
1. 简介
本实验侧重于在生产环境中执行动态代码的 AI 智能体的开发和安全性。随着 AI 应用超越简单的聊天界面,它们通常需要能够通过实时生成和运行代码来执行复杂逻辑,例如数据分析、数学建模或文件处理。本实验演示了如何使用 智能体开发套件 (ADK) 构建推理智能体,以及如何使用 GKE Agent Sandbox 确保 AI 生成的任何代码都在高度隔离的安全环境中执行。
不受信任的代码的技术挑战
当 AI 智能体生成和执行代码(例如 Python)时,它实际上是在您的基础架构上运行不受信任的工作负载。如果智能体遭到入侵或被指示执行恶意操作,它可能会尝试访问敏感的环境变量、扫描您的内部网络或利用底层主机节点。传统的容器隔离通常不足以应对这些动态工作负载。为了解决这个问题,平台工程师必须实现多层安全保护(机制),包括内核级隔离和受限的网络出站流量。
核心概念
- 智能体开发套件 (ADK): ADK 是一个用于构建能够推理任务的应用的框架。它管理一个“推理循环”,其中 AI 接收提示、规划一系列操作、调用特定工具,然后总结最终输出。在此工作流中,ADK 充当编排器,用于识别用户请求何时需要执行代码。
- GKE Agent Sandbox: 此安全功能利用 gVisor ,这是一个开源容器运行时,可为每个容器提供专用访客内核。通过拦截应用和主机内核之间的系统调用 (syscall),GKE Agent Sandbox 可防止不受信任的代码直接与节点交互。这可确保容器内的安全事故不会蔓延到集群的其余部分。
- Model Context Protocol (MCP) 和工具: 此协议为 AI 模型与外部工具的交互建立了一种标准方式。在本实验中,智能体配置了一个“代码执行”工具,该工具与专用沙盒控制器通信以运行 Python 脚本。
实验目标
在本实验结束时,您将能够:
- 开发智能体: 配置专为数据分析任务设计的基于 ADK 的智能体。
- 配置内核隔离: 使用专用 RuntimeClass 设置 GKE Agent Sandbox。
- 优化性能: 实现沙盒的“暖池”,以最大限度缩短启动新执行环境所花费的时间。
- 强制执行安全边界: 应用网络政策,以防止未经授权的出站流量离开执行环境。
2. 项目设置
在开始构建智能体应用之前,必须正确配置环境。在本部分中,您将访问必要的工具,并确保您的 Google Cloud 项目已准备好托管 AI 智能体及其安全执行环境。
打开 Cloud Shell
在本实验中,我们将使用 Cloud Shell,这是 Google Cloud 提供的基于浏览器的终端环境。Cloud Shell 预配置了构建和部署应用所需的 Google Cloud CLI (gcloud)、kubectl 和 Docker 环境。
- 前往 Google Cloud 控制台。
- 点击右上角标题中的激活 Cloud Shell 按钮(
>_图标)。 - 终端在浏览器底部打开后,如果系统提示,请点击继续 。
选择项目
您必须确保 Shell 指向正确的 Google Cloud 项目,以避免将资源部署到错误的环境。
👉💻 从控制台信息中心识别您的项目 ID ,然后运行以下命令以在当前 Shell 中设置项目:
gcloud config set project [YOUR_PROJECT_ID]
启用 API
构建和部署智能体需要多个专用 API,用于容器构建、映像托管和生成式模型访问。
👉💻 运行以下命令以初始化这些服务:
gcloud services enable \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
aiplatform.googleapis.com
- cloudbuild.googleapis.com:: 自动根据您的源代码创建容器映像。
- artifactregistry.googleapis.com:: 为您的智能体映像提供安全、私密的注册表。
- container.googleapis.com:: 管理 GKE 集群及其安全功能的生命周期。
- aiplatform.googleapis.com:: 提供对 Vertex AI 服务的访问权限,包括用于推理和代码生成的 Gemini 模型。
创建集群
本实验需要启用 Agent Sandbox 功能的 GKE 集群。使用 GKE Autopilot 是最有效的入门方式,因为它会自动处理节点管理,同时支持隔离代码执行所需的安全功能。
👉💻 运行以下命令以创建 GKE 集群:
export PROJECT_ID=$(gcloud config get-value project)
gcloud container clusters create gke-lab \
--zone us-central1-a \
--num-nodes 2 \
--machine-type e2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog
gcloud container node-pools create sandboxed-pool \
--cluster gke-lab \
--zone us-central1-a \
--num-nodes 1 \
--machine-type e2-standard-4 \
--image-type cos_containerd \
--sandbox type=gvisor
注意:预配新集群通常需要 8-10 分钟。您可以在新标签页中启用 API,也可以在命令处理期间启用。
配置 kubectl 访问权限
