compute_subnetwork" "subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-node-subnet"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.0.1.0/24" : "10.0.2.0/24"
}
resource "google_compute_subnetwork" "proxy_subnets" {
for_each = toset(var.regions)
name = "\${var.network_prefix}-proxy-subnet-\${each.value}"
region = each.value
network = google_compute_network.vpc.id
ip_cidr_range = each.value == "europe-west4" ? "10.1.1.0/24" : "10.1.2.0/24"
purpose = "GLOBAL_MANAGED_PROXY"
role = "ACTIVE"
}
resource "google_compute_address" "gateway_ips" {
for_each = toset(var.regions)
name = "gemma-gateway-ip-\${each.value}"
region = each.value
subnetwork = google_compute_subnetwork.subnets[each.value].id
address_type = "INTERNAL"
}
resource "google_compute_firewall" "allow_internal" {
name = "\${var.network_prefix}-allow-internal"
network = google_compute_network.vpc.name
allow { protocol = "all" }
source_ranges = ["10.0.0.0/8", "10.1.0.0/16"]
}
resource "google_compute_firewall" "allow_health_checks" {
name = "\${var.network_prefix}-allow-hc"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["8000"]
}
source_ranges = ["130.211.0.0/22", "35.191.0.0/16"]
}
EOF
cat <<EOF > fuse.tf
resource "google_storage_bucket" "model_bucket" {
name = "\${var.project_id}-gemma-weights"
location = "US"
force_destroy = true
uniform_bucket_level_access = true
depends_on = [google_project_service.base_apis]
}
resource "google_service_account" "gcs_fuse_sa" {
account_id = "gcs-fuse-sa"
display_name = "Service Account for GCS FUSE"
}
resource "google_storage_bucket_iam_member" "gcs_fuse_sa_admin" {
bucket = google_storage_bucket.model_bucket.name
role = "roles/storage.objectAdmin"
member = "serviceAccount:\${google_service_account.gcs_fuse_sa.email}"
}
resource "google_project_iam_binding" "workload_identity_binding" {
project = var.project_id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:\${var.project_id}.svc.id.goog[default/gemma-ksa]"]
}
EOF
variable.tf dosyaları proje adını, bölgeleri ve bölge bilgilerini ekler. Not: "regions" değişkenini default = ["europe-west4", "us-east5"] TPU kotanızın olduğu bölgelerle güncelleyin. Daha fazla bilgi için "GKE'de TPU kullanılabilirliğini doğrulama" başlıklı belgeye göz atın.
network.tf, projenize iki farklı bölgede alt ağlar, yalnızca proxy alt ağları ve güvenlik duvarı kuralları içeren yeni bir VPC ekler.
provider.tf, Terraform'u desteklemek için ilgili sağlayıcıyı ekler.
fuse.tf, model ağırlıklarınızı önbelleğe almak için Cloud Storage paketini ekler ve objectAdmin izinlerine sahip bir IAM hizmet hesabı sağlar. Bu hesabı GKE Workload Identity'ye bağlar.
- gke-tf dizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın
terraform init -Çalışma dizinini başlatır. Bu adımda, söz konusu yapılandırma için gerekli sağlayıcılar indirilir.terraform plan -Terraform'un altyapınızı dağıtmak için hangi işlemleri yapacağını gösteren bir yürütme planı oluşturur.terraform apply –auto-approvegüncellemeleri çalıştırır ve otomatik olarak onaylar.
terraform init
terraform plan
- Şimdi dağıtımı çalıştırın (Bu işlem 3-5 dakika sürebilir).
terraform apply -auto-approve
- Aynı
gke-tfklasörde aşağıdaki gke.tf dosyasını oluşturun.
