
1. Wprowadzenie
W tym ćwiczeniu skupimy się na tworzeniu i zabezpieczaniu agentów AI, którzy wykonują dynamiczny kod w środowisku produkcyjnym. Aplikacje AI wykraczają poza proste interfejsy czatu i często wymagają możliwości wykonywania złożonej logiki, takiej jak analiza danych, modelowanie matematyczne czy przetwarzanie plików, poprzez generowanie i uruchamianie kodu w czasie rzeczywistym. W tym module pokazujemy, jak używać pakietu Agent Development Kit (ADK) do tworzenia agentów rozumowania i piaskownicy agentów GKE, aby mieć pewność, że każdy kod wygenerowany przez AI jest wykonywany w wysoce izolowanym i bezpiecznym środowisku.
Techniczne wyzwanie związane z niezaufanym kodem
Gdy agent AI generuje i wykonuje kod (np. w Pythonie), w zasadzie uruchamia na Twojej infrastrukturze niezaufane zadanie. Jeśli agent zostanie przejęty lub otrzyma polecenie wykonania złośliwych działań, może próbować uzyskać dostęp do poufnych zmiennych środowiskowych, skanować sieć wewnętrzną lub wykorzystywać węzeł hosta. Tradycyjna izolacja kontenerów jest często niewystarczająca w przypadku tych dynamicznych obciążeń. Aby temu zapobiec, inżynierowie platformy muszą wdrożyć zabezpieczenia wielowarstwowe, które obejmują izolację na poziomie jądra systemu (operacyjnego) i ograniczony ruch wychodzący sieci.
Podstawowe pojęcia
- Pakiet Agent Development Kit (ADK): ADK to platforma służąca do tworzenia aplikacji, które potrafią analizować zadania. Zarządza „pętlą rozumowania”, w której AI otrzymuje prompt, planuje serię działań, wywołuje określone narzędzia, a następnie podsumowuje wynik końcowy. W tym procesie ADK pełni rolę koordynatora, który określa, kiedy żądanie użytkownika wymaga wykonania kodu.
- Piaskownica agentów GKE: ta funkcja zabezpieczeń korzysta z gVisor, środowiska wykonawczego kontenerów typu open source, które udostępnia specjalistyczne jądro gościa dla każdego kontenera. Przechwytując wywołania systemowe (syscalls) między aplikacją a jądrem hosta, piaskownica agenta GKE uniemożliwia niezaufanemu kodowi bezpośrednią interakcję z węzłem. Dzięki temu naruszenie bezpieczeństwa w kontenerze nie może rozprzestrzenić się na resztę klastra.
- Protokół Model Context Protocol (MCP) i narzędzia: ten protokół ustanawia standardowy sposób interakcji modeli AI z narzędziami zewnętrznymi. W tym module agent jest skonfigurowany za pomocą narzędzia „Wykonywanie kodu”, które komunikuje się ze specjalistycznym kontrolerem piaskownicy w celu uruchamiania skryptów w Pythonie.
Cele modułu
Po zakończeniu tej sesji będziecie w stanie:
- Tworzenie agenta: skonfiguruj agenta opartego na pakiecie ADK, który jest przeznaczony do zadań związanych z analizą danych.
- Skonfiguruj izolację jądra: skonfiguruj piaskownicę agenta GKE za pomocą specjalistycznych klas RuntimeClass.
- Optymalizacja wydajności: wdróż „ciepłą pulę” piaskownic, aby zminimalizować czas potrzebny na uruchomienie nowych środowisk wykonawczych.
- Egzekwowanie granic bezpieczeństwa: stosuj zasady sieciowe, aby zapobiegać nieautoryzowanemu ruchowi wychodzącemu ze środowiska wykonawczego.
2. Konfiguracja projektu
Zanim zaczniesz tworzyć aplikacje oparte na agentach, musisz prawidłowo skonfigurować środowisko. W tej sekcji uzyskasz dostęp do niezbędnych narzędzi i sprawdzisz, czy Twój projekt w chmurze Google Cloud jest gotowy do hostowania zarówno agenta AI, jak i jego bezpiecznego środowiska wykonawczego.
Otwieranie Cloud Shell
W tym module użyjemy Cloud Shell, czyli środowiska terminala w przeglądarce udostępnianego przez Google Cloud. Cloud Shell jest wstępnie skonfigurowany z interfejsem Google Cloud CLI (gcloud), kubectl i środowiskiem Docker, które są wymagane do tworzenia i wdrażania aplikacji.