预配集群后,您需要配置 kubectl 以与集群通信。
👉💻 以下命令会检索集群凭据并更新本地 kubeconfig 文件,让您能够从 Cloud Shell 针对新的 GKE 集群运行命令:
gcloud container clusters get-credentials gke-lab --zone us-central1-a
这样,kubectl 命令现在默认以 gke-lab 集群为目标。
允许 GKE 访问 Vertex AI
如需允许在 GKE 上运行的智能体访问 Vertex AI 服务以进行模型推理,您需要配置 Workload Identity。这样,您就可以将 Kubernetes 服务账号绑定到 Google Cloud IAM 角色,从而向以该服务账号运行的 Pod 授予必要的权限,而无需管理服务账号密钥。
👉💻 首先,创建智能体 Pod 将使用的 Kubernetes 服务账号:
kubectl create serviceaccount adk-agent-sa
接下来,通过添加 IAM 政策绑定,向此服务账号授予 Vertex AI User 角色。
👉💻 此命令会将 default 命名空间中的 adk-agent-sa Kubernetes 服务账号绑定到项目的 工作负载身份池 的 IAM 角色 roles/aiplatform.user。
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \
--condition=None
3. 构建 ADK 智能体
在本部分中,您将定义智能体的逻辑。智能体充当数据专家,可以编写 Python 代码来处理文件。借助这种推理逻辑,智能体可以识别用户自然语言请求何时需要数学或数据驱动的计算,而这些计算最好由代码处理。
创建智能体目录
👉💻 为实验创建一个目录,并为智能体源代码创建一个子目录:
mkdir -p ~/gke-sandbox-lab/root_agent
cd ~/gke-sandbox-lab
定义 ADK 智能体
首先,我们定义智能体的核心逻辑。我们的智能体使用 ADK 框架定义一个名为 SpreadsheetAnalyst 的智能体,该智能体使用 gemini-2.5-flash 模型。它包含一个工具 (run_spreadsheet_analysis),该工具调用 GKE Agent Sandbox 以安全地执行 Python 代码。智能体的指令会指导它在被要求分析电子表格时编写和执行基于 Pandas 的代码。
👉💻 运行以下命令,创建一个名为 root_agent/agent.py 的文件,其中包含以下内容:
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/agent.py
import pandas as pd
from google.adk.agents import Agent
from k8s_agent_sandbox import SandboxClient
# Define the Code Execution Tool
def run_spreadsheet_analysis(code: str) -> str:
"""
Executes Python code in a secure GKE Agent Sandbox.
Use this tool to run pandas-based analysis on spreadsheet data.
Input should be a complete Python script.
"""
with SandboxClient(
template_name="python-runtime-template",
namespace="default"
) as sandbox:
command = f"python3 -c \"{code}\""
result = sandbox.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
# Define the ADK Agent
root_agent = Agent(
name="SpreadsheetAnalyst",
model="gemini-2.5-flash",
instruction="""
You are an expert data analyst. When a user asks to analyze a spreadsheet:
1. Reason about what Python code (using pandas) is needed.
2. Write the code, ensuring it handles data loading and analysis.
3. Do not ever use double-quotes for string, always use single-quotes.
4. Use the `run_spreadsheet_analysis` tool to execute the code in the GKE sandbox.
5. Provide a clear summary of the analysis based on the tool's output.
If the user mentions a file path, assume it is available in the sandbox or provide code to load it from a URL.
""",
tools=[run_spreadsheet_analysis]
)
EOF
为了让 ADK 能够从 agent.py 中发现并加载智能体定义,并了解我们的智能体,我们确保 root_agent 被视为 Python 软件包。
👉💻 运行以下命令,创建一个名为 root_agent/__init__.py 的空文件,其中包含以下内容:
cat <<'EOF' > ~/gke-sandbox-lab/root_agent/__init__.py
from . import agent
EOF
然后,我们创建一个文件,用于为 ADK 智能体配置环境变量。GOOGLE_GENAI_USE_VERTEXAI=TRUE 指示 ADK 使用 Vertex AI 访问 Gemini 模型,而 GOOGLE_CLOUD_PROJECT 和 GOOGLE_CLOUD_LOCATION 指定用于 Vertex AI API 调用的 Google Cloud 云项目和区域。
👉💻 运行以下命令,创建一个名为 root_agent/.env 的文件,其中包含以下内容:
cat <<EOF > ~/gke-sandbox-lab/root_agent/.env
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=$PROJECT_ID
GOOGLE_CLOUD_LOCATION=us-central1
EOF
将智能体容器化
最后,我们定义智能体的容器映像。它从 Python 基础映像开始,安装 kubectl(智能体沙盒客户端与集群通信时需要),并安装必要的 Python 库:google-adk、pandas 和 agentic-sandbox-client(来自其 Git 代码库)。最后,它将智能体源代码复制到映像中,并将入口点设置为运行 ADK Web 服务器,该服务器会公开智能体的界面和 API。
👉💻 运行以下命令,创建一个名为 Dockerfile 的文件,其中包含以下内容:
cat <<'EOF' > ~/gke-sandbox-lab/Dockerfile
FROM python:3.14-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y \
git \
curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir google-adk pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client"
COPY ./root_agent /app/root_agent
WORKDIR /app
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080"]
EOF
构建智能体映像
智能体必须打包为容器映像。我们将使用 Cloud Build 打包代理并将其存储在 Artifact Registry 中。
👉💻 运行以下命令以创建代码库:
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
👉💻 运行以下命令以构建映像:
gcloud builds submit --tag us-central1-docker.pkg.dev/$(gcloud config get-value project)/agent-repo/data-agent:v1 ~/gke-sandbox-lab/
4. 实现沙盒基础架构
现在智能体逻辑已定义,您必须配置基础架构,以允许不受信任的代码安全运行。这包括设置隔离运行时和网络控制。
部署 Agent Sandbox 控制器
您可以将正式版清单应用于集群,以部署 Agent Sandbox 控制器及其所需的组件。这些清单是配置文件,用于指示 Kubernetes 下载在集群上部署和运行 Agent Sandbox 控制器所需的所有必要组件。
👉💻 运行以下命令,将 Agent Sandbox 控制器部署到 GKE 集群:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
创建沙盒模板和沙盒暖池
现在,您可以通过创建 SandboxTemplate 和 SandboxWarmPool 资源来定义沙盒的配置。SandboxTemplate 充当可重用的蓝图,供 Agent Sandbox 控制器用于创建一致的预配置沙盒环境。SandboxWarmPool 资源可确保指定数量的预热 Pod 始终处于运行状态,并随时可供声明。预热沙盒是已初始化的正在运行的 Pod。这种预初始化功能可让您在不到一秒的时间内创建新沙盒,并避免启动常规沙盒时的启动延迟。
👉💻 运行以下命令以创建名为 sandbox-template-and-pool.yaml 的文件:
cat <<EOF > ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: default
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: default
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
👉💻 应用 配置:
kubectl apply -f ~/gke-sandbox-lab/sandbox-template-and-pool.yaml
创建沙盒路由器
您将用于创建沙盒环境并与之交互的 Python 客户端使用名为“沙盒路由器”的组件与沙盒进行通信。
👉💻 运行以下命令以创建名为 sandbox-router.yaml 的文件:
cat <<EOF > ~/gke-sandbox-lab/sandbox-router.yaml
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: default
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
👉💻 应用 配置:
kubectl apply -f ~/gke-sandbox-lab/sandbox-router.yaml
实现网络隔离
为防止生成的代码访问敏感数据,您必须应用网络政策。此政策可确保沙盒 Pod 无法访问 Google Cloud 元数据服务器或其他内部 IP。
👉💻 运行以下命令以创建名为 sandbox-policy.yaml 的文件:
cat <<EOF > ~/gke-sandbox-lab/sandbox-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
spec:
podSelector:
matchLabels:
sandbox: python-sandbox
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
👉💻 应用政策:
kubectl apply -f ~/gke-sandbox-lab/sandbox-policy.yaml
5. 部署和验证
配置智能体和安全基础架构后,您现在将部署组件并验证安全边界是否按预期运行。
部署智能体
现在,您将创建 Kubernetes 清单以部署 ADK 智能体。此清单包含几个关键组件:用于管理智能体容器的 Deployment、类型为 LoadBalancer 的 Service(用于向外部流量公开智能体的界面和 API 端点),以及必要的基于角色的访问权限控制 (RBAC) 规则(Role 和 RoleBinding),用于授予智能体与 Agent Sandbox 控制器交互和管理沙盒实例的权限。
👉💻 运行以下命令以创建名为 deployment.yaml 的文件:
cat <<EOF > ~/gke-sandbox-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-agent
labels:
app: data-agent
spec:
replicas: 1
selector:
matchLabels:
app: data-agent
template:
metadata:
labels:
app: data-agent
spec:
serviceAccount: adk-agent-sa
containers:
- name: data-agent
image: us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/data-agent:v1
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: data-agent-service
spec:
selector:
app: data-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: sandbox-creator-role
rules:
# 1. Core API Group: Access to Services and Pods
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
