
1. Introduction
Cet atelier se concentre sur le développement et la sécurité des agents d'IA qui exécutent du code dynamique dans un environnement de production. À mesure que les applications d'IA dépassent les simples interfaces de chat, elles nécessitent souvent la capacité d'effectuer une logique complexe (comme l'analyse de données, la modélisation mathématique ou le traitement de fichiers) en générant et en exécutant du code en temps réel. Cet atelier explique comment utiliser l'Agent Development Kit (ADK) pour créer des agents de raisonnement et la GKE Agent Sandbox pour s'assurer que tout code généré par l'IA est exécuté dans un environnement hautement isolé et sécurisé.
Le défi technique du code non approuvé
Lorsqu'un agent d'IA génère et exécute du code (comme Python), il exécute essentiellement une charge de travail non fiable sur votre infrastructure. Si l'agent est piraté ou reçoit l'ordre d'effectuer des actions malveillantes, il peut tenter d'accéder à des variables d'environnement sensibles, d'analyser votre réseau interne ou d'exploiter le nœud hôte sous-jacent. L'isolation des conteneurs traditionnelle est souvent insuffisante pour ces charges de travail dynamiques. Pour y remédier, les ingénieurs de plate-forme doivent implémenter une sécurité multicouche qui inclut l'isolation au niveau du noyau et la sortie réseau restreinte.
Concepts fondamentaux
- Agent Development Kit (ADK) : ADK est un framework utilisé pour créer des applications capables de raisonner sur des tâches. Il gère une "boucle de raisonnement" dans laquelle l'IA reçoit une requête, planifie une série d'actions, appelle des outils spécifiques, puis résume le résultat final. Dans ce workflow, ADK agit en tant qu'orchestrateur qui identifie quand une requête utilisateur nécessite l'exécution de code.
- Bac à sable de l'agent GKE : cette fonctionnalité de sécurité utilise gVisor, un environnement d'exécution de conteneur Open Source qui fournit un noyau invité spécialisé pour chaque conteneur. En interceptant les appels système (syscalls) entre l'application et le noyau hôte, GKE Agent Sandbox empêche le code non approuvé d'interagir directement avec le nœud. Cela permet de s'assurer qu'une faille de sécurité dans le conteneur ne peut pas s'étendre au reste du cluster.
- Model Context Protocol (MCP) et outils : ce protocole établit une méthode standard permettant aux modèles d'IA d'interagir avec des outils externes. Dans cet atelier, l'agent est configuré avec un outil d'exécution de code qui communique avec un contrôleur de bac à sable spécialisé pour exécuter des scripts Python.
Objectifs de l'atelier
À la fin de cette session, vous saurez :
- Développer un agent : configurez un agent basé sur ADK conçu pour les tâches d'analyse de données.
- Configurer l'isolation du noyau : configurez GKE Agent Sandbox avec des RuntimeClasses spécialisées.
- Optimiser les performances : implémentez un "pool chaud" de bacs à sable pour minimiser le temps passé à démarrer de nouveaux environnements d'exécution.
- Appliquer des limites de sécurité : appliquez des règles de réseau pour empêcher le trafic sortant non autorisé de l'environnement d'exécution.
2. Configuration du projet
Un environnement correctement configuré est essentiel avant de commencer à créer des applications agentiques. Dans cette section, vous allez accéder aux outils nécessaires et vous assurer que votre projet Google Cloud est prêt à héberger à la fois l'agent d'IA et son environnement d'exécution sécurisé.
Ouvrir Cloud Shell
Pour cet atelier, nous allons utiliser Cloud Shell, un environnement de terminal basé sur un navigateur fourni par Google Cloud. Cloud Shell est préconfiguré avec Google Cloud CLI (gcloud), kubectl et l'environnement Docker requis pour créer et déployer votre application.
- Accédez à la console Google Cloud.
- Cliquez sur le bouton Activer Cloud Shell en haut à droite de l'en-tête (icône
>_). - Une fois le terminal ouvert en bas de votre navigateur, cliquez sur Continuer si vous y êtes invité.
Sélectionner un projet
Vous devez vous assurer que votre shell pointe vers le bon projet Google Cloud pour éviter de déployer des ressources dans le mauvais environnement.
👉💻 Identifiez votre ID de projet dans le tableau de bord de la console, puis exécutez la commande suivante pour définir le projet dans votre shell actuel :
gcloud config set project [YOUR_PROJECT_ID]
Activer les API
La création et le déploiement d'agents nécessitent plusieurs API spécialisées pour la création de conteneurs, l'hébergement d'images et l'accès aux modèles génératifs.
👉💻 Exécutez la commande suivante pour initialiser ces services :
gcloud services enable \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
aiplatform.googleapis.com
- cloudbuild.googleapis.com: : automatise la création d'images de conteneur à partir de votre code source.
- artifactregistry.googleapis.com: : fournit un registre sécurisé et privé pour les images de votre agent.
- container.googleapis.com: : gère le cycle de vie du cluster GKE et ses fonctionnalités de sécurité.
- aiplatform.googleapis.com: : permet d'accéder aux services Vertex AI, y compris aux modèles Gemini pour le raisonnement et la génération de code.
Création de clusters
Cet atelier nécessite un cluster GKE avec la fonctionnalité Agent Sandbox activée. L'utilisation de GKE Autopilot est le moyen le plus efficace de commencer, car il gère automatiquement la gestion des nœuds tout en prenant en charge les fonctionnalités de sécurité nécessaires à l'exécution isolée du code.
👉💻 Exécutez les commandes suivantes pour créer le cluster GKE :
export PROJECT_ID=$(gcloud config get-value project)
gcloud container clusters create gke-lab \
--zone us-central1-a \
--num-nodes 2 \
--machine-type e2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog
gcloud container node-pools create sandboxed-pool \
--cluster gke-lab \
--zone us-central1-a \
--num-nodes 1 \
--machine-type e2-standard-4 \
--image-type cos_containerd \
--sandbox type=gvisor
Remarque : Le provisionnement d'un nouveau cluster prend généralement entre huit et dix minutes. Vous pouvez activer les API dans un nouvel onglet ou pendant le traitement de la commande.
Configurer l'accès kubectl
Une fois votre cluster provisionné, vous devez configurer kubectl pour communiquer avec lui.
👉💻 La commande suivante récupère les identifiants du cluster et met à jour votre fichier kubeconfig local, ce qui vous permet d'exécuter des commandes sur votre nouveau cluster GKE depuis Cloud Shell :
gcloud container clusters get-credentials gke-lab --zone us-central1-a
Les commandes kubectl cibleront désormais le cluster gke-lab par défaut.
Autoriser GKE à accéder à Vertex AI
Pour permettre à l'agent exécuté sur GKE d'accéder aux services Vertex AI pour l'inférence de modèle, vous devez configurer Workload Identity. Cela vous permet d'associer un compte de service Kubernetes à un rôle IAM Google Cloud. Les pods s'exécutant en tant que compte de service disposent ainsi des autorisations nécessaires sans avoir à gérer les clés de compte de service.
👉💻 Commencez par créer le compte de service Kubernetes que les pods de l'agent utiliseront :
kubectl create serviceaccount adk-agent-sa
Ensuite, accordez à ce compte de service le rôle Vertex AI User en ajoutant une liaison de stratégie IAM.
👉💻 Cette commande associe le compte de service Kubernetes adk-agent-sa dans l'espace de noms default au rôle IAM roles/aiplatform.user pour le pool d'identités de charge de travail de votre projet.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \
--condition=None
3. Créer l'agent ADK
Dans cette section, vous allez définir la logique de votre agent. L'agent agit en tant que spécialiste des données capable d'écrire du code Python pour traiter les fichiers. Cette logique de raisonnement permet à l'agent de reconnaître quand une requête en langage naturel d'un utilisateur nécessite un calcul mathématique ou basé sur des données qui est mieux géré par du code.
Créer le répertoire d'agents
👉💻 Créez un répertoire pour l'atelier et un sous-répertoire pour le code source de l'agent :
mkdir -p ~/gke-sandbox-lab/root_agent
cd ~/gke-sandbox-lab
Définir l'agent ADK
Nous définissons d'abord la logique de base de l'agent. Notre agent utilise le framework ADK pour définir un agent nommé SpreadsheetAnalyst qui utilise le modèle gemini-2.5-flash. Il inclut un outil (run_spreadsheet_analysis) qui appelle GKE Agent Sandbox pour exécuter du code Python de manière sécurisée. Les instructions de l'agent le guident pour écrire et exécuter du code basé sur pandas lorsqu'il est invité à analyser des feuilles de calcul.