cat <<EOF > gke.tf
resource "google_container_cluster" "clusters" {
provider = google-beta
for_each = toset(var.regions)
name = "gke-\${each.value}"
location = var.region_to_tpu_zone[each.value]
deletion_protection = false
network = google_compute_network.vpc.id
subnetwork = google_compute_subnetwork.subnets[each.value].id
release_channel { channel = "RAPID" }
datapath_provider = "ADVANCED_DATAPATH"
networking_mode = "VPC_NATIVE"
gateway_api_config { channel = "CHANNEL_STANDARD" }
ip_allocation_policy {
cluster_ipv4_cidr_block = ""
services_ipv4_cidr_block = ""
}
workload_identity_config { workload_pool = "\${var.project_id}.svc.id.goog" }
addons_config {
gcs_fuse_csi_driver_config { enabled = true }
}
initial_node_count = 1
node_config {
machine_type = "e2-standard-16"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
workload_metadata_config { mode = "GKE_METADATA" }
}
}
resource "google_container_node_pool" "tpu_pools" {
provider = google-beta
for_each = toset(var.regions)
name = "tpu-v6e-pool"
location = var.region_to_tpu_zone[each.value]
cluster = google_container_cluster.clusters[each.value].name
node_count = 1
network_config { accelerator_network_profile = "auto" }
node_config {
machine_type = "ct6e-standard-4t"
oauth_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
labels = { "cloud.google.com/gke-networking-dra-driver" = "true" }
workload_metadata_config { mode = "GKE_METADATA" }
}
lifecycle { ignore_changes = [node_config[0].labels] }
}
EOF
gke.tf, farklı bölgelerde iki küme ekler, 4 çipli TPU v6e'yi çalıştıran iki TPU düğüm havuzu oluşturur ve yönetilen DRANET'i düğüm havuzlarına atar.
- Şimdi dağıtımı çalıştırın (Bu işlem 10-15 dakika sürebilir).
terraform apply -auto-approve
- Doğrula
echo -e "\n=== Verifying GKE Clusters ==="
gcloud container clusters list --filter="name:gke-europe-west4 OR name:gke-us-east5" --project=$PROJECT_ID
echo -e "\n=== Verifying VPC Network ==="
gcloud compute networks list --filter="name:tpu-gke-dranet-vpc" --project=$PROJECT_ID
echo -e "\n=== Verifying Reserved Static IPs for Gateway ==="
gcloud compute addresses list --filter="name~gemma-gateway-ip" --project=$PROJECT_ID
echo -e "\n=== Verifying GCS Bucket ==="
gcloud storage ls | grep "${PROJECT_ID}-gemma-weights"
echo -e "\n=== Verifying GCS FUSE Service Account ==="
gcloud iam service-accounts list --filter="email:gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com" --project=$PROJECT_ID
4. Filo tescili
Kümeyi bir filoya kaydetmemiz gerekiyor.
gke-tfdizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın.
cat <<EOF > fleet.tf
data "google_project" "project" {
project_id = var.project_id
}
resource "google_project_service" "fleet_apis" {
for_each = toset([
"gkehub.googleapis.com",
"multiclusterservicediscovery.googleapis.com",
"multiclusteringress.googleapis.com",
"trafficdirector.googleapis.com"
])
project = var.project_id
service = each.value
disable_on_destroy = false
}
resource "google_project_service_identity" "mci_sa" {
provider = google-beta
project = var.project_id
service = "multiclusteringress.googleapis.com"
depends_on = [google_project_service.fleet_apis]
}
resource "time_sleep" "wait_for_apis" {
create_duration = "60s"
depends_on = [google_project_service.fleet_apis]
}
resource "google_project_iam_member" "mci_sa_admin" {
project = var.project_id
role = "roles/container.admin"
member = "serviceAccount:\${google_project_service_identity.mci_sa.email}"
depends_on = [google_project_service_identity.mci_sa, time_sleep.wait_for_apis]
}
resource "google_gke_hub_membership" "memberships" {
provider = google-beta
for_each = toset(var.regions)
project = var.project_id
membership_id = "gke-\${each.value}"
endpoint {
gke_cluster { resource_link = "//container.googleapis.com/\${google_container_cluster.clusters[each.value].id}" }
}
depends_on = [time_sleep.wait_for_apis, google_container_cluster.clusters]
}
resource "google_gke_hub_feature" "mcs" {
provider = google-beta
name = "multiclusterservicediscovery"
location = "global"
project = var.project_id
depends_on = [time_sleep.wait_for_apis]
}
resource "google_gke_hub_feature" "ingress" {
provider = google-beta
name = "multiclusteringress"
location = "global"
project = var.project_id
depends_on = [google_gke_hub_membership.memberships, google_project_iam_member.mci_sa_admin]
spec {
multiclusteringress { config_membership = "projects/\${var.project_id}/locations/global/memberships/gke-us-east5" }
}
}
EOF
fleet.tf dosyası, her iki kümeyi de küresel bir GKE filosuyla kaydeder ve çoklu küme hizmet keşfi ile girişi etkinleştirir. Bu, ABD kümesini merkezi yapılandırma kümesi olarak belirleyerek Gateway API'nin trafiği izlemesine ve yönlendirmesine olanak tanır.