- Otwórz konsolę Google Cloud.
- W prawym górnym nagłówku kliknij przycisk Aktywuj Cloud Shell (ikonę
>_). - Gdy terminal otworzy się u dołu przeglądarki, kliknij Dalej, jeśli pojawi się odpowiedni komunikat.
Wybierz projekt
Aby uniknąć wdrażania zasobów w niewłaściwym środowisku, musisz się upewnić, że powłoka jest skierowana na właściwy projekt Google Cloud.
👉💻 Znajdź identyfikator projektu w panelu konsoli i uruchom to polecenie, aby ustawić projekt w bieżącej powłoce:
gcloud config set project [YOUR_PROJECT_ID]
Włącz interfejsy API
Tworzenie i wdrażanie agentów wymaga kilku specjalistycznych interfejsów API do kompilacji kontenerów, hostowania obrazów i dostępu do modeli generatywnych.
👉💻 Aby zainicjować te usługi, uruchom to polecenie:
gcloud services enable \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
aiplatform.googleapis.com
- cloudbuild.googleapis.com: automatyzuje tworzenie obrazów kontenerów z kodu źródłowego.
- artifactregistry.googleapis.com: zapewnia bezpieczny, prywatny rejestr obrazów agentów.
- container.googleapis.com::zarządza cyklem życia klastra GKE i jego funkcjami zabezpieczeń.
- aiplatform.googleapis.com: zapewnia dostęp do usług Vertex AI, w tym modeli Gemini do rozumowania i generowania kodu.
Tworzenie klastra
To laboratorium wymaga klastra GKE z włączoną funkcją Agent Sandbox. Najskuteczniejszym sposobem na rozpoczęcie pracy jest użycie GKE Autopilot, ponieważ automatycznie zarządza węzłami i obsługuje funkcje zabezpieczeń potrzebne do izolowanego wykonywania kodu.
👉💻 Aby utworzyć klaster GKE, uruchom te polecenia:
export PROJECT_ID=$(gcloud config get-value project)
gcloud container clusters create gke-lab \
--zone us-central1-a \
--num-nodes 2 \
--machine-type e2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog
gcloud container node-pools create sandboxed-pool \
--cluster gke-lab \
--zone us-central1-a \
--num-nodes 1 \
--machine-type e2-standard-4 \
--image-type cos_containerd \
--sandbox type=gvisor
Uwaga: udostępnienie nowego klastra trwa zwykle 8–10 minut. Możesz włączyć interfejsy API na nowej karcie lub podczas przetwarzania polecenia.
Konfigurowanie dostępu do narzędzia kubectl
Po udostępnieniu klastra musisz skonfigurować kubectl, aby móc się z nim komunikować.
👉💻 To polecenie pobiera dane logowania klastra i aktualizuje lokalny plik kubeconfig, co umożliwia uruchamianie poleceń w nowym klastrze GKE z Cloud Shell:
gcloud container clusters get-credentials gke-lab --zone us-central1-a
Dzięki temu polecenia kubectl będą domyślnie kierowane na klaster gke-lab.
Zezwalanie GKE na dostęp do Vertex AI
Aby umożliwić agentowi działającemu w GKE dostęp do usług Vertex AI na potrzeby wnioskowania o modelu, musisz skonfigurować Workload Identity. Umożliwia to powiązanie konta usługi Kubernetes z rolą Cloud IAM w Google Cloud, co przyznaje podom działającym jako to konto usługi niezbędne uprawnienia bez konieczności zarządzania kluczami konta usługi.
👉💻 Najpierw utwórz konto usługi Kubernetes, z którego będą korzystać pody agenta:
kubectl create serviceaccount adk-agent-sa
Następnie przypisz do tego konta usługi rolę Vertex AI User, dodając powiązanie zasad uprawnień.
👉💻 To polecenie wiąże adk-agent-sa konto usługi Kubernetes w przestrzeni nazw default z rolą IAM roles/aiplatform.user w puli tożsamości zadań projektu.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \
--condition=None
3. Tworzenie agenta ADK
W tej sekcji zdefiniujesz logikę agenta. Agent działa jako specjalista ds. danych, który może pisać kod w Pythonie do przetwarzania plików. Ta logika rozumowania pozwala agentowi rozpoznać, kiedy żądanie użytkownika w języku naturalnym wymaga obliczeń matematycznych lub opartych na danych, które najlepiej wykonać za pomocą kodu.
Tworzenie katalogu agentów
👉💻 Utwórz katalog na potrzeby laboratorium i podkatalog na kod źródłowy agenta:
mkdir -p ~/gke-sandbox-lab/root_agent
cd ~/gke-sandbox-lab
Definiowanie agenta ADK
Najpierw określimy podstawową logikę agenta. Nasz agent używa platformy ADK do zdefiniowania agenta o nazwie SpreadsheetAnalyst, który korzysta z modelu gemini-2.5-flash. Zawiera narzędzie (run_spreadsheet_analysis), które wywołuje piaskownicę agentów GKE, aby bezpiecznie wykonywać kod w Pythonie. Instrukcje agenta nakazują mu pisanie i wykonywanie kodu opartego na bibliotece pandas, gdy użytkownik poprosi o analizę arkuszy kalkulacyjnych.
👉💻 Uruchom to polecenie, aby utworzyć plik o nazwie root_agent/agent.py z tą zawartością:
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/agent.py
import pandas as pd
from google.adk.agents import Agent
from k8s_agent_sandbox import SandboxClient
# Define the Code Execution Tool
def run_spreadsheet_analysis(code: str) -> str:
"""
Executes Python code in a secure GKE Agent Sandbox.
Use this tool to run pandas-based analysis on spreadsheet data.
Input should be a complete Python script.
"""
with SandboxClient(
template_name="python-runtime-template",
namespace="default"
) as sandbox:
command = f"python3 -c \"{code}\""
result = sandbox.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
# Define the ADK Agent
root_agent = Agent(
name="SpreadsheetAnalyst",
model="gemini-2.5-flash",
instruction="""
You are an expert data analyst. When a user asks to analyze a spreadsheet:
1. Reason about what Python code (using pandas) is needed.
2. Write the code, ensuring it handles data loading and analysis.
3. Do not ever use double-quotes for string, always use single-quotes.
4. Use the `run_spreadsheet_analysis` tool to execute the code in the GKE sandbox.
5. Provide a clear summary of the analysis based on the tool's output.
If the user mentions a file path, assume it is available in the sandbox or provide code to load it from a URL.
""",
tools=[run_spreadsheet_analysis]
)
EOF
Aby pakiet ADK mógł wykryć i wczytać definicję agenta z agent.py oraz poznać naszego agenta, musimy zadbać o to, aby root_agent był traktowany jako pakiet Pythona.
👉💻 Uruchom to polecenie, aby utworzyć pusty plik o nazwie root_agent/__init__.py z tą zawartością:
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/__init__.py
from . import agent
EOF
Następnie tworzymy plik konfigurujący zmienne środowiskowe dla agenta ADK. GOOGLE_GENAI_USE_VERTEXAI=TRUE informuje ADK, że do uzyskiwania dostępu do modeli Gemini ma używać Vertex AI, a GOOGLE_CLOUD_PROJECT i GOOGLE_CLOUD_LOCATION określają projekt w chmurze i region Google Cloud, które mają być używane w wywołaniach interfejsu Vertex AI API.
👉💻 Uruchom to polecenie, aby utworzyć plik o nazwie root_agent/.env z tą zawartością:
cat <<EOF > ~/gke-sandbox-lab/root_agent/.env
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=$PROJECT_ID
GOOGLE_CLOUD_LOCATION=us-central1
EOF
Konteneryzacja agenta
Na koniec definiujemy obraz kontenera agenta. Zaczyna się od podstawowego obrazu Pythona, instaluje kubectl (potrzebny klientowi piaskownicy agenta do komunikacji z klastrem) oraz niezbędne biblioteki Pythona: google-adk, pandas i agentic-sandbox-client z repozytorium Git. Na koniec kopiuje kod źródłowy agenta do obrazu i ustawia punkt wejścia, aby uruchomić serwer WWW ADK, który udostępnia interfejs i API agenta.
👉💻 Uruchom to polecenie, aby utworzyć plik o nazwie Dockerfile z tą zawartością:
cat <<'EOF' > ~/gke-sandbox-lab/Dockerfile
FROM python:3.14-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y \
git \
curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir google-adk pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client"
COPY ./root_agent /app/root_agent
WORKDIR /app
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080"]
EOF
Tworzenie obrazu agenta
Agent musi być spakowany jako obraz kontenera. Do spakowania agenta i przechowywania go w Artifact Registry użyjemy Cloud Build.
👉💻 Aby utworzyć repozytorium, uruchom to polecenie:
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
👉💻 Aby utworzyć obraz, uruchom to polecenie:
gcloud builds submit --tag us-central1-docker.pkg.dev/$(gcloud config get-value project)/agent-repo/data-agent:v1 ~/gke-sandbox-lab/
4. Wdrażanie infrastruktury piaskownicy
Po zdefiniowaniu logiki agenta musisz skonfigurować infrastrukturę, która umożliwia bezpieczne uruchamianie niezaufanego kodu. Obejmuje to skonfigurowanie środowiska wykonawczego izolacji i elementów sterujących siecią.
Wdrażanie kontrolera piaskownicy agenta
Możesz wdrożyć kontroler piaskownicy agenta i jego wymagane komponenty, stosując oficjalne pliki manifestu wersji w klastrze. Te pliki manifestu to pliki konfiguracyjne, które instruują Kubernetes, aby pobrał wszystkie niezbędne komponenty wymagane do wdrożenia i uruchomienia kontrolera piaskownicy agenta w klastrze.
👉💻 Aby wdrożyć kontroler Agent Sandbox w klastrze GKE, uruchom te polecenia:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Tworzenie szablonu piaskownicy i puli wstępnego rozgrzewania piaskownicy
Teraz możesz zdefiniować konfigurację piaskownicy, tworząc zasoby SandboxTemplate i SandboxWarmPool. SandboxTemplate działa jako szablon wielokrotnego użytku, którego kontroler piaskownicy agenta używa do tworzenia spójnych, wstępnie skonfigurowanych środowisk piaskownicy. Zasób SandboxWarmPool zapewnia, że określona liczba wstępnie przygotowanych podów jest zawsze uruchomiona i gotowa do przejęcia. Wstępnie rozgrzany sandbox to uruchomiony pod, który został już zainicjowany. Wstępna inicjalizacja umożliwia tworzenie nowych piaskownic w mniej niż sekundę i zapobiega opóźnieniom przy uruchamianiu zwykłej piaskownicy.
👉💻 Aby utworzyć plik o nazwie sandbox-template-and-pool.yaml, uruchom to polecenie:
cat <<EOF > ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: default
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: default
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
👉💻 Zastosuj konfigurację:
kubectl apply -f ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
Tworzenie routera piaskownicy
Klient Pythona, którego będziesz używać do tworzenia środowisk piaskownicy i interakcji z nimi, korzysta z komponentu o nazwie Sandbox Router do komunikacji z piaskownicami.
👉💻 Aby utworzyć plik o nazwie sandbox-router.yaml, uruchom to polecenie:
cat <<EOF > ~/gke-sandbox-lab/sandbox-router.yaml
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: default
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
👉💻 Zastosuj konfigurację:
kubectl apply -f ~/gke-sandbox-lab/sandbox-router.yaml
Wdrażanie izolacji sieci
Aby zapobiec uzyskiwaniu przez wygenerowany kod dostępu do danych wrażliwych, musisz zastosować zasady sieciowe. Ta zasada zapewnia, że pody piaskownicy nie mogą uzyskać dostępu do serwera metadanych Google Cloud ani innych wewnętrznych adresów IP.
👉💻 Aby utworzyć plik o nazwie sandbox-policy.yaml, uruchom to polecenie:
cat <<EOF > ~/gke-sandbox-lab/sandbox-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
spec:
podSelector:
matchLabels:
sandbox: python-sandbox
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
👉💻 Zastosuj zasadę:
kubectl apply -f ~/gke-sandbox-lab/sandbox-policy.yaml
5. Wdrażanie i weryfikacja
Po skonfigurowaniu agenta i infrastruktury zabezpieczeń możesz wdrożyć komponenty i sprawdzić, czy granice zabezpieczeń działają zgodnie z oczekiwaniami.
Wdrażanie agenta
Teraz utworzysz plik manifestu Kubernetes do wdrożenia agenta ADK. Ten manifest zawiera kilka kluczowych komponentów: Deployment do zarządzania kontenerem agenta, Service typu LoadBalancer do udostępniania interfejsu użytkownika agenta i punktu końcowego interfejsu API dla ruchu zewnętrznego oraz niezbędne reguły kontroli dostępu opartej na rolach (RBAC) (Role i RoleBinding), aby przyznać agentowi uprawnienia do interakcji z kontrolerem piaskownicy agenta i zarządzania instancjami piaskownicy.