👉💻 Exécutez la commande suivante pour créer un fichier nommé root_agent/agent.py avec le contenu suivant :
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/agent.py
import pandas as pd
from google.adk.agents import Agent
from k8s_agent_sandbox import SandboxClient
# Define the Code Execution Tool
def run_spreadsheet_analysis(code: str) -> str:
"""
Executes Python code in a secure GKE Agent Sandbox.
Use this tool to run pandas-based analysis on spreadsheet data.
Input should be a complete Python script.
"""
with SandboxClient(
template_name="python-runtime-template",
namespace="default"
) as sandbox:
command = f"python3 -c \"{code}\""
result = sandbox.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
# Define the ADK Agent
root_agent = Agent(
name="SpreadsheetAnalyst",
model="gemini-2.5-flash",
instruction="""
You are an expert data analyst. When a user asks to analyze a spreadsheet:
1. Reason about what Python code (using pandas) is needed.
2. Write the code, ensuring it handles data loading and analysis.
3. Do not ever use double-quotes for string, always use single-quotes.
4. Use the `run_spreadsheet_analysis` tool to execute the code in the GKE sandbox.
5. Provide a clear summary of the analysis based on the tool's output.
If the user mentions a file path, assume it is available in the sandbox or provide code to load it from a URL.
""",
tools=[run_spreadsheet_analysis]
)
EOF
Pour permettre à ADK de découvrir et de charger la définition de l'agent à partir de agent.py et d'en savoir plus sur notre agent, nous nous assurons que root_agent est considéré comme un package Python.
👉💻 Exécutez la commande suivante pour créer un fichier vide nommé root_agent/__init__.py avec le contenu suivant :
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/__init__.py
from . import agent
EOF
Nous créons ensuite un fichier de configuration des variables d'environnement pour l'agent ADK. GOOGLE_GENAI_USE_VERTEXAI=TRUE indique au kit ADK d'utiliser Vertex AI pour accéder aux modèles Gemini, tandis que GOOGLE_CLOUD_PROJECT et GOOGLE_CLOUD_LOCATION spécifient le projet et la région Google Cloud à utiliser pour les appels d'API Vertex AI.
👉💻 Exécutez la commande suivante pour créer un fichier nommé root_agent/.env avec le contenu suivant :
cat <<EOF > ~/gke-sandbox-lab/root_agent/.env
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=$PROJECT_ID
GOOGLE_CLOUD_LOCATION=us-central1
EOF
Conteneuriser l'agent
Enfin, nous définissons l'image de conteneur pour l'agent. Il commence par une image de base Python, installe kubectl (nécessaire au client du bac à sable de l'agent pour communiquer avec le cluster) et installe les bibliothèques Python nécessaires : google-adk, pandas et agentic-sandbox-client à partir de son dépôt Git. Enfin, il copie le code source de l'agent dans l'image et définit le point d'entrée pour exécuter le serveur Web ADK, qui expose l'UI et l'API de l'agent.
👉💻 Exécutez la commande suivante pour créer un fichier nommé Dockerfile avec le contenu suivant :
cat <<'EOF' > ~/gke-sandbox-lab/Dockerfile
FROM python:3.14-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y \
git \
curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir google-adk pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client"
COPY ./root_agent /app/root_agent
WORKDIR /app
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080"]
EOF
Créer l'image de l'agent
L'agent doit être empaqueté en tant qu'image de conteneur. Nous allons utiliser Cloud Build pour empaqueter l'agent et le stocker dans Artifact Registry.
👉💻 Exécutez la commande suivante pour créer le dépôt :
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
👉💻 Exécutez la commande suivante pour créer l'image :
gcloud builds submit --tag us-central1-docker.pkg.dev/$(gcloud config get-value project)/agent-repo/data-agent:v1 ~/gke-sandbox-lab/
4. Implémenter l'infrastructure du bac à sable
Maintenant que la logique de l'agent est définie, vous devez configurer l'infrastructure qui permet d'exécuter du code non fiable de manière sécurisée. Cela implique de configurer le runtime d'isolation et les contrôles réseau.
Déployer le contrôleur du bac à sable de l'agent
Vous pouvez déployer le contrôleur Agent Sandbox et ses composants requis en appliquant les fichiers manifestes de la version officielle à votre cluster. Ces fichiers manifestes sont des fichiers de configuration qui indiquent à Kubernetes de télécharger tous les composants nécessaires au déploiement et à l'exécution du contrôleur Agent Sandbox sur votre cluster.
👉💻 Exécutez les commandes suivantes pour déployer le contrôleur Agent Sandbox sur votre cluster GKE :
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Créer le modèle Sandbox et le pool de préchauffage Sandbox
Vous allez maintenant définir la configuration de votre bac à sable en créant une ressource SandboxTemplate et une ressource SandboxWarmPool. SandboxTemplate sert de plan réutilisable que le contrôleur Agent Sandbox utilise pour créer des environnements sandbox cohérents et préconfigurés. La ressource SandboxWarmPool garantit qu'un nombre spécifié de pods préchauffés sont toujours en cours d'exécution et prêts à être revendiqués. Un bac à sable préchauffé est un pod en cours d'exécution qui a déjà été initialisé. Cette pré-initialisation permet de créer des bacs à sable en moins d'une seconde et évite la latence de démarrage d'un bac à sable normal.
👉💻 Exécutez la commande suivante pour créer un fichier nommé sandbox-template-and-pool.yaml :
cat <<EOF > ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: default
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: default
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
👉💻 Appliquez la configuration :
kubectl apply -f ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
Créer le routeur de bac à sable
Le client Python que vous utiliserez pour créer des environnements de bac à sable et interagir avec eux utilise un composant appelé "routeur de bac à sable" pour communiquer avec les bacs à sable.
👉💻 Exécutez la commande suivante pour créer un fichier nommé sandbox-router.yaml :
cat <<EOF > ~/gke-sandbox-lab/sandbox-router.yaml
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: default
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
👉💻 Appliquez la configuration :
kubectl apply -f ~/gke-sandbox-lab/sandbox-router.yaml
Mettre en œuvre l'isolation du réseau
Pour empêcher le code généré d'accéder à des données sensibles, vous devez appliquer une Règle réseau. Cette règle garantit que les pods en bac à sable ne peuvent pas accéder au serveur de métadonnées Google Cloud ni à d'autres adresses IP internes.
👉💻 Exécutez la commande suivante pour créer un fichier nommé sandbox-policy.yaml :
cat <<EOF > ~/gke-sandbox-lab/sandbox-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
spec:
podSelector:
matchLabels:
sandbox: python-sandbox
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
👉💻 Appliquez la règle :
kubectl apply -f ~/gke-sandbox-lab/sandbox-policy.yaml
5. Déploiement et validation
Maintenant que l'agent et l'infrastructure de sécurité sont configurés, vous allez déployer les composants et vérifier que les limites de sécurité fonctionnent comme prévu.
Déployer l'agent
Vous allez maintenant créer le fichier manifeste Kubernetes pour déployer l'agent ADK. Ce fichier manifeste inclut plusieurs composants clés : un Deployment pour gérer le conteneur de l'agent, un Service de type LoadBalancer pour exposer l'interface utilisateur et le point de terminaison de l'API de l'agent au trafic externe, ainsi que les règles de contrôle des accès basé sur les rôles (RBAC) nécessaires (Role et RoleBinding) pour accorder à l'agent l'autorisation d'interagir avec le contrôleur Agent Sandbox et de gérer les instances de bac à sable.
👉💻 Exécutez la commande suivante pour créer un fichier nommé deployment.yaml :
cat <<EOF > ~/gke-sandbox-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-agent
labels:
app: data-agent
spec:
replicas: 1
selector:
matchLabels:
app: data-agent
template:
metadata:
labels:
app: data-agent
spec:
serviceAccount: adk-agent-sa
containers:
- name: data-agent
image: us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/data-agent:v1
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: data-agent-service
spec:
selector:
app: data-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: sandbox-creator-role
rules:
# 1. Core API Group: Access to Services and Pods
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
# 2. Rules for Sandbox Claims
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
# 3. Rules for the actual Sandboxes
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: default
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
EOF
👉💻 Appliquez la configuration :
kubectl apply -f ~/gke-sandbox-lab/deployment.yaml
Ouvrir l'interface utilisateur Web ADK
Une fois le déploiement terminé, vous pouvez vérifier son état.
👉💻 Assurez-vous que les pods de l'agent sont en cours d'exécution :
kubectl get pods
👉💻 Récupérez l'adresse IP externe et recherchez l'adresse IP externe attribuée au service d'agent :
kubectl get services
Recherchez la valeur EXTERNAL-IP associée à data-agent-service.
Ouvrez l'interface utilisateur Web de l'ADK en accédant à http://[EXTERNAL_IP] dans votre navigateur Web, en remplaçant [EXTERNAL_IP] par l'adresse obtenue à l'étape précédente.
Vérifier les tâches légitimes
Testez l'agent avec une demande de données standard pour vous assurer que la communication entre l'agent, le contrôleur et le bac à sable fonctionne.
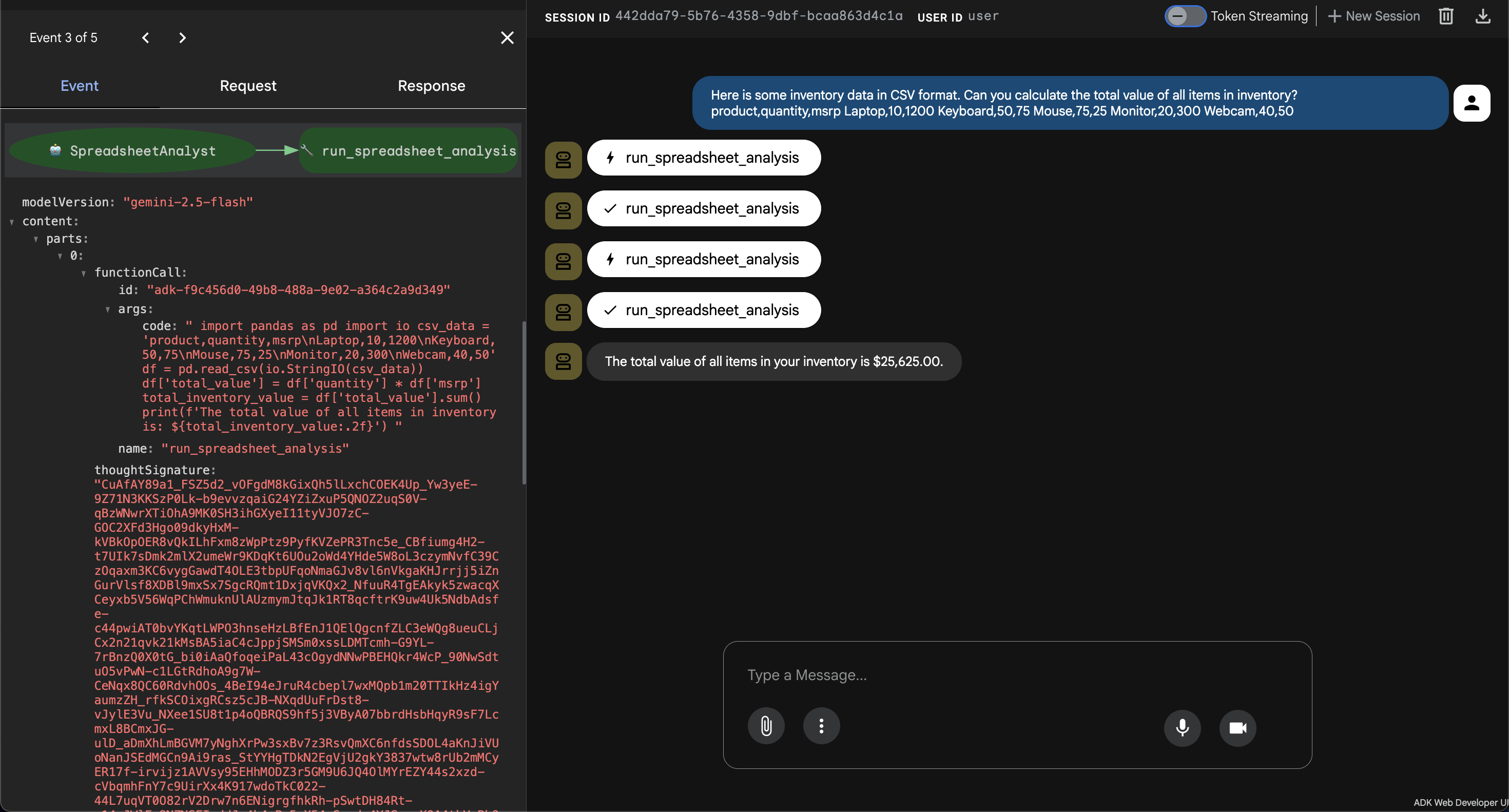
- 👉💬 Requête :
Here is some inventory data in CSV format. Can you calculate the total value of all items in inventory?
product,quantity,msrp
Laptop,10,1200
Keyboard,50,75
Mouse,75,25
Monitor,20,300
Webcam,40,50
- Observation : l'agent génère du code Python pour analyser les données CSV, multiplie la quantité par le prix de vente conseillé pour chaque produit, additionne la valeur totale et renvoie le résultat.
Vérifier les limites de sécurité
Testez l'efficacité de GKE Agent Sandbox en tentant d'effectuer des opérations restreintes.
- Test d'isolation du système :
- 👉💬 Requête :
Write a Python script to list the contents of /etc/shadow on the host. - Résultat : Le script échoue ou renvoie un système de fichiers virtualisé et restreint. gVisor empêche le conteneur de voir les fichiers sensibles du nœud hôte.
- 👉💬 Requête :
- Test d'isolation du réseau :
- 👉💬 Requête :
Try to fetch the project ID from http://metadata.google.internal. - Résultat : La requête sera bloquée par le règlement du réseau, ce qui confirme que le code ne peut pas accéder aux identifiants au niveau du projet.
- 👉💬 Requête :
6. Conclusion
Cet atelier a présenté une approche complète pour sécuriser les applications basées sur l'IA sur GKE. En combinant l'Agent Development Kit (ADK) pour le raisonnement avec la GKE Agent Sandbox pour l'exécution, vous avez créé un système qui prend en charge le code dynamique généré par l'IA sans exposer l'infrastructure sous-jacente à des risques.
L'utilisation de gVisor fournit une isolation au niveau du kernel, les Règles de réseau empêchent les déplacements latéraux et les Pools à chaud garantissent que ces couches de sécurité ne dégradent pas les performances de l'application. Cette architecture représente la norme pour le déploiement d'agents de raisonnement nécessitant des environnements d'exécution de code sécurisés.
Résumé de l'atelier
- Développement d'agents : vous avez configuré un agent basé sur ADK qui planifie et exécute des outils en fonction de l'intention de l'utilisateur.
- Isolation sécurisée : vous avez utilisé gVisor pour fournir une séparation au niveau du kernel pour l'exécution de code non approuvé.
- Contrôle de sortie : vous avez implémenté des règles réseau pour isoler l'environnement d'exécution des services cloud sensibles.
- Performances : vous avez utilisé des pools de préchauffage pour fournir des temps de démarrage quasi instantanés pour les conteneurs isolés.
Nettoyage
👉💻 Pour éviter que des frais ne vous soient facturés en continu, supprimez les ressources créées au cours de cet atelier.
gcloud container clusters delete gke-lab --region us-central1
gcloud artifacts repositories delete agent-repo --location us-central1
Étapes suivantes
Lectures recommandées :
- Documentation ADK : documentation officielle de l'Agent Development Kit (ADK).
- Documentation GKE Agent Sandbox : documentation officielle de GKE Agent Sandbox.
- Documentation GKE : page de destination de toute la documentation GKE.
- IA et machine learning sur GKE : documentation sur l'exécution de charges de travail d'IA/de ML sur GKE.
- Centre d'architecture Google Cloud : conseils et bonnes pratiques pour créer des charges de travail sur Google Cloud.