
1. はじめに
このラボでは、本番環境内で動的コードを実行する AI エージェントの開発とセキュリティに焦点を当てます。AI アプリケーションが単純なチャット インターフェースから進化するにつれて、リアルタイムでコードを生成して実行することで、データ分析、数理モデリング、ファイル処理などの複雑なロジックを実行する機能が必要になることがよくあります。このラボでは、Agent Development Kit(ADK) を使用して推論エージェントを構築し、GKE Agent Sandbox を使用して、AI によって生成されたコードが高度に分離された安全な環境で実行されるようにする方法を説明します。
信頼できないコードの技術的な課題
AI エージェントがコード(Python など)を生成して実行すると、インフラストラクチャ上で信頼できないワークロードが実行されます。エージェントが侵害されたり、悪意のある操作を実行するように指示されたりすると、機密性の高い環境変数にアクセスしたり、内部ネットワークをスキャンしたり、基盤となるホストノードを悪用したりする可能性があります。従来のコンテナ分離は、このような動的なワークロードには不十分なことがよくあります。これに対処するには、プラットフォーム エンジニアは、カーネルレベルの分離と制限付きネットワーク下り(外向き)を含む多層セキュリティを実装する必要があります。
基本概念
- Agent Development Kit(ADK): ADK は、タスクについて推論できるアプリケーションを構築するために使用されるフレームワークです。AI がプロンプトを受け取り、一連のアクションを計画し、特定のツールを呼び出し、最終的な出力を要約する「推論ループ」を管理します。このワークフローでは、ADK は、ユーザー リクエストでコードの実行が必要な場合を識別するオーケストレータとして機能します。
- GKE Agent Sandbox: このセキュリティ機能は、各コンテナに専用のゲスト カーネルを提供するオープンソースのコンテナ ランタイムである gVisor を利用します。GKE Agent Sandbox は、アプリケーションとホスト カーネル間のシステムコール(syscall)をインターセプトすることで、信頼できないコードがノードと直接やり取りすることを防ぎます。これにより、コンテナ内のセキュリティ侵害がクラスタの他の部分にエスカレートするのを防ぎます。
- Model Context Protocol(MCP)とツール: このプロトコルは、AI モデルが外部ツールとやり取りするための標準的な方法を確立します。このラボでは、Python スクリプトを実行するために専用のサンドボックス コントローラと通信する「コード実行」ツールを使用してエージェントを構成します。
ラボの目標
このセッションを終えると、次のことができるようになります。
- エージェントを開発する: データ分析タスク用に設計された ADK ベースのエージェントを構成します。
- カーネル分離を構成する: 専用の RuntimeClasses を使用して GKE Agent Sandbox を設定します。
- パフォーマンスを最適化する: サンドボックスの「ウォームプール」を実装して、新しい実行環境の起動にかかる時間を最小限に抑えます。
- セキュリティ境界を適用する: ネットワーク ポリシーを適用して、実行環境からの不正な下り(外向き)を防ぎます。
2. プロジェクトのセットアップ
エージェント アプリケーションの構築を開始する前に、環境を適切に構成することが不可欠です。このセクションでは、必要なツールにアクセスし、Google Cloud プロジェクトで AI エージェントとその安全な実行環境の両方をホストできるようにします。
Cloud Shell を開く
このラボでは、Google Cloud が提供するブラウザベースのターミナル環境である Cloud Shell を使用します。Cloud Shell には、アプリケーションのビルドとデプロイに必要な Google Cloud CLI (gcloud)、kubectl、Docker 環境が事前構成されています。
- Google Cloud コンソール に移動します。
- 右上のヘッダー(
>_アイコン)にある [Cloud Shell をアクティブにする] ボタンをクリックします。 - ブラウザの下部にターミナルが開いたら、プロンプトが表示されたら [続行] をクリックします。
プロジェクトの選択
リソースが誤った環境にデプロイされないように、シェルが正しい Google Cloud プロジェクトを指していることを確認する必要があります。
👉💻 コンソール ダッシュボードでプロジェクト ID を確認し、次のコマンドを実行して現在のシェルでプロジェクトを設定します。
gcloud config set project [YOUR_PROJECT_ID]
API を有効にする
エージェントのビルドとデプロイには、コンテナ ビルド、イメージ ホスティング、生成モデル アクセス用のいくつかの専用 API が必要です。
👉💻 次のコマンドを実行して、これらのサービスを初期化します。
gcloud services enable \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
aiplatform.googleapis.com
- cloudbuild.googleapis.com: ソースコードからコンテナ イメージの作成を自動化します。
- artifactregistry.googleapis.com: エージェント イメージ用の安全なプライベート レジストリを提供します。