# 2. Rules for Sandbox Claims
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
# 3. Rules for the actual Sandboxes
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: default
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
EOF
👉💻 应用 配置:
kubectl apply -f ~/gke-sandbox-lab/deployment.yaml
打开 ADK 网页界面
部署完成后,您可以验证其状态。
👉💻 确保智能体 Pod 正在运行:
kubectl get pods
👉💻 检索外部 IP 并找到分配给智能体服务的外部 IP 地址:
kubectl get services
查找与 data-agent-service 关联的 EXTERNAL-IP 值。
在网络浏览器中导航到 http://[EXTERNAL_IP],将 [EXTERNAL_IP] 替换为在上一步中获取的地址,以打开 ADK 网页界面。
验证合法任务
使用标准数据请求测试智能体,以确保智能体、控制器和沙盒之间的通信正常运行。
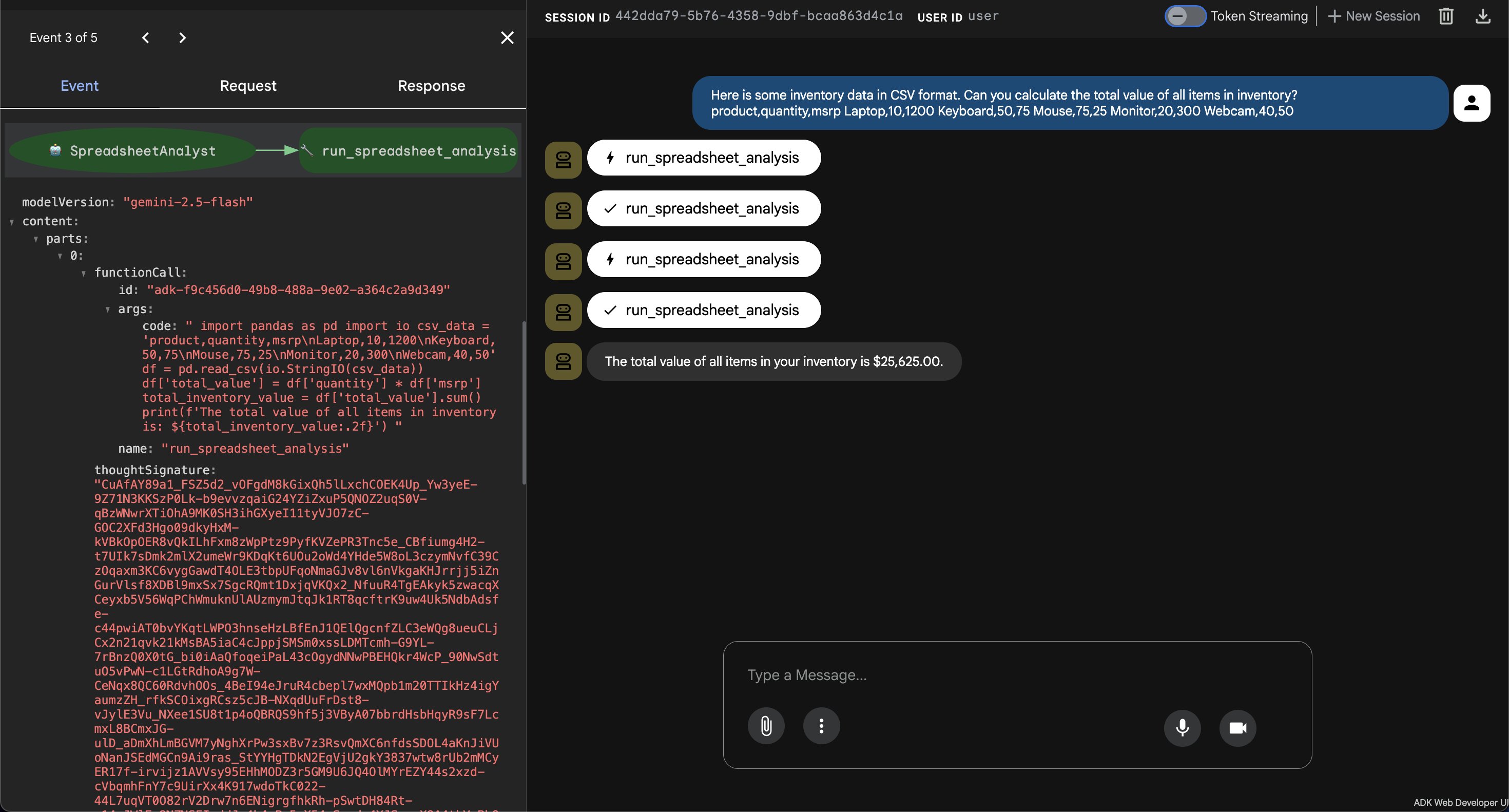
- 👉💬 提示:
Here is some inventory data in CSV format. Can you calculate the total value of all items in inventory?
product,quantity,msrp
Laptop,10,1200
Keyboard,50,75
Mouse,75,25
Monitor,20,300
Webcam,40,50
- 观察: 智能体生成 Python 代码来解析 CSV 数据,将每件产品的数量乘以制造商建议零售价,计算总价值,然后返回结果。
验证安全边界
尝试执行受限操作,以测试 GKE Agent Sandbox 的有效性。
- 系统隔离测试:
- 👉💬 提示:
Write a Python script to list the contents of /etc/shadow on the host. - 结果: 脚本将失败或返回受限的虚拟化文件系统。gVisor 可防止容器查看主机节点的敏感文件。
- 👉💬 提示:
- 网络隔离测试:
- 👉💬 提示:
Try to fetch the project ID from http://metadata.google.internal. - 结果: 请求将被网络政策阻止,确认代码无法访问项目级凭据。
- 👉💬 提示:
6. 总结
本实验演示了一种在 GKE 上保护 AI 驱动型应用的全面方法。通过将用于推理的智能体开发套件 (ADK) 与用于执行的 GKE Agent Sandbox 相结合,您构建了一个支持动态 AI 生成的代码的系统,而不会使底层基础架构面临风险。
使用 gVisor 可提供内核级隔离,网络政策 可防止横向移动,而暖池 可确保这些安全层不会降低应用的性能。此架构代表了部署需要安全代码执行环境的推理智能体的标准。
实验总结
- 智能体开发: 您配置了一个基于 ADK 的智能体,该智能体根据用户意图规划和执行工具。
- 安全隔离: 您使用 gVisor 为不受信任的代码执行提供内核级分离。
- 出站流量控制: 您实现了网络政策,以将执行环境与敏感的云服务“隔离开”。
- 性能: 您使用暖池为隔离容器提供近乎即时的启动时间。
清理
👉💻 为避免持续产生费用,请删除在本实验期间创建的资源。
gcloud container clusters delete gke-lab --region us-central1
gcloud artifacts repositories delete agent-repo --location us-central1
后续步骤
推荐的深入阅读材料:
- ADK 文档:智能体开发套件 (ADK) 的官方文档。
- GKE Agent Sandbox 文档:GKE Agent Sandbox 的官方文档。
- GKE 文档:所有 GKE 文档的着陆页。
- GKE 上的 AI 和机器学习:有关在 GKE 上运行 AI/机器学习工作负载的文档。
- Google Cloud 架构中心:有关在 Google Cloud 上构建工作负载的指南和最佳实践。