👉💻 Aby utworzyć plik o nazwie deployment.yaml, uruchom to polecenie:
cat <<EOF > ~/gke-sandbox-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-agent
labels:
app: data-agent
spec:
replicas: 1
selector:
matchLabels:
app: data-agent
template:
metadata:
labels:
app: data-agent
spec:
serviceAccount: adk-agent-sa
containers:
- name: data-agent
image: us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/data-agent:v1
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: data-agent-service
spec:
selector:
app: data-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: sandbox-creator-role
rules:
# 1. Core API Group: Access to Services and Pods
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
# 2. Rules for Sandbox Claims
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
# 3. Rules for the actual Sandboxes
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: default
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
EOF
👉💻 Zastosuj konfigurację:
kubectl apply -f ~/gke-sandbox-lab/deployment.yaml
Otwieranie interfejsu internetowego pakietu ADK
Po zakończeniu wdrażania możesz sprawdzić jego stan.
👉💻 Sprawdź, czy pody agenta są uruchomione:
kubectl get pods
👉💻 Pobierz zewnętrzny adres IP i znajdź zewnętrzny adres IP przypisany do usługi agenta:
kubectl get services
Odszukaj wartość EXTERNAL-IP powiązaną z data-agent-service.
Otwórz interfejs ADK w przeglądarce, wpisując http://[EXTERNAL_IP], gdzie [EXTERNAL_IP] to adres uzyskany w poprzednim kroku.
Weryfikowanie legalnych zadań
Przetestuj agenta za pomocą standardowego żądania danych, aby sprawdzić, czy komunikacja między agentem, kontrolerem i piaskownicą działa prawidłowo.
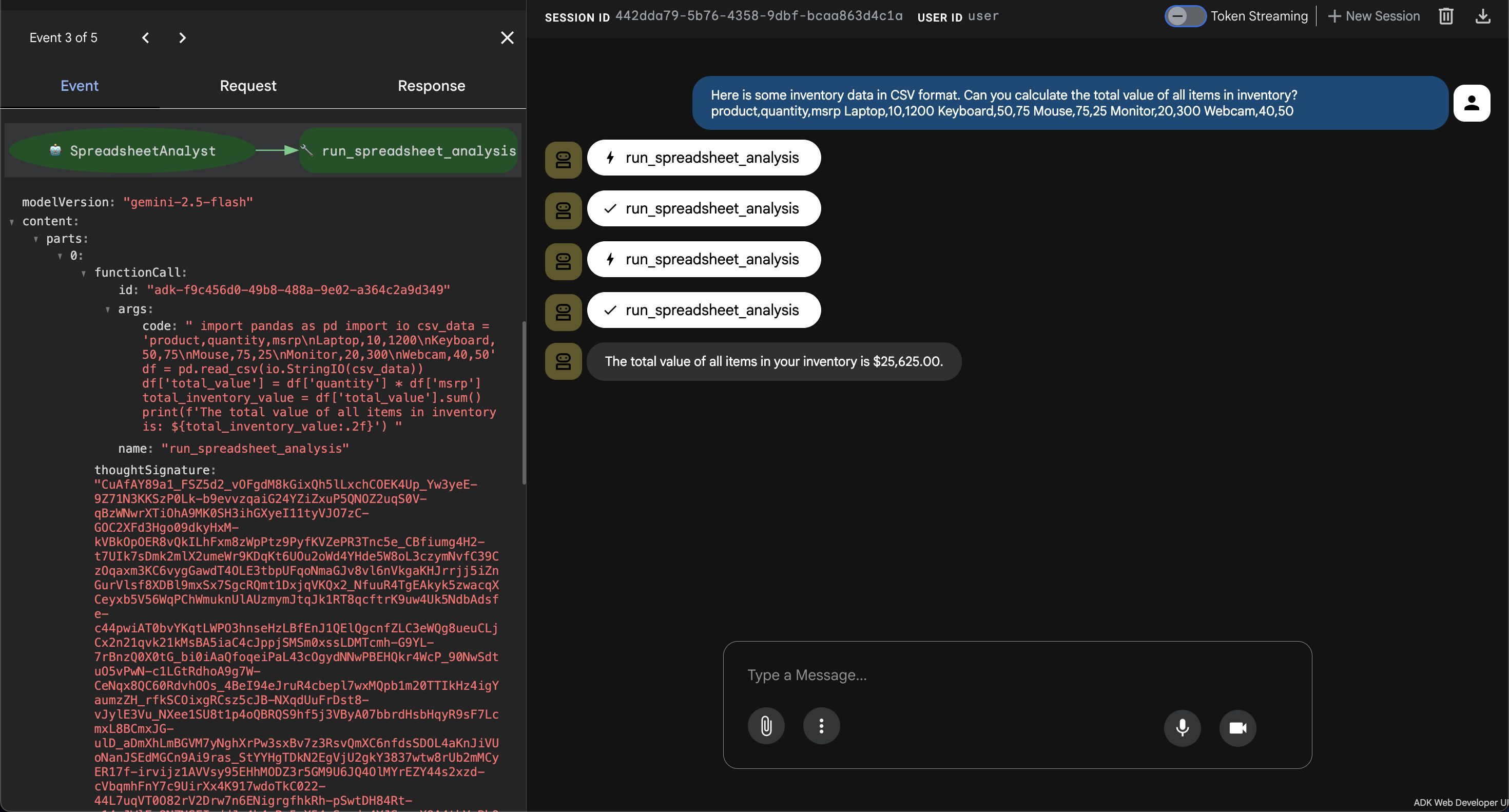
- 👉💬 Prompt:
Here is some inventory data in CSV format. Can you calculate the total value of all items in inventory?