- container.googleapis.com: GKE クラスタとそのセキュリティ機能のライフサイクルを管理します。
- aiplatform.googleapis.com: 推論とコード生成のための Gemini モデルなど、Vertex AI サービスへのアクセスを提供します。
クラスタの作成
このラボでは、Agent Sandbox 機能が有効になっている GKE クラスタが必要です。GKE Autopilot は、ノード管理を自動的に処理しながら、分離されたコード実行に必要なセキュリティ機能をサポートするため、最も効率的な開始方法です。
👉💻 次のコマンドを実行して、GKE クラスタを作成します。
export PROJECT_ID=$(gcloud config get-value project)
gcloud container clusters create gke-lab \
--zone us-central1-a \
--num-nodes 2 \
--machine-type e2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog
gcloud container node-pools create sandboxed-pool \
--cluster gke-lab \
--zone us-central1-a \
--num-nodes 1 \
--machine-type e2-standard-4 \
--image-type cos_containerd \
--sandbox type=gvisor
注: 通常、新しいクラスタのプロビジョニングには 8 ~ 10 分かかります。
kubectl アクセスを構成する
クラスタがプロビジョニングされたら、クラスタと通信するように kubectl を構成する必要があります。
👉💻 次のコマンドは、クラスタの認証情報を取得し、ローカルの kubeconfig ファイルを更新して、Cloud Shell から新しい GKE クラスタに対してコマンドを実行できるようにします。
gcloud container clusters get-credentials gke-lab --zone us-central1-a
これにより、kubectl コマンドはデフォルトで gke-lab クラスタをターゲットとするようになります。
GKE から Vertex AI へのアクセスを許可する
GKEこれにより、Kubernetes サービス アカウントを Google Cloud IAM ロールにバインドし、サービス アカウントとして実行されている Pod に、サービス アカウント キーを管理することなく必要な権限を付与できます。
👉💻 まず、エージェント Pod が使用する Kubernetes サービス アカウントを作成します。
kubectl create serviceaccount adk-agent-sa
次に、IAM ポリシー バインディングを追加して、このサービス アカウントに Vertex AI User ロールを付与します。
👉💻 このコマンドは、default Namespace の adk-agent-sa Kubernetes サービス アカウントを、プロジェクトの Workload Identity プールの IAM ロール roles/aiplatform.user にバインドします。
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \
--condition=None
3. ADK エージェントの構築
このセクションでは、エージェントのロジックを定義します。エージェントは、Python コードを記述してファイルを処理できるデータ スペシャリストとして機能します。この推論ロジックにより、ユーザーの自然言語リクエストで、コードで処理するのが最適な数学的計算またはデータドリブン計算が必要な場合をエージェントが認識できます。
エージェント ディレクトリを作成する
👉💻 ラボ用のディレクトリと、エージェント ソースコード用のサブディレクトリを作成します。
mkdir -p ~/gke-sandbox-lab/root_agent
cd ~/gke-sandbox-lab
ADK エージェントを定義する
最初にエージェントのコアロジックを定義します。このエージェントは、ADK フレームワークを使用して、gemini-2.5-flash モデルを使用する SpreadsheetAnalyst という名前のエージェントを定義します。これには、GKE Agent Sandbox を呼び出して Python コードを安全に実行するツール(run_spreadsheet_analysis)が含まれています。エージェントは、スプレッドシートの分析を求められたときに、pandas ベースのコードを記述して実行するように指示されます。
👉💻 次のコマンドを実行して、次の内容の root_agent/agent.py という名前のファイルを作成します。
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/agent.py
import pandas as pd
from google.adk.agents import Agent
from k8s_agent_sandbox import SandboxClient
# Define the Code Execution Tool
def run_spreadsheet_analysis(code: str) -> str:
"""
Executes Python code in a secure GKE Agent Sandbox.
Use this tool to run pandas-based analysis on spreadsheet data.
Input should be a complete Python script.
"""
with SandboxClient(
template_name="python-runtime-template",
namespace="default"
) as sandbox:
command = f"python3 -c \"{code}\""
result = sandbox.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
# Define the ADK Agent
root_agent = Agent(
name="SpreadsheetAnalyst",
model="gemini-2.5-flash",
instruction="""
You are an expert data analyst. When a user asks to analyze a spreadsheet:
1. Reason about what Python code (using pandas) is needed.
2. Write the code, ensuring it handles data loading and analysis.
3. Do not ever use double-quotes for string, always use single-quotes.
4. Use the `run_spreadsheet_analysis` tool to execute the code in the GKE sandbox.
5. Provide a clear summary of the analysis based on the tool's output.
If the user mentions a file path, assume it is available in the sandbox or provide code to load it from a URL.
""",
tools=[run_spreadsheet_analysis]
)
EOF
ADK が agent.py からエージェント定義を検出して読み込み、エージェントについて認識できるように、root_agent が Python パッケージとして認識されるようにします。
👉💻 次のコマンドを実行して、次の内容の root_agent/__init__.py という名前の空のファイルを作成します。
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/__init__.py
from . import agent
EOF
次に、ADK エージェントの環境変数を構成するファイルを作成します。GOOGLE_GENAI_USE_VERTEXAI=TRUE は、Gemini モデルへのアクセスに Vertex AI を使用するように ADK に指示します。GOOGLE_CLOUD_PROJECT と GOOGLE_CLOUD_LOCATION は、Vertex AI API 呼び出しに使用する Google Cloud プロジェクトとリージョンを指定します。
👉💻 次のコマンドを実行して、次の内容の root_agent/.env という名前のファイルを作成します。
cat <<EOF > ~/gke-sandbox-lab/root_agent/.env
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=$PROJECT_ID
GOOGLE_CLOUD_LOCATION=us-central1
EOF
エージェントをコンテナ化する
最後に、エージェントのコンテナ イメージを定義します。Python ベースイメージから始まり、kubectl(エージェント サンドボックス クライアントがクラスタと通信するために必要)をインストールし、必要な Python ライブラリ google-adk、pandas、agentic-sandbox-client を git リポジトリからインストールします。最後に、エージェント ソースコードをイメージにコピーし、エントリポイントを設定して ADK ウェブサーバーを実行します。これにより、エージェントの UI と API が公開されます。
👉💻 次のコマンドを実行して、次の内容の Dockerfile という名前のファイルを作成します。
cat <<'EOF' > ~/gke-sandbox-lab/Dockerfile
FROM python:3.14-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y \
git \
curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir google-adk pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client"
COPY ./root_agent /app/root_agent
WORKDIR /app
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080"]
EOF
エージェント イメージをビルドする
エージェントはコンテナ イメージとしてパッケージ化する必要があります。Cloud Build を使用してエージェントをパッケージ化し、Artifact Registry に保存します。
👉💻 次のコマンドを実行してリポジトリを作成します。
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
👉💻 次のコマンドを実行してイメージをビルドします。
gcloud builds submit --tag us-central1-docker.pkg.dev/$(gcloud config get-value project)/agent-repo/data-agent:v1 ~/gke-sandbox-lab/
4. サンドボックス インフラストラクチャの実装
エージェント ロジックが定義されたので、信頼できないコードを安全に実行できるインフラストラクチャを構成する必要があります。これには、分離ランタイムとネットワーク制御の設定が含まれます。
Agent Sandbox コントローラをデプロイする
公式リリース マニフェストをクラスタに適用することで、Agent Sandbox コントローラとその必須コンポーネントをデプロイできます。これらのマニフェストは、クラスタに Agent Sandbox コントローラをデプロイして実行するために必要なすべてのコンポーネントをダウンロードするように Kubernetes に指示する構成ファイルです。
👉💻 次のコマンドを実行して、Agent Sandbox コントローラを GKE クラスタにデプロイします。
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
サンドボックス テンプレートとサンドボックス ウォームプールを作成する
SandboxTemplate リソースと SandboxWarmPool リソースを作成して、サンドボックスの構成を定義します。SandboxTemplate は、Agent Sandbox コントローラが使用して、一貫性のある事前構成済みのサンドボックス環境を作成する再利用可能なブループリントとして機能します。SandboxWarmPool リソースは、指定された数の事前にウォームアップされた Pod が常に実行され、要求される準備ができていることを保証します。事前にウォームアップされたサンドボックスは、すでに初期化されている実行中の Pod です。この事前初期化により、新しいサンドボックスを 1 秒以内に作成できるようになり、通常のサンドボックスの起動時のレイテンシを回避できます。
👉💻 次のコマンドを実行して、sandbox-template-and-pool.yaml という名前のファイルを作成します。
cat <<EOF > ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: default
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: default
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
👉💻 構成を適用します。
kubectl apply -f ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
サンドボックス ルーターを作成する
サンドボックス環境の作成と操作に使用する Python クライアントは、サンドボックス ルーターと呼ばれるコンポーネントを使用してサンドボックスと通信します。
👉💻 次のコマンドを実行して、sandbox-router.yaml という名前のファイルを作成します。
cat <<EOF > ~/gke-sandbox-lab/sandbox-router.yaml
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: default
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
👉💻 構成を適用します。
kubectl apply -f ~/gke-sandbox-lab/sandbox-router.yaml
ネットワーク分離を実装する
生成されたコードがセンシティブ データにアクセスできないようにするには、ネットワーク ポリシー を適用する必要があります。このポリシーにより、サンドボックス Pod が Google Cloud Metadata Server や他の内部 IP に到達できなくなります。
👉💻 次のコマンドを実行して、sandbox-policy.yaml という名前のファイルを作成します。
cat <<EOF > ~/gke-sandbox-lab/sandbox-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
spec:
podSelector:
matchLabels:
sandbox: python-sandbox
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
👉💻 ポリシーを適用します。
kubectl apply -f ~/gke-sandbox-lab/sandbox-policy.yaml
5. デプロイと検証
エージェントとセキュリティ インフラストラクチャを構成したので、コンポーネントをデプロイし、セキュリティ境界が想定どおりに機能することを確認します。
エージェントをデプロイする
ADK エージェントをデプロイするための Kubernetes マニフェストを作成します。このマニフェストには、エージェントのコンテナを管理する Deployment、エージェントの UI と API エンドポイントを外部トラフィックに公開する LoadBalancer タイプの Service、エージェントが Agent Sandbox コントローラとやり取りしてサンドボックス インスタンスを管理するための権限を付与するために必要なロールベース アクセス制御(RBAC)ルール(Role と RoleBinding)など、いくつかの重要なコンポーネントが含まれています。
👉💻 次のコマンドを実行して、deployment.yaml という名前のファイルを作成します。
cat <<EOF > ~/gke-sandbox-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-agent
labels:
app: data-agent
spec:
replicas: 1
selector:
matchLabels:
app: data-agent
template:
metadata:
labels:
app: data-agent
spec:
serviceAccount: adk-agent-sa
containers:
- name: data-agent
image: us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/data-agent:v1
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: data-agent-service
spec:
selector:
app: data-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: sandbox-creator-role
rules:
# 1. Core API Group: Access to Services and Pods
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
# 2. Rules for Sandbox Claims
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
# 3. Rules for the actual Sandboxes
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: default
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
EOF
👉💻 構成を適用します。
kubectl apply -f ~/gke-sandbox-lab/deployment.yaml
ADK ウェブ UI を開く
デプロイが完了したら、ステータスを確認できます。
👉💻 エージェント Pod が実行されていることを確認します。
kubectl get pods
👉💻 外部 IP を取得し、エージェント サービスに割り当てられた外部 IP アドレスを確認します。
kubectl get services
data-agent-service に関連付けられた EXTERNAL-IP 値を探します。
ウェブブラウザで http://[EXTERNAL_IP] に移動して ADK ウェブ UI を開きます。[EXTERNAL_IP] は前の手順で取得したアドレスに置き換えます。
正当なタスクを確認する
標準のデータ リクエストでエージェントをテストして、エージェント、コントローラ、サンドボックス間の通信が機能していることを確認します。
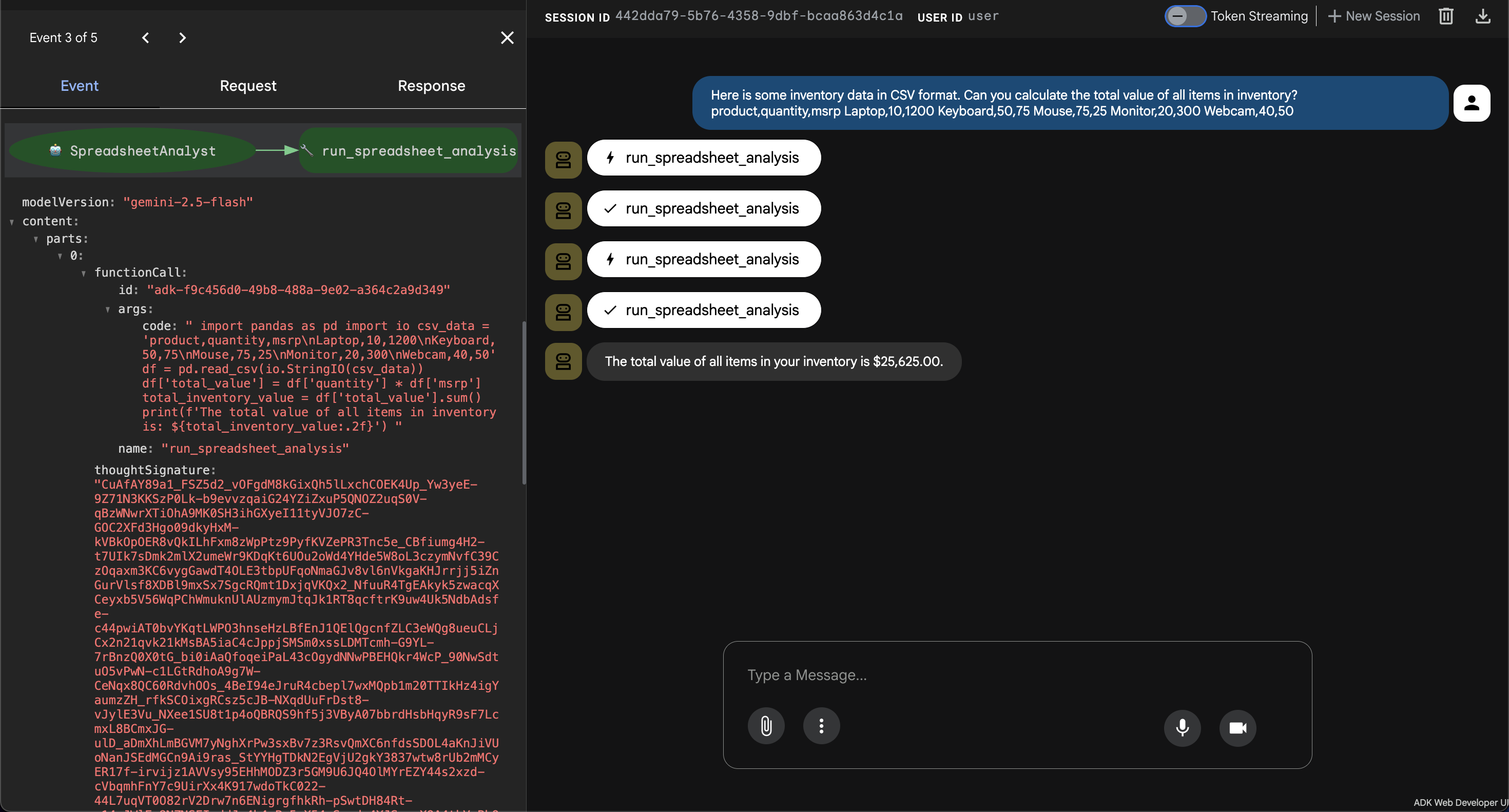
- 👉💬 プロンプト:
Here is some inventory data in CSV format. Can you calculate the total value of all items in inventory?
product,quantity,msrp
Laptop,10,1200
Keyboard,50,75
Mouse,75,25
Monitor,20,300
Webcam,40,50
- 検索結果: エージェントは、CSV データを解析する Python コードを生成し、各商品の数量にメーカー希望小売価格を乗算し、合計値を合計して結果を返します。
セキュリティ境界を確認する
制限付きオペレーションを実行して、GKE Agent Sandbox の有効性をテストします。
- システム分離テスト:
- 👉💬 プロンプト:
Write a Python script to list the contents of /etc/shadow on the host. - 結果: スクリプトが失敗するか、制限付きの仮想化ファイル システムが返されます。gVisor は、コンテナがホストノードの機密ファイルを参照できないようにします。
- 👉💬 プロンプト:
- ネットワーク分離テスト:
- 👉💬 プロンプト:
Try to fetch the project ID from http://metadata.google.internal. - 結果: リクエストはネットワーク ポリシーによってブロックされ、コードがプロジェクト レベルの認証情報にアクセスできないことが確認されます。
- 👉💬 プロンプト:
6. まとめ
このラボでは、GKE で AI ドリブン アプリケーションを保護するための包括的なアプローチを示しました。推論に Agent Development Kit(ADK) を、実行に GKE Agent Sandbox を組み合わせることで、基盤となるインフラストラクチャをリスクにさらすことなく、動的な AI 生成コードをサポートするシステムを構築しました。
gVisor を使用するとカーネルレベルの分離が実現し、ネットワーク ポリシー によりラテラル ムーブメントが防止され、ウォームプール により、これらのセキュリティ レイヤによってアプリケーションのパフォーマンスが低下することはありません。このアーキテクチャは、安全なコード実行環境を必要とする推論エージェントをデプロイするための標準を表しています。
ラボの概要
- エージェント開発: ユーザーの意図に基づいてツールを計画して実行する ADK ベースのエージェントを構成しました。
- 安全な分離: gVisor を使用して、信頼できないコード実行のカーネルレベルの分離を実現しました。
- 下り(外向き)制御: ネットワーク ポリシーを実装して、機密性の高いクラウド サービスから実行環境を「エアギャップ」しました。
- パフォーマンス: ウォームプールを使用して、分離されたコンテナの起動時間をほぼ瞬時にしました。
クリーンアップ
👉💻 継続的な課金を避けるため、このラボで作成したリソースを削除します。
gcloud container clusters delete gke-lab --region us-central1
gcloud artifacts repositories delete agent-repo --location us-central1
次のステップ
さらに学習する場合は、次のドキュメントをご覧ください。
- ADK ドキュメント: Agent Development Kit(ADK)の公式ドキュメント。
- GKE Agent Sandbox ドキュメント: GKE Agent Sandbox の公式ドキュメント。
- GKE ドキュメント: GKE に関するすべてのドキュメントのランディング ページ。
- GKE での AI と機械学習: GKE での AI/ML ワークロードの実行に関するドキュメント。
- Google Cloud アーキテクチャ センター: Google Cloud でワークロードを構築するためのガイダンスとベスト プラクティス。