gke-tfklasöründe (bu işlem 3-5 dakika sürebilir) komutunu çalıştırın.
terraform plan
terraform apply -auto-approve
- Filo kaydını doğrulama
gcloud container fleet memberships list --project=$PROJECT_ID
5. Model ağırlıklarını FUSE'a önbelleğe alma
Gemma modelini bir Python komut dosyası aracılığıyla doğrudan FUSE'a bağlı Cloud Storage paketine güvenli bir şekilde indirmek için ABD kümesinde geçici bir Kubernetes işi çalıştıracağız.
- Aşağıdaki değişkenleri oluşturun
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
- Bu işlemde google/gemma-3-27b-it modeli kullanıldığından HF jetonu oluşturmanız gerekir. Aşağıdaki
YOUR_ACTUAL_HUGGING_FACE_TOKENdeğerini gerçek jetonunuzla değiştirin.
export HF_TOKEN="YOUR_ACTUAL_HUGGING_FACE_TOKEN"
gke-tfdizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın.
gcloud container clusters get-credentials gke-us-east5 --zone us-east5-b --project=$PROJECT_ID
cat <<EOF > ksa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
EOF
kubectl apply -f ksa.yaml --context=$CTX_US
kubectl delete secret hf-secret --context=$CTX_US --ignore-not-found
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX_US
cat <<EOF > download-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: model-downloader
namespace: default
spec:
backoffLimit: 1
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
restartPolicy: Never
containers:
- name: downloader
image: python:3.11-slim
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
command:
- bash
- -c
- |
pip install -U huggingface_hub
echo "Downloading Gemma 3 directly to GCS bucket..."
python3 -c "from huggingface_hub import snapshot_download; import os; snapshot_download(repo_id='google/gemma-3-27b-it', local_dir='/data/gemma-weights', token=os.environ['HF_TOKEN'])"
echo "Download complete! Safe to proceed."
volumeMounts:
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
volumes:
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
EOF
kubectl apply -f download-job.yaml --context=$CTX_US
- Devam etmeden önce indirme işleminin tamamlanmasını bekleyin (model boyutuna bağlı olarak 5-10 dakika sürer).
kubectl logs -f job/model-downloader --context=$CTX_US
("İndirme tamamlandı!" mesajı gösterildiğinde günlüklerden çıkmak için Ctrl+C tuşuna basın.)
6. İş yükü vLLM ve Gemma'yı dağıtma
gke-tfdizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın.
cat <<EOF > workload.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: gemma-ksa
namespace: default
annotations:
iam.gke.io/gcp-service-account: "gcs-fuse-sa@${PROJECT_ID}.iam.gserviceaccount.com"
---
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: all-netdev
namespace: default
spec:
spec:
devices:
requests:
- name: req-netdev
exactly:
deviceClassName: netdev.google.com
allocationMode: All
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gemma
namespace: default
labels:
app: gemma-server
spec:
replicas: 1
selector:
matchLabels:
app: gemma-server
template:
metadata:
labels:
app: gemma-server
annotations:
gke-gcsfuse/volumes: "true"
spec:
serviceAccountName: gemma-ksa
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x2
resourceClaims:
- name: netdev
resourceClaimTemplateName: all-netdev
containers:
- name: vllm-tpu
image: vllm/vllm-tpu:latest
command:
- bash
- -c
- |
export PYTHONUNBUFFERED=1
echo "Booting vLLM instantly from local GCS FUSE mount..."