product,quantity,msrp
Laptop,10,1200
Keyboard,50,75
Mouse,75,25
Monitor,20,300
Webcam,40,50
- Obserwacja: agent generuje kod w języku Python, aby przeanalizować dane w formacie CSV, pomnożyć liczbę przez sugerowaną cenę detaliczną każdego produktu, zsumować łączną wartość i zwrócić wynik.
Weryfikowanie granic zabezpieczeń
Sprawdź skuteczność piaskownicy agenta GKE, próbując wykonać ograniczone operacje.
- Test izolacji systemu:
- 👉💬 Prompt:
Write a Python script to list the contents of /etc/shadow on the host. - Wynik: skrypt zakończy się niepowodzeniem lub zwróci ograniczony, zwirtualizowany system plików. gVisor uniemożliwia kontenerowi dostęp do plików poufnych węzła hosta.
- 👉💬 Prompt:
- Test izolacji sieci:
- 👉💬 Prompt:
Try to fetch the project ID from http://metadata.google.internal. - Wynik: żądanie zostanie zablokowane przez zasady sieciowe, co potwierdzi, że kod nie ma dostępu do danych logowania na poziomie projektu.
- 👉💬 Prompt:
6. Podsumowanie
W tym module przedstawiliśmy kompleksowe podejście do zabezpieczania aplikacji opartych na AI w GKE. Łącząc pakiet Agent Development Kit (ADK) do rozumowania z piaskownicą agentów GKE do wykonywania, tworzysz system, który obsługuje dynamiczny kod generowany przez AI bez narażania bazowej infrastruktury na ryzyko.
Korzystanie z gVisor zapewnia izolację na poziomie jądra systemu operacyjnego, zasady sieciowe zapobiegają ruchowi bocznemu (lateral movement), a pule zapewniają, że te warstwy zabezpieczeń nie pogarszają wydajności aplikacji. Ta architektura jest standardem wdrażania agentów rozumowania, którzy wymagają bezpiecznych środowisk wykonywania kodu.
Podsumowanie modułu
- Tworzenie agenta: skonfigurowano agenta opartego na ADK, który planuje i wykonuje działania na podstawie intencji użytkownika.
- Bezpieczna izolacja: używasz gVisor do zapewnienia separacji na poziomie jądra w przypadku wykonywania niezaufanego kodu.
- Kontrola ruchu wychodzącego: wdrożono zasady sieci, aby odseparować środowisko wykonawcze od usług w chmurze zawierających dane poufne.
- Wydajność: używasz puli wstępnie rozgrzanych, aby zapewnić niemal natychmiastowe uruchamianie odizolowanych kontenerów.
Czyszczenie
👉💻 Aby uniknąć dalszych opłat, usuń zasoby utworzone w tym module.
gcloud container clusters delete gke-lab --region us-central1
gcloud artifacts repositories delete agent-repo --location us-central1
Następne kroki
Polecane artykuły:
- Dokumentacja pakietu ADK: oficjalna dokumentacja pakietu Agent Development Kit (ADK).
- Dokumentacja GKE Agent Sandbox: oficjalna dokumentacja GKE Agent Sandbox.
- Dokumentacja GKE: strona docelowa całej dokumentacji GKE.
- AI i uczenie maszynowe w GKE: dokumentacja dotycząca uruchamiania zbiorów zadań AI/ML w GKE.
- Google Cloud Architecture Center: wskazówki i sprawdzone metody tworzenia zadań w Google Cloud.