python3 -m vllm.entrypoints.openai.api_server \
--model /data/gemma-weights \
--tensor-parallel-size 4 \
--port 8000
ports:
- containerPort: 8000
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
claims:
- name: netdev
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: gcs-fuse-volume
mountPath: /data/gemma-weights
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
- name: gcs-fuse-volume
csi:
driver: gcsfuse.csi.storage.gke.io
readOnly: true
volumeAttributes:
bucketName: "${PROJECT_ID}-gemma-weights"
mountOptions: "implicit-dirs"
fileCacheCapacity: "100Gi"
fileCacheForRangeRead: "true"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-gemma-service
namespace: default
spec:
selector:
app: gemma-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: vllm-gemma-monitoring
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
interval: 15s
path: /metrics
EOF
- Şimdi aşağıdaki komut dosyasını çalıştırın (Bu işlem, iki bölgede dağıtım yapıldığından 5-10 dakika sürer).
for CTX in $CTX_EU $CTX_US; do
ZONE=$(echo $CTX | cut -d_ -f3)
CLUSTER=$(echo $CTX | cut -d_ -f4)
gcloud container clusters get-credentials $CLUSTER --zone $ZONE --project=$PROJECT_ID
kubectl delete secret hf-secret --ignore-not-found --context=$CTX
kubectl create secret generic hf-secret --from-literal=hf_token=${HF_TOKEN} --context=$CTX
kubectl apply -f workload.yaml --context=$CTX
done
- Dağıtımı onaylama
for CTX in $CTX_EU $CTX_US; do kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX; done
- İşlem tamamlandıktan sonra, aşağıdaki komutu çalıştırarak yönetilen DRANET ağının pod'lara atanıp atanmadığını doğrulayabilirsiniz.
for CTX in $CTX_EU $CTX_US; do
echo "Checking DRA network interfaces on $CTX..."
kubectl --context=$CTX exec deployment/vllm-gemma -c vllm-tpu -- ls /sys/class/net
echo "----------------------------------------"
done
Standart kapsül ağ iletişimi için eth0 adlı ek ağ arayüzlerinin yanı sıra özel TPU yapınızı temsil eden ikincil arayüzleri (eth1, eth2 vb.) görürsünüz.
7. Çıkarım API'si ve Ağ Geçidi Yapılandırması
Şimdi InferenceObjective (gemma-objective), AutoscalingMetric (tpu-cache) ve Inference Pool(gemma-pool) öğelerini oluşturacaksınız. Çıkarım havuzu, Helm grafiği kullanılarak oluşturulur. Oluşturma işlemini yükler ve doğrular.
gke-tfdizininde olduğunuzdan emin olun ve aşağıdaki komutları çalıştırın. Bu işlem, nesneyi dağıtır ve bir doğrulama çalıştırır.
cat <<EOF > inference-objective.yaml
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferenceObjective
metadata:
name: gemma-objective
namespace: default
spec:
priority: 10
poolRef:
name: gemma-pool
group: "inference.networking.k8s.io"
EOF
cat <<EOF > metrics.yaml
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: tpu-cache
namespace: default
spec:
selector:
matchLabels:
app: gemma-server
endpoints:
- port: 8000
path: /metrics
metrics:
- name: vllm:kv_cache_usage_perc
exportName: tpu-cache
EOF
for CTX in $CTX_EU $CTX_US; do
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX
kubectl apply -f inference-objective.yaml --context=$CTX
kubectl apply -f metrics.yaml --context=$CTX
done
helm install gemma-pool --kube-context $CTX_EU \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
helm install gemma-pool --kube-context $CTX_US \
--set inferencePool.modelServers.matchLabels.app=gemma-server \
--set provider.name=gke \
--set inferenceExtension.monitoring.gke.enabled=true \
--version v1.1.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
for CTX in $CTX_EU $CTX_US; do
kubectl annotate inferencepool gemma-pool networking.gke.io/export="True" --context=$CTX
done
for CTX in $CTX_EU $CTX_US; do
echo "Verifying Inference API resources on $CTX..."
kubectl get inferencepools --context=$CTX
kubectl get autoscalingmetrics tpu-cache --context=$CTX
done
8. Ağ Geçidi Yapılandırması
Şimdi bölgeler arası ağ geçidi yapılandırmasını oluşturacaksınız. Gateway(cross-region-gateway), HTTPRoute (gemma-route), HealthCheckPolicy(gemma-health-check)and GCPBackendPolicy(gemma-backend-policy. Çıkarım havuzu, Helm grafiği kullanılarak oluşturulur. Oluşturma işlemini yükler ve doğrular. (Ağ geçidinin etkinleşmesi 8-10 dakika sürer)
cat <<EOF > config-cluster.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cross-region-gateway
namespace: default
spec:
gatewayClassName: gke-l7-cross-regional-internal-managed-mc
addresses:
- type: networking.gke.io/named-address-with-region
value: "regions/europe-west4/addresses/gemma-gateway-ip-europe-west4"
- type: networking.gke.io/named-address-with-region
value: "regions/us-east5/addresses/gemma-gateway-ip-us-east5"
listeners:
- name: http
protocol: HTTP
port: 80
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: gemma-route
namespace: default
spec:
parentRefs:
- name: cross-region-gateway
kind: Gateway
rules:
- backendRefs:
- group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
port: 8000
---
apiVersion: networking.gke.io/v1
kind: HealthCheckPolicy
metadata:
name: gemma-health-check
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
config:
type: HTTP
httpHealthCheck:
requestPath: /health
port: 8000
---
apiVersion: networking.gke.io/v1
kind: GCPBackendPolicy
metadata:
name: gemma-backend-policy
namespace: default
spec:
targetRef:
group: networking.gke.io
kind: GCPInferencePoolImport
name: gemma-pool
default:
timeoutSec: 100
balancingMode: CUSTOM_METRICS
trafficDuration: LONG
customMetrics:
- name: gke.named_metrics.tpu-cache
dryRun: false
maxUtilizationPercent: 60
EOF
echo -e "\n=== Creating Cross-Regional Gateway Resources ==="
kubectl apply -f config-cluster.yaml --context=$CTX_US
echo -e "\n=== Provisioning Global Load Balancer (This takes 5-10 minutes) ==="
echo "Working on the Gateway... waiting for Google Cloud to assign IPs and program routes..."
# The script will hold here until the gateway is officially ready
kubectl wait --for=condition=programmed gateway/cross-region-gateway --timeout=10m --context=$CTX_US
echo -e "\n=== SUCCESS: Gateway is fully provisioned and ready! ==="
Çıkarım havuzu (Helm): Her iki bölgedeki model sunucularınızı tek bir mantıksal arka uçta gruplandırır.
Gateway ve HTTPRoute: Gerçek genel dahili yük dengeleyiciyi oluşturur ve gelen yapay zeka istemlerini modellerinize yönlendirme kurallarını tanımlar.
Durum denetimi ve arka uç politikaları: İsteklerin yalnızca iyi durumda olan pod'lara gönderilmesini sağlar ve akıllı, metriğe dayalı trafik dağıtımına olanak tanır (aşırı yüklenmiş TPU'ları önler).
Doğrulama: Google Cloud'un dahili IP adreslerini tam olarak sağladığından emin olmak için komut dosyası duraklatılır.
9. Yük devretme testi
Şimdi laboratuvarın en iyi kısmına, yani mimarinizin yüksek kullanılabilirliğini test etme bölümüne geçiyoruz.
Bu otomatik testin tam olarak ne yapacağını aşağıda bulabilirsiniz:
- Temel Test: Simüle edilmiş kullanıcımız bir çıkarım istemi gönderir ("Fransa'nın başkenti neresidir?"). Kullanıcı birincil bölgede bulunduğundan, ağ geçidi isteği mümkün olan en düşük gecikme süresi için bu yerel TPU'lara yönlendirir.
- Felaket: Birincil bölgedeki (
replicas=0) tüm TPU pod'larını kapatarak felaket niteliğinde bir veri merkezi kesintisini simüle ediyoruz. - Algılama: 45 saniye bekleriz. Bu süre zarfında, ağ geçidinin durum kontrolleri başarısız olur, birincil arka ucun tamamen çevrimdışı olduğunu fark eder ve genel yönlendirme tablolarını dinamik olarak günceller.
- Yük Devretme: Kullanıcımız ikinci bir istem gönderiyor ("Almanya'nın başkenti neresidir?"). Kullanıcı, kesinti olduğundan haberdar değildir. Ağ geçidi, isteği yakalar ve anında sağlıklı ikincil TPU'larınıza yönlendirir.
- Kurtarma: Birincil TPU'ları geri yükleyerek küresel mimarinizi tekrar tam kapasiteyle çalışır hâle getiririz.
- Cloud Shell'i açıp aşağıdaki komutu çalıştırın:
cat << 'EOF' > failover-test.sh
#!/bin/bash
# Multi-Cluster Inference Failover Test
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo -e "\n=== PHASE 1: VERIFYING CURRENT STATE (BOTH CLUSTERS UP) ==="
echo "Checking US Cluster (Primary):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Secondary):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nDeploying Test Client in US..."
export GATEWAY_IP_US=$(gcloud compute addresses describe gemma-gateway-ip-us-east5 --region=us-east5 --project=$PROJECT_ID --format="value(address)")
kubectl run curl-test --image=curlimages/curl --restart=Never --context=$CTX_US -- sleep 3600
kubectl wait --for=condition=ready pod/curl-test --context=$CTX_US --timeout=60s
echo -e "\n=== PHASE 2: BASELINE TEST (US Client -> US TPUs) ==="
echo "Prompting the AI: 'What is the capital of France?'"
echo "Expect to see the full JSON response including token usage..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 3: SIMULATING REGIONAL OUTAGE (Scaling US to 0) ==="
kubectl scale deployment vllm-gemma --replicas=0 --context=$CTX_US
echo "Waiting 20 seconds for pods to begin terminating..."
sleep 20
echo -e "\n=== PHASE 4: CONFIRMING STATE (PODS TERMINATING) ==="
echo "Checking US Cluster (Should be terminating):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\nWaiting 45 seconds for Gateway health checks to update global routing tables..."
sleep 45
echo -e "\n=== PHASE 5: CONFIRMING COMPLETE DOWN AND EURO UP ==="
echo "Checking US Cluster (Should be completely empty now):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Should still be running):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 6: FAILOVER TEST (US Client -> EU TPUs) ==="
echo "Prompting the AI: 'What is the capital of Germany?'"
echo "Request is actively being rerouted to Europe. Expecting full JSON response..."
kubectl exec curl-test --context=$CTX_US -- curl -s -X POST http://$GATEWAY_IP_US/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/gemma-weights",
"messages": [{"role": "user", "content": "What is the capital of Germany?"}],
"max_tokens": 100
}' | jq .
echo -e "\n=== PHASE 7: RESTORING INFRASTRUCTURE (Scaling US to 1) ==="
kubectl scale deployment vllm-gemma --replicas=1 --context=$CTX_US
echo "Waiting for US pods to boot and mount FUSE..."
kubectl rollout status deployment/vllm-gemma --timeout=15m --context=$CTX_US
echo -e "\n=== PHASE 8: CONFIRMING BOTH SYSTEMS ARE BACK UP ==="
echo "Checking US Cluster (Restored):"
kubectl get pods -l app=gemma-server --context=$CTX_US
echo "Checking EU Cluster (Still Healthy):"
kubectl get pods -l app=gemma-server --context=$CTX_EU
echo -e "\n=== PHASE 9: CLEANUP ==="
kubectl delete pod curl-test --context=$CTX_US
echo "Failover lab complete."
EOF
chmod +x failover-test.sh
./failover-test.sh
- Test tamamlandıktan sonra temizlik yapabilirsiniz.
10. Temizleme
- İş yükünü temizleme
#!/bin/bash
echo "=== PART 1: Kubernetes & Workload Cleanup ==="
export PROJECT_ID=$(gcloud config get-value project)
export CTX_EU="gke_${PROJECT_ID}_europe-west4-a_gke-europe-west4"
export CTX_US="gke_${PROJECT_ID}_us-east5-b_gke-us-east5"
echo "Deleting Gateway resources..."
for CTX in $CTX_EU $CTX_US; do
kubectl delete gateways,httproutes,healthcheckpolicies,gcpbackendpolicies --all --context=$CTX --ignore-not-found
done
echo "Waiting 60 seconds for the external Load Balancer to detach..."
sleep 60
echo "Cleaning up workloads and custom resources..."
for CTX in $CTX_EU $CTX_US; do
helm uninstall gemma-pool --kube-context=$CTX || true
kubectl delete job model-downloader --context=$CTX --ignore-not-found
kubectl delete all -l app=gemma-server --context=$CTX --ignore-not-found
kubectl delete inferenceobjectives,autoscalingmetrics --all --context=$CTX --ignore-not-found
kubectl delete serviceaccount gemma-ksa --context=$CTX --ignore-not-found
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/gateway-api-inference-extension/v1.1.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml --context=$CTX --ignore-not-found
done
echo -e "\n=== Part 1 Complete! Safe to proceed to Terraform Teardown. ==="
- Altyapıyı temizleyin.
gke-tfklasöründe olduğunuzdan emin olun.
cat << 'EOF' > cleanup-tf.sh
#!/bin/bash
echo "=== PART 2: Infrastructure & Terraform Teardown ==="
export PROJECT_ID=$(gcloud config get-value project)
export LAB_NETWORK="tpu-gke-dranet-vpc"
echo "Destroying GKE Fleet Features to prevent firewall resurrection..."
terraform destroy -target=google_gke_hub_feature.mcs -target=google_gke_hub_feature.ingress -auto-approve
echo "Waiting 30 seconds for the self-healing controllers to spin down..."
sleep 30
echo "Hunting down orphaned auto-generated firewall rules strictly on the lab network..."
GHOST_RULES=$(gcloud compute firewall-rules list --filter="network~${LAB_NETWORK} AND (name~mcsd OR name~k8s-fw-l7)" --format="value(name)" --project=$PROJECT_ID)
if [ ! -z "$GHOST_RULES" ]; then
for rule in $GHOST_RULES; do
echo "Deleting ghost rule: $rule"
gcloud compute firewall-rules delete $rule --project=$PROJECT_ID --quiet
done
else
echo "No ghost rules found on ${LAB_NETWORK}."
fi
echo "=== Controllers and Firewalls dead. Destroying remaining Base Infrastructure. ==="
MAX_RETRIES=3
RETRY_COUNT=0
SUCCESS=false
while [ $RETRY_COUNT -lt $MAX_RETRIES ]; do
# Run the destroy command. If it succeeds (exit code 0), break the loop.
if terraform destroy -auto-approve; then
SUCCESS=true
break
else
RETRY_COUNT=$((RETRY_COUNT+1))
echo -e "\n[WARNING] Terraform destroy encountered an error (likely a GCP resource lock)."
if [ $RETRY_COUNT -lt $MAX_RETRIES ]; then
echo "Waiting 30 seconds before retry $RETRY_COUNT of $MAX_RETRIES..."
sleep 30
fi
fi
done
if [ "$SUCCESS" = true ]; then
echo -e "\n=== Lab Cleanup Successfully Completed! ==="
else
echo -e "\n[ERROR] Lab Cleanup failed after $MAX_RETRIES attempts."
echo "Some resources may still be locked. Run 'terraform destroy -auto-approve' manually later to finish."
exit 1
fi
EOF
chmod +x cleanup-tf.sh
./cleanup-tf.sh
Belirli kaynakları silerken sorun yaşarsanız terraform destroy komut dosyasını ./cleanup-tf.sh yeniden çalıştırmanız gerekir.
11. Tebrikler
Tebrikler! GKE, yönetilen DRANET ve TPU v6e hızlandırıcılarını kullanarak yüksek düzeyde kullanılabilir, çok kümeli bir GKE çıkarım ağ geçidi ve bölgeler arası yapay zeka çıkarım mimarisi başarıyla dağıttınız.
Anında model yükleme için Cloud Storage FUSE ve gecikmeye duyarlı, çok kümeli yönlendirme için Inference Gateway API'yi birleştirerek, dahili kullanıcı trafiğini düşürmeden bölgesel veri merkezinin tamamen kesintiye uğramasına dayanabilecek esnek bir arka uç oluşturdunuz.
Sonraki adımlar / Daha fazla bilgi
GKE ağ iletişimi hakkında daha fazla bilgi edinebilirsiniz.
Sonraki laboratuvarınıza katılın
Google Cloud ile görevinize devam edin ve aşağıdaki Google Cloud laboratuvarlarına göz